






KMP算法
KMP算法可以看做是对暴力求解的一种改进,在前面的暴力算法中,i指针和j指针都是要回溯的,这是不合理的,因为当发现不匹配的时候,已经扫描到的区域我们其实是已知的,如下图所示
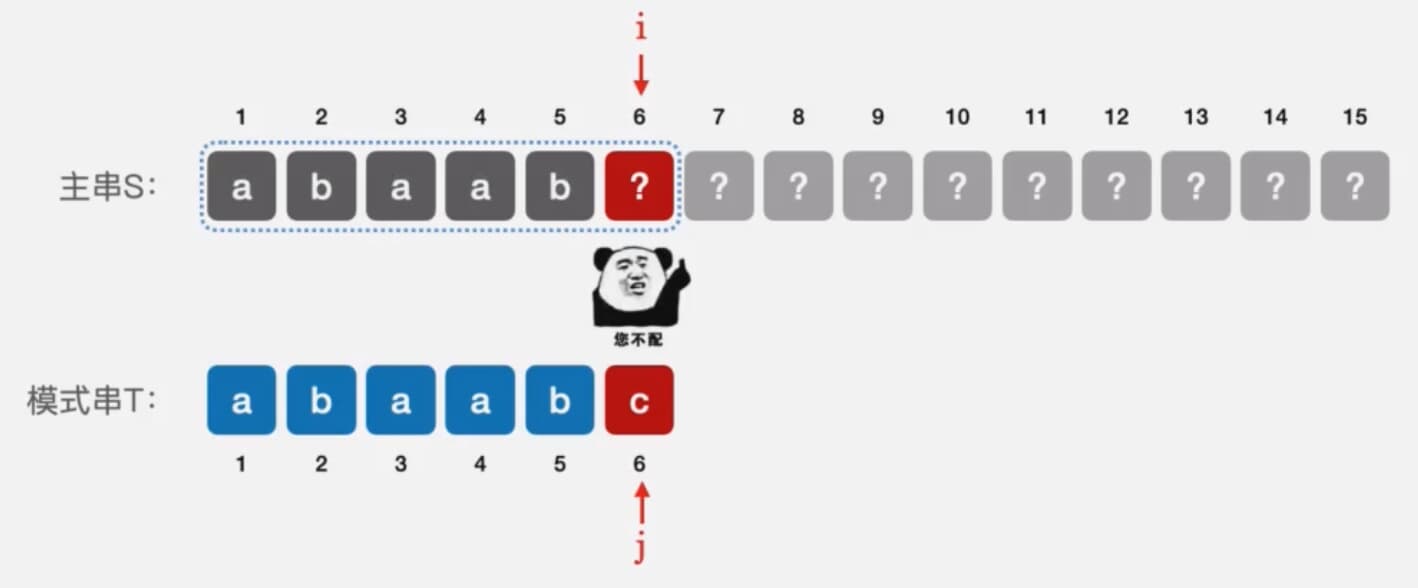
当我们发现不匹配后,我们其实已经知道了主串的第1到第5个字符是什么,其实就是模式串前面的字符,KMP算法就是将这些信息利用起来从而将时间复杂度优化到O(n)
既然前面的信息我们已经有了,我们其实完全不用回溯i指针,只需要回溯j指针,下面我们来看如何利用起来。
就那上面的例子来说,当第六个元素不匹配后,主串的1~5和模式串的1~5其实是一样的,读者可以看一下,我是否可以直接将j回溯到3号元素的位置而不回溯i,显然是可以的,因为i前面的两个字符是a和b,而3号位置的两个元素也是a和b,相当于少匹配了两个字符,只回溯j,不回溯i,这就是KMP算法的核心思想。
下面我们来看一下为什么我可以把j移动到3号位置,而不动i,为什么不是其他的位置呢?
可以对比上图,首先我们知道下一个要匹配的字符是i,我们假设我们要回溯到模式串第k个位置,那么这个k必须具备这样一个性质,就是k前面的所有字符必须和i前面的字符匹配上,我们可以看到上图,主串第6号位置前面的字符为abaab,如果j回溯到模式串3号位置,模式串3号前面的a和b正好可以和主串6号位置前面的ab匹配上,此时就可以继续往下匹配,但如果j回溯到4号位置,那模式串4号位置前面的aba就无法和主串6号位置前面的aab匹配上,所以这就不可行。
如果能理解上面加粗的话,那么我们就可以再深入一步,当匹配到6号位置的时候,实际上我们直到主串1~5的位置和模式串1~5的位置一定是一样的,所以,i前面末端的所有字符,就等于j前面的末端的所有字符,所以,我也可以这么说,我们假设匹配失败要回溯到模式串的第k个字符,那么k前面的所有字符必须和j前面的字符匹配上,因为j前面的字符和i前面的字符是一样的,我希望读者可以深入理解一下这句话,如果理解透彻了,就会发现,这个k的取值现在和主串就没关系了,发现了吗?只要k前面的所有字符能够和i前面的字符匹配上就可以了,所以能决定k取值的只有模式串本身和j目前的取值。
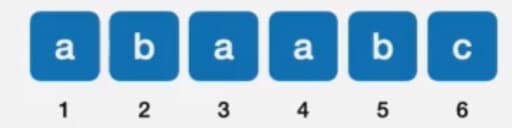
既然回溯位置只和模式串本身和匹配失败的位置有关系,我们就针对这个模式串来分析一下j处于不同的情况下需要回溯的情况,从后往前分析
如果匹配到第六个字符失败了,假设我们要回溯到第k个位置,那么k位置前面的所有字符应该和第六个字符前面的字符匹配上,很显然应该指向3的位置,因为3号位置前面的所有字符为ab,而6号位置前面的字符也为ab,可以匹配上。
如果匹配到第五个字符失败了,假设我们要回溯到第k个位置,那么k位置前面的所有字符应该和第五个字符前面的字符匹配上,可以观察出应该指向2号位置,因为2号位置前面的所有字符为a,5号字符前面的字符也是a,如果指向其他地方都是匹配不上的,比如指向4,4前面的字符为aba,而5前面的字符为aab,很显然匹配不上
如果匹配到第四个字符失败了,按照前面的规则,我们也可以看出,如果我们回溯到2号位置,那么2号位置前面的a和4号位置前面的a匹配上了,所以应该回溯到2号位置
如果匹配到3号位置失效,此时不论k回溯到1还是2,都无法满足规则,如下图所示
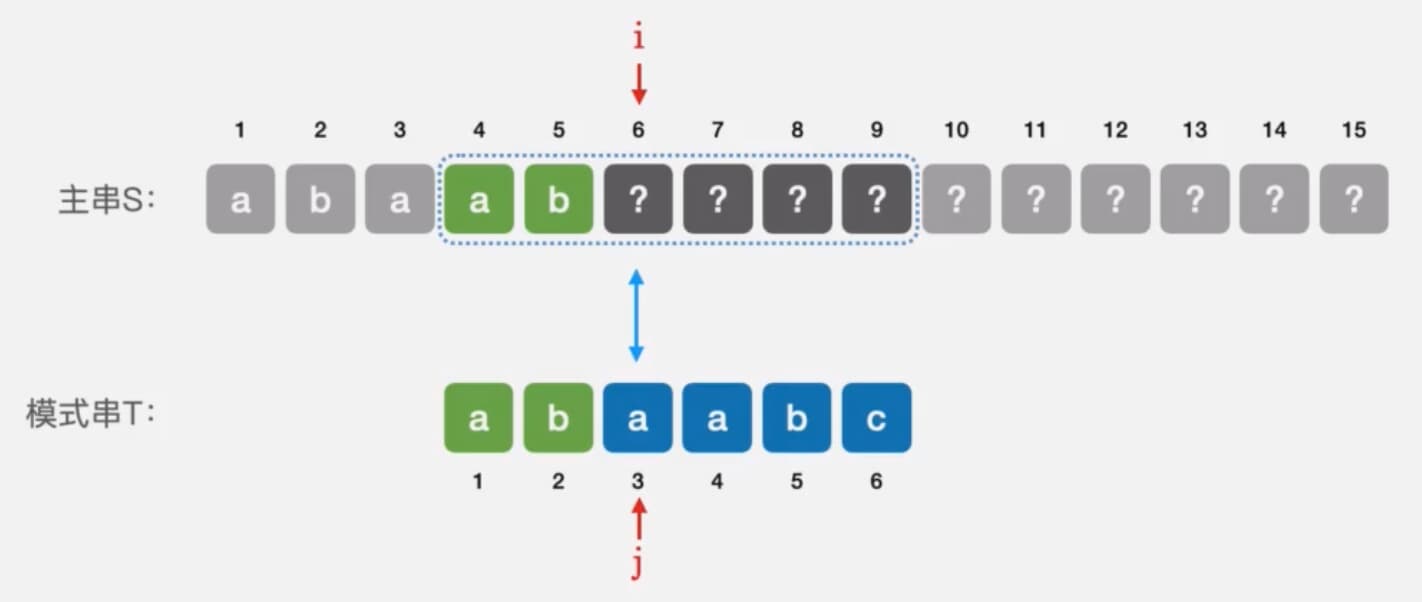
可以观察到,这种情况下,下一个要匹配的字符其实是模式串的1号位置,所以当第三个位置匹配失败的时候,我们应该回溯到模式串的1号位置
如果第二号位置匹配失败呢,如下图所示
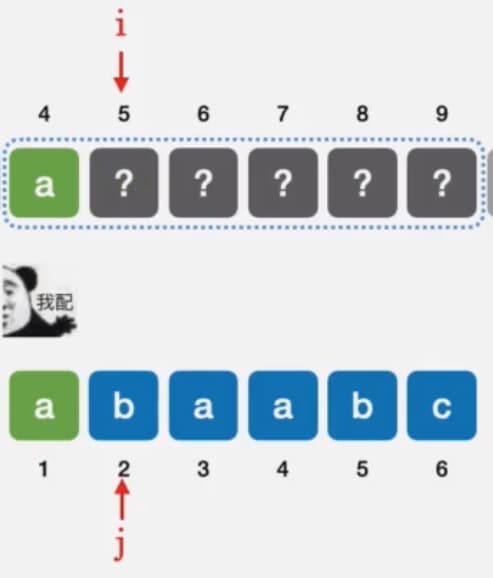
其实这种情况很简单,j是回溯,又不能往后跑,所以j只能回溯到1号位置,所以其实对于任意的模式字符串,只要是第二个元素匹配失败,他都只能回溯到第一个元素上去。
情况特别一点的是第一个位置匹配失败,如下图所示
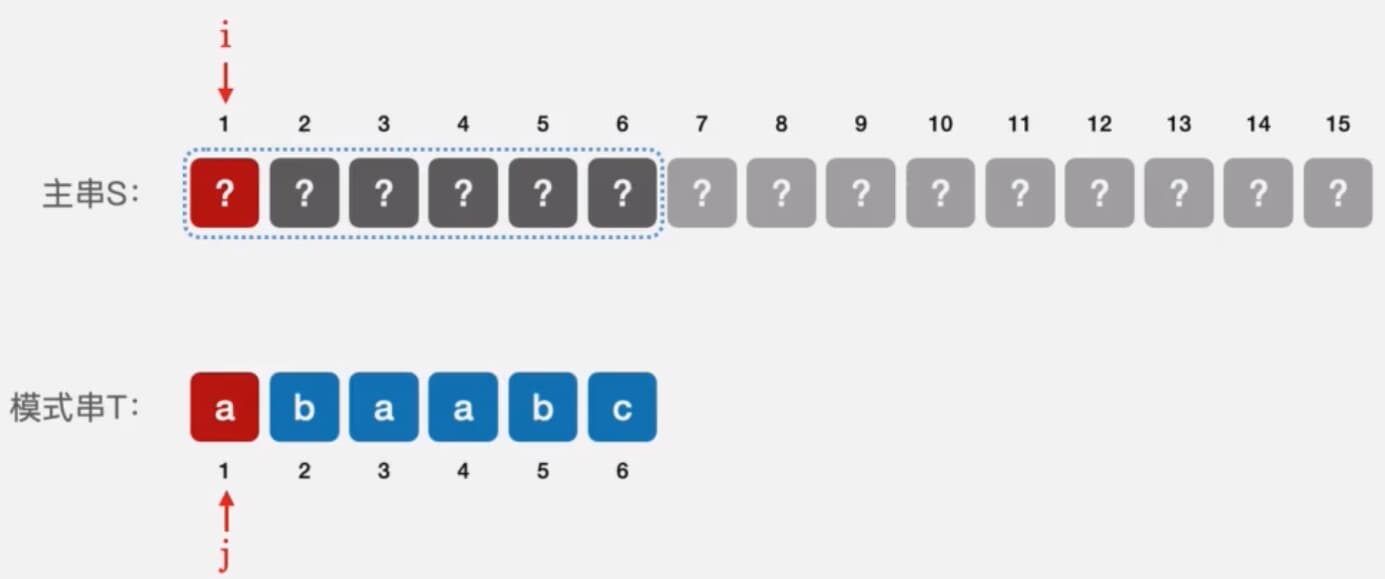
这个时候由于第一个元素直接就匹配失败了,我们应该继续匹配下一个元素,应该让i+1,j保持不动,这样固然没有问题,但是我们发现,我们每次进行匹配都会让i的值和j的值同时加一,我们可以利用这个同时+1的算法,让j的值回溯到0,然后j和i同时+1即可,这样做虽然对代码逻辑没有任何影响,但可以减少代码量,也算是一种优化。
上面我们分清楚了j处于每一个位置时匹配失败的回溯位置,如下所示
- 第六个元素匹配失败,i=3
- 第五个元素匹配失败,i=2
- 第四个元素匹配失败,i=2
- 第三个元素匹配失败,i=1
- 第二个元素匹配失败,i=1
- 第一个元素匹配失败,i=0(i和j都要加一)
我们可以将这个信息列成一张表
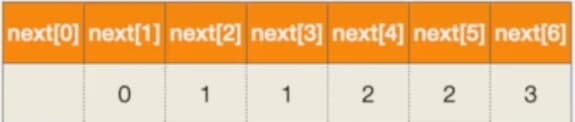
我们称这张表为next表,next[j]表示第j个元素匹配失败的时候j指针应该回溯的位置
有了这张表之后,我们就可以尝试来写出KMP算法了
int KMP(myString *s,myString *t,int *next){//s为主串,t为模式串,还需要把next数组传入
//初始化1和j
int i = 1;
int j = 1;
while(i < s.length && j < j.length){
if(s[i] == j[i] || j == 0){
//如果能匹配上,匹配下一个元素,如果j为0,也让他们都加一
i++;
j++;
}else{
//如果匹配不上,进行回溯,这里只回溯j
j = next[j];
}
}
//出循环的时候,说明i和j至少有一个越界
if(j > t.length){//如果j比t.length大,说明j被完完整整匹配了一遍,此时j的值为t.length+1
return i-t.length;//返回值应该是开始匹配的第一个元素位置,应该是i-j+1,化简后为i-t.length
}else{
return -1;
}
}
如果理解了KMP算法的核心逻辑,那么这个算法理解起来就没有什么难度,唯一的难点在于第六行代码,当j==0的时候,我们同样要让i和j相加,因为当j==0的时候,表示上一次匹配的第一个元素匹配就失败了,所以需要将j回溯到0,让i和j都加1,这是前面提过的。
KMP算法由于i指针不回溯,最坏时间复杂度只会到O(n),以上就介绍完了KMP算法。
综合来看KMP算法的最坏时间复杂度其实是O(m+n),这是因为求next数组其实是需要一个O(m)时间复杂度的算法
下面讲一下手算next数组的技巧,next[j]其实就是第j个字符匹配不上的时候应该回溯到的位置,而回溯到的那个位置前面所有的字符,应该和第j个位置前面的字符匹配上,这是前面讲过的。
在讲技巧之前,先来了解一下前后缀的概念,字符串的前缀,就是字符前面的n个连续字符字符,例如"abcd"的前缀一共有"a",“ab”,“abc”,“abcd"四个,而后缀正好相反,就是尾部n个连续字符,这个字符串的后缀有"d”,“cd”,“bcd”,"abcd"四个。
我们计算next[j],其实就是计算前面的第1到第j-1这个字符串除自身以外的最长公共前后缀的个数+1
我们举个例子来理解,例如"google"这个字符串
如果第四个位置匹配失败,前面三个字符就是goo,他的前缀有g,go,goo三个,后缀有o,oo,goo三个,我们抛开goo自身,前缀就只有g,go,后缀就只有o,oo,这显然没有公共前后缀,公共前后缀就是0,所以0+1就是1,所以next[4] =0+1=1。
同理如果我们要求next[5],也就是第5个字符匹配失败应该回溯的位置,前4个字符除去自身以外的前缀有g,go,goo,后缀有g,og,oog,这个时候发现前缀的g和后缀的g相等,没有其他的前后缀相等,他的长度为1,所以next[5] = 1+1=2
对于第二个元素匹配失败的情况,由于其前面只有一个字符,公共前后缀长度必为0,所以一定回溯到1。
而对于第一个元素匹配失败的情况,一定是回溯到0这个位置,至于为什么我们前面提到过,如果忘记了可以翻看前面的算法。
考研并不要求掌握求next数组的计算机算法,只要求可以手算即可
KMP算法的进一步优化
KMP算法也是可以进一步优化的,但优化的并不是KMP算法本身,而是next数组,我们在讲KMP算法的时候提到过,KMP相对于暴力算法而言,其实就是利用了暴力算法没有用到的一些多余信息,但是我们前面的KMP算法其实还有一些多于信息没有用到,什么信息呢,我们看下面的例子。
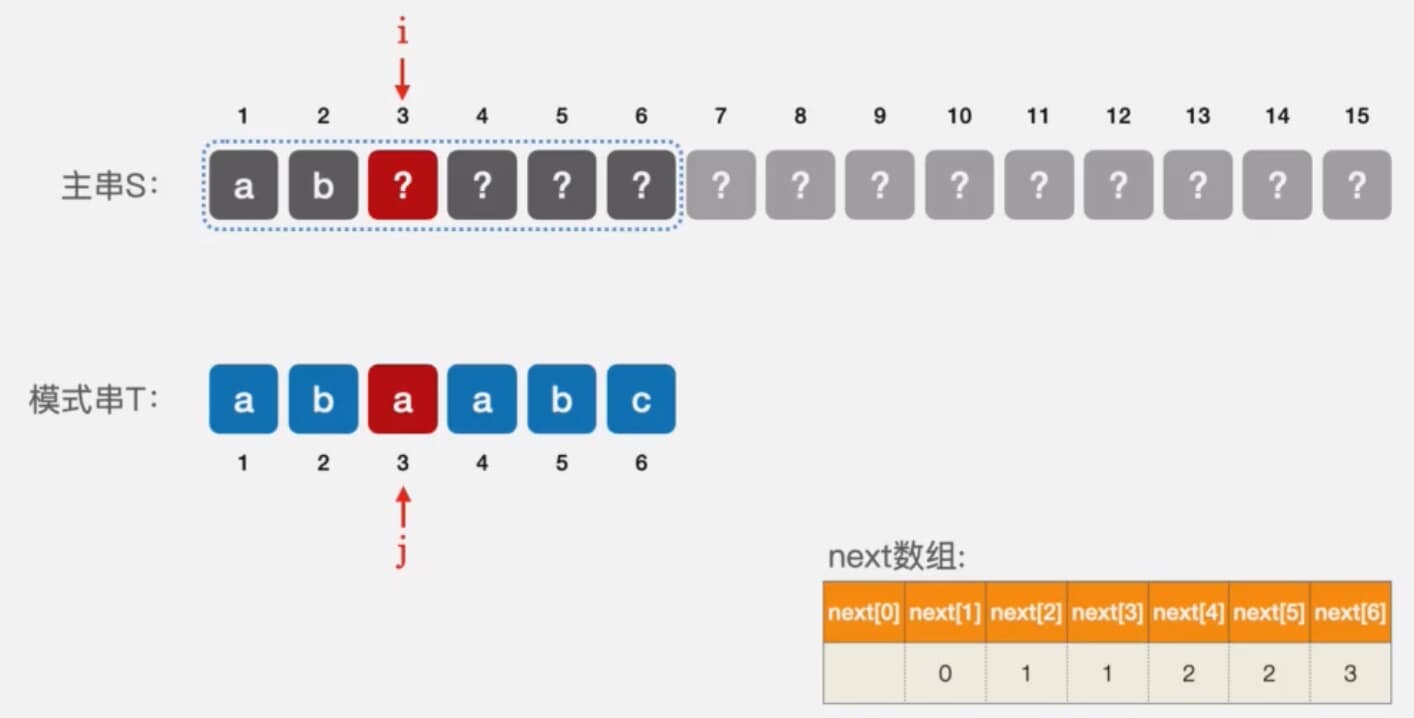
这个例子中我们直接给出了next数组,我们看到,当我们匹配到3号字符的时候,匹配失败了,此时我们知道主串中1号和2号字符,但我们在前面忽略了一个信息,就是主串的3号字符,虽然我们不知道主串的3号字符是什么,但我们起码知道主串的3号字符不等于a,如果我们将这个信息利用起来,就可以对next数组进一步优化。
现在我们直到,主串中3号字符并不是a,而j应该回溯到的位置,也就是next[3]为1,我们发现模式串种第一个字符正好又是a,同样是a,既然3号字符匹配不上,那么1号字符也一定匹配不上,这是已经注定的,既然1号字符匹配不上,就会让他跳转到next[1]位置上去,既然3号字符匹配不上的1号字符也一定匹配不上,那回溯到1号字符似乎就是一个多余的操作,我们不如直接让3号字符回溯到下一个位置,也就是next[1]的位置,即0号位置,这就是KMP算法的改进思路,这种改进的next数组,我们称为nextval数组。
以上只是对改进思路的介绍,下面介绍一下求nextval的解题技巧
求nextval数组之前,我们必须求出next数组,求next数组的技巧在前面已经介绍过,下面默认已经有了next数组。
对于next数组的第一位由于其是固定的0,属于特殊情况,所以无法优化,第一位的nextval值固定为0,从第二位开始看。
我们如果要优化next[j],我们假设next[j]=k,此时我们看第k位和第i位是否相同,如果不同,那么说明无法优化,next和nextval值一样,如果相同,那么就把k的nextval的值copy过来,我们以一个例子来说明。
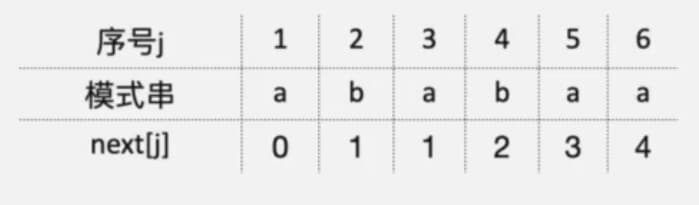
我们一位一位分析
第一位:第一位属于特殊情况,nextval[1]直接写0
第二位:第二位的的字符为b,第二位的next指向第一个位置,字符为a,字符a和字符b不相同,所以第二位的next无法优化,nextval[2] = next[2] = 1
第三位:第三位的字符为a,第三位的next数组指向第一个位置,字符也为a,我们发现这两个字符相同,那么就把第一个位置的nextval拿过来,也就是nextval[3] = nextval[1] = 0
第四位:第四位字符为b,next数组指向第二个位置,字符也为b,他们相同,所以第四位的nextval就是把第二个位置的nextval拿过来,即nextval[4] = nextval[2] = 1
第五位:第五位字符为a,next指向第三个位置,第三个位置的字符为a,他们相同,所以nextval[5] = nextval[3] = 0
第六位:第六位字符为a,next指向第四个位置,第四个位置的字符为b,他们不同,所以无法优化,即nextval[6]=nextval[6] = 4
[5] = nextval[3] = 0
第六位:第六位字符为a,next指向第四个位置,第四个位置的字符为b,他们不同,所以无法优化,即nextval[6]=nextval[6] = 4
如果看懂了上面的例子,相信就能掌握手算nextval了,总而言之,就是看当前字符和当前所指向的字符是否相同,如果相同,就把别人的nextval抄过来,如果不同,就用自己的next值,就和抄作业一样,秉承着能抄坚决不写的原则,如果和别人的作业一样,就可以把别人的抄过来,如果和别人的作业不一样,就得自己写,也就是用自己的。















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









