







在文章写完之后,经过对比发现,其实只要把代码
KerasRegressor(build_fn=build_model, verbose=1, validation_data=(X_test, y_test))
改成:
KerasRegressor(build_fn=build_model, verbose=1)
即删掉validation_data参数便不会再报错,盲猜的确是版本问题。不过在文章后续的代码中,完整的实现了LSTM、网格搜索超参数优化、网格搜索可视化,最终还是学到不少知识。奈斯~~~~
1.需求:
在自己搭建的LSTM上实现网格搜索超参数优化,代码如下:
def build_model(learning_rate, units):
model = Sequential()
model.add(LSTM(units, input_shape=(X_train.shape[1], X_train.shape[2])))
model.add(Dense(1))
adam = optimizers.Adam(lr=learning_rate, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(loss='mae', optimizer='adam')
return model
grid_model = KerasRegressor(build_fn=build_model, verbose=1, validation_data=(X_test, y_test))
parameters = {'learning_rate': [0.01, 0.001, 0.0001],
'units ': [32, 64],
}
grid_search = GridSearchCV(estimator=grid_model,
param_grid=parameters,
cv=2)
2.问题:
出现报错如下:
RuntimeError: Cannot clone object <keras.wrappers.scikit_learn.KerasRegressor object at 0x000002A0354F8550>, as the constructor either does not set or modifies parameter validation_data
 经过多番搜寻,可能是版本问题,将sklearn回退到0.21.3,问题依旧无法解决。
经过多番搜寻,可能是版本问题,将sklearn回退到0.21.3,问题依旧无法解决。
目前的版本号如下:
 --------------------------------------------------------------------------------------------------------------------------
--------------------------------------------------------------------------------------------------------------------------
由于一直未找到解决办法,故通过其他有关网格搜索的代码进行了相关功能的实现,具体措施如下:
3.曲线解决
3.1前提:
在做回归任务中应用网格搜索导入KerasRegressor、GridSearchCV,如果是分类任务请导入KerasClassifier、GridSearchCV。
# 导入的包 可能有些没用到
import numpy as np
import pandas as pd
import tensorflow as tf
from IPython.core.display import display
from keras import optimizers
import matplotlib.pyplot as plt
from keras.layers import LSTM, Dense, Dropout
from keras.models import Sequential
from keras.utils import plot_model
from keras.wrappers.scikit_learn import KerasRegressor
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import MinMaxScaler
import warnings
import sys
import sklearn
import keras
import matplotlib as mpl
import mglearn
import timeit
此处默认已经划分好训练集X_train、 y_train和测试集X_test、 y_test,接下来从构建训练模型(LSTM)开始,并加入网格搜索。
单层LSTM + 全连接层
# 构建训练模型
def build_model(learning_rate=0.1):
model = Sequential()
model.add(LSTM(32, input_shape=(X_train.shape[1], X_train.shape[2])))
model.add(Dense(1))
adam = optimizers.Adam(lr=learning_rate, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0)
model.compile(loss='mae', optimizer='adam')
return model
grid_model = KerasRegressor(build_fn=build_model, verbose=1)
# 设置参数候选值
epochs = [40, 50, 60, 70, 80, 100]
learning_rate = [0.01, 0.001, 0.0001, 0.00001]
# 创建GridSearchCV,并训练
param_grid = dict(learning_rate=learning_rate, epochs=epochs)
grid_search = GridSearchCV(estimator=grid_model, param_grid=param_grid, scoring="neg_mean_squared_error", n_jobs=1, cv=2)
grid_result = grid_search.fit(X_test, y_test,
batch_size=32,
validation_data=(X_test, y_test))
GridSearchCV()部分参数解释:
- refit=True,默认为True,程序将会以交叉验证训练集得到的最佳参数,重新对所有可用的训练集与开发集进行,作为最终用于性能评估的最佳模型参数。即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集;
- estimator = 选择使用的估计器;
- param_grid = 需要最优化的参数的取值,值为字典或者列表;
- cv = None,交叉验证参数,默认None,使用三折交叉验证(取决于sklearn的版本); 通常使用 5, 10;
- scoring = None, 这时需要使用score函数,根据所选模型不同,评价准则不同,字符串或者自定义形如:scorer(estimator, X, y);如果是None,则使用estimator的误差估计函数。
传送门根据sklearn文档,我在此处选择了scoring=“neg_mean_squared_error”。
3.2网格搜索可视化:
# 打印结果
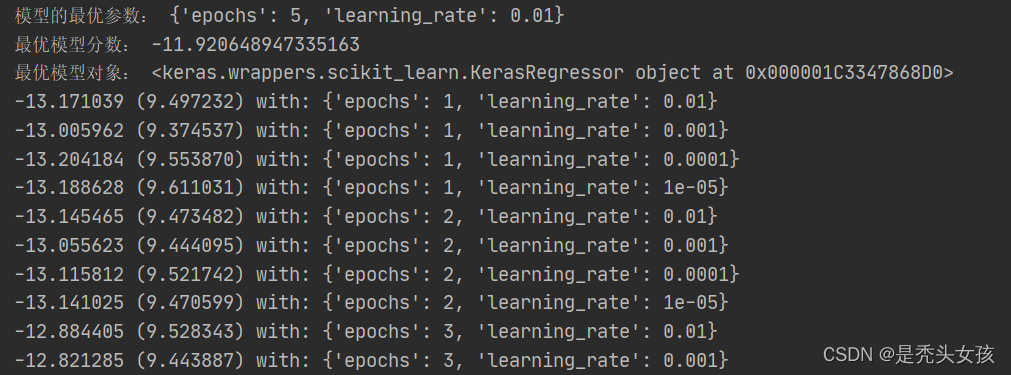
print("模型的最优参数:", grid_result.best_params_)
print("最优模型分数:", grid_result.best_score_)
print("最优模型对象:", grid_result.best_estimator_)
# # 输出网格搜索每组超参数的cv数据
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, std, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, std, param))
片段代码结果展示:
# 将cv数据转成Dataframe形式并打印,相对上述要更加详细
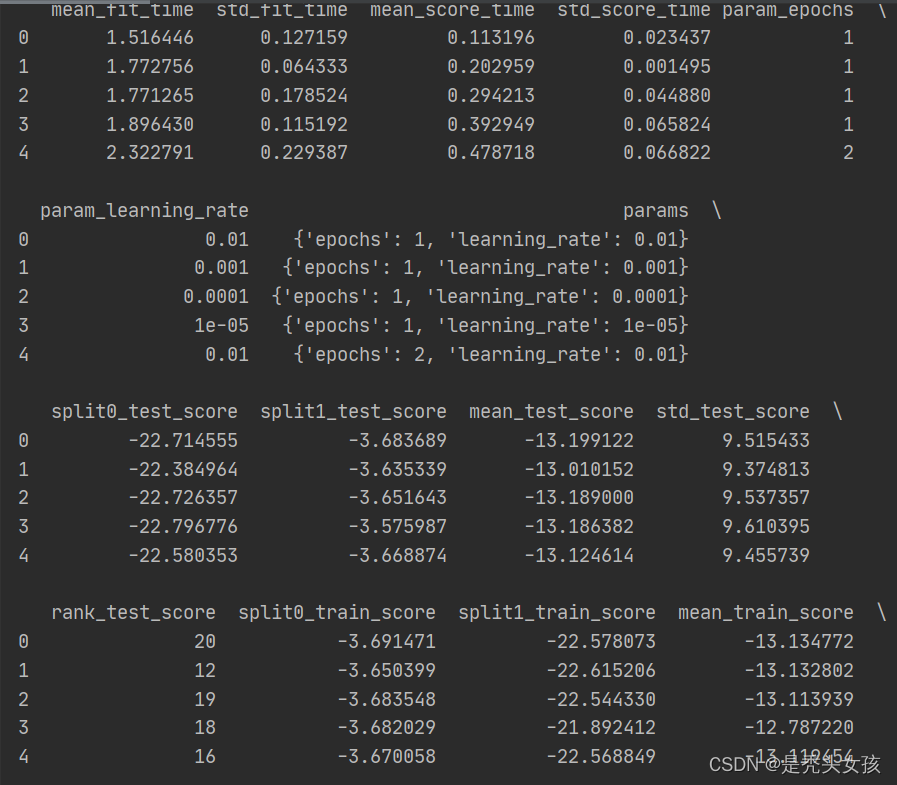
results = pd.DataFrame(grid_search.cv_results_)
# 仅展示前行
display(results.head())
片段代码结果展示:
# 超参数热力图可视化(二维网络)
scores = np.array(results.mean_test_score).reshape(len(epochs), len(learning_rate))
# plot the mean cross-validation scores
scores_image = mglearn.tools.heatmap(
scores, xlabel='learning_rate', xticklabels=param_grid['learning_rate'],
ylabel='epochs', yticklabels=param_grid['epochs'], cmap="viridis")
plt.colorbar(scores_image) # 显示热力图中最右边的条形图
plt.show()
上述在画图过程中,要注意xlabel,xticklabels, ylabel,yticklabels的值,要和cv_results_(即results.mean_test_score)相对应,可以查看打印出来的cv_results_来确定。
举例如下:根据打印出来的Dataframe中params和mean_test_score来进行对应,4行epochs,5列learning_rate,展示在热力图上x为learning_rate,y为epochs。
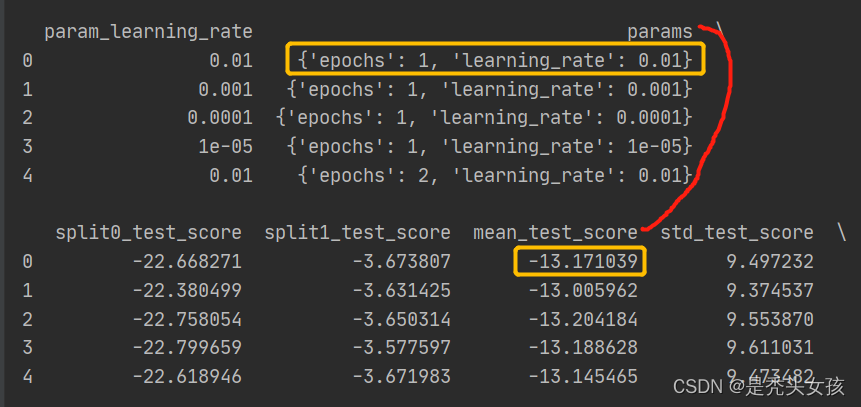
要注意绘制出来的热力图是否与之前打印的模型最优参数、评分等cv数据对应。
片段代码结果展示:
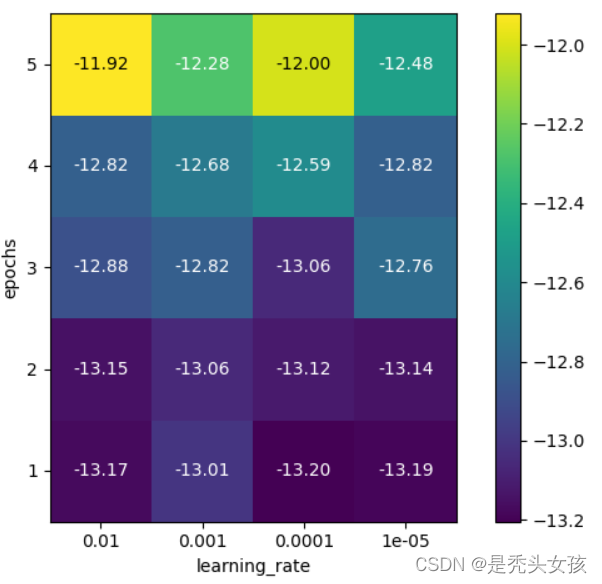
颜色表示交叉验证的得分:浅色表示高,深色表示低。
4.最终获得最优参数模型
# 获得超参数优化的最好的模型
model = grid_search.best_estimator_.model
# 进行预测
pred_test = model.predict(X_test)
5.参考博文:
1.机器学习中gridSearchCV(网格搜索)的参数、方法:主要可以了解网格搜索中相关函数的参数
2.Keras模型使用GridSearchCV自动调参:主要是用于进行参照实现了LSTM+GridSearchCV
3.机器学习 | 网络搜索及可视化:主要是学习网格搜索可视化的具体方式















 4028
4028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









