







 本文深入探讨GAT图注意力网络,一种改进自GCN的图神经网络模型,旨在克服GCN模型中对邻域节点权重分配的局限性。GAT通过引入注意力机制,为不同邻居节点指定不同权重,增强模型的空间信息捕捉能力。文章详细讲解了GAT的工作原理,包括图注意力层的输入输出、特征提取、注意力机制及multi-head attention的应用。
本文深入探讨GAT图注意力网络,一种改进自GCN的图神经网络模型,旨在克服GCN模型中对邻域节点权重分配的局限性。GAT通过引入注意力机制,为不同邻居节点指定不同权重,增强模型的空间信息捕捉能力。文章详细讲解了GAT的工作原理,包括图注意力层的输入输出、特征提取、注意力机制及multi-head attention的应用。
作者:張張張張
github地址:https://github.com/zhanghekai
【转载请注明出处,谢谢!】
G
A
T
GAT
GAT源代码地址:https://github.com/PetarV-/GAT
G
A
T
GAT
GAT论文地址:https://arxiv.org/pdf/1710.10903.pdf
\qquad G A T GAT GAT是在 G C N GCN GCN的基础上进行改进而得以实现的,不熟悉 G C N GCN GCN的朋友可以阅读我的另一篇文章【图结构】之图神经网络GCN详解,关于输入的特征矩阵的生成方式以及最后如何用 G A T GAT GAT或 G C N GCN GCN进行分类,都在这篇文章中有所讲述!
文章目录
一、在GCN中引入注意力机制——GAT
在
G
C
N
GCN
GCN详解那篇文章最后我们提出了
G
C
N
GCN
GCN的两个缺点,
G
A
T
GAT
GAT就是来解决这两个缺点的:
G
C
N
GCN
GCN缺点:
- 这个模型对于同阶的邻域上分配给不同的邻居的权重是完全相同的(也就是 G A T GAT GAT论文里说的:无法允许为邻居中的不同节点指定不同的权重)。这一点限制了模型对于空间信息的相关性的捕捉能力,这也是在很多任务上不如 G A T GAT GAT的根本原因。
- G C N GCN GCN结合临近节点特征的方式和图的结构依依相关,这局限了训练所得模型在其他图结构上的泛化能力。
\qquad G r a p h A t t e n t i o n N e t w o r k ( G A T ) Graph Attention Network (GAT) GraphAttentionNetwork(GAT)提出了用注意力机制对邻近节点特征加权求和。 邻近节点特征的权重完全取决于节点特征,独立于图结构。 G A T GAT GAT和 G C N GCN GCN的核心区别在于如何收集并累和距离为1的邻居节点的特征表示。 图注意力模型 G A T GAT GAT用注意力机制替代了 G C N GCN GCN中固定的标准化操作。本质上, G A T GAT GAT只是将原本 G C N GCN GCN的标准化函数替换为使用注意力权重的邻居节点特征聚合函数。
G A T GAT GAT优点:
- 在 G A T GAT GAT中,图中的每个节点可以根据邻节点的特征,为其分配不同的权值。
- G A T GAT GAT的另一个优点在于,引入注意力机制之后,只与相邻节点有关,即共享边的节点有关,无需得到整张图的信息:(1)该图不需要是无向的(如果边缘 j → i j\to i j→i不存在,我们可以简单地省略计算 α i j \alpha_{ij} αij);(2)它使我们的技术直接适用于 i n d u c t i v e    l e a r n i n g inductive\;learning inductivelearning——包括在训练期间完全看不见的图形上的评估模型的任务。
二、图注意力层Graph Attention layer
2.1 图注意力层的输入与输出
-
图注意力层的输入是:一个节点特征向量集:
h = { h ⃗ 1 , h ⃗ 2 , ⋯ , h ⃗ N } , h ⃗ i ∈ R F h=\{\vec{h}_1,\vec{h}_2,\cdots,\vec{h}_N\},\vec{h}_i\in \R^F h={h1,h2,⋯,hN},hi∈RF
其中 N N N为节点个数, F F F为节点特征的个数。矩阵 h h h的大小是 N × F N\times F N×F,代表了所有节点的特征,而 R \R R只代表了某一个节点的特征,所以它的大小为 F × 1 F \times 1 F×1。输出同理。 -
每一层的输出是:一个新的节点特征向量集:
h ′ = { h ′ ⃗ 1 , h ′ ⃗ 2 , ⋯ , h ′ ⃗ N } , h ′ ⃗ i ∈ R F ′ h'=\{ \vec{h'}_1,\vec{h'}_2,\cdots,\vec{h'}_N\},\vec{h'}_i\in \R^{F'} h′={h′1,h′2,⋯,h′N},h′i∈RF′
其中 F ′ F' F′表示新的节点特征向量维度(可以不等于 F F F)。
\qquad G A T GAT GAT与 G C N GCN GCN同样也是一个特征提取器,针对的是 N N N个节点,按照其输入的节点特征预测输出新的节点的特征。
2.2 特征提取与注意力机制
\qquad 为了得到相应的输入与输出的转换,我们需要根据输入的特征至少进行一次线性变换得到输出的特征,所以我们需要对所有节点训练一个权重矩阵: W ∈ R F ′ × F W\in\R^{F' \times F} W∈RF′×F,这个权重矩阵就是输入的 F F F个特征与输出的 F ′ F' F′个特征之间的关系。
\qquad
针对每个节点实行
s
e
l
f
−
a
t
t
e
n
t
i
o
n
self-attention
self−attention的注意力机制,注意力系数
(
a
t
t
e
n
t
i
o
n
  
c
o
e
f
f
i
c
i
e
n
t
s
)
(attention \;coefficients)
(attentioncoefficients)为:
(1)
e
i
j
=
a
(
W
h
⃗
i
,
W
h
⃗
j
)
e_{ij}=a(W\vec{h}_i,W\vec{h}_j)\tag{1}
eij=a(Whi,Whj)(1)
注意:
a
a
a不是一个常数或是矩阵,
a
(
)
a()
a()是一个函数,类似于
f
(
x
)
f(x)
f(x)那种自己定义好的函数。
- 这个公式表示了节点 j j j对节点 i i i的重要性,而不去考虑图结构的信息。
- 如前面介绍过的,向量 h h h就是节点的特征向量。
- 下标 i , j i,j i,j表示第 i i i个节点和第 j j j个节点。
★什么是 s e l f − a t t e n t i o n self-attention self−attention机制?
\qquad s e l f − a t t e n t i o n self-attention self−attention其作用是能够更好地学习到全局特征之间的依赖关系, s e l f − a t t e n t i o n self-attention self−attention通过直接计算图结构中任意两个节点之间的关系,一步到位地获取图结构的全局几何特征。
\qquad s e l f − a t t e n t i o n self-attention self−attention利用了 a t t e n t i o n attention attention机制,分三个阶段进行计算:(1) 引入不同的函数和计算机制,根据 Q u e r y Query Query和某个 K e y i Key_i Keyi,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量 C o s i n e Cosine Cosine相似性或者通过再引入额外的神经网络来求值;(2) 引入类似 s o f t m a x softmax softmax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为 1 1 1的概率分布;另一方面也可以通过 s o f t m a x softmax softmax的内在机制更加突出重要元素的权重;(3)第二阶段的计算结果 a i a_i ai即为 v a l u e i value_i valuei对应的权重系数,然后进行加权求和即可得到 a t t e n t i o n attention attention数值。
\qquad
作者通过
m
a
s
k
e
d
  
a
t
t
e
n
t
i
o
n
masked \;attention
maskedattention将这个注意力机制引入图结构中,
m
a
s
k
e
d
  
a
t
t
e
n
t
i
o
n
masked \;attention
maskedattention的含义是:仅将注意力分配到节点
i
i
i的邻居节点集
N
i
N_i
Ni上,即
j
∈
N
i
j \in N_i
j∈Ni (在本文中,节点
i
i
i也是
N
i
N_i
Ni的一部分)。 为了使得注意力系数更容易计算和便于比较,我们引入了
s
o
f
t
m
a
x
softmax
softmax对所有的
i
i
i的相邻节点
j
j
j进行正则化:
(2)
α
i
j
=
s
o
f
t
m
a
x
j
(
e
i
j
)
=
e
x
p
(
e
i
j
)
∑
k
∈
N
i
e
x
p
(
e
i
k
)
\alpha_{ij}=softmax_j(e_{ij})=\frac{exp(e_{ij})}{\sum_{k\in N_i}exp(e_{ik})}\tag{2}
αij=softmaxj(eij)=∑k∈Niexp(eik)exp(eij)(2)
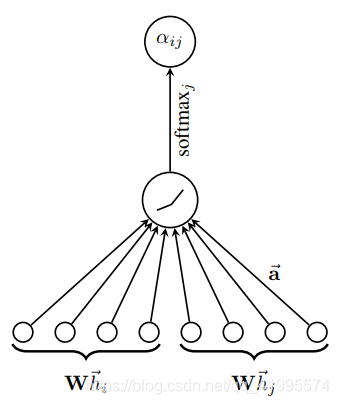
\qquad 实验之中,注意力机制 a a a是一个单层的前馈神经网络, a ⃗ ∈ R 2 F ′ \vec{\rm{a}}\in\R^{2F'} a∈R2F′是神经网络中连接层与层之间的权重矩阵,在该前馈神将网络的输出层上还加入了 L e a k y R e L u LeakyReLu LeakyReLu函数,这里小于零斜率为 0.2 0.2 0.2。
★什么是 L e a k y R e L u LeakyReLu LeakyReLu函数?
\qquad R e L u ReLu ReLu是将所有的负值都设为零,相反, L e a k y R e L u LeakyReLu LeakyReLu是给所有负值赋予一个非零斜率,在本论文中以数学的方式我们可以表示为:
y i = { x i i f    x i ≥ 0 0.2 i f    x i ≤ 0 y_i=\begin{cases}x_i & if\;x_i\geq0\\0.2 & if\;x_i\leq0\end{cases} yi={xi0.2ifxi≥0ifxi≤0
\qquad
综合上述公式(1)和(2),整理到一起可得到完整的注意力机制如下:
(3)
α
i
j
=
e
x
p
(
L
e
a
k
y
R
e
L
u
(
a
⃗
T
[
W
h
⃗
i
∣
∣
W
h
⃗
j
]
)
)
∑
k
∈
N
i
e
x
p
(
L
e
a
k
y
R
e
L
u
(
a
⃗
T
[
W
h
⃗
i
∣
∣
W
h
⃗
k
]
)
)
\alpha_{ij}=\frac{exp(LeakyReLu(\vec{\rm{a}}^T[W\vec{h}_i||W\vec{h}_j]))}{\sum_{k\in N_i}exp(LeakyReLu(\vec{\rm{a}}^T[W\vec{h}_i||W\vec{h}_k]))}\tag{3}
αij=∑k∈Niexp(LeakyReLu(aT[Whi∣∣Whk]))exp(LeakyReLu(aT[Whi∣∣Whj]))(3)
- ∣ ∣    ||\; ∣∣符号的意思是连接操作 ( c o n c a t e n a t i o n    o p e r a t i o n ) (concatenation \;operation) (concatenationoperation)
- ⋅ T \cdot ^T ⋅T表示为转置
注意: e i j e_{ij} eij和 α i j \alpha_{ij} αij都叫做"注意力系数",只不过 α i j \alpha_{ij} αij是在 e i j e_{ij} eij基础上进行归一化后的。
上述过程可用下图来表示:
2.3 输出特征
\qquad
通过上述运算得到了正则化后的不同节点之间的注意力系数,可以用来预测每个节点的输出特征:
(4)
h
′
⃗
i
=
σ
(
∑
j
∈
N
i
α
i
j
W
h
⃗
j
)
\vec{h'}_i=\sigma(\sum_{j \in N_i}\alpha_{ij}W\vec{h}_j)\tag{4}
h′i=σ(j∈Ni∑αijWhj)(4)
- W W W为与特征相乘的权重矩阵
- α \alpha α为前面计算得到的注意力互相关系数
- σ \sigma σ为非线性激活函数
- j ∈ N i j \in N_i j∈Ni中遍历的 j j j表示所有与 i i i相邻的节点
- 这个公式表示就是:该节点的输出特征与和它相邻的所有节点有关,是它们的线性和的非线性激活后得到的。
2.4 multi-head attention
\qquad
为了稳定
s
e
l
f
−
a
t
t
e
n
t
i
o
n
self-attention
self−attention的学习过程,作者发现扩展我们的机制以采用
m
u
l
t
i
−
h
e
a
d
  
a
t
t
e
n
t
i
o
n
multi-head\;attention
multi−headattention是有益的。具体而言,
K
K
K个独立注意力机制执行公式(4),然后将它们的特征连接起来。但是,如果我们对最终的网络层执行
m
u
l
t
i
−
h
e
a
d
  
a
t
t
e
n
t
i
o
n
multi-head\;attention
multi−headattention,则连接操作不再合理,相反,我们采用
K
K
K平均来替代连接操作,并延迟应用最终的非线性函数(通常为分类问题的
s
o
f
t
m
a
x
softmax
softmax或
l
o
g
i
s
t
i
c
  
s
i
g
m
o
i
d
logistic \;sigmoid
logisticsigmoid),得到最终的公式:
h
′
⃗
i
=
σ
(
1
K
∑
k
=
1
K
∑
j
∈
N
i
α
i
j
k
W
k
h
⃗
j
)
\vec{h'}_i=\sigma(\frac{1}{K}\sum_{k=1}^{K}\sum_{j\in N_i}\alpha_{ij}^kW^k\vec{h}_j)
h′i=σ(K1k=1∑Kj∈Ni∑αijkWkhj)
- 共 K K K个注意力机制需要考虑, k k k表示 K K K中的第 k k k个
- 第 k k k个注意力机制为 a k a^k ak
- 第 k k k个注意力机制下输入特征的线性变换权重矩阵表示为 W k W^k Wk
★什么是 m u l t i − h e a d    a t t e n t i o n multi-head\;attention multi−headattention ?
\qquad 这里面 m u l t i − h e a d    a t t e n t i o n multi-head\;attention multi−headattention其实就是多个 s e l f − a t t e n t i o n self-attention self−attention结构的结合,每个 h e a d head head学习到在不同表示空间中的特征,多个 h e a d head head学习到的 a t t e n t i o n attention attention侧重点可能略有不同,这样给了模型更大的容量。
m
u
l
t
i
−
h
e
a
d
  
a
t
t
e
n
t
i
o
n
multi-head\;attention
multi−headattention图例:
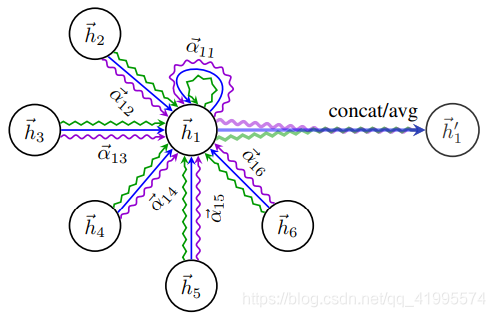
\qquad
由节点
h
⃗
1
\vec{h}_1
h1在其邻域上的
m
u
l
t
i
−
h
e
a
d
  
a
t
t
e
n
t
i
o
n
multi-head\;attention
multi−headattention(具有
K
=
3
K = 3
K=3个头)的图示。不同的箭头样式和颜色表示独立的注意力计算,来自每个头的聚合特征被连接或平均以获得
h
′
⃗
1
\vec{h'}_1
h′1。
三、GAT实现分类
\qquad G A T GAT GAT的分类过程与 G C N GCN GCN的分类过程十分相似,均是采用 s o f t m a x softmax softmax函数 + + +交叉熵损失函数 + + +梯度下降法来完成的,详细内容可参阅我的另一篇文章【图结构】之图神经网络GCN详解
【参考文献】

















 7780
7780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









