







说明:最近学校要求班委收集每个同学青年大学习的学习完成截图,并核实学习情况,故此次想开发一套自动识别图片中的文字,并对其进行改名的程序,从而将人力解放出来去干些更有意义的事情。
任务目标
1.自动识别图像中特殊字段信息
2.批量读入图片
3.自动批量对图片进行命名
开发准备
Tesseract-OCR介绍
开源的OCR识别引擎,高版本识别基于LSTM,其整个处理流程如下:
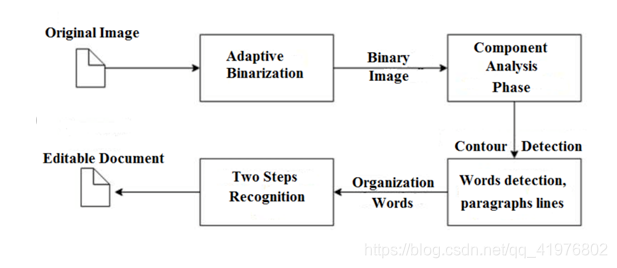
以上图片来源于小白学视觉 的博客
安装Tesseract-OCR Python SDK支持
pip install pytesseract
附:网上找到的Tesseract-OCR下载链接
http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe
下载Tesseract-OCR 5.0.0-alpha.20201127安装包并安装,然后在系统的环境变量中添加对于的安装路径,默认为:
C:\Program Files\Tesseract-OCR
若自定义安装,换为对应路径即可。
验证与测试
安装与配置好OpenCV-Python与Tesseract-OCR之后,需要进一步通过代码验证正确性。打开Pycharm IDE,新建一个python项目与python文件,输入以下代码:
import pytesseract as tess
print(tess.get_tesseract_version())
print(tess.get_languages())
运行结果如下:
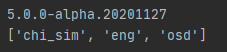
第一行是版本信息,第二行是支持的语言信息,默认只支持英文。'eng’表示支持英文,'chi_sim’表示支持简体中文。若要想也支持中文的识别,需要自行下载对应的语言包,并将其放在Tesseract OCR安装目录的tessdata文件夹下
Tesseract OCR中英文语言包的下载地址
https://github.com/tesseract-ocr/tessda 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1074
1074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









