








前言
在老学长的建议下,毕业后选择了自如,最近又经历了一次换房风波,这勾起了我的好奇心,在北京到底怎样租房才是最划算的,哪些地方属于“禁区”,哪些又是“宝地”,于是就想着挖一挖北京租房的一些小猫腻,为自己和将来要租房的人提供参考。今天就先看看北京哪些地区属于租房“禁区”。走~
数据准备
我们通过高德地图先获取了北京市五环线的最大外接矩形坐标,再利用自如提供的的数据接口,得到北京五环范围内790个小区的最低合租信息。其实他在地图上长这样:

这种看不到有用的信息,我们把五环内的所有数据放一块,再加工一下就变成了这样:
| 街道ID | 所在街道 | 最低价格 | 经度 | 纬度 |
|---|---|---|---|---|
| 1111030000000 | 佳世苑小区 | 1390 | 116.128533 | 39.723864 |
| 1111060000000 | 蓝光星华海悦城 | 1260 | 116.124636 | 39.732086 |
| 1184370000000 | 房山超级蜂巢 | 2790 | 116.129289 | 39.723603 |
| … | … | … | … | … |
| 数据下载,点这里 |
二、数据获取
- 利用网络数据通常需要找到可访问的数据地址,自如提供了地图数据服务,需要在点击请求中找到数据的请求地址,例如:
https://www.ziroom.com/map/room/listmin_lng=116.190081&max_lng=116.554003&min_lat=39.77811&max_lat=40.025685&zoom=18
- 找到后搜索结果一般如下:其中的包含关键的经纬度信息,之后只需要用代码整理请求结果(一般为JSON格式)就行。

1.数据获取源码
引入依赖:
import pandas as pd ##处理excel文件数据
import csv
import requests
import json
from tqdm import tqdm
## 北京市租房数据提取范围
min_lng=116.190081
min_lat=39.77811
max_lng=116.554003
max_lat=40.025685
获取总页数,自如通过页来控制显示条目数,每页展示20条数据:
## 请求地址
url='https://www.ziroom.com/map/room/list?min_lng={}&max_lng={}&min_lat={}&max_lat={}&zoom=18'.format(min_lng,max_lng,min_lat,max_lat)
## 发送请求,请求结果放入response,headers数据请求时的浏览器头文件,提供是模拟为浏览器请求
response = requests.get(url,headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'Referer':'https://www.ziroom.com/map/'
})
data_json =json.loads(response.text)
page = data_json['data']['pages']
page
##创建最后的csv结果文件
out = open('./北京/beijing.csv','a', newline='')
## 将结果文件执行为写入状态
csv_write = csv.writer(out,dialect='excel')
## 结果数据中写入第一行,第一行通常为表中各项题目,如 '名称','描述','价格'
csv_write.writerow(['名称','描述','价格','单位','地址','所在街道','街道ID'])
## 自如通过页来控制显示条目数,每页展示20条数据,需要通过遍历页码来得到所有数据
for i in range(page+1):
url='https://www.ziroom.com/map/room/list?min_lng={}&max_lng={}&min_lat={}&max_lat={}&zoom=18&p={}'.format(min_lng,max_lng,min_lat,max_lat,i)
response = requests.get(url,headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'Referer':'https://www.ziroom.com/map/'
})
data_json =json.loads(response.text)
## 将请求结果中需要的数据整理出来
for datajsons in data_json['data']['rooms']:
datajson = str(datajsons)
datajsoni = eval(datajson)
name=datajsoni['name']
desc=datajsoni['desc']
price=datajsoni['price']
price_unit=datajsoni['price_unit']
location=datajsoni['location'][0]['name']
resblock_name=datajsoni['resblock_name']
resblock_id =datajsoni['resblock_id']
string = [name,desc,price,price_unit,location,resblock_name,resblock_id]
## 逐行写入最后csv文件中
csv_write.writerow(string)
out.close()
利用天地图API对beijing.csv矢量化:
import pandas as pd
import urllib.parse
file_data = pd.read_excel('./北京/beijing.xlsx',sheet_name='beijing')
out = open('./北京/beijing.csv','a', newline='')
csv_write = csv.writer(out,dialect='excel')
csv_write.writerow(['名称','描述','价格','单位','地址','所在街道','街道ID','lon','lat'])
for index,data_each in file_data.iterrows():
url_poi='http://api.tianditu.gov.cn/geocoder?ds={/"keyWord/":/"北京市'+str(data_each[5])+str(data_each[4])+'/"}&tk=你的KEY'
response = requests.get(url_poi).text
data = eval(response)
if index >= 0:
print(index)
try:
location=data['location']
s=[data_each[0],data_each[1],data_each[2],data_each[3],data_each[4],data_each[5],data_each[6],location['lon'],location['lat']]
csv_write.writerow(s)
except:
s=[data_each[0],data_each[1],data_each[2],data_each[3],data_each[4],data_each[5],data_each[6],0,0]
csv_write.writerow(s)
out.close()
获取结果:
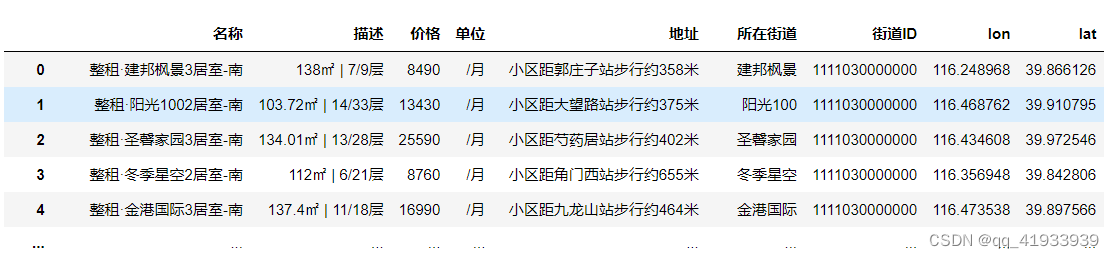
2.通过GIS软件处理矢量数据
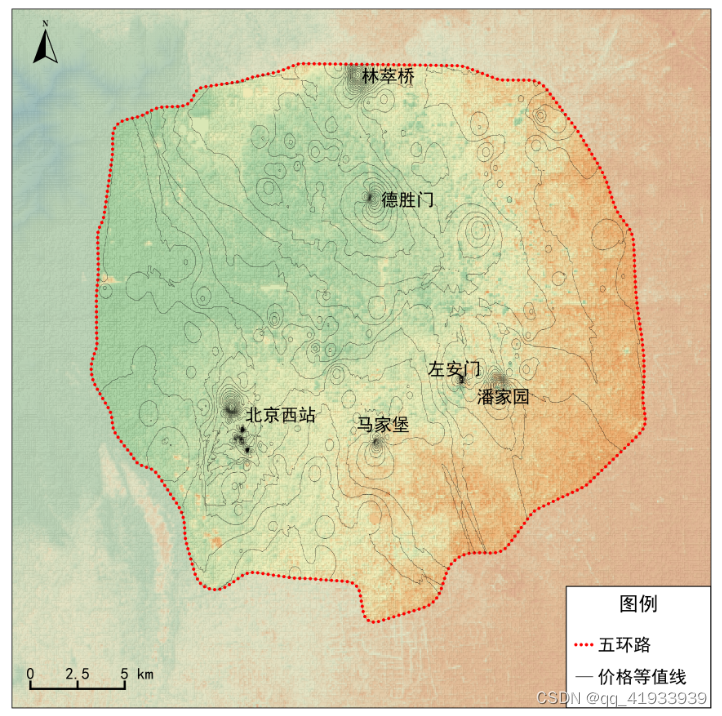
有了价格数据和坐标信息,就可以利用GIS工具进行处理,得到最终的价格分布图:
总结
根据自如数据显示,北京租房价格最高区域大致分布在北京西站、马家堡、潘家园、得胜门、林崒桥。可以看出这五个地区较周边区域价格抬升过快,以后不能在这附近租房了,图中红绿颜色仅代表地形,还有部分低价后续探索。

















 1126
1126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











