







公司一直使用的Filebeat进行日志采集
由于Filebeat采集组件一些问题,现需要使用iLogtail进行代替
现记录下iLogtail介绍和实际使用过程
这是iLogtail系列的第三篇文章
目录
一、背景
由于业务需要,此处以多个kafka接收方作为配置。
二、前提条件
由于需要多个kafka作为接收方,先在生产环境xxx01和xxx03上安装kafka3.0并启动,分别创建名为logtail-flusher-kafka的topic。
三、安装ilogtail
下载1.0.28的ilogtail版本,并解压。
wget https://logtail-release-cn-hangzhou.oss-cn-hangzhou.aliyuncs.com/linux64/1.0.28/x86_64/logtail-linux64.tar.gz
四、创建配置文件
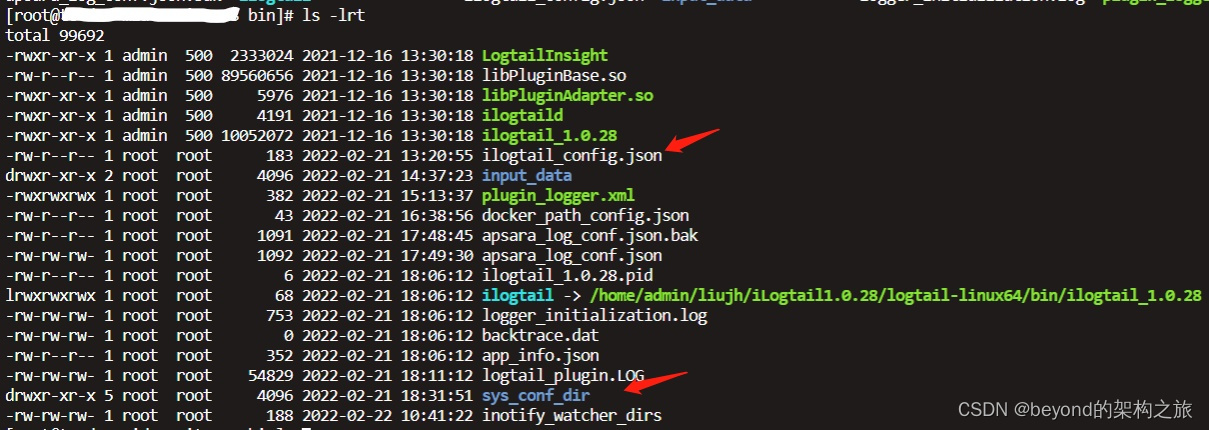
进入bin目录,创建sys_conf_dir文件夹(配置文件存放目录)及ilogtail_config.json文件(整体配置文件设置)。
ilogtail_config.json内容如下:
##### logtail_sys_conf_dir取值为:$pwd/sys_conf_dir/
##### config_server_address固定取值,保持不变。
{
"logtail_sys_conf_dir": "/home/admin/liujh/iLogtail1.0.28/logtail-linux64/bin/sys_conf_dir/",
"config_server_address" : "http://logtail.cn-zhangjiakou.log.aliyuncs.com"
}
五、创建采集配置文件
在sys_conf_dir下创建采集配置文件user_local_config.json。
{
"metrics":
{
"##1.0##kafka_output_test2":
{
"category": "file",
"log_type": "apsara_log",
"log_path": "/home/admin/xxx/iLogtail1.0.28/logtail-linux64/bin/input_data",
"file_pattern": "*.log",
"create_time": 1631018645,
"defaultEndpoint": "",
"delay_alarm_bytes": 0,
"delay_skip_bytes": 0,
"discard_none_utf8": false,
"discard_unmatch": false,
"docker_exclude_env":
{},
"docker_exclude_label":
{},
"docker_file": false,
"docker_include_env":
{},
"docker_include_label":
{},
"enable": true,
"enable_tag": false,
"file_encoding": "utf8",
"filter_keys":
[],
"filter_regs":
[],
"group_topic": "",
"plugin":
{
"processors":
[
{
"type":"processor_add_fields",
"detail":
{
"Fields": {
"input_type": "log",
"type": "LOGTAIL_LOG",
"offset": "offset",
"@timestamp": "@timestamp",
"beat": "beat",
"fields": "fields"
}
}
},
{
"type":"processor_rename",
"detail": {
"SourceKeys": ["__tag__:__path__","content"],
"DestKeys": ["source","message"],
"NoKeyError": true
}
},
{
"type" : "processor_filter_regex",
"detail" : {
"Include" : {
"content" : ".*"
}
}
}
],
"flushers":
[
{
"type": "flusher_kafka",
"detail":
{
"Brokers":
[
"99.6.0.99:9092"
],
"Topic": "logtail-flusher-kafka"
}
},
{
"type": "flusher_kafka",
"detail":
{
"Brokers":
[
"99.6.0.98:9092"
],
"Topic": "logtail-flusher-kafka"
}
}
]
},
"local_storage": true,
"log_tz": "",
"max_depth": 10,
"max_send_rate": -1,
"merge_type": "topic",
"preserve": true,
"preserve_depth": 1,
"priority": 0,
"raw_log": false,
"aliuid": "",
"region": "",
"project_name": "",
"send_rate_expire": 0,
"sensitive_keys":
[],
"shard_hash_key":
[],
"tail_existed": false,
"time_key": "",
"timeformat": "",
"topic_format": "none",
"tz_adjust": false,
"version": 1,
"advanced":
{
"force_multiconfig": false,
"tail_size_kb": 1024
}
}
}
} |
详细格式说明:
- 文件最外层的key为
metrics,内部为各个具体的采集配置。 - 采集配置的key为配置名,改名称需保证在本文件中唯一。建议命名:"##1.0##采集配置名称"。
- 采集配置value内部为具体采集参数配置,其中关键参数以及含义如下:
| 参数名 | 类型 | 描述 |
| enable | bool | 该配置是否生效,为false时该配置不生效。 |
| category | string | 文件采集场景取值为"file"。 |
| log_type | string | 日志的采集模式。具体说明如下:
|
| log_path | string | 采集路径。 |
| file_pattern | string | 采集文件。 |
| plugin | object | 具体采集配置,为json object,具体配置参考下面说明 |
| version | int | 该配置版本号,建议每次修改配置后加1 |
- plugin 字段为json object,为具体输入源以及处理方式配置:
| 配置项 | 类型 | 描述 |
| processors | object array | 处理方式配置,具体请参考链接。 processor_json:将原始日志按照json格式展开。 |
| flushers | object array | flusher_stdout:采集到标准输出,一般用于调试场景; flusher_kafka:采集到kafka。 |
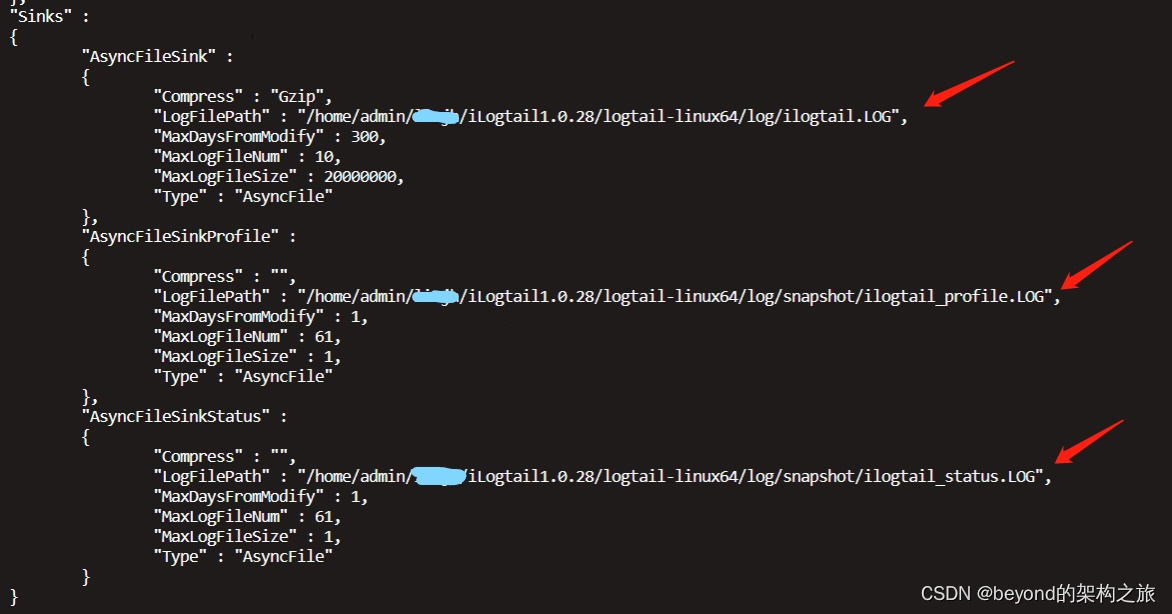
六、修改日志文件存储路径
在bin目录同级创建log文件夹,在log目录里创建snapshot文件夹,修改bin目录下apsara_log_conf.json配置日志输出路径。
七、部署问题记录
配置文件user_local_config.json的名字修改后无法被成功加载
user_local_config.json配置文件修改后 会 自动加载无需重启ilogtail
user_local_config.json中metrics中id需要唯一
八、相关限制
具体可见文档Logtail限制说明 - 日志服务 - 阿里云
限制一:同一文件对应多个采集配置
不支持,建议文件采集到一个Logstore,可以配置多份订阅。若有相关需求,可通过为文件配置软链接的方式绕过该限制。
默认情况下,一个文件只能匹配一个Logtail配置。当多个Logtail配置匹配同一个文件时,只会生效1个。因为在客户端上对文件中的日志采集多份需要消耗多倍的CPU、内存、磁盘IO和网络IO开销,将对同机部署的其他服务性能造成额外影响,并非优化的日志采集方案。
限制二:文件编码
支持UTF8或GBK的编码日志文件,建议使用UTF8编码以获得更好的处理性能。如果日志文件为其它编码格式则会出现乱码、数据丢失等错误。
九、配置文件及日志说明
ilogtail_config.json 启动参数配置文件
user_local_config.json 采集配置文件
app_info.json 记录Logtail的启动时间、获取到的IP地址、主机名等信息
ilogtail.LOG 记录了Logtail的运行日志,日志级别从低到高分别为INFO、WARN和ERROR,其中INFO类型的日志无需关注
logtail_plugin.LOG 记录Logtail插件的运行日志,日志级别从低到高分别为INFO、WARN和ERROR,其中INFO类型的日志无需关注
十、功能测试
模拟生产日志,同时查看两个kafka下观察是否正常接收,并且格式正确



















 599
599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









