







 本文探讨了使用深度学习模型解决YouTube-8M大规模视频分类问题。研究了基于帧池化(BoF)、简单LSTM和LSTM_MoE结构的模型,其中LSTM_MoE利用专家混合层进行长期时间依赖性建模。实验显示,最佳模型能显著提升基线性能。
本文探讨了使用深度学习模型解决YouTube-8M大规模视频分类问题。研究了基于帧池化(BoF)、简单LSTM和LSTM_MoE结构的模型,其中LSTM_MoE利用专家混合层进行长期时间依赖性建模。实验显示,最佳模型能显著提升基线性能。
paper: https://arxiv.org/abs/1706.04488
摘要
视频分类问题已经研究了很多年。 卷积神经网络(CNN)在图像识别任务中的成功为研究人员创建更高级的视频分类方法提供了强大的动力。 由于视频具有时间内容,因此长期短期记忆(LSTM)网络成为方便的工具,可以对长期的时间线索进行建模。 两种方法都需要输入数据的大型数据集。 本文提供了三个模型,用于使用最近宣布的YouTube8M大规模数据集解决视频分类问题。 第一个模型基于帧池化方法。 基于LSTM网络的其他两个模型。 在第三模型中使用了专家中间层的混合物,从而可以在不显着增加计算的情况下增加模型容量。 已经进行了一组用于处理不平衡训练数据的实验。
1.介绍
近年来,随着深度学习方法的兴起,图像分类问题正在复兴。 设计了许多模型(AlexNet [1],VGGNet [2],ResNet [3],Inception [4]),它们可以有效地识别图像内容。 这样做的第一个原因是免费发布了高分辨率图像ImageNet [5]的大规模数据库,并且在GPU上使用了高效的操作,从而以相对较低的成本提供了高吞吐量的计算。 这种深度学习模型的预测准确性接近于人类水平的表现。
这个方向的下一步不仅是静态图像中的对象识别,还包括动作识别,视频分类。 提供这些问题输入数据集的基准很少(Sports-1M [6],UCF101 [7]等)。 最近发布的YouTube-8M基准测试[8]的数据集规模大大超过了竞争对手。就像该区域中的对象识别一样,许多手工制作的视频帧特征提取方法,例如定向梯度直方图(HOG),光流直方图(HOF),时空关注周围的运动边界直方图(MBH) 点[9],在密集网格[10],SIFT [11]中,存在梅尔频率倒谱系数(MFCC)[12],STIP [13]和密集轨迹[14]。然后使用BOW词袋方法将一组video-frame编码为video-level。 BoW的问题在于它仅使用静态视频帧信息来处理时间分量,即帧排序。递归神经网络(RNN)在基于时间的输入数据建模中显示出良好的效果。 几篇论文[15,16]描述了使用长短期记忆(LSTM)网络解决视频分类问题并取得了良好的效果。
本文介绍了用于解决YouTube-8M视频分类问题的三种模型。 在Google Cloud和YouTube-8M视频理解挑战赛[17]中使用了描述的模型。 第一个模型基于BoW:将基于时间的帧代码合并,然后进行分类;第二个模型和第三个模型基于LSTM方法。 与[15,16]相比,我们还使用了YouTube-8M提供的视频配乐信息。
本文的结构如下。 第2节回顾了使用深度学习的视频分类问题的相关作品。 第3节简要介绍了YouTube8M数据集。 第4节介绍了拟议的深度学习模型,用于解决YouTube-8M数据集上的多标签多类别分类。 第5节提供了将建议的模型训练到数据集的结果。 最后,第6节通过总结本文要解决的要点来总结本文。
3.输入数据
Frame-level:原始视频已经过预处理,以提取帧级功能。 在开始的360秒内,每个视频均以1 fps的速率进行解码,然后将解码后的帧馈送到Inception-v3网络中。 在分类层之前获取长度为2048的特征向量。 为了将特征尺寸减小到1024 PCA,并应用了量化。同样,音频特征是从视频中提取的[20]并添加到数据集中。帧级数据集的总大小约为1.7TB。 提取的功能以tfrecords格式存储,并且可以在Internet上使用[8]。
Video-level:此数据集中的要素是从帧级要素数据集中聚合的。在我们的模型中,我们将仅使用帧级数据集。
4.模型
本节介绍了用于训练和预测视频主题的模型。 第一个基于Bag-of-Frames方法的模型–沿时间轴合并输入视频帧特征的微型批处理,以获取视频级特征。 这允许在时间轴上对静态空间信息进行建模。
由于输入数据具有时间轴(基于时间),因此我们决定使用RNN,它允许提取顺序输入数据的时间信息。 第二个模型提出了一个几乎没有LSTM层和分类器的网络。第三个模型也是基于RNN的,但是在此我们基于[18,19]添加中间MoE层。
4.1Bag-of-Frames architecture
词袋表示法在视频分类问题中被广泛使用[15、16、22、23]。 每个输入样本对应一个视频,具有一组视频标签和一系列帧特征。 帧功能可以是每个输入视频帧的手工功能,也可以是由Inception-v3编码的原始视频帧。
对于训练数据集中的每个样本,都有一组帧级特征和真实的视频级标签。我们需要训练模型来预测视频级标签。 输入数据(batch_size,max_frames,feature_size)被发送到FramePooling层,在其中应用每个样本的时间帧之间的池化。 与[15]中一样,我们使用最大池从每个输入样本的所有基于时间的帧级特征中获取一个特征向量。 在FramePooling层之后,使用了两个FC层。 在顶层,我们使用S型分类器。
在Input,FC1和FC2层之后添加了批处理归一化层,以提供稳定性,收敛速度和某些正则化。 还会将压差应用于Input和FC1层的输出(概率为0.3)。 对于每个输入样本(max_frames = 90)在时间维度上使用90帧训练该模型。 乙状结肠交叉熵损失用于训练多类多标签分类器。 衰减率为0.9的RMSProp用作优化器。 我们使用基本学习率10 -4,它在每2 * 10 7个样本后衰减。
4.2Simple_LSTM结构
在本节中,我们考虑简单的LSTM架构,该架构允许对长期时间信息进行建模。 LSTM网络可以将先前的信息连接到当前任务(例如,将信息从视频的先前帧连接到当前帧),它们能够学习长期依赖性。
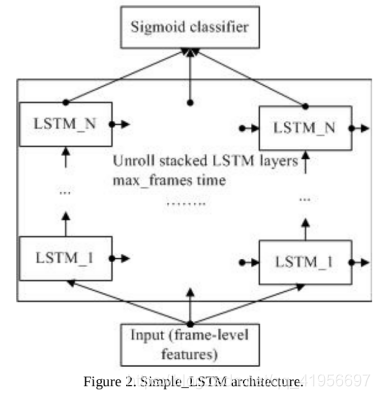
在“输入”层之后添加“批归一化”层,以提供稳定性,收敛速度和某些正则化。 Dropout应用于每个LSTM层的输出(概率为0.4)。 在某些实验中,使用了残余连接。 我们在时间维度上使用max_frames = 90训练了该模型。 乙状结肠交叉熵损失用于训练多类多标签分类器。 衰减率为0.9的RMSProp用作优化器。 我们使用基本学习率2 * 10-4,该学习率在每10 7个样本后衰减。
4.3 LSTM_MoE 结构
专家混合[19]的想法是培训一组专家,其中每个专家专门研究案件。 为每个样本门控网络选择专家。 门控网络的输出是softmax层,它提供选择特定专家的概率(输出概率的数量等于专家的数量)。
在早期的工作中[19,24,25,26],MoE被用作顶层。 Shazeer等。 [18]提出使用MoEs作为通用神经网络组件。 我们在Tensorflow库[27]中实现了MoE层,并在第三个模型中使用了它。
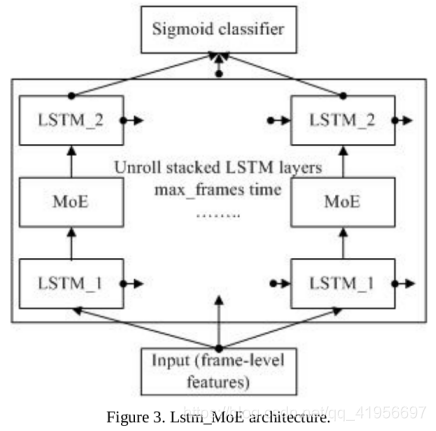
除了以下详细信息,LSTM_MoE与Simple_LSTM相似:
1.仅使用2个LSTM层
2.hidden_size = 512
3.LSTM_1层的输出是MoE层的输入,MoE层的输出是LSTM_2层的输入。
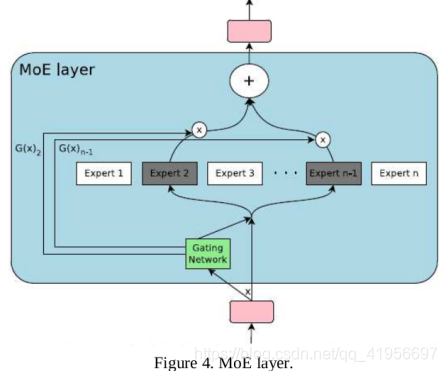
在图4中,提供了MoE层的示意图。 LSTM_1层的输出发送到门控网络。 门控网络选择专家的稀疏组合来处理每个输入样本。 这种稀疏选择可以节省计算量。
MoE层由门控网络和一组n个专家网络组成。 我们使用了n = 64个专家网络,每个样本中有4个处于活动状态。 每个专家网络由两个FC层组成,其中包含1024个隐藏单元。门控网络倾向于选择相同的专家。 为了提供负载平衡,提供了两个损失函数“损失重要性”,这些损失函数用于惩罚这种行为。
LSTM_MoE是一个非常消耗内存的模型,因此仅使用该模型进行了有限的实验。
5.实验
视频的最初几秒钟通常在视频分类方面不是很有用,因为它们包含一些文本或介绍性动画,这些视频或视频对分类没有帮助。 因此,我们跳过了输入数据的前几秒(帧)。 这样可以将评估指标提高约0.6%。 在我们所有的实验中,输入数据的前20帧均被跳过。
在下一个处理不平衡训练数据的尝试中,我们使用惩罚损失函数。 我们在模型上增加了额外成本,以便在训练过程中对少数族裔犯下分类错误。 我们对损失函数中的假阴性案例进行惩罚,使惩罚系数与训练集中的标签数成反比。
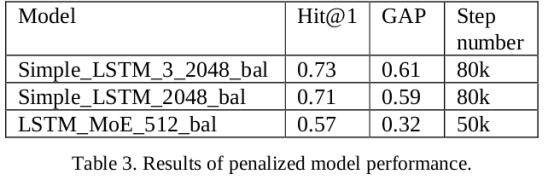
不幸的是,惩罚模型收敛缓慢,需要更多时间进行训练。 在表3中,提供了使用惩罚模型的实验结果。
6.结论
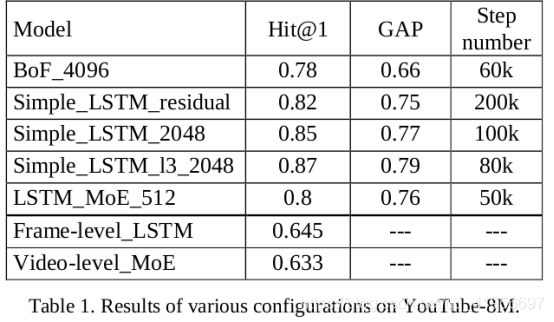
我们提出了三种用于视频分类的深度学习模型。 所有提供的模型都接受了来自YouTube-8M数据集的帧级输入数据的训练。 第一个模型(BoF)使用帧池化方法。Simple_LSTM和LSTM_MoE使用LSTM层进行长期时间依赖性建模。 在LSTM_MoE模型中,已实施并训练了专家混合层。在输入数据集中,我们跳过了最初的几秒钟(帧),因为它们通常在视频分类任务中没有用。我们最好的模型配置可将基线性能(命中率@ 1)提高14-23%。我们还进行了一组实验,使用惩罚损失函数处理不平衡训练数据。 这导致更多的分布式预测结果,但会降低总体Hit @ 1和GAP指标。 这些实验是进一步调整和改进的主题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









