







iLogtail和Mogo整合实践
最近在做日志采集-处理-展示的系统
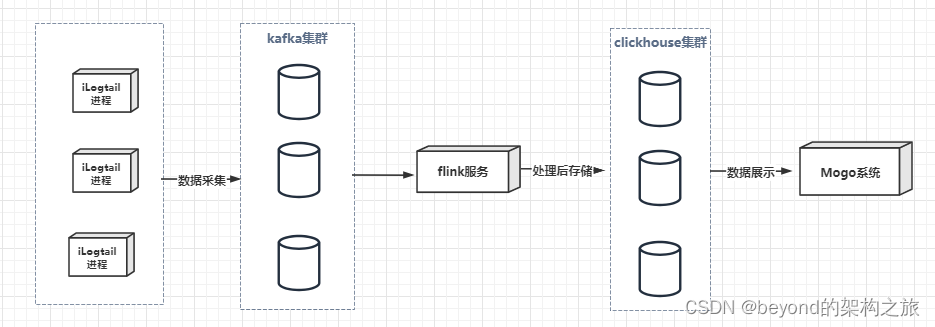
日志采集采用了iLogtail采集日志传输到kafka
之后通过flink处理kafka中数据存储到clickhouse
最后通过Mogo展示clickhouse中数据
整体采集日志服务架构
整体架构如下,本次重点讲解iLogtail采集和Mogo展示部分。
iLogtail日志采集
我们在iLogtail和Filebeat中选择iLogtail主要出于以下原因:
- iLogtail中flushers(处理方式)配置中,支持多个kafka集群作为接收者
- iLogtail能达到单核100M/s的采集性能,高于Filebeat 5倍以上
- iLogtail使用时cpu占用率远低于Filebeat
数据采集到kafka大家主要参考文档iLogtail使用入门-iLogtail本地配置模式部署(For Kafka Flusher)
在按照文档部署后,下面主要讲解实际采集中需要注意的问题点:
当我们遇到错误日志中的堆栈信息,需要对此进行多行日志解析
2022-03-02 14:01:30.000 DEBUG 3049 --- [pool-5-thread-1] c.a.toptea.sysm.invilid.InvilidResource : 输出正常值1
2022-03-02 14:01:30.000 DEBUG 3049 --- [pool-5-thread-1] c.a.toptea.sysm.invilid.InvilidResource : 输出正常值2
2022-03-02 14:01:30.000 DEBUG 3049 --- [pool-5-thread-1] c.a.toptea.sysm.invilid.InvilidResource : 输出正常值3
2022-03-02 14:01:30.006 ERROR 3049 --- [pool-5-thread-1] c.a.toptea.sysm.invilid.InvilidResource : ERROR
java.lang.ArithmeticException: / by zero
at com.ai.toptea.sysm.invilid.InvilidResource.invilidJob2(InvilidResource.java:35) ~[sysm-data-invilid-2.0.0.jar:2.0.0]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:1.8.0_152]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[na:1.8.0_152]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_152]
at java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_152]
at org.springframework.scheduling.support.ScheduledMethodRunnable.run(ScheduledMethodRunnable.java:84) [spring-context-5.2.5.RELEASE.jar:5.2.5.RELEASE]
at org.springframework.scheduling.support.DelegatingErrorHandlingRunnable.run(DelegatingErrorHandlingRunnable.java:54) [spring-context-5.2.5.RELEASE.jar:5.2.5.RELEASE]
at org.springframework.scheduling.concurrent.ReschedulingRunnable.run(ReschedulingRunnable.java:93) [spring-context-5.2.5.RELEASE.jar:5.2.5.RELEASE]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) [na:1.8.0_152]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) [na:1.8.0_152]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180) [na:1.8.0_152]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293) [na:1.8.0_152]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [na:1.8.0_152]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [na:1.8.0_152]
at java.lang.Thread.run(Thread.java:748) [na:1.8.0_152]
2022-03-02 14:01:30.006 DEBUG 3049 --- [pool-5-thread-1] c.a.toptea.sysm.invilid.InvilidResource : 输出正常值4
2022-03-02 14:01:30.006 DEBUG 3049 --- [pool-5-thread-1] c.a.toptea.sysm.invilid.InvilidResource : 输出正常值5
多行日志提交给插件时需要使用 processor_split_log_regex 进行基于行首正则的切分,日期开头配置如下,大家可以根据实际情况修改。
{
"detail":{
"SplitKey":"content",
"SplitRegex":"\\d+-\\d+-\\d+ \\d+:\\d+:\\d+.*"
},
"type":"processor_split_log_regex"
}
还有很多其他的处理方式,可参考Logtail 混合模式:使用插件处理文件日志
添加日志字段和重命名日志字段
可在processors中通过processor_add_fields添加和processor_rename重命名字段。
processor_add_fields使用具体参照文档https://help.aliyun.com/document_detail/196155.html
processor_rename使用具体参照文档https://help.aliyun.com/document_detail/196157.html
"processors":
[
{
"type":"processor_add_fields",
"detail":
{
"Fields": {
"input_type": "log",
"type": "LOGTAIL_LOG"
}
}
},
{
"type":"processor_rename",
"detail": {
"SourceKeys": ["__tag__:__path__","content"],
"DestKeys": ["source","message"],
"NoKeyError": true
}
}
]
完整配置如下,其中包含对于堆栈信息处理,添加字段处理
大家只需要根据实际情况修改日志采集相关配置log_path和file_pattern,日志输出flushers中kafka的地址及topic,还有就是日志处理processors中新增字段processor_add_fields中的配置。
{
"metrics":{
"##1.0##kafka_output_test3":{
"category":"file",
"log_type":"apsara_log",
"separator":"",
"keys":[
""
],
"regex":[
""
],
"log_begin_regex":[
""
],
"log_begin_regexs":[
""
],
"logBeginRegex":[
""
],
"logBeginRegexs":[
""
],
"log_path":"/home/admin/logs/",
"file_pattern":"*.log",
"create_time":1631018645,
"defaultEndpoint":"",
"delay_alarm_bytes":0,
"delay_skip_bytes":0,
"discard_none_utf8":false,
"discard_unmatch":false,
"docker_exclude_env":{
},
"docker_exclude_label":{
},
"docker_file":false,
"docker_include_env":{
},
"docker_include_label":{
},
"enable":true,
"enable_tag":false,
"file_encoding":"utf8",
"filter_keys":[
],
"filter_regs":[
],
"group_topic":"",
"plugin":{
"processors":[
{
"detail":{
"SplitRegex":"\\d+-\\d+-\\d+ \\d+:\\d+:\\d+.*",
"SplitKey":"content"
},
"type":"processor_split_log_regex"
},
{
"type":"processor_add_fields",
"detail":{
"Fields":{
"appName":"beyond",
"hostName":"jk-load3"
}
}
}
],
"flushers":[
{
"type":"flusher_kafka",
"detail":{
"Brokers":[
"127.0.0.1:9092"
],
"Topic":"logtail-flusher-kafka"
}
}
]
},
"local_storage":true,
"log_tz":"",
"max_depth":10,
"max_send_rate":-1,
"merge_type":"topic",
"preserve":true,
"preserve_depth":1,
"priority":0,
"raw_log":false,
"aliuid":"",
"region":"",
"project_name":"",
"send_rate_expire":0,
"sensitive_keys":[
],
"shard_hash_key":[
],
"tail_existed":false,
"time_key":"",
"timeformat":"",
"topic_format":"none",
"tz_adjust":false,
"version":1,
"advanced":{
"force_multiconfig":false,
"tail_size_kb":10485760
}
}
}
}
日志路径修改
因为启动后日志是默认配置的是bin目录下,所以需要修改下。
在bin目录同级创建log文件夹,在log目录里创建snapshot文件夹,修改bin目录下apsara_log_conf.json配置日志输出路径。
{
"AsyncFileSink" :
{
"Compress" : "Gzip",
"LogFilePath" : "/home/admin/iLogtail1.0.28/logtail-linux64/log/ilogtail.LOG",
"MaxDaysFromModify" : 300,
"MaxLogFileNum" : 10,
"MaxLogFileSize" : 20000000,
"Type" : "AsyncFile"
},
"AsyncFileSinkProfile" :
{
"Compress" : "",
"LogFilePath" : "/home/admin/iLogtail1.0.28/logtail-linux64/log/snapshot/ilogtail_profile.LOG",
"MaxDaysFromModify" : 1,
"MaxLogFileNum" : 61,
"MaxLogFileSize" : 1,
"Type" : "AsyncFile"
},
"AsyncFileSinkStatus" :
{
"Compress" : "",
"LogFilePath" : "/home/admin/iLogtail1.0.28/logtail-linux64/log/snapshot/ilogtail_status.LOG",
"MaxDaysFromModify" : 1,
"MaxLogFileNum" : 61,
"MaxLogFileSize" : 1,
"Type" : "AsyncFile"
}
}
修改bin目录下plugin_logger.xml配置文件
<rollingfile type="size" filename="/home/admin/iLogtail1.0.28/logtail-linux64/log/logtail_plugin.LOG" maxsize="2097152" maxrolls="10"/>
修改性能参数配置
在bin/ilogtail_config.json配置文件中修改Logtail启动参数,因为默认cpu限制为2核,为了尽量降低对机器上业务的影响,这里我改成了1核的限制。
{
"logtail_sys_conf_dir": "/home/admin/iLogtail1.0.28/logtail-linux64/bin/sys_conf_dir/",
"config_server_address" : "http://logtail.cn-zhangjiakou.log.aliyuncs.com",
"cpu_usage_limit" : 1
}
相关iLogtail的参考文档
整体介绍文档地址 https://zhuanlan.zhihu.com/p/443563965
官方配置介绍https://help.aliyun.com/document_detail/29058.html
设计介绍文档https://github.com/alibaba/ilogtail/blob/main/docs/zh/concept%26designs/Overview.md
数据结构介绍https://github.com/alibaba/ilogtail/blob/main/docs/zh/concept%26designs/Datastructure.md
iLogtail 使用指南https://github.com/alibaba/ilogtail/tree/main/docs/zh
iLogtail本地配置模式部署(For Kafka Flusher)参考资料https://developer.aliyun.com/article/848943
iLogtail 与Filebeat 性能对比文档https://new.qq.com/omn/20220124/20220124A01IZ800.html
处理采集到数据的方式参考
https://developer.aliyun.com/article/727322?spm=a2c4g.11186623.0.0.4b9f22d9H32xNc
修改Logtail性能参数参考https://help.aliyun.com/document_detail/32278.htm#concept-sdg-czb-wdb
Logtail技术分享(一) : Polling + Inotify 组合下的日志保序采集方案https://developer.aliyun.com/article/204554
Logtail技术分享(二) : 多租户隔离技术+双十一实战效果https://developer.aliyun.com/article/251629?spm=a2c6h.14164896.0.0.404c3396hdbbnN
处理数据插件介绍https://help.aliyun.com/document_detail/196153.html
日志处理与存储
这里我们采用了主流的大数据处理技术kafka+flink+clickhouse,主要借助了kafka的高吞吐量、低延迟来收集各种服务的log,通过kafka以统一接口服务的方式开放给flink数据,然后通过flink极致的流式处理性能将数据处理完存储到clickhouse中。
中间的具体实现可以自行选择,这里不做过多介绍。
Mogo日志系统展示clickhouse中的数据
安装使用主要参考了https://mogo.shimo.im/doc/AV62KU4AABMRQ
我采取的本地部署的方式,只不过Linux的下载地址我没成功,所以我用的是wget https://github.com/shimohq/mogo/releases/download/v0.1.0/mogo-v0.1.0-linux-amd64.tar.gz
# 下载二进制
# Linux 下下载
wget https://github.com/shimohq/mogo/releases/download/v0.1.0/mogo-v0.1.0-linux-amd64.tar.gz
# 解压 tar.gz 包到 ./mogo 目录
# 修改 config/default.toml 配置文件
# 执行 scripts/migration 下迁移脚本,创建数据库和表
# 启动 mogo
cd ./mogo-${latest} && ./mogo -config config/default.toml
# 打开浏览器访问 http://localhost:19001
# 默认登录用户名: shimo
# 默认登录密码: shimo
这里需要注意的是Mogo中用到了mysql和redis,需要大家提前安装好。
所以default.toml配置文件主要需要修改的是[server.http],[server.governor],[mysql.default],[redis.default]。
使用介绍
由于我只是使用Mogo直接从clickhouse中获取数据的,并没有用到Mogo的其他功能,所以我的具体操作如下:
- 新增数据库连接实例
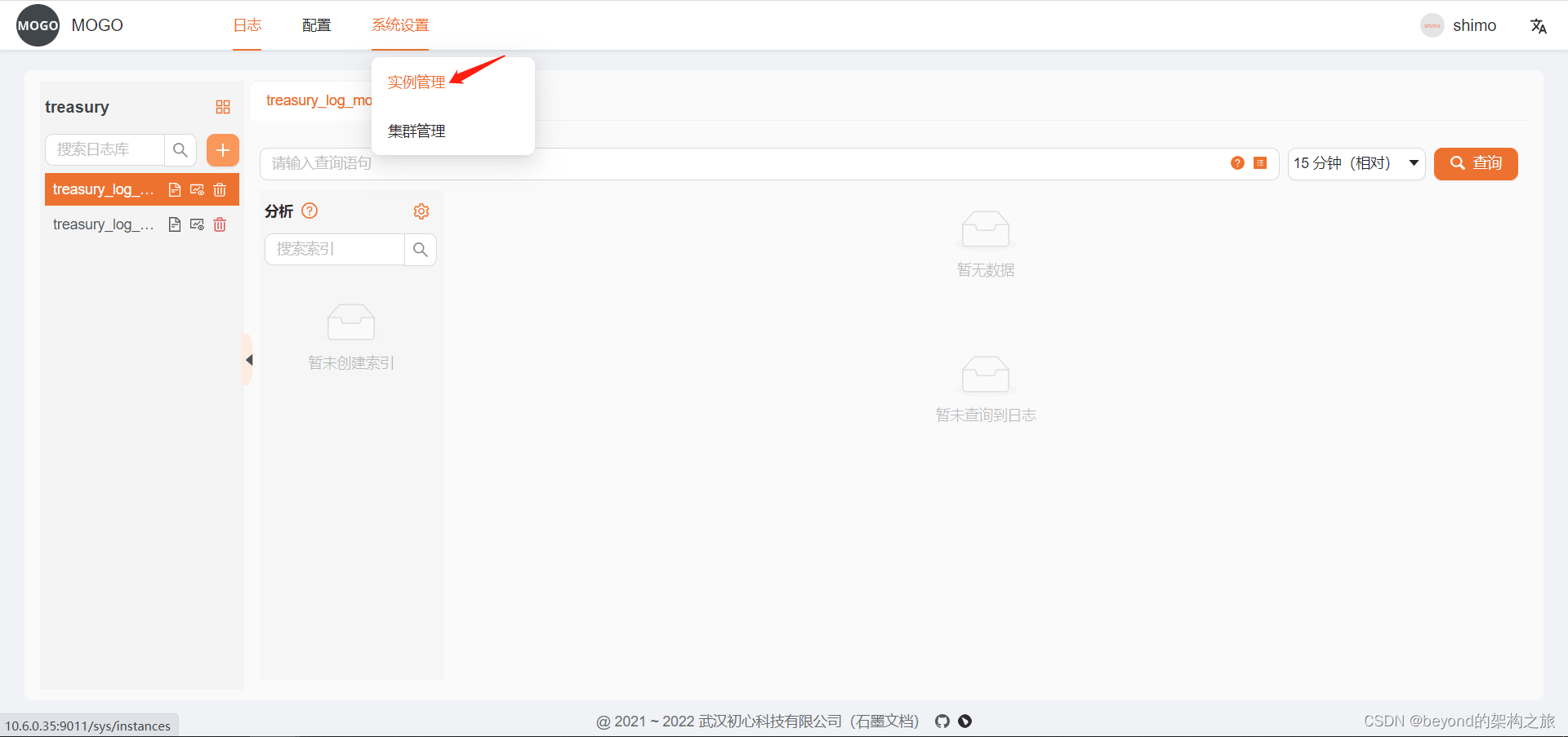
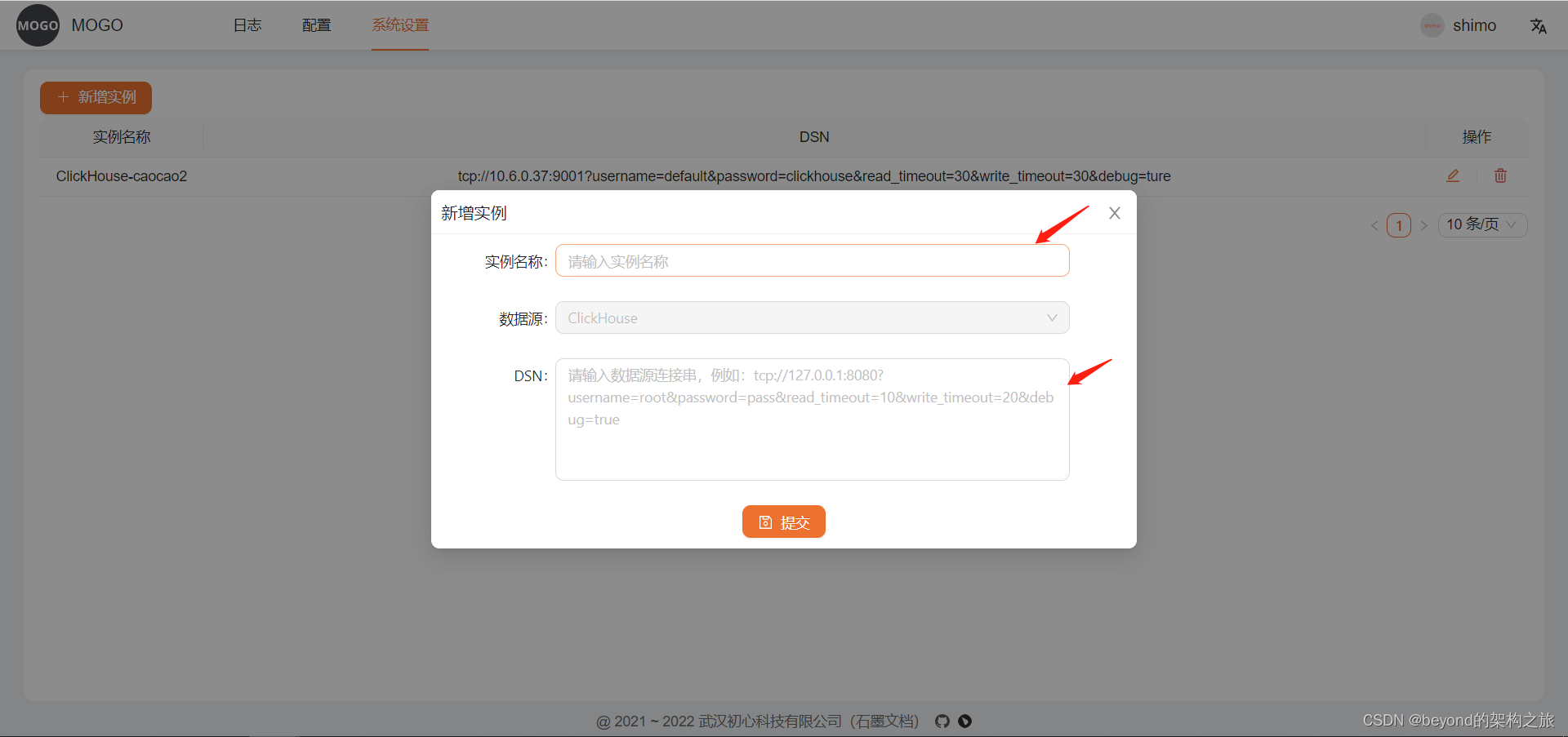
注意是tcp端口,连接串参考:
tcp://127.0.0.1:9001?username=clickhouse&password=clickhouse&read_timeout=30&write_timeout=30&debug=ture
对应的mysql中数据表mocro.mogo_base_instance,做的是软删除。
- 创建数据库

这里因为要用到已有数据库,但是Mogo不支持填写已存在数据库,所以先随便取个名字
然后在mysql中数据表mocro.mogo_base_database将clickhouse数据库名字修改
- 创建数据表
创建完实例后创建数据表,不可和已有表名重复,对应的是mysql中数据表mocro.mogo_base_table
页面上操作完会自动创建,这里的kafka地址配置和采集规则配置是为了将数据从kafka采集到clickhouse中,我们直接使用Mogo查询功能,所以这里不用管
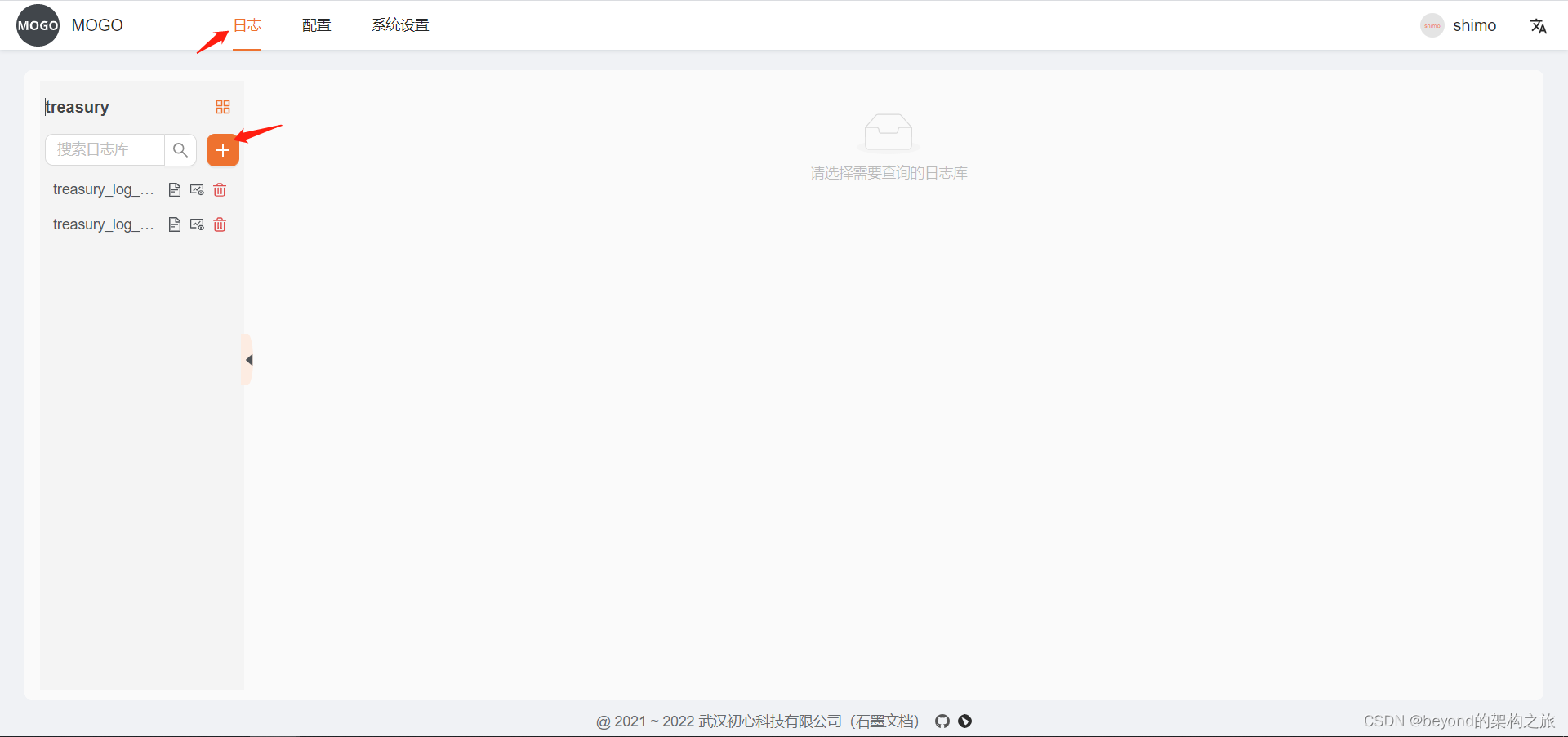
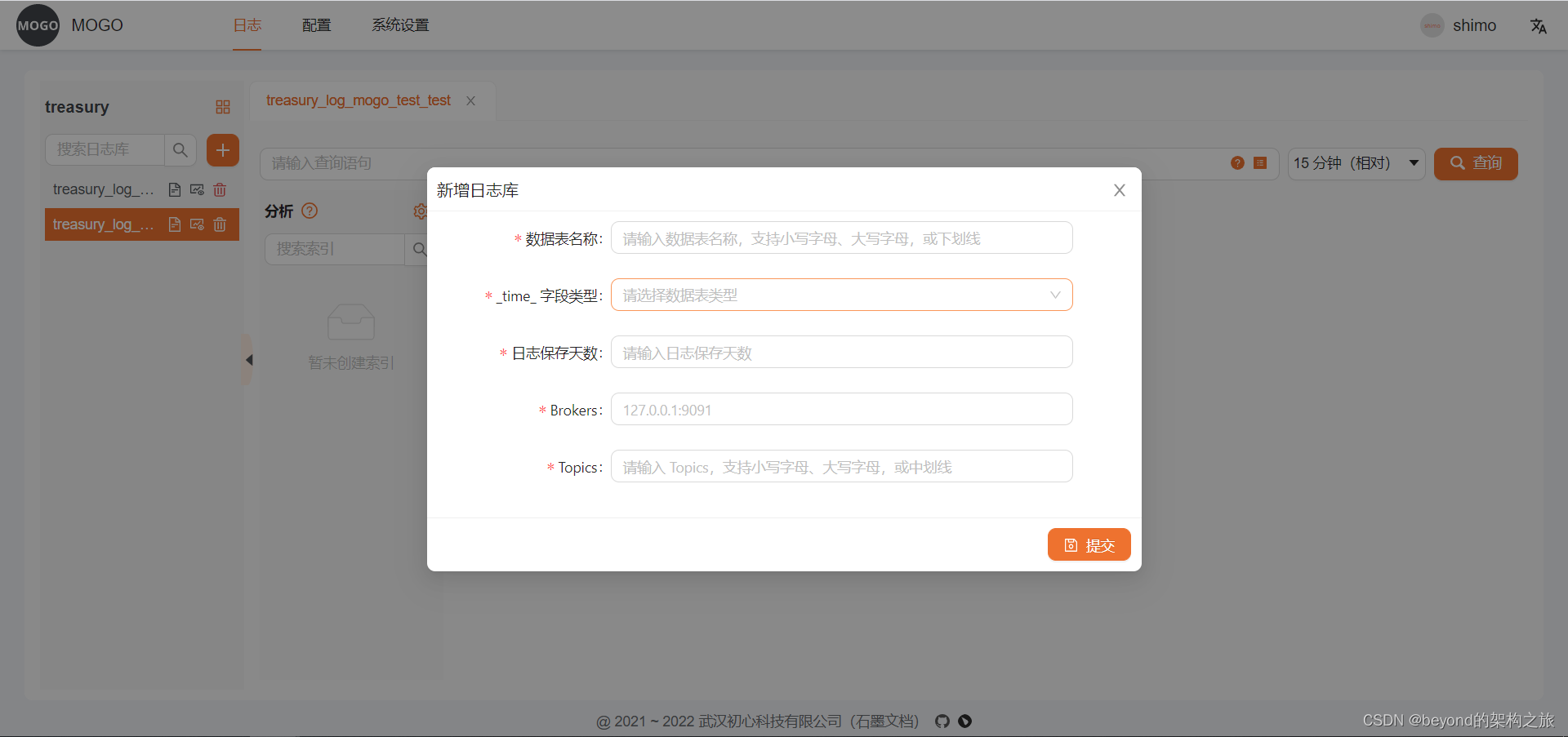
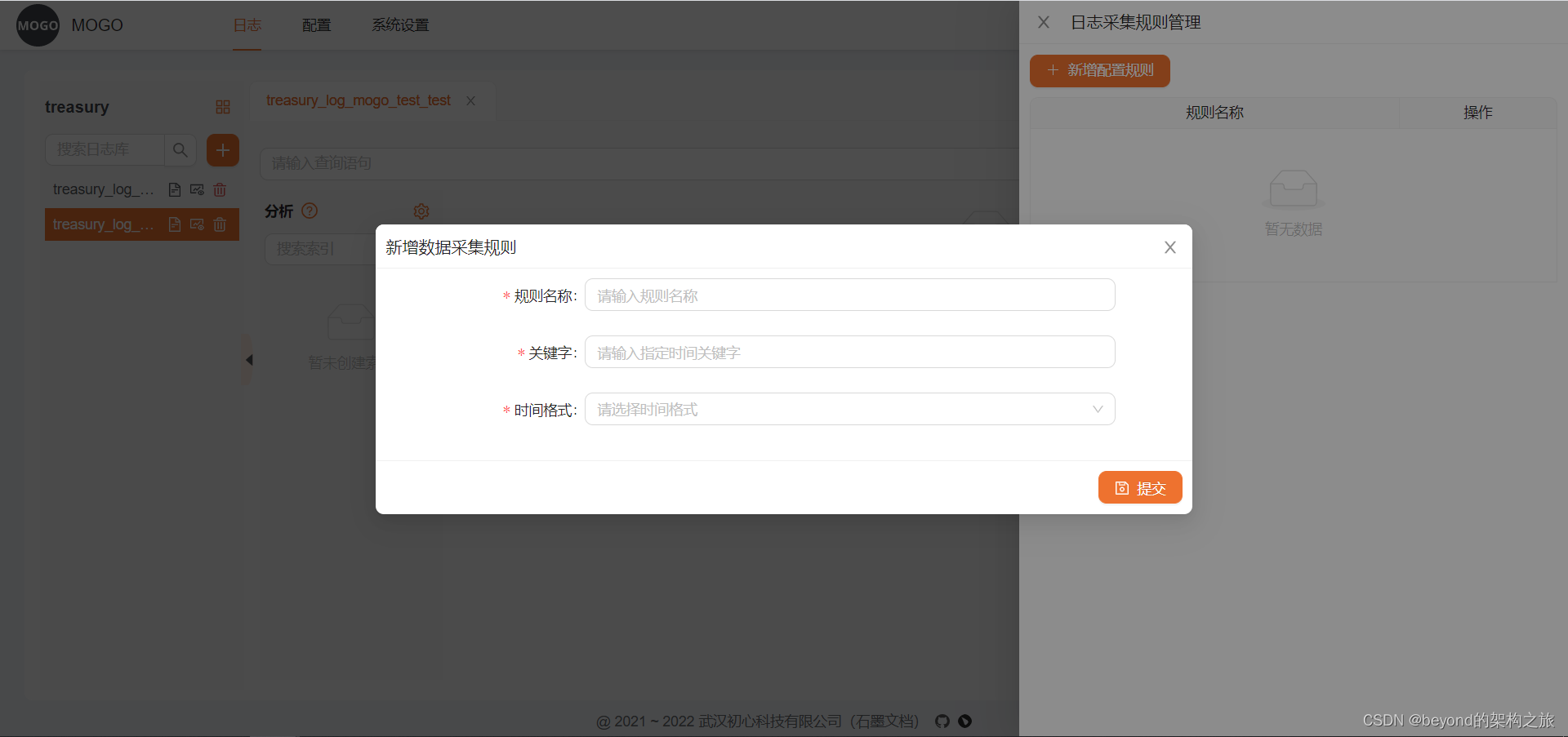
对于已存在的表查询,需要直接在mysql中数据表mocro.mogo_base_table直接添加,必须包含_time_second_字段
之后就可以根据需要自己查询了

因为目前Mogo项目(go语言)对于我目前的日志存储系统中clickhouse配套使用中有些问题,所以在咨询了Mogo相关开发大佬后做出了点修改。
1、全局固定了日志查询字段为_time_second_,为了避免改动已有的日志存储程序,现将Mogo源码中涉及到的_time_second_字段改为datatime字段
// 2022.03.09 // todo
// 定制化修改,将 所有 _time_second_ 改为 datatime
const ignoreKey = "datatime"
//const timeCondition = "datatime >= %d AND datatime < %d"
const timeCondition = "datatime >= %s AND datatime < %s"
2、因为我们日志系统中clickhouse的表通过Mogo查询一直报错,经过排查后发现是我们目前的日志表格式各Mogo自动创建的数据表格式略微不同导致的,所以将源码中涉及到的所有时间戳查询方式修改为日期格式字符串查询。
func (c *ClickHouse) countSQL(param view.ReqQuery) (sql string) {
// 2022.03.09 // todo
// 定制化修改,解决报错问题将所有日期由时间戳格式化为日期格式字符串
var ccST = "'" + time.Unix(param.ST, 0).Format("2006-01-02 15:04:05") + "'"
var ccET = "'" + time.Unix(param.ET, 0).Format("2006-01-02 15:04:05") + "'"
sql = fmt.Sprintf("SELECT count(*) as count FROM %s WHERE %s AND "+timeCondition,
param.DatabaseTable,
param.Query,
//param.ST, param.ET)
ccST, ccET)
elog.Debug("ClickHouse", elog.Any("step", "countSQL"), elog.Any("sql", sql))
return
}
后期集成
如果也有小伙伴和我一样是用Mogo只作为展示功能,那么你可能也需要对自己的日志存储系统做如下改造。
自己的日志项目在clickhouse中自动创建表时也要同时自动在Mogo的数据表mocro.mogo_base_table中自动加入一条相应数据,这样就可以在Mogo前台看到我们自己日志存储系统的clickhouse中所有数据了。















 333
333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









