







栈内存和堆内存
- 内存中的栈区与堆区:
一般说到内存,指的是计算机的随机储存器(RAM),程序都在这里面运行。计算机内存的大致划分如下图所示:
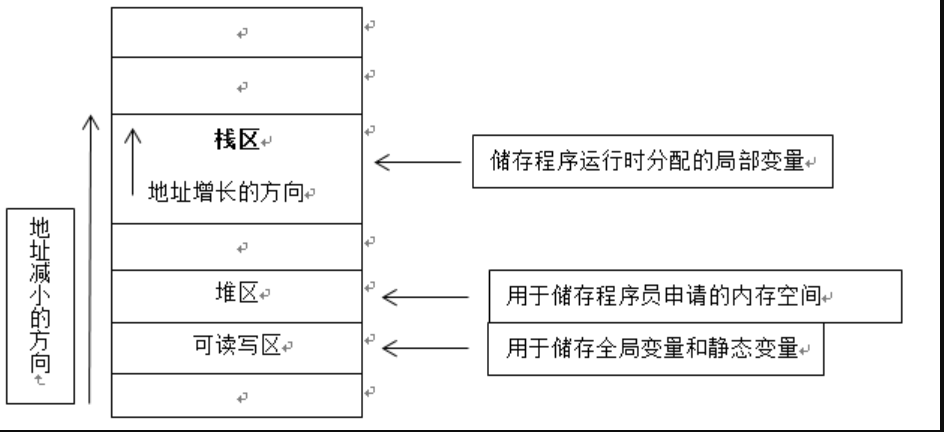
####* 栈内存:由程序自动向操作系统申请分配以及回收,程序启动时统一分配此后不能再扩大,决定了递归深度有上限,但是C/C++一般情况下递归上万次是可以的,速度快,使用方便,但程序员无法控制。若分配失败,则提示栈溢出错误。栈区向地址减小的方向增长,const局部变量也储存在栈区内,主调函数所拥有的局部变量等信息存在堆栈中
//测试栈内存
#include <iostream>
int main()
{
int i = 10; //变量i储存在栈区中
const int i2 = 20;
int i3 = 30;
std::cout << &i << " " << &i2 << " " << &i3 << std::endl;
return 0;
}
测试输出为:

&i3 < &i2 < &i,证明地址是减小的。
- 堆内存:程序员向操作系统申请一块内存,当系统收到程序的申请时,会遍历一个记录空闲内存地址的链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。分配的速度较慢,地址不连续,容易碎片化。此外,由程序员申请,同时也必须由程序员负责销毁,否则则导致内存泄露。使用new/malloc进行分配的空间称为堆,全局变量保存在堆中,申请巨大数组时与放置在栈中相比,将其放在堆中可以减少栈溢出的危险
//测试堆内存和栈内存的区别
#include <iostream>
int main()
{
int i = 10; //变量i储存在栈区中
char pc[] = "hello!"; //储存在栈区
const double cd = 99.2; //储存在栈区
static long si = 99; //si储存在可读写区,专门用来储存全局变量和静态变量的内存
int* pi = new int(100); //指针pi指向的内存是在 堆区,专门储存程序运行时分配的内存
std::cout << &i << " " << &pc << " " << &cd << " " << &si << " " << pi << std::endl;
delete pi; //需程序员自己释放
return 0;
}
测试输出为:

运行多次后会发现pi所指向的地址并不连续,是跳跃式的;而&si是一致的,储存在可读写区;前三个变量都储存在栈区,由程序自动分配和销毁。
小心内存泄漏
1)配对使用,有一个malloc,就应该有一个free。(C++中对应为new和delete)
2) 尽量在同一层上使用,不要malloc在函数中,而free在函数外。最好在同一调用层上使用这两个函数。
3) malloc分配的内存一定要初始化。free后的指针一定要设置为NULL。
- 申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,由编译器决定栈的大小(一般1M/2M),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
关于堆和栈区别的比喻:
堆和栈的区别可以引用一位前辈的比喻来看出:
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。
[1]: https://images2015.cnblogs.com/blog/928019/201607/928019-20160719170222107-1820485296.png
[2]: https://i-blog.csdnimg.cn/blog_migrate/57f085dadcd93c90922a8e9a265c6329.png
[3]: https://i-blog.csdnimg.cn/blog_migrate/a9ea82a177a30d60ce81a815a07289b2.png















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}