







日志文件
日志文件是用于记录系统操作事件的文件集合。
日志文件它具有处理历史数据、诊断问题的追踪以及理解系统的活动等重要的作用。
日志种类
调试日志
调试程序,或者做一些状态的输出,便于我们查询程序的运行状况。为了让我们能够更加灵活且方便的控制这些调试信息,我们肯定是需要更加专业的日志技术。我们平时在调试程序的过程中所使用的肯定就是专业开发工具自带的debug 功能,可以实时查看程序运行情况,不能够有效保存运行情况的信息。调试日志是能够更加方便的去“重现”这些问题。
系统日志
系统日志是用来记录系统中硬件、软件和系统相关问题的信息。同时还可以监视系统中发生的事件。用户可以通过它来检查错误发生的原因,或者寻找收到攻击是留下的痕迹。
系统日志包括系统日志、应用日志和安全日志这几种分类。
日志框架及作用
日志作用
- 控制日志输出的内容和格式。
- 控制日志输出的位置。
- 日志文件相关的优化,如异步操作、归档、压缩
- 日志系统的维护
- 面向接口开发-日志的门面
目前日志框架
日志门面:为了将各个服务框架中自带的日志进行统一门面处理,使用门面技术。
- JCL (Jakarta Commons Logging)
- slf4j ( Simple Logging Facade for Java)
日志实现:
- JUL--JDK自带的原生日志框架,不需要导入第三方依赖。在java.util.logging
- Log4j--Apache开源项目,性能问题,Apache公司已经停止维护
- logback--与Log4j同一人开发,吸收Log4j优点,且可靠、通用,灵活,springboot2.0以后默认使用
- log4j2--利用logback优势特征,在log4j基础上改进为log4j2版本,springboot1.4以后支持log4j2,目前性能最好的日志框架
日志门面与日志实现区别:
- 日志框架技术:JUL、Log4j、log4j2、logback,用来记录日志信息
- 日志门面技术:JCL、slf4j,用来解决 应用程序 在使用各种日志框架对应API时候导致的耦合性,因此提出一套门面技术,开发人员只需调用门面接口即可。
JUL(了解)
1、简介
全程Java Util Logging,它是java原生的日志框架,使用时不需要另外引用第三方的类库,相对其他的框架使用方便,学习简单,主要是使用在小型应用中。
2、组件及介绍
- Logger:被称为记录器,应用程序通过获取Logger对象,抵用其API来发布日志信息。Logger通常被认为是访问日志系统的入口程序。
- Handler:处理器,每个Logger都会关联一个或者是一组 Handler,Logger 会将日志交给关联的Handler去做处理,由Handler 负责将日志做记录。Handler具体实现了日志的输出位置,比如可以输出到控制台或者是文件中等等。
- Filter:过滤器,根据需要定制哪些信息会被记录,哪些信息会被略过。
- Formatter:格式化组件,它负责对日志中的数据和信息进行转换和格式化,所以它决定了我们输出日志最终的形式。
- Level:日志的输出级别,每条日志消息都有一个关联的级别。我们根据输出级别的设置,用来展现最终所呈现的日志信息。根据不同的需求,去设置不同的级别。
3、入门代码
public class TestJUL {
public static void main(String[] args) {
/**
* 日志入口程序
* Java.util.logging.Logger
*/
//Logger对象的创建方式,不能直接new对象
//取符对象的方法参数,需要引入当前类的全路径字符串(当前我们先这么用,以后根据包结构有Logger父子关系,以后详细介绍)
Logger logger = Logger.getLogger("com.hweadee.logger.TestJUL");
/**
* 日志输出的两种方式
*/
// 方式一:使用info方法
logger.info("hello JUL");
// 方式二:使用log方法
logger.log(Level.INFO, "hello JUL");
logger.log(Level.INFO, "user info id={0},name={1}", new Object[]{"xiatain", 32});
}
}Log4j
1、简介
Log4j是Apache下的一款开源的日志框架,通过在项目中使用Log4J,我们可以控制日志信息输出到控制台、文件、数据库、GUI组件,甚至是套接口服务器、NT的事件记录器、UNIX Syslog 守护进程等;
最令人感兴趣的就是,这些可以通过一个配置文件来灵活地进行配置,而不需要修改应用的代码。
2、日志级别
日志的输出都是分级别的,当一条日志信息的级别大于或等于配置文件的级别时,就对这条日志进行记录。常见的日志级别如下(优先级依次升高)。
| 序号 | 日志级别 | 说明 |
|---|---|---|
| 1 | trace | 追踪,指明程序运行轨迹。迫踪信息,记录程序所有的流程信息 |
| 2 | debug | 调试,实际应用中一般将其作为最低级别,而 trace 则很少使用,一般在开发中使用,记录程序变量参数传递信息等等 |
| 3 | info | 输出重要的运行信息,数据连接、网络连接、IO操作等等,使用较多 |
| 4 | warn | 警告信息,可能会发生问题,使用较多 |
| 5 | error | 错误信息,不会影响系统运行,使用较多 |
| 6 | fatal | 严重错误,一般会造成系统崩溃并终止运行,很少使用 |
3、入门案例
在pom文件中引入Junit的jar包和log4j的jar包
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>public class Log4jTest {
@Test
public void test() {
//初始化配置信息,在入门案例中暂不使用配置文件
BasicConfigurator.configure();
//获取日志记录器对象
Logger logger = Logger.getLogger(String.valueOf(Log4jTest.class));
//日志级别
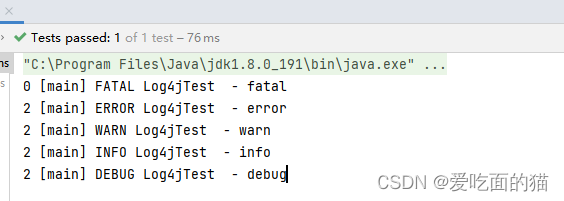
logger.fatal("fatal");//严重错误,一般会造成系统崩溃并终止运行
logger.error("error"); // 错误信息,不会影响系统运行
logger.warn("warn");//警告信息,可能会发生问题
logger.info("info");// 运行信息,数据连接、网络连接、I0操作等等
logger.debug("debug");// 调试信息,一般在开发中使用,记录程序变量参数传递信息等等
logger.trace("trace"); //追踪信息,记录程序所有的流程信息
}
}
4、组件介绍
Log4j主要由Loggers、Appenders、Layout组成。
- Loggers(日志记录器):控制日志的输出以及输出级别;
- Appenders(输出控制器):指定日志的输出方式(输出到控制台、文件等);
- Layout(日志格式化器):控制日志信息的输出格式。
01、Loggerse
- 日志记录器,负责收集处理日志记录,实例的命名就是类的全限定名,如com.bjpowernode.log4j.XX;
- Logger的名字大小写敏感,其命名有继承机制:例如: name为com.bjpowernode.log4j 的 logger会继承name为 com.bjpowernode。
- Log4J中有一个特殊的 logger 叫做"root",他是所有 logger 的根,也就意味着其他所有的 logger都会直接或者间接地继承自root。
- root logger可以用Logger.getRootLogger()方法获取。
- 自 log4j1.2 版以来,Logger类已经取代了Category类。对于熟悉早期版本的log4j的人来说,Logger类可以被视为Category类的别名。
Logger root = Logger.getRootLogger();
Logger log = Logger.getLogger("root");
System.out.println(log==root); //false 说明root无法通过name获取
Logger log2 = Logger.getLogger("root");
System.out.println(log==log2); //true,说明一个name唯一对应一个logger
02、Appender
用来指定日志输出到哪个地方,可以同时指定日志的输出目的地。Log4j常用的输出目的地有以下几种:
| 输出端类型 | 作用 |
|---|---|
| ConspleAppender | 将日志输出到控制台 |
| FileAppender | 将日志输出到文件中 |
| DailyRollingFileAppender | 将日志输出到一个日志文件,并且每天输出到一个新的文件 |
| RollingFileAppender | 将日志信息输出到一个日志文件,并且指定文件的尺寸,当文件大小达到指定 尺寸时,会自动把文件改名,同时产生一个新的文件 |
| JDBCAppender | 把日志信息保存到数据库中 |
03、Layouts
布局器Layouts用于控制日志输出内容的格式,让我们可以使用各种需要的格式输出日志。Log4j常用的Lavouts:
| 格式化器类型 | 作用 |
|---|---|
| HTMLLayout | 格式化日志输出为HTML表格形式 |
| SimpleLayout | 简单的日志输出格式化,打印的默认info级别消息,日志格式为(info - message) |
| PatternLayout | 最强大的格式化期,可以根据自定义格式输出日志,如果没有指定转换格式,就是用默认的转换格式 |
| XMLlLayout | 格式化日志输出为XML表格形式 |
ConversionPattern参数的格式含义:
格式名 含义
%c 输出日志信息所属的类目,通常就是所在类的全名
%d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyy MMM dd HH:mm:ss,SSS},输出类似:2002年10月18日 22:10:28,921
%f 输出日志消息产生时所在的文件名称
%l 输出日志事件的发生位置,相当于%C.%M(%F:%L)的组合,包括类目名、发生的线程,以及在代码中的行数。举例:Testlog4.main (TestLog4.java:10)
%m 输出代码中指定的消息,产生的日志具体信息
%n 输出一个回车换行符,Windows平台为"\r\n",Unix平台为"\n"输出日志信息换行
%p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL。如果是调用debug()输出的,则为DEBUG,依此类推
%r 输出自应用启动到输出该log信息耗费的毫秒数
%t 输出产生该日志事件的线程名
%x: 输出和当前线程相关联的NDC(嵌套诊断环境),尤其用到像java servlets这样的多客户多线程的应用中。
%%: 输出一个"%"字符
可以在%与模式字符之间加上修饰符来控制其最小宽度、最大宽度、和文本的对齐方式。
1)%20c:指定输出category的名称,最小的宽度是20,如果category的名称小于20的话,默认的情况下右对齐。
2)%-20c:指定输出category的名称,最小的宽度是20,如果category的名称小于20的话,"-"号指定左对齐。
3)%.30c:指定输出category的名称,最大的宽度是30,如果category的名称大于30的话,就会将左边多出的字符截掉,但小于30的话也不会有空格。
4)%20.30c:如果category的名称小于20就补空格,并且右对齐,如果其名称长于30字符,就从左边较远输出的字符截掉。
04、使用log4j.properties配置文件
001、测试代码
public class Log4jTest {
@Test
public void test() {
// 设置内置日志启动,默认是false
LogLog.setInternalDebugging(true);
//获取日志记录器对象
Logger logger = Logger.getLogger(Log4jTest.class);
//日志级别
logger.fatal("fatal");//严重错误,一般会造成系统崩溃并终止运行
logger.error("error"); // 错误信息,不会影响系统运行
logger.warn("warn");//警告信息,可能会发生问题
logger.info("info");// 运行信息,数据连接、网络连接、I0操作等等
logger.debug("debug");// 调试信息,一般在开发中使用,记录程序变量参数传递信息等等
logger.trace("trace"); //追踪信息,记录程序所有的流程信息
}
}002、配置log4j.properties
在resources下面创建一个log4j.properties,以输出到 控制台 为例,
- 输出消息格式为:SimpleLayout , 配置内容 及 运行结果 如下:
# 配置 Root 顶级父元素
# 指定日志输出级别为=debug ,使用的appender即输出目标为=console
log4j.rootLogger = debug,console
# 指定 控制台日志 输出的 appender
log4j.appender.console = org.apache.log4j.ConsoleAppender
# 指定 消息格式
log4j.appender.console.layout = org.apache.log4j.SimpleLayout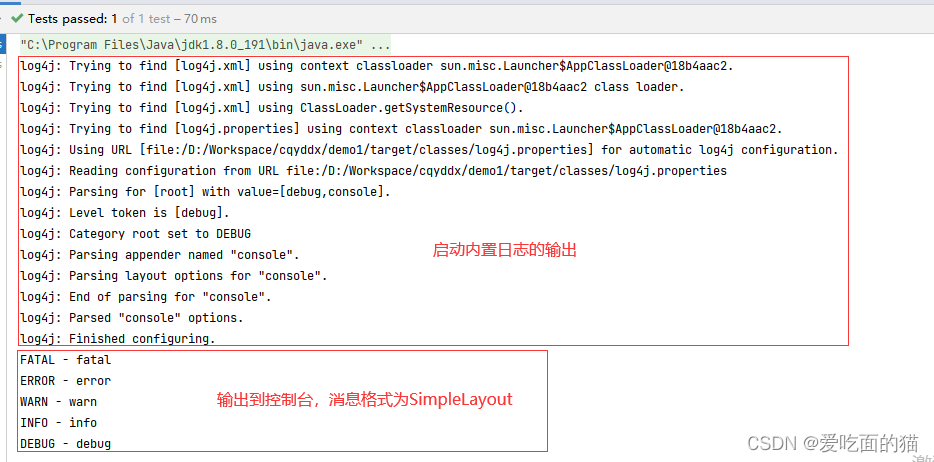
- 输出消息格式为:XMLLayout , 配置内容 及 运行结果 如下:
# 配置 Root 顶级父元素
# 指定日志输出级别为=debug ,使用的appender即输出目标为=console
log4j.rootLogger = debug,console
# 指定 控制台日志 输出的 appender
log4j.appender.console = org.apache.log4j.ConsoleAppender
# 指定 消息格式
log4j.appender.console.layout = org.apache.log4j.XMLLayout
- 输出消息格式为:HTMLLayout , 配置内容 及 运行结果 如下:
# 配置 Root 顶级父元素
# 指定日志输出级别为=debug ,使用的appender即输出目标为=console
log4j.rootLogger = debug,console
# 指定 控制台日志 输出的 appender
log4j.appender.console = org.apache.log4j.ConsoleAppender
# 指定 消息格式
log4j.appender.console.layout = org.apache.log4j.HTMLLayout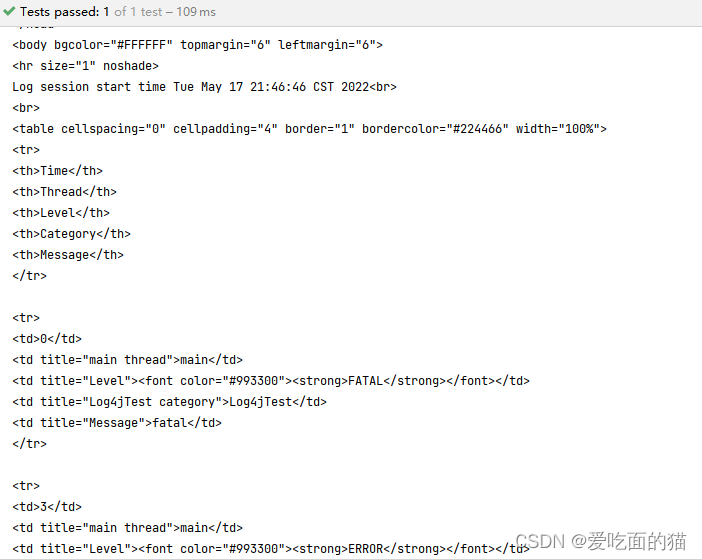

- 输出消息格式为:自定义 PatternLayout , 配置内容 及 运行结果 如下:
# 配置 Root 顶级父元素
# 指定日志输出级别为=debug ,使用的appender即输出目标为=console
log4j.rootLogger = debug,console
# 指定 控制台日志 输出的 appender
log4j.appender.console = org.apache.log4j.ConsoleAppender
# 指定 消息格式
log4j.appender.console.layout = org.apache.log4j.PatternLayout
# 指定 消息格式的内容 %p:消息级别、%r:消息用的时间、
# %c:类全名、%t:线程名、%F:文件名 %L:行号
# [%p]%r %c %t %F %L %d{yyyy-MM-dd HH:mm:ss} = [%p]%r %l %d{yyyy-MM-dd HH:mm:ss}
log4j.appender.console.layout.conversionPattern= [%p]%r %l %d{yyyy-MM-dd HH:mm:ss} %m%n
#日志立即输出,不用缓冲,默认为true
log4j.appender.rollingFile.ImmediateFlush=true
#因为是文件,所以会有追加的动作,控制是否追加,还是覆盖,默认为true
log4j.appender.rollingFile.Append=true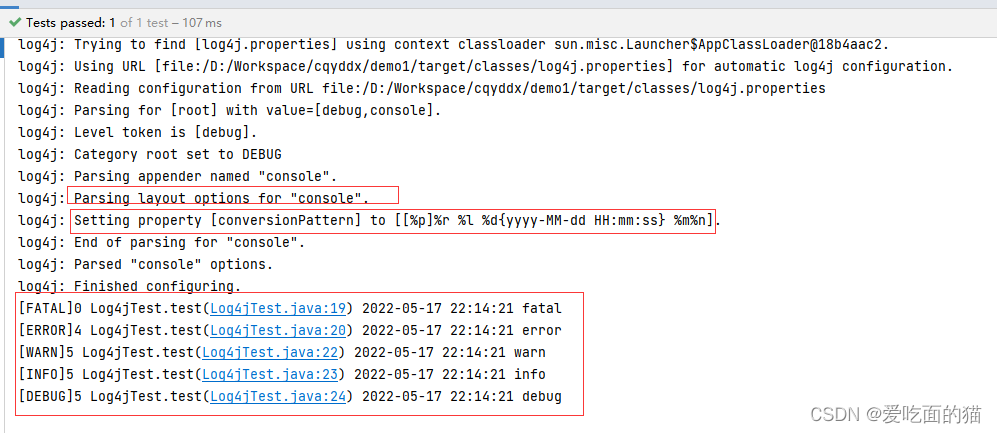
003、配置输出到文件
在resources下面创建一个log4j.properties,代码如下:
# 配置 Root 顶级父元素 # 指定日志输出级别为=debug ,使用的appender为=console、file、 log4j.rootLogger = debug,console,file # 指定 控制台日志 输出的 appender log4j.appender.console = org.apache.log4j.ConsoleAppender # 指定 消息格式 log4j.appender.console.layout = org.apache.log4j.PatternLayout # 指定 消息格式的内容 %p:消息级别、%r:消息用的时间、 # %c:类全名、%t:线程名、%F:文件名 %L:行号 # [%p]%r %c %t %F %L %d{yyyy-MM-dd HH:mm:ss} = [%p]%r %l %d{yyyy-MM-dd HH:mm:ss} log4j.appender.console.layout.conversionPattern = [%p]%r %l %d{yyyy-MM-dd HH:mm:ss} %m%n # 指定 日志文件 输出的 appender log4j.appender.file = org.apache.log4j.FileAppender # 指定 消息格式 log4j.appender.file.layout = org.apache.log4j.PatternLayout # 指定 消息格式的内容 log4j.appender.file.layout.conversionPattern = [%p]%r %l %d{yyyy-MM-dd HH:mm:ss} %m%n # 指定 消息日志文件保存的路径 log4j.appender.file.file = ./logs/log4j.log # 指定 消息日志文件的字符集 log4j.appender.file.encoding = UTF-8
运行结果如图: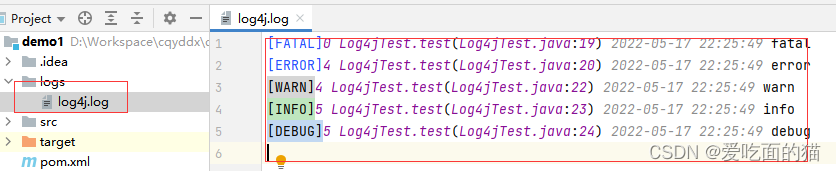
004、配置输出到数据库
添加数据库依赖:
<dependencies>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.17</version>
</dependency>
</dependencies>
在resources下面创建一个log4j.properties,代码如下:
# 配置 Root 顶级父元素 # 指定日志输出级别为=debug ,使用的appender为=console、file、 log4j.rootLogger = debug,console,file,logDB # 指定 控制台日志 log4j.appender.console = org.apache.log4j.ConsoleAppender # 指定 消息格式 log4j.appender.console.layout = org.apache.log4j.PatternLayout # 指定 消息格式的内容 %p:消息级别、%r:消息用的时间、 # %c:类全名、%t:线程名、%F:文件名 %L:行号 # [%p]%r %c %t %F %L %d{yyyy-MM-dd HH:mm:ss} = [%p]%r %l %d{yyyy-MM-dd HH:mm:ss} log4j.appender.console.layout.conversionPattern = [%p]%r %l %d{yyyy-MM-dd HH:mm:ss} %m%n # 指定 日志文件 输出的 appender log4j.appender.file = org.apache.log4j.FileAppender # 指定 消息格式 log4j.appender.file.layout = org.apache.log4j.PatternLayout # 指定 消息格式的内容 log4j.appender.file.layout.conversionPattern = [%p]%r %l %d{yyyy-MM-dd HH:mm:ss} %m%n # 指定 消息日志文件保存的路径 log4j.appender.file.file = ./logs/log4j.log # 指定 消息日志文件的字符集 log4j.appender.file.encoding = UTF-8 # 指定 日志文件 输出到数据库Mysql log4j.appender.logDB = org.apache.log4j.jdbc.JDBCAppender log4j.appender.logDB.layout = org.apache.log4j.PatternLayout log4j.appender.logDB.Driver = com.mysql.cj.jdbc.Driver log4j.appender.logDB.URL = jdbc:mysql://localhost:3306/cqyddx?useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true&useSSL=false&serverTimezone=Asia/Shanghai log4j.appender.logDB.User = root log4j.appender.logDB.Password = root log4j.appender.logDB.Sql = INSERT INTO log(project_name, create_date, LEVEL, category, file_name, thread_name, line, all_category, message) \ VALUES ('itcast', '%d{yyyy-MM-dd HH:mm:ss}', '%p', '%c', '%F', '%t', '%L', '%l', '%m');
创建数据库表格:
CREATE TABLE log(
log_id INT ( 11 ) NOT NULL AUTO_INCREMENT,
project_name VARCHAR ( 255 ) DEFAULT NULL COMMENT '目项名',
create_date VARCHAR ( 255 ) DEFAULT NULL COMMENT '创建时间',
level VARCHAR ( 255 ) DEFAULT NULL COMMENT '优先级',
category VARCHAR ( 255 ) DEFAULT NULL COMMENT '所在类的全名',
file_name VARCHAR ( 255 ) DEFAULT NULL COMMENT '输出日志消息产生时所在的文件名称',
thread_name VARCHAR ( 255 ) DEFAULT NULL COMMENT '日志事件的线程名',
line VARCHAR ( 255 ) DEFAULT NULL COMMENT '号行',
all_category VARCHAR ( 255 ) DEFAULT NULL COMMENT '日志事件的发生位置',
message VARCHAR ( 4000 ) DEFAULT NULL COMMENT '输出代码中指定的消息',
PRIMARY KEY ( log_id )
);
运行结果如图:
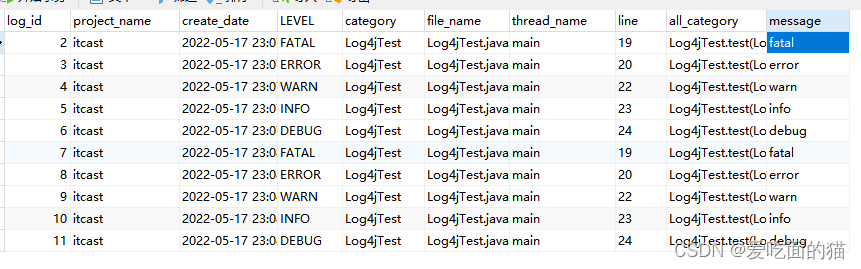
005、按频率(时间)生成日志文件
ailyRollingFileAppender是日志记录软件包Log4J中的一个Appender,它能够按一定的频度滚动日志记录文件。DatePattern选项的有效值为:
- '.'yyyy-MM,对应monthly(每月)
- '.'yyyy-ww,对应weekly(每周)
- '.'yyyy-MM-dd,对应daily(每天)
- '.'yyyy-MM-dd-a,对应half-daily(每半天)
- '.'yyyy-MM-dd-HH,对应hourly(每小时)
- '.'yyyy-MM-dd-HH-mm,对应minutely(每分钟)
在resources下面创建一个log4j.properties,代码如下:
# 配置 Root 顶级父元素 # 指定日志输出级别为=debug ,使用的appender为=console、file、dailyFile log4j.rootLogger = debug,console,file,logDB,dailyFile # 指定 控制台日志 log4j.appender.console = org.apache.log4j.ConsoleAppender # 指定 消息格式 log4j.appender.console.layout = org.apache.log4j.PatternLayout # 指定 消息格式的内容 %p:消息级别、%r:消息用的时间、 # %c:类全名、%t:线程名、%F:文件名 %L:行号 # [%p]%r %c %t %F %L %d{yyyy-MM-dd HH:mm:ss} = [%p]%r %l %d{yyyy-MM-dd HH:mm:ss} log4j.appender.console.layout.conversionPattern = [%p]%r %l %d{yyyy-MM-dd HH:mm:ss} %m%n # 指定 日志文件 输出的 appender log4j.appender.file = org.apache.log4j.FileAppender # 指定 消息格式 log4j.appender.file.layout = org.apache.log4j.PatternLayout # 指定 消息格式的内容 log4j.appender.file.layout.conversionPattern = [%p]%r %l %d{yyyy-MM-dd HH:mm:ss} %m%n # 指定 消息日志文件保存的路径 log4j.appender.file.file = ./logs/log4j.log # 指定 消息日志文件的字符集 log4j.appender.file.encoding = UTF-8 # 指定 日志文件 输出到数据库Mysql log4j.appender.logDB = org.apache.log4j.jdbc.JDBCAppender log4j.appender.logDB.layout = org.apache.log4j.PatternLayout log4j.appender.logDB.Driver = com.mysql.cj.jdbc.Driver log4j.appender.logDB.URL = jdbc:mysql://localhost:3306/cqyddx?useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true&useSSL=false&serverTimezone=Asia/Shanghai log4j.appender.logDB.User = root log4j.appender.logDB.Password = root log4j.appender.logDB.Sql = INSERT INTO log(project_name, create_date, LEVEL, category, file_name, thread_name, line, all_category, message) \ VALUES ('itcast', '%d{yyyy-MM-dd HH:mm:ss}', '%p', '%c', '%F', '%t', '%L', '%l', '%m'); #按照时间规则拆分的appender对象 log4j.appender.dailyFile = org.apache.log4j.DailyRollingFileAppender #指定消息格式layout log4j.appender.dailyFile.layout = org.apache.log4j.PatternLayout #指定消息格式的内容 log4j.appender.dailyFile.layout.conversionPattern = [%-10p]%r %l %d{yyyy-MM-dd HH:mm:ss.SSS] %m%n #指定日志文件保存路径 log4j.appender.dailyFile.file = ./logs/dailyFile.log #指定日志文件的字符集 log4j.appender.dailyFile.encoding = UTF-8 #指定日期拆分规则,按照指定格式拆分(即按月、周、天、小时等拆封,并文件命名也以此方式命名,此处以秒为案例。实际过程中都是以天或周以上的为主) log4j.appender.dailyFile.datePattern = '.'yyyy-MM-dd-HH-mm-ssy运行结果截图:
测试代码:
public class Log4jTest {
@Test
public void test() {
//获取日志记录器对象
Logger logger = Logger.getLogger(Log4jTest.class);
for (int i = 0; i < 100000; i++) {
//日志级别
logger.fatal("fatal");//严重错误,一般会造成系统崩溃并终止运行
logger.error("error"); // 错误信息,不会影响系统运行
logger.warn("warn");//警告信息,可能会发生问题
logger.info("info");// 运行信息,数据连接、网络连接、I0操作等等
logger.debug("debug");// 调试信息,一般在开发中使用,记录程序变量参数传递信息等等
logger.trace("trace"); //追踪信息,记录程序所有的流程信息
}
}
}
运行结果截图
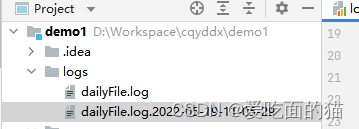
006、磁盘文件滚动输出日志
测试代码:
public class Log4jTest {
@Test
public void test() {
//获取日志记录器对象
Logger logger = Logger.getLogger(Log4jTest.class);
for (int i = 0; i < 100000; i++) {
//日志级别
logger.fatal("fatal");//严重错误,一般会造成系统崩溃并终止运行
logger.error("error"); // 错误信息,不会影响系统运行
logger.warn("warn");//警告信息,可能会发生问题
logger.info("info");// 运行信息,数据连接、网络连接、I0操作等等
logger.debug("debug");// 调试信息,一般在开发中使用,记录程序变量参数传递信息等等
logger.trace("trace"); //追踪信息,记录程序所有的流程信息
}
}
}在resources下面创建一个log4j.properties,代码如下:配置文件
# 配置 Root 顶级父元素 # 指定日志输出级别为=debug ,使用的appender为=console、file、dailyFile,rollingFile # log4j.rootLogger = debug,console,file,logDB,dailyFile,rollingFile log4j.rootLogger = debug,rollingFile # 指定 控制台日志 log4j.appender.console = org.apache.log4j.ConsoleAppender # 指定 消息格式 log4j.appender.console.layout = org.apache.log4j.PatternLayout # 指定 消息格式的内容 %p:消息级别、%r:消息用的时间、 # %c:类全名、%t:线程名、%F:文件名 %L:行号 # [%p]%r %c %t %F %L %d{yyyy-MM-dd HH:mm:ss} = [%p]%r %l %d{yyyy-MM-dd HH:mm:ss} log4j.appender.console.layout.conversionPattern = [%p]%r %l %d{yyyy-MM-dd HH:mm:ss} %m%n # 指定 日志文件 输出的 appender log4j.appender.file = org.apache.log4j.FileAppender # 指定 消息格式 log4j.appender.file.layout = org.apache.log4j.PatternLayout # 指定 消息格式的内容 log4j.appender.file.layout.conversionPattern = [%p]%r %l %d{yyyy-MM-dd HH:mm:ss} %m%n # 指定 消息日志文件保存的路径 log4j.appender.file.file = ./logs/log4j.log # 指定 消息日志文件的字符集 log4j.appender.file.encoding = UTF-8 # 指定 日志文件 输出到数据库Mysql log4j.appender.logDB = org.apache.log4j.jdbc.JDBCAppender log4j.appender.logDB.layout = org.apache.log4j.PatternLayout log4j.appender.logDB.Driver = com.mysql.cj.jdbc.Driver log4j.appender.logDB.URL = jdbc:mysql://localhost:3306/cqyddx?useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true&useSSL=false&serverTimezone=Asia/Shanghai log4j.appender.logDB.User = root log4j.appender.logDB.Password = root log4j.appender.logDB.Sql = INSERT INTO log(project_name, create_date, LEVEL, category, file_name, thread_name, line, all_category, message) \ VALUES ('itcast', '%d{yyyy-MM-dd HH:mm:ss}', '%p', '%c', '%F', '%t', '%L', '%l', '%m'); #按照时间规则拆分的appender对象 log4j.appender.dailyFile = org.apache.log4j.DailyRollingFileAppender #指定消息格式layout log4j.appender.dailyFile.layout = org.apache.log4j.PatternLayout #指定消息格式的内容 log4j.appender.dailyFile.layout.conversionPattern = [%-10p]%r %l %d{yyyy-MM-dd HH:mm:ss.SSS] %m%n #指定日志文件保存路径 log4j.appender.dailyFile.file = ./logs/dailyFile.log #指定日志文件的字符集 log4j.appender.dailyFile.encoding = UTF-8 #指定日期拆分规则 log4j.appender.dailyFile.datePattern = '.'yyyy-MM-dd-HH-mm-ss #按照日志大小拆分文件 log4j.appender.rollingFile = org.apache.log4j.RollingFileAppender #指定消息格式 layout log4j.appender.rollingFile.layout = org.apache.log4j.PatternLayout log4j.appender.rollingFile.layout.conversionPa #指定消息格式的内容 ttern = [%-10p]%r %l %d{yyyy-MM-dd HH:mm:ss.SSS] %m%n #指定日志文件保存路径 log4j.appender.rollingFile.file = ./logs/rollingFile.log #指定日志文件的字符集 log4j.appender.rollingFile.encoding = UTF-8 #指定日志文件内容大小 #配置日志文件拆分的阈值,超过了这个值就会生成一个新的文件,默认10M log4j.appender.rollingFile.maxFileSize = 1MB #配置拆分文件的个数,默认1个1MB就拆分一个,如果超过阈值,保留最新的,覆盖最旧的 #指定日志文件数量,例如满足 log4j.appender.rollingFile.maxBackupIndex = 3 #指定输出级别为debug,优先级最高 log4j.appender.rollingFile.Threshold=DEBUG #日志立即输出,不用缓冲,默认为true log4j.appender.rollingFile.ImmediateFlush=true #因为是文件,所以会有追加的动作,控制是否追加,还是覆盖,默认为true log4j.appender.rollingFile.Append=true
运行结果如图
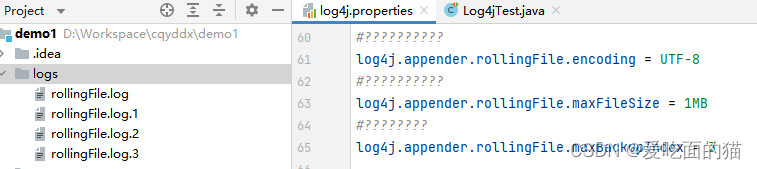
日志门面详解

















 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









