







 本文介绍了竞争型学习神经网络,包括SOM、LVQ和CPN的基本概念、工作原理以及Python实现。SOM神经网络用于数据聚类和降维,LVQ是带有监督的聚类算法,而CPN结合了SOM和BP网络的特点。文章通过实例展示了这些网络的应用,并讨论了它们的优缺点。
本文介绍了竞争型学习神经网络,包括SOM、LVQ和CPN的基本概念、工作原理以及Python实现。SOM神经网络用于数据聚类和降维,LVQ是带有监督的聚类算法,而CPN结合了SOM和BP网络的特点。文章通过实例展示了这些网络的应用,并讨论了它们的优缺点。
竞争型学习神经网络
简述
最近对神经网络比较感兴趣,因此花了两三天时间对整个领域进行了简单的调研,梳理和学习。其中深度学习,尤其以我们熟悉的如今大火的深度网络模型,如CNN, RNN, GAN和AE及它们的子类等;是在本世纪初,硬件性能达到了一个新的高度后才能有如此巨大的发展的。事实上在21世纪之前,各种各样的神经网络模型已经被发明并应用。那时候由于硬件性能的限制,以及由通信网络不发达导致的数据量匮乏,并没有人敢去思考如何用巨大的算力去挖掘大数据。那时的网络一般是借助设计网络结构的技巧取胜(比如很多网络不借助编程,而是直接用硬件实现),其中很多网络在今天,其设计理念也是值得借鉴的。
为此,我在两三天的时间里,学习了一些从上世纪60年代,到本世纪初出现的一些经典的神经网络模型,并在此整理并给出代码。
竞争层
我们本篇主要介绍竞争型的神经网络,即在网络中出现竞争层的网络。竞争层比起我们熟悉的全连接层要朴素很多;
首先,竞争层会接受一个向量样本,每个竞争层中的神经元都自带一个和该样本维度相同的向量,称作"权向量"。然后,用每个权向量和输入向量按照一定规则进行比较,相似程度最高的那个称作获胜神经元。
然后在输出时,只有获胜神经元会输出1,其他神经元输出0,也就是胜者通吃的法则。这一特点也就决定了,在使用反向传播算法训练这种网络时,只有获胜神经元会受到训练。
讲到这里大家可能会发现,这种训练方法有点类似聚类中的K-means算法。通过比较中心向量和样本的相似程度,调整中心向量。的确,两者理念是相同的。而这一特点也就决定了竞争型网络既可以用于监督学习,也可以用于无监督学习。
SOM神经网络简述
首先,我们来介绍Self-Organizing feature Map,自组织特征映射网络,som是一种自组织的网络结构,常用于数据的聚类和降维。网络的结构非常简单,只有一层竞争层,接受输入向量并进行比较后,直接输出结果。

其主要特点是网络内部的拓扑结构,为什么它叫"自组织"网络?因为SOM在执行基本的竞争层工作的同时,不止是调整获胜神经元,还会调整获胜神经元附近的神经元。为什么要进行这样的操作呢?我们可以想象,在我们的训练过程中,相似的样本会在向量空间中相对接近,形成一个独立的簇状。如果让相邻的神经元也去靠近同样的样本,则很大概率会让训练出的网络的相邻神经元,在向量空间中也越接近,表征这相同的类别。WIKI上的一张图就很形象。
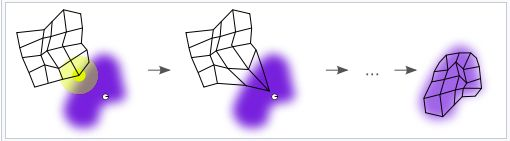
其训练分为:
- 初始化每个节点的权重。权重设置为标准化小型随机值。
- 从训练集中随机选择一个向量并呈现给网格。
- 检查每个节点来计算哪一个的权重最像输入向量。这会让你获得最佳匹配单元(BMU)。我们通过迭代所有节点并计算每个节点的权重与当前输入向量之间的欧几里德距离来计算BMU。权重向量和输入向量最接近的节点则被标记为BMU。
- 计算BMU邻域的半径。在半径范围内找到的节点则认为处于BMU邻域内。
- 调整在步骤4中发现的节点的权重,让它们更像输入向量。节点和BMU越近,权重调整的越多。重复步骤2,迭代N次。
评估相似度可以使用单纯的向量欧拉距离,也可以借助度量学习或者归一化等方法帮助训练。
这种方法是一种聚类方法,而又有不同于聚类的地方;因为网络能自组织地学习特征向量空间中的分布,并把相似的分布烙印在自己的网络拓扑结构上,它同时还具备了特征间聚类和可视化的能力。

如图,在特征上接近的数据会被聚集在网络拓扑结构相同的区域内。
SOM神经网络实战
TIPS:有关训练的小技巧
第一,SOM和BP网不同,它的学习速度很大程度取决于样本,而不取决于网络当前的学习情况。所以如果想让网络有效训练,一种方法是使用随迭代次数下降的学习率。
第二:在进行自组织训练时,调动周边神经元的一个方法是先计算神经元在网络拓扑上的距离,再根据该距离计算出一个衰减因子。常用的衰减函数有高斯分布、门函数等。
前面说了,SOM网络能用作聚类、降维等工作上。这里我们就分别体验一下它的功能。
考虑这样的一项任务,对一个色彩比较多样的图片,我们想要让它进行简单压缩,让每个像素点的色彩种类限制在几种。即在图片所有像素组成的三维向量空间内寻找到最能表征图片的n种颜色。
这个任务很适合SOM,因为SOM进行的就是向量的竞争,而且最后得到的权值向量就可以直接被用于表征图片的颜色。
首先我们调一下包,常用的numpy和matplotlib等
import numpy as np
import random
from copy import deepcopy
import matplotlib
from matplotlib import pyplot as plt
然后我们设计一个SOM类,以及配套的距离估算函数等。
def gaussian(x, sigma):
"""Returns a Gaussian centered in c."""
d = (2*np.pi)**0.5*sigma
return np.exp(-(x**2)/2/(sigma**2))/d
def Manhattan(x1,x2):
return abs(x1[0]-x2[0])+abs(x1[1]-x2[1])
class node:
def __init__(self,input_len,weight):
self.w = np.ones(input_len)*weight
self.x = None
self.y = None
def forward(self, x):
self.x = x
vec = (x-self.w).reshape(1,-1)
self.y = np.dot(vec,vec.T)
return self.y
def backward(self):
return (self.x-self.w)
class SOM:
def __init__(self,x,y,input_len,sigma,weight,lr=0.2):
'''
输入参数
x,y:输出层的长宽
input_len:输入向量的size
sigma:高斯衰落函数的标准差
'''
self.x = x;self.y = y;
self.nodes = [[node(input_len,weight) for _ in range(y)] for _ in range(x)]
self.sigma = sigma
self.lr = lr
def fit(self, data, iter_num=10000):
for t in range(iter_num):
lr = self.lr*np.exp(-t/iter_num)
x = random.choice(data)
winner = (0,0)
dist = float("inf")
for i in range(self.x):
for j in range(self.y):
node = self.nodes[i][j]
d = node.forward(x)
if d<dist:
winner = (i,j)
dist = d
i,j = winner
dw = self.nodes[i][j].backward()
for m in range(self.x):
for n in range(self.y):
node = self.nodes[m][n]
manh = Manhattan((m,n),(i,j))
node.w += lr*gaussian(manh,self.sigma)*dw
def predict(self, x):
res = None
dist = float("inf")
for i in range(self.x):
for j in range(self.y):
node = self.nodes[i][j]
d = node.forward(x)
if d<dist:
res = node.w
dist = d
return res
def weights(self):
return [[self.nodes[i][j].w for j in range(self.y)]
for i in range(self.x)]
导入一张图片用作训练,这里我用的是我的微信头像’kokoro’
img = plt.imread('kokoro.jpg& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6295
6295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









