







基础理解
看到梯度下降算法,首先我们应该去了解几个问题,这是什么?干什么用的?为什么会产生这个概念或者事物?实现的具体思路是什么?为什么这么实现,其背后的原理是什么?
首先我们应该明确的一点是,所谓的梯度下降算法并不是一个机器学习算法,而是一个基于搜索的最优化算法。我们在上一节所讲到的线性回归算法的目标是最优化一个损失函数,这也是梯度下降算法的思路。而梯度上升算法是最大化一个效用函数。
其次我们需要明确,为什么会产生这种算法呢?从上一节我们可以看出来,我们可以通过正规方程解的方式求解出theta的值,但是很多数情况下theta的值是没法求出其具体的公式的,因此梯度下降算法应允而生。
实现的具体思路及逻辑:
要实现梯度下降,要就是实现最小化一个损失函数,需要用到导数,参数为theta,对theta进行求解导数,需要不断的递减theta然后进行求解,此时便用到了学习速率。

而且学习速率取值的大小也十分的重要。
如图所示:

梯度下降算法在线性回归中的使用:
公式推导:

代码封装:
def fit_gd(self,X_train,y_train,eta=0.01,n_iters=1e4):
'''check'''
assert X_train.shape[0] == y_train.shape[0],\
"the size must be valid"
'''No.1 get J'''
def J(X_b,theta,y):
try:
return np.sum(y - X_b.dot(theta)) / len(y)
except:
return float('inf')
def DJ(X_b,theta,y):
return X_b.T.dot(X_b.dot(theta) - y) *2 / len(X_b)
def gradient_decent(X_b,y,initial_theta,eta,n_iters = 1e4,epsilon = 1e-8):
theta = initial_theta
cur_iters = 0
while cur_iters < n_iters:
gradient = DJ(X_b,y,theta)
last_theta = theta
theta = theta - gradient*n_iters
if(abs(J(X_b,y,theta) - J(X_b,y,last_theta)) < epsilon):
break
cur_iters += 1
X_b = np.hstack([np.ones((len(X_train),1)),X_train])
initial_theta = np.zeros(X_b.shape[1])
self._theta = gradient_decent(X_b,y_train,initial_theta,eta,n_iters)
self.coef_ = self._theta[1:]
self.interception_ = self._theta[0]
return self
随机梯度下降法
随机梯度下降法和批量梯度下降法在计算theta时是两种不同的方式,两者互有千秋,将两者正式融合的是小批量梯度下降法(代码会在GitHub中开源,博客不会详细介绍)。
现在介绍两者区别:
批量梯度下降法(Batch Gradient Descent):是梯度下降的最原始的一种方式,使用特点和思路是使用全部的样本进行更新theta,这样的做法效率很低,训练过程慢。
随机梯度下降法:和BGD不同,随机梯度下降法在更新theta时使用的是随机的一个样本进行更新,例如如果存在10万条数据,我们使用几万条数据便将theta更新到最优解了,大大提升了训练模型的效率,但是准确率较低。(通常情况下,我们愿意使用牺牲模型一定的精度来换取训练模型所用的时间)。
另外,实现随机梯度下降时所用的学习速率需要注意:
我们每次都是采取的随机的一个样本,如果采用固定的学习速率的话,如果我们接近找到的最佳的theta,就会慢慢的跳出最优位置,解决方案是需要让学习速率根据运行的次数越来越小。
模拟退火的思想,我们将学习速率定义为下面的函数:
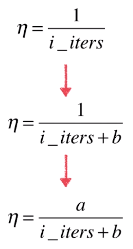
经验上比较适合的值:a = 5、b = 50;
封装随机梯度下降算法
def fit_sgd(self,X_train,y_train,eta=0.01,n_iters=5,t0=5,t1=50):
'''check'''
assert X_train.shape[0] == y_train.shape[0],\
"the size must be valid"
assert n_iters>=1,\
"the valud must be >= 1"
def dJ_sgd(theta,x_b_i,y_i):
return x_b_i*(x_b_i.dot(theta) - y_i) * 2.
def sgd(X_b,y,initial_theta,n_iters,t0=5,t1=50):
def learning_rate(t):
return t0 / (t + t1)
theta = initial_theta
m = len(X_b)
for cur_iters in range(n_iters):
indexes = np.random.permutation(m)
X_b_new = X_b[indexes]
y_train_new = y_train[indexes]
for i in range(m):
gradient = dJ_sgd(theta,X_b_new[i],y_train_new[i])
theta = theta - eta * gradient
return theta
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
initial_theta = np.zeros(X_b.shape[1])
self._theta = sgd(X_b, y_train, initial_theta, eta, n_iters)
self.coef_ = self._theta[1:]
self.interception_ = self._theta[0]
return self
后一小节将介绍小批量梯度下降算法和对梯度下降算法的更多思考















 319
319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









