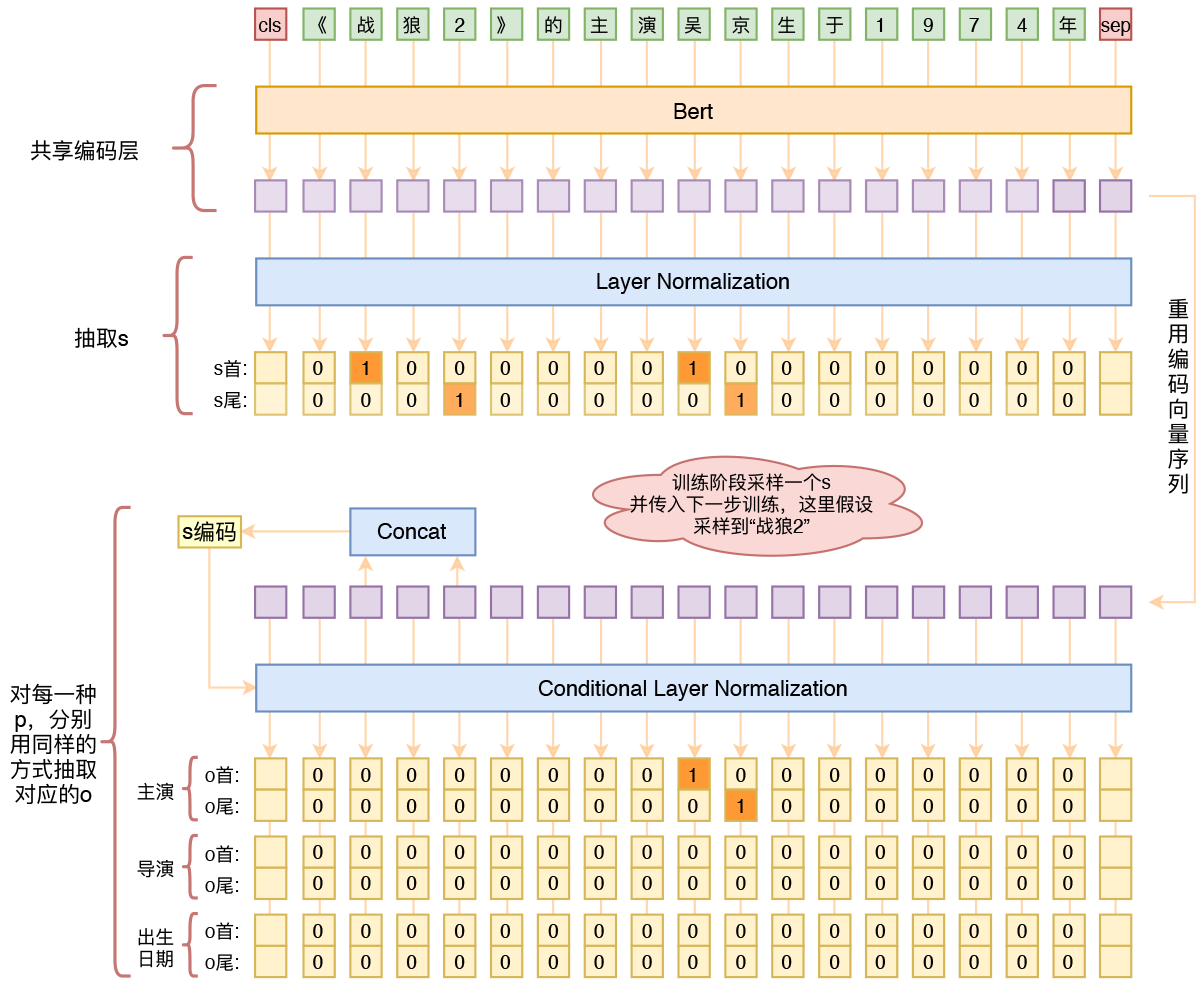
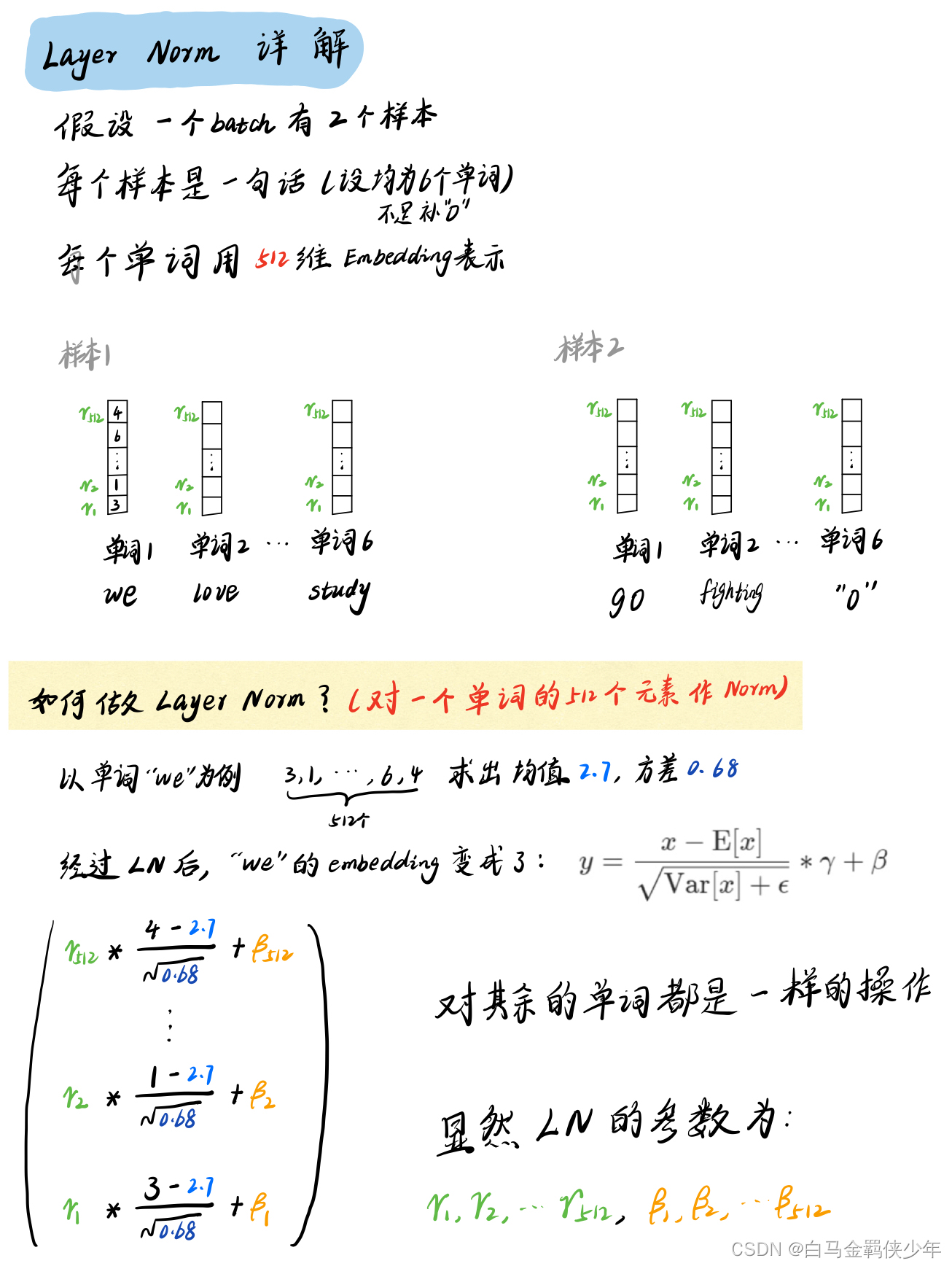
模型介绍 1、原始序列转id后,传入bert的编码器,得到编码序列; 2、编码序列接两个二分类器,预测s; 3、根据传入的s,从编码序列中抽取出s的首和尾对应的编码向量; 4、以s的编码向量作为条件,对编码序列做一次条件Layer Norm; 5、条件Layer Norm后的序列来预测该s对应的o、p Layer Norm : 进行归一化 条件Layer Norm 出现的问题 出现问题:抽取S,P,O时候类别不均衡,0太多1太少 解决方法:将概率值做n次方。 解决思路: 原来输出一个概率值p,代表类别1的概率是p,我现在将它变为 p n p^{n}








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5757
5757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






