







引言
人工智能(AI)——一个熟悉又神秘的词汇。我们常听说它可以生成诗歌、编写代码、创作艺术,甚至回答各种问题。然而,当你想亲手实现一个“AI 模型”时,却可能感到无从下手。这篇教程正是为你准备的,将带你从零开始,逐步掌握从“AI 新手”到“能够搭建 AI 模型”的核心技能。
一、AI 的基本概念
1.什么是 AI 模型?
AI 模型是通过训练得到的一种程序,能够利用海量数据学习规律,并在此基础上完成各种任务。它的工作原理就像教一个孩子认水果:通过反复观察图片,孩子学会了“香蕉是黄色的”“苹果是圆的”,从而即使面对未见过的水果图片,也能做出正确判断。
AI模型:学生- 数据:课本
- 模型训练:学生做练习题
- 模型评估:学生考试
2.模型如何学习?
模型学习的核心步骤如下:
- 喂数据:提供大量样本,让模型了解世界的“规律”。
- 定义目标:明确任务,例如判断图片中是狗还是猫。
- 反复训练:模型不断调整其“参数”(类似脑回路),以优化对数据的理解。
- 测试与应用:在实际场景中运行模型,评估其效果。
3.AI 模型的类型
根据任务的性质,AI 模型主要分为以下几类:
- 分类模型:识别类别,例如垃圾邮件分类。
- 回归模型:预测数值,例如房价预测。
- 生成模型:创造内容,例如生成图像或文本。
4.什么是“大模型”?
“大模型”是相对于传统 AI 模型而言的,指的是参数规模大、学习能力强的模型。它们拥有强大的数据处理和推理能力,能够应对复杂任务。例如,GPT 系列模型不仅可以完成写作任务,还能实现编程、回答问题等多种功能,表现得更加“聪明”。
二、开发环境准备
在开始训练模型前,我们需要搭建一个“工作环境”,就像进入厨房前需要准备好工具一样。以下是必备的“厨具”:
1.安装 Python
Python 是 AI 开发的首选语言,因其简单易用的特点深受开发者喜爱。前往 Python 官网 下载最新版本并安装。安装时务必勾选 “Add Python to PATH”,确保后续工具可以正常运行。
2.安装开发工具
推荐以下两款工具,便于你编写和调试代码:
Jupyter Notebook:一个交互式环境,适合初学者边调试边学习AI代码。VS Code:功能强大的代码编辑器,支持插件扩展,适合处理更复杂的项目。
3.安装必要的 Python 库
在终端运行以下命令,安装 AI 开发常用的库:
pip install numpy pandas matplotlib seaborn scikit-learn tensorflow
这些库的用途:
NumPy:用于高效的数学计算和数组操作。Pandas:强大的数据处理与分析工具。Matplotlib/Seaborn:用于数据可视化,展示数据分布和关系。Scikit-learn:经典的机器学习库,支持分类、回归和聚类等任务。TensorFlow:深度学习框架,用于构建和训练神经网络。
三、数据是 AI 的“粮食”
1.数据集来源
在 AI 项目中,数据是模型的基础,就像粮食之于人类。没有数据,模型就无法“成长”。下面是常见的数据来源:
- 开源平台:如
Kaggle和UCI Machine Learning Repository提供了丰富的高质量数据集,适合各种任务和领域。 Sklearn自带数据集:内置数据集,如加利福尼亚房价、鸢尾花数据集,简单易用,适合初学者入门练习。
本教程选用:加利福尼亚房价数据集
from sklearn.datasets import fetch_california_housing
import pandas as pd
# 加载 California Housing 数据集
housing = fetch_california_housing()
data = pd.DataFrame(housing.data, columns=housing.feature_names)
data['PRICE'] = housing.target
# 查看数据
print(data.head())
运行结果:
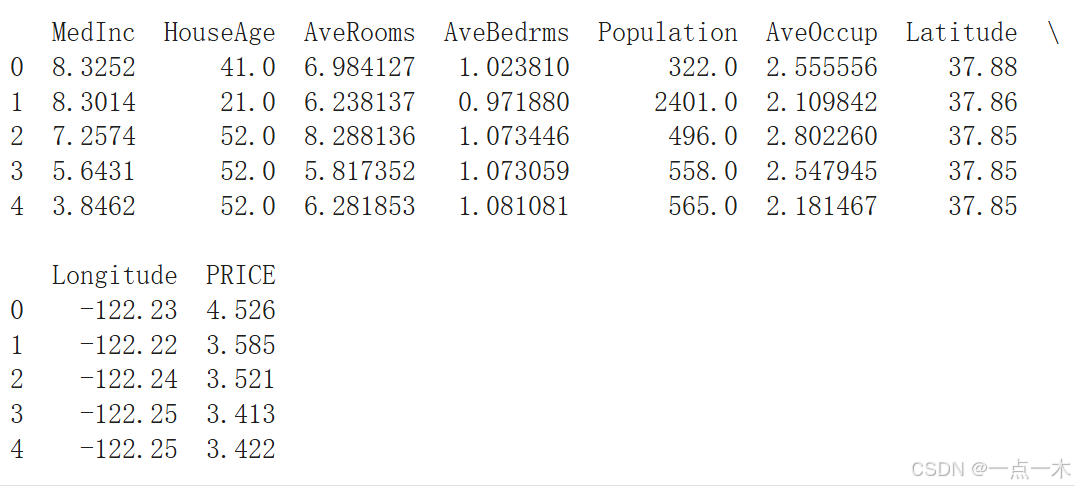
2.数据探索与可视化
在训练模型之前,数据探索是至关重要的一步。通过探索,我们可以了解数据的结构、分布特征以及特征间的关系,为后续的数据清洗和建模奠定基础。
(1) 数据基本信息
# 查看数据统计信息
print(data.describe())
运行结果:
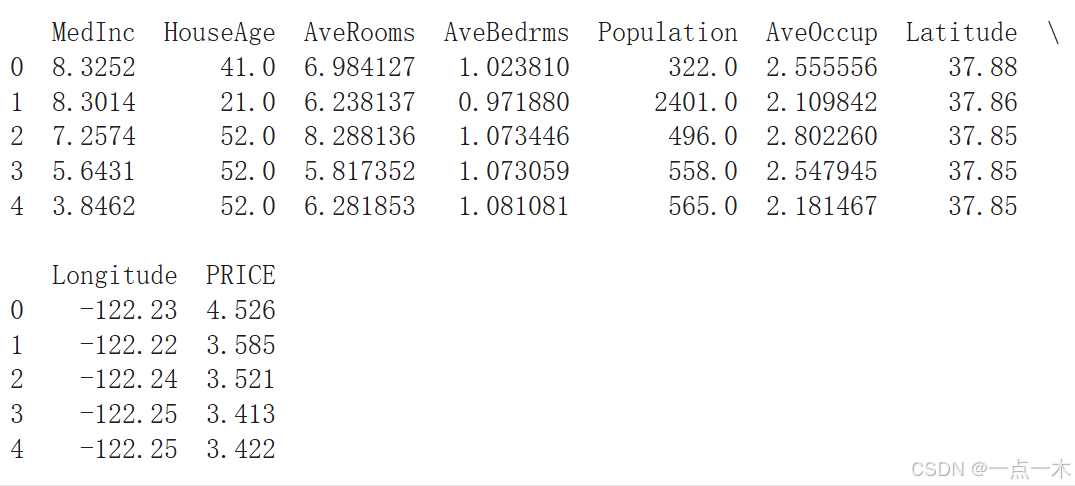
(2) 可视化分布
import matplotlib.pyplot as plt
import seaborn as sns
# 绘制房价分布图
sns.histplot(data['PRICE'], kde=True, bins=20)
plt.title("Price Distribution") # 房价分布
plt.xlabel("Price") # 房价
plt.ylabel("Frequency") # 频数
plt.show()
运行结果:
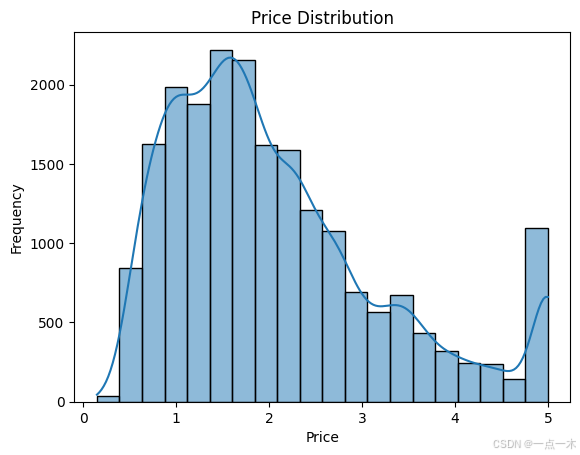
(3) 相关性分析
# 绘制特征相关性热力图
plt.figure(figsize=(10, 8))
sns.heatmap(data.corr(), annot=True, cmap='coolwarm')
plt.title("Feature Correlation Heatmap") # 特征相关性热力图
plt.show()
运行结果:
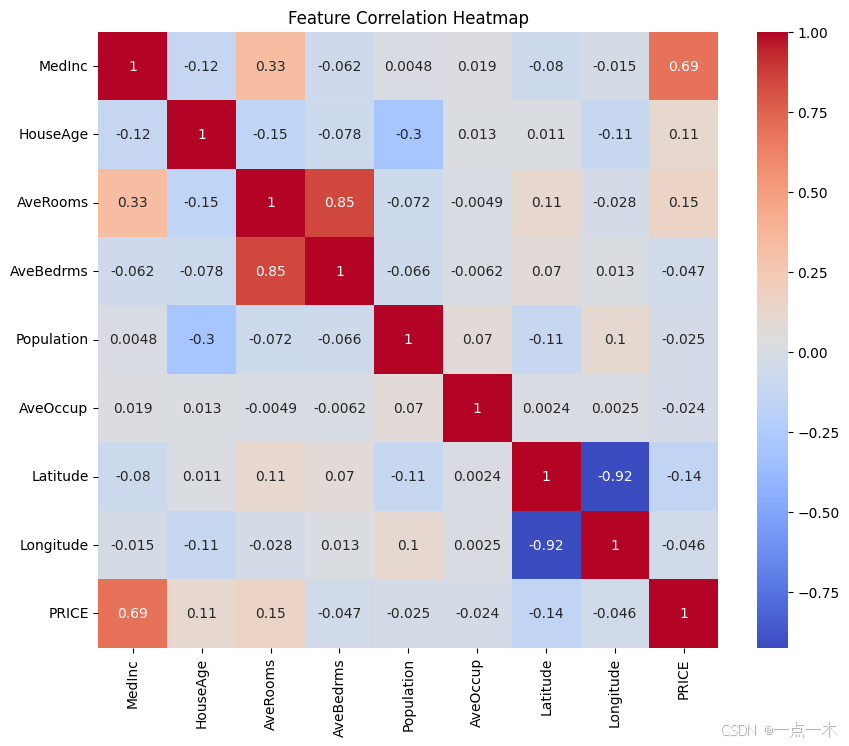
3.数据清洗与预处理
在训练模型之前,数据需要经过“加工”,以便让模型更高效地学习。常见的清洗与预处理步骤包括检查缺失值、处理异常值和标准化特征。
(1) 检查缺失值
# 检查缺失值
print(data.isnull().sum())
运行结果:

(2) 数据标准化
from sklearn.preprocessing import StandardScaler
# 特征标准化
scaler = StandardScaler()
features = data.drop('PRICE', axis=1)
target = data['PRICE']
features_scaled = scaler.fit_transform(features)
四、训练一个简单模型
我们从最基础的线性回归模型开始。尽管它不是“大模型”,但简单直观,可以帮助你快速了解 AI 模型的训练流程,并打下坚实的基础。
1.划分训练集和测试集
from sklearn.model_selection import 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











