







切割数据
Paddleocr/PPOCRLabel/gen_ocr_train_val_test.py;切割后的数据在train_data中,注意切割后的数据前缀默认是当前目录,因此建议切割数据在liunx中进行。建议在liunx中指定
python gen_ocr_train_val_test.py --datasetRootPath==XX
或者修改下面--datasetRootPath中的default
if __name__ == "__main__":
# 功能描述:分别划分检测和识别的训练集、验证集、测试集
# 说明:可以根据自己的路径和需求调整参数,图像数据往往多人合作分批标注,每一批图像数据放在一个文件夹内用PPOCRLabel进行标注,
# 如此会有多个标注好的图像文件夹汇总并划分训练集、验证集、测试集的需求
parser = argparse.ArgumentParser()
parser.add_argument(
"--trainValTestRatio",
type=str,
default="8:2:0",
help="ratio of trainset:valset:testset")
parser.add_argument(
"--datasetRootPath",
type=str,
default="./xia/",
help="需要切割的数据path to the dataset marked by ppocrlabel, E.g, dataset folder named 1,2,3..."
)
parser.add_argument(
"--detRootPath",
type=str,
default="../train_data/det",
help="the path where the divided detection dataset is placed")
parser.add_argument(
"--recRootPath",
type=str,
default="../train_data/rec",
help="the path where the divided recognition dataset is placed"
)
parser.add_argument(
"--detLabelFileName",
type=str,
default="Label.txt",
help="the name of the detection annotation file")
parser.add_argument(
"--recLabelFileName",
type=str,
default="rec_gt.txt",
help="the name of the recognition annotation file"
)
parser.add_argument(
"--recImageDirName",
type=str,
default="crop_img",
help="the name of the folder where the cropped recognition dataset is located"
)如果在Win中切割,放入liunx中训练。前缀可能如下
常见的Liunx命令
切换路径:cd /路径
编辑或者创建文档:vim
仅退出vim,先按ESC,再shift+:,在底部看到:,输入q或者q!
改动完退出vim,先按ESC,再shift+:,在底部看到:,输入wq
复制文件:单个文件:cp XXX YYY ;文件夹:cp -rf XXX YYY
删除文件:rm -rf XXX
det
训练
1、打开tmux窗口启动,这样断开连接后台可以继续训练
2、根据需求修改配置文件,如输出名称,数据集位置,注意暂时不要改吧epoch,训练容易报错
shell命令如下,创建和修改shell后需要
创建:vim XXX.sh
修改权限:chmod +x XXX.sh
#首先使用该命令打开tmux窗口: tmux attach -t my_session_name
#根据任务修改configs
python3 -m paddle.distributed.launch --gpus '0' tools/train.py
-c ./configs/det/ch_PP-OCRv4/训练使用的配置文件.yml
-o Global.pretrained_model=./pretrain_models/PPHGNet_small_ocr_det.pdparams推理
python3 tools/export_model.py
-c ./configs/det/ch_PP-OCRv4/训练使用的配置文件.yml
-o Global.pretrained_model=./output/训练输出文件夹名称/best_accuracy
Global.save_inference_dir=./inference/输出文件夹名称/ 配置文件位置:/data/ocr/PaddleOCR-2.7.5/configs/det
#使用命令修改配置文件
#-o参数在不需要修改yml文件的情况下,改变训练的参数,比如,调整训练的学习率为0.0001
python3 tools/train.py -c configs/det/det_mv3_db.yml
-o Optimizer.base_lr=0.0001也可以直接修改额配置文件,如/data/ocr/PaddleOCR-2.7.5/configs/det/ch_PP-OCRv4/ch_PP-OCRv4_det_teacher.yml
修改训练得到模型地址
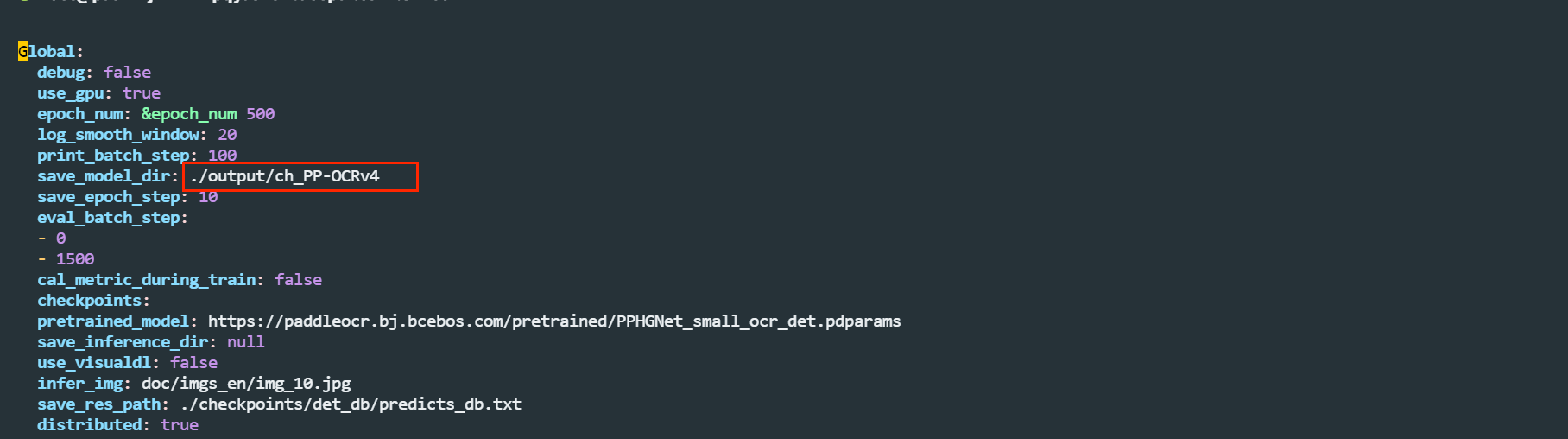
修改数据集:


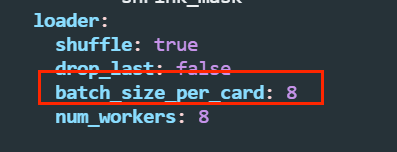
修改batch_size:
Rec:
训练
# tmux attach -t my_session_name
python3 -m paddle.distributed.launch --gpus '0' tools/train.py
-c configs/rec/PP-OCRv4/配置文件.yml
-o
Global.pretrained_model=./pretrain_models/en_PP-OCRv4_rec_train/best_accuracy配置文件位置:/data/ocr/PaddleOCR-2.7.5/configs/rec
推理
python3 tools/export_model.py
-c configs/rec/PP-OCRv4/训练配置文件.yml
-o Global.pretrained_model=/data/ocr/PaddleOCR-2.7.5/output/训练输出文件夹/best_model/model
Global.save_inference_dir=./inference/推理输出文件夹/














 1712
1712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









