







机器学习之K均值聚类
- 什么是聚类?
聚类是一种无监督的学习,它将相似的对象归到同一个簇中。假定有一些数据,现在将相似数据归到一起,簇识别会告诉我们这些簇到底都是些什么。聚类与分类的最大不同在于,分类的目标事先已知,而聚类则不一样。因为其产生的结果与分类相同,而只是类别没有预先定义,聚类有时也被称为无监督分类(unsupervised classification)。
- k均值聚类
把一组样本分成k组,根据每个样本的特征,相似的放在一组。具体来说:
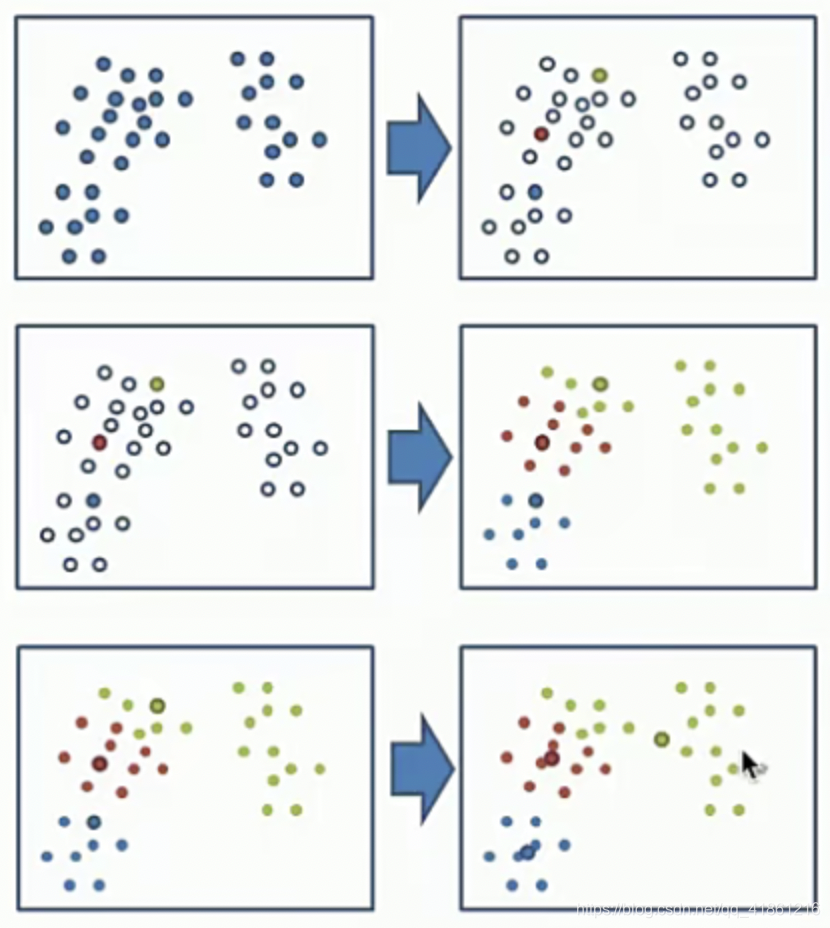
1.先在这个样本中随机取k个点样本作为质心,如下图第一行。
2.再对每一个样本计算到这k个点的距离,选取最近的作为自己的标记,最终形成k组,如下图第二行。
3.分别计算这k个组的平均值,再与原来的k个质心去比较,如果相同则聚类结束,如果不同,把这新的k个平均值作为新的质心,重复第二步。如下图第三行。
- KmeansAPI介绍

kmeans在sklearn的cluster包里。KMeans的第一个参数指的是你要分几个类,第二个参数是默认的,写不写无所谓。
示例:
import kMeans
from numpy import *
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
datMat = mat(kMeans.loadDataSet('testSet.txt'))
x = datMat[:]
km = KMeans(n_clusters=4)
km.fit(x)
predict = km.predict(x)
print(predict)
color = ['blue','red','green','orange']
colr = [color[i] for i in predict]
plt.scatter(x[:,0].tolist(),x[:,1].tolist(),color=colr)
plt.show()
先加载要聚类的样本,我用的是机器学习实战里面的testSet的样本。使用kmean时先实例化一个对象(km),我是把样本集分成了4组,所以参数是4,然后训练样本集,然后进行预测。
上面这张是聚类的结果,把样本标记成0、1、2、3四组。然后绘制出散点图图如下。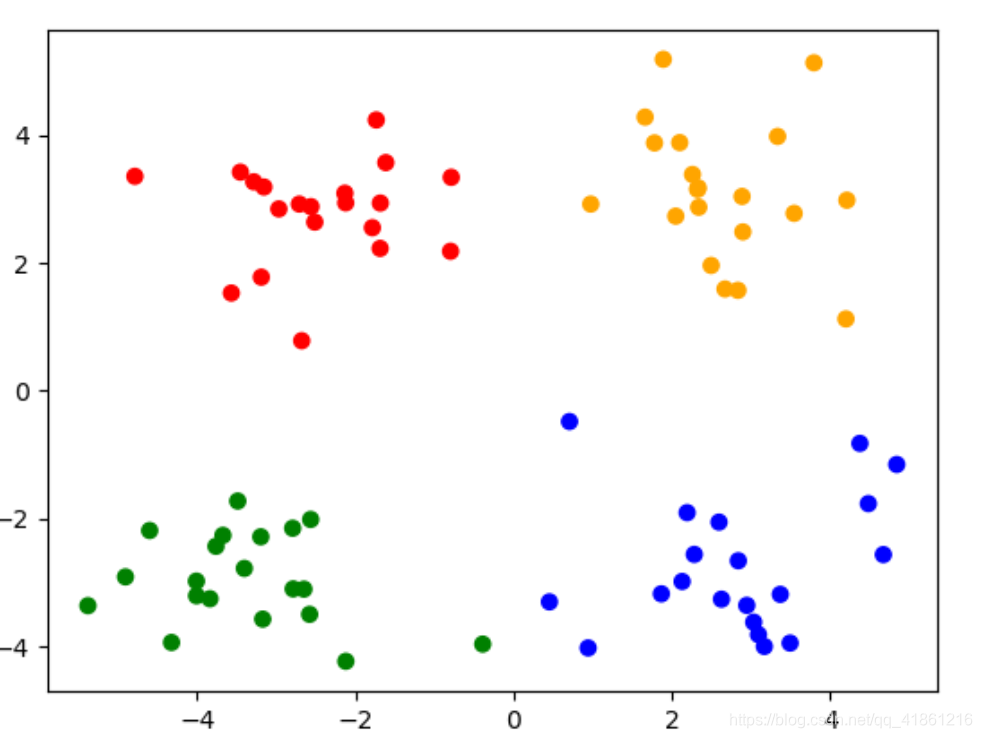















 1163
1163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











