







Learning Deep Representations of Appearance and Motion for Anomalous Event Detection
Abstract
- 作者用DNN自动学习特征表示。
- 双融合框架。早期外观和运动像素融合构建联合表示输入,后期将三个一分类分类器分数融合获得最好异常分数。
- 具体过程是通过堆叠降噪自编码器分别提取外观和运动(光流图)特征以及融合后通过编码器提取联合表示特征,再针对三个特征利用三个一分类SVM获得异常分数最后融合获得最终异常分数。
Conclusions
未来的工作包括研究其他网络架构、在SDAE环境中融合多模态数据的替代方法、以及使用多任务学习来扩展框架,用于在异构场景中检测异常。
Introduction
早期利用轨迹特征,但是对于遮挡时轨迹难提取所以对于复杂或拥挤场景不适用。进而在2D图或者3D视频体中提取手工特征例如HOG、3D时空梯度、HOF等。同样这些特征并不天然适用于当前任务。然而使用深度学习丰富并且具有区分性的特征可以通过多层的非线性变换学习到,因此作者认为检测视频中的异常事件也可以受益于深度学习模型。
总结了贡献:①作者认为他们是第一个引入无监督深度学习框架,利用自编码器自动构造用于视频异常检测的判别表示。②作者提出了一种新的方法来学习外观和运动特征及其相关性是第一个将多模态深度学习应用于异常事件检测的工作。③提出了一种结合外观特征和运动特征的双融合方案④该方法在具有挑战性的异常检测数据集上进行了验证,与目前最先进的方法相比,作者方法获得了非常有竞争力的性能。
Ps:贡献一在视频异常检测首个使用深度学习提取特征顺势而为抢占先机,贡献二是自然衍生的首先必然要针对外观和运动提取特征,他们之间的相关性应该也有探讨的。贡献三即双融合方案了,12年有人提出相关思想,此处借鉴Double fusion for multimedia event detection. In Advances in Multimedia Modeling, 2012.
Method
整体过程为先通过滑动窗口获得patch块包括外观、运动和联合的,为了提高计算效率利用了背景减法,然后通过预训练和微调的降噪自编码器提取用于一分类的特征,进而利用三个一分类SVM获得异常分数。
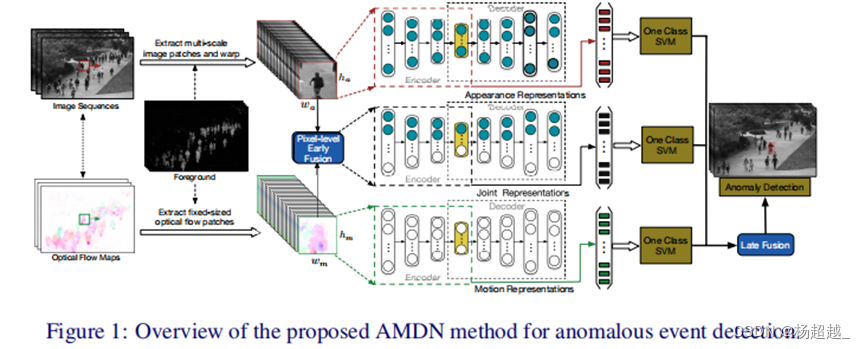
降噪自编码器:一个模型,能够从有噪音的原始数据作为输入,而能够恢复出真正的原始数据。这样的模型,更具有鲁棒性。
将原始输入+噪声构造初始输入,通过编码器压缩得到隐藏层表示再通过解码器重构原始输入,通过加入噪声网络可以学到更稳定鲁棒的特征表示。
针对降噪自编码器的优化目标:
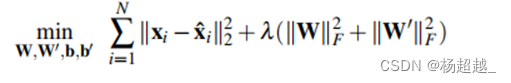
第一项最小化输入与输出的误差,第二项是F范数针对矩阵是矩阵中值的绝对值平方和再开方。此外为了学习有意义的表示可以让隐藏层值稀疏。令
μ
j
\mu_j
μj表示目标系数层次,
u
^
j
=
1
N
∑
i
=
1
N
h
i
j
\hat{u}_j = \frac{1}{N} \sum^N_{i=1}h^j_i
u^j=N1∑i=1Nhij表示隐藏层第j个单元平均激活值
ψ
(
μ
∣
∣
μ
^
)
=
−
∑
j
=
1
H
[
μ
j
l
o
g
(
μ
j
^
)
+
(
1
−
μ
j
)
l
o
g
(
1
−
μ
^
j
)
\psi(\mu||\hat{\mu})=-\sum_{j=1}^H[\mu_jlog(\hat{\mu_j})+(1-\mu_j)log(1-\hat\mu_j)
ψ(μ∣∣μ^)=−∑j=1H[μjlog(μj^)+(1−μj)log(1−μ^j)利用该交叉熵损失促使平均激活值靠近目标。
AMDN结构
外观:通过利用步长为d的滑动窗口再图片熵提取密集图像patch然后置为同一大小
w
a
×
h
a
×
c
a
w_a \times h_a \times c_a
wa×ha×ca,三个参数依次为宽、高和通道数,然后数值归一化到[0,1]然后利用四层编码层编码其中第一层神经元为
v
a
×
w
a
×
h
a
×
c
a
v_a \times w_a \times h_a \times c_a
va×wa×ha×ca 其中
v
a
v_a
va是为了让神经元数大于输入值数量以构造过完备的表示
v
a
v_a
va大于1
运动:同上构造patch大小为
w
m
×
h
m
×
c
m
w_m \times h_m \times c_m
wm×hm×cm,其中通道为2(光流)进而归一化,第一层神经元数为
v
m
×
w
m
×
h
m
×
c
m
v_m \times w_m \times h_m \times c_m
vm×wm×hm×cm
联合外观和运动:输入宽高不变通道标为
c
a
+
c
m
c_a+c_m
ca+cm所以推测是在通道维度进行了拼接
训练
关于堆叠降噪自编码器的预训练和微调可以看:堆叠式降噪自动编码器(SDA)
其中在训练过程中使用的损失为之前提到的自编码器的优化目标和稀疏限制,整体微调损失函数:
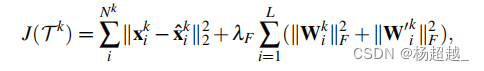
N
k
N^k
Nk为训练样本书
K
∈
(
A
,
M
,
J
)
K \in {(A,M,J)}
K∈(A,M,J)即包括外观、运动和联合表示的特征。微调网络后需要使用提取特征进行异常检测,理论上每层产生的特征都可以用来作为异常检测的特征表示,但是为了获得更压缩的表示或者说更高级的语义表示,所以使用bottleneck层产生的特征。
一类SVM
单类SVM是一种应用广泛的异常点检测算法,其主要思想是在特征空间中学习一个超球,并将大部分训练数据映射到超球中。数据分布的异常值对应于位于超球外的点。
本文使用的是OCSVM,其中关于one class SVM的两大方法可参考one class SVM
优化目标:
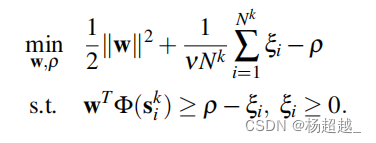
通过解决上述优化问题获得w和
ρ
\rho
ρ然后计算:
A
k
(
S
t
k
)
=
ρ
−
w
T
Φ
(
s
t
k
)
A^k(S_t^k)= \rho-w^T \Phi(s_t^k)
Ak(Stk)=ρ−wTΦ(stk)得到异常分数。
后融合 Todo

实验
训练输入:使用三个尺寸滑动窗口分别是
15
×
15
、
18
×
18
、
20
×
20
15 \times 15、18\times18、20\times20
15×15、18×18、20×20产生了超过50million的patches然后从中随机采样10million,然后统一到15
×
\times
× 15尺寸,对于运动使用
15
×
15
15\times 15
15×15的尺寸然后随机采用6 million个训练样本。
测试:使用固定大小15X15的步长为15的滑动窗口采样。
模型:对于外观和运动第一层神经元数为1024,联合表示为2048.编码器层数为:1024(2048)->512(1024)->256(512)->128(256),解码器为对称结构。
训练:高斯噪声方差为0.0003、SGD(momentum=0.9),batch=256,预训练学习率
λ
=
0.01
\lambda =0.01
λ=0.01,微调阶段学习率
λ
F
=
0.0001
\lambda_F=0.0001
λF=0.0001,mini-batch=256,一分类参数
ν
\nu
ν采样交叉验证获得
实验结果:
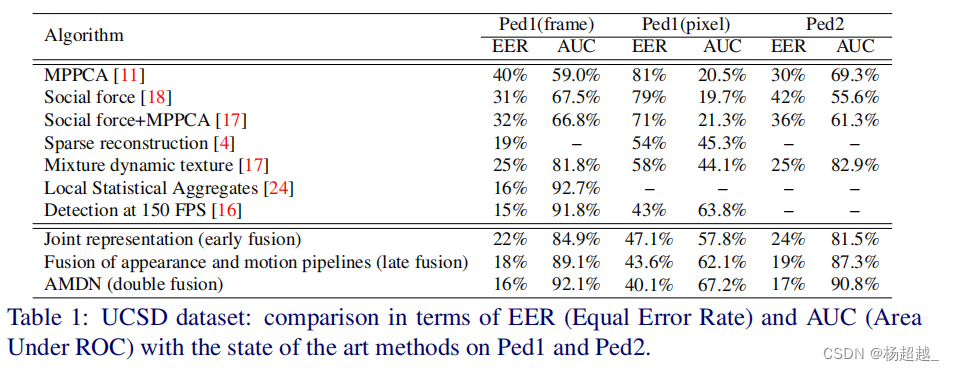
最终帧级别 AUC:
ped1(92.1%)
ped2(90.8%)
Discussion:
1.利用自编码器学习特征相比于手工特征有很大的进步,此外一个问题是由于不是端到端的所以学习的特征也不是专门针对于下游任务的。这也是利用一分类SVM类方法的问题所在,提取的特征越具有区分性越好。关注提取特征网络框架进展,不过后续端到端方法提取特征效果应该会天然优于一分类SVM方法。
2.聚焦了前景,减少了背景的影响。
3.没有使用卷积神经网络。
4.早期融合可能是两种表示在channel维度拼接,后期融合没看懂意义。
== 以上个人理解,希望与大家一起交流~ ==















 1881
1881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









