






1
什么是Maven?
一个大型的 Web 项目,需要依赖很多第三方类库,不同 Jar 包之间还有复杂的依赖关系;这时,Maven 出现了,我们只需要告诉它需要的 Jar 包,它会帮我们自动下载并管理它们。
Maven就是这样一个项目管理工具,它包含了一个对象模型。一组标准集合,一个依赖管理系统。
Maven的核心思想?
约定大于配置。Maven会约定一些规则,不能违反,比如项目的目录结构。
Spring
什么是Spring?
Spring是一个轻量级的容器(框架),如果加上定语:
Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器(框架)。
Spring全家桶的组成?
Spring Framework:Spring的核心;
Spring Boot:构建项目,可以用它快速开发单个微服务;
Spring Cloud:协调微服务,可以将一个大项目拆分成多个小项目分而治之;
Spring Cloud Data Flow:连接数据源,集成多个平台数据。
再深入到Spring Framework
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LQbN1ZYO-1685417610806)(C:\Users\DoubleC\Desktop\小白要找工作\images\image-20230530090328053.png)]
Spring由二十多个小模块组成,下面只列举这个项目中用到的技术栈。
- Core Container(核心容器)
- 控制反转(IoC)
- Data Access(数据访问)
- Spring MyBatis
- Web(Web开发)
- Spring MVC
- Data Integration(数据集成)
- Email:发邮件
- Scheduling:定时任务
- AMQP:消息队列
- Security:安全控制
什么是IoC?
控制反转(IoC)是一种管理对象 Bean 的设计思想,它将手动创建 Bean 对象的权力交给 Spring 框架。这样我们在创建对象时就只需要添加相应的注解或配置文件,而不用考虑如何创建它。
它的优点:降低耦合,我们在将Bean对象交给容器管理时,需要对象的定义和配置文件,各对象之间的关系在配置文件中声明,不会直接产生耦合。
依赖注入(DI):是IoC的实现方式;
IoC容器(IoC Container):是依赖注入的关键。本质上是一个工厂,数据结构是Map。
IoC 容器控制了对象,主要控制了外部资源获取。反转则是由容器来帮忙创建及注入依赖对象
有了IoC容器后,把创建和查找依赖对象的控制权交给了容器,由容器进行注入组合对象,所以对象与对象之间是松散耦合,这样也方便测试,利于功能复用,更重要的是使得程序的整个体系结构变得非常灵活
对象Bean如何使用?
Bean常见的四种注解:
@Controller
@Repository
@Service
@Component
如何使用Bean:
使用依赖注入:@AutoWired
Spring MVC
为什么要引入Spring MVC?
在早期 Web 开发中,控制层、业务层和数据访问层均交给 JSP 或 Java Bean 处理,这样做的弊端:
- JSP和Java Bean严重耦合;Java和Html耦合;
- 技术人员除了需要 Java 知识,还需要前端技术栈才可以工作;
- 前端依赖后端,后端依赖前端,工作效率很低;
- 代码复用性差;
什么是Spring MVC?
- M 代表模型(Model):模型就是数据,如:dao , bean
- V 代表视图(View):视图用于展示数据,如:网页,JSP
- C 代表控制器(Controller):控制器用于接收用户请求,将不同的数据展现在不同的视图上。
Spring MVC的架构?
MVC 三者都属于该表现层。(controller、service、dao)
补充一个小知识点:模板引擎Thymeleaf:用于生成动态Html。
项目开发顺序!
了解了MVC的基本原理,大概的开发顺序就跃然纸上。
开发顺序与调用顺序相反,这个很好理解,因为后面的依赖前面的。
Dao -> Service -> Controller
- entity:开发属性名;
- Dao:写接口,定义方法头;
- Mapper:写配置文件.xml,实现接口,Bean对象生成;
- MapperTests:添加AutoWired注解注入Mapper,测试Bean;
- service:添加Service注解,还要添加AutoWired注解注入Mapper,开发业务代码,根据不同逻辑返回值,将返回值交给controller;
- controller:添加Controller注解,同样要注入Mapper,根据service传过来的不同返回值处理请求,将查询到的数据通过model传给模板;
- .html:模板就是html文件,将数据渲染为视图View展示给用户。
Spring Boot
什么是Spring Boot?
一个Java Web的开发框架,和Spring MVC类似。但其实Spring Boot也不是什么新的框架,它默认配置了很多框架的使用方式,就像maven整合了所有的jar包,spring boot整合了所有的框架 。
演化过程:J2EE -> Spring -> Spring Boot
Spring Boot的核心思想?
约定大于配置。默认帮我们进行了很多设置,多数 Spring Boot 应用只需要很少的 Spring 配置。
Spring Boot的优势?
- 为所有Spring开发者更快的入门
- 开箱即用,提供各种默认配置来简化项目配置
- 内嵌式容器简化Web项目
- 没有冗余代码生成和XML配置的要求
- 调试技巧
响应状态码有哪些?
- 2开头:成功响应;
- 3开头:重定向,向浏览器返回需要再次访问的地址,浏览器再次访问。重定向的作用:使用一种低耦合的方式实现功能的跳转;
- 4开头:客户端响应失败;
- 5开头:服务器已经接收请求,但响应失败
如何调试?
先打印日志,分析;
如果还是不行,根据响应状态码定位是客户端还是服务端的问题,确定之后打断点Debug。
Git
- commit、push、pull是什么意思?
- commit:提交到本地数据库;
- push:同步到远程数据库;
- pull:将服务器的代码拉取到本地;
- update:pull时如果发现代码冲突,会弹出一个解决冲突的窗口,在这里解决;
Git 回退的三种类型?
- mixed:为默认值,等同于git reset。将文件回退到工作区,此时会保留工作区中的文件,但会丢弃暂存区中的文件;
- soft:将文件回退到暂存区,此时会保留工作区和暂存区中的文件;
- hard:将文件回退到修改前,此时会丢弃工作区和暂存区中的文件;
2
注册
如何实现注册功能?
- 将注册信息发给服务器;
- 服务器发送邮件给注册时的邮箱;
- 用户点击激活链接完成注册。
会话管理
HTTP协议的特点?
HTTP是无状态的:一个浏览器向一个服务器发送的请求都是独立的,服务器记不住浏览器的状态;使用Cookies可以创建有状态的会话。
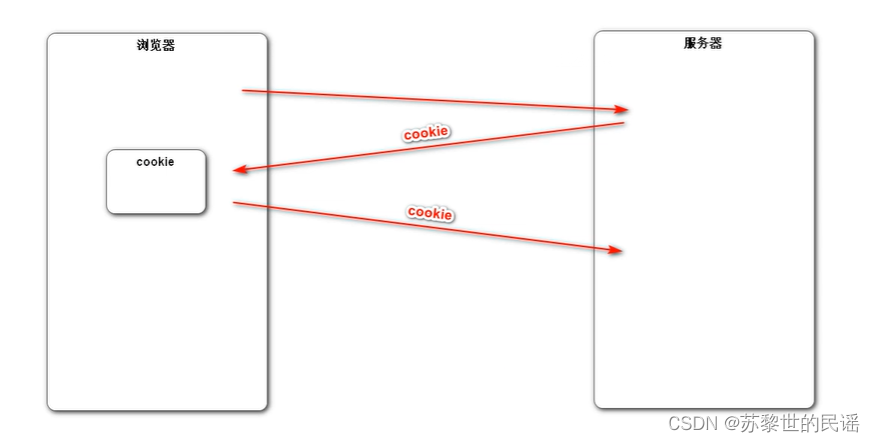
解法一:Cookies
服务器发送给浏览器并保存在本地的一小块数据,浏览器下一次向同一服务器发送请求时携带它给服务器,服务器根据Cookies迅速查找,找到该用户的活动记录。
解法二:Session
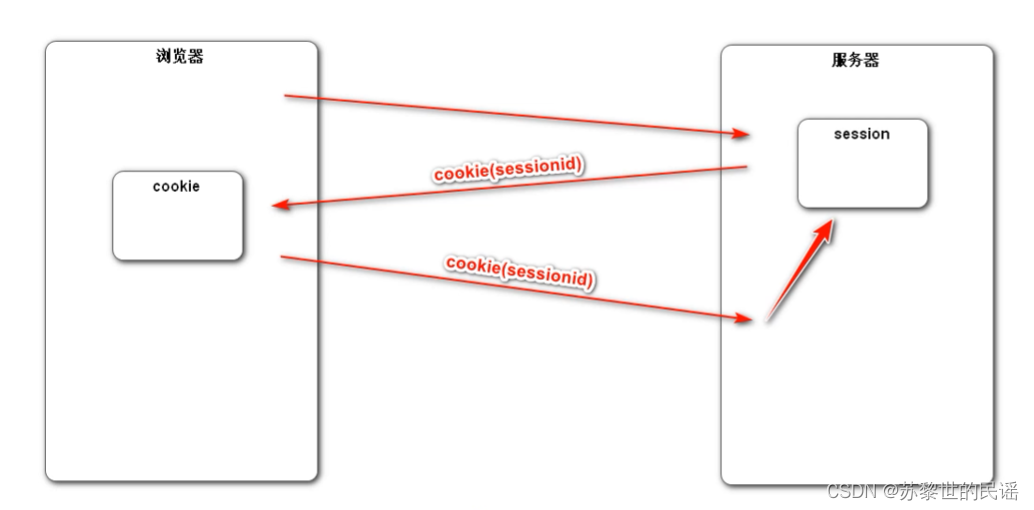
在服务端记录客户端信息,只需要传送 session 的 id ,提高安全性,但增加了服务端的内存压力。
拦截器
什么是拦截器?
Interceptor,用于拦截不合理的请求。比如:没登录,但想通过输入网址访问信息页面,当然不行了!
Spring加载项目时,会按默认顺序将这些拦截器注册进来,将来的调用顺序就是这个注册顺序。当然,对于自定义的拦截器,你可以定义它的注册顺序。
三个重要方法?
preHandle():在调用Controller方法或获取静态资源前被调用(静态资源包括html、js等)。postHandle():在调用Controller方法或获取静态资源后,但是视图还没有被渲染前调用。afterCompletion():在视图渲染后进行调用,主要用来清除资源。
拦截器在项目中的应用?
-
拦截登录请求
- 自定义登录需要的注解
preHandle()方法判断是否有置顶注解,没有则拦截
-
拦截登录凭证
-
preHandle()方法:
- 从Cookie中获取凭证ticket
- 根据凭证查询用户,将用户信息放入在本次请求中
- 构建用户认证的结果,并存入SecurityContext,以便于Security进行授权
-
postHandle()方法:
- 将用户信息添加到modelAndView中
-
afterCompletion()方法:
- 释放资源
-
补充:常用快捷键
ctrl + Shift + F 全局查找
ctrl + Shift + N 查找类
3
过滤敏感词
Java原生API的缺点?
Java自带的原生API也可以实现过滤敏感词,但若遇到大篇幅文章,replace方法性能就太低了。
故使用前缀树方法,此方法用空间换时间,以消耗内存为代价。
过滤敏感词的基本原理?
- 用到三个指针,第一个指针指向树的结点,根节点为空。如下图:

- 用两个指针遍历字符串,上面的为begin,下面的为position。begin先移动,同时树指针检查root的子节点,若二者匹配则树指针指向子节点position++;若二者没有匹配则begin++position++。直到position遍历完整个字符串(相比begin遍历完整个字符串更节约性能一点)。最终begin~position即为敏感词,用“**”替换。
特点:begin只进不退,position以当前begin为起点,来回跳动。
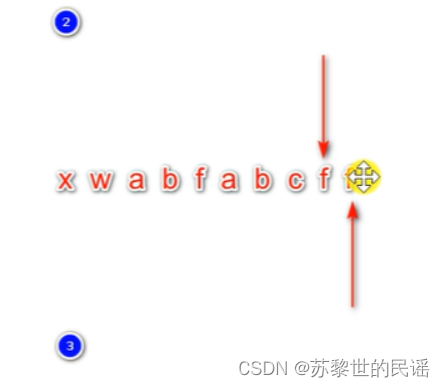
- StringBuilder是一个类,用来拼接字符串,这里我们用作存储结果字符串。

异步请求
什么是异步请求?
整个网页不刷新,访问服务器,得到数据后返回给网页,局部刷新。实现异步请求的技术叫AJAX。网页能够将增量更新呈现在页面上。
什么是AJAX?
AJAX指异步的json和xml技术,不是一门新的语言,而是使用现有技术的新方法。项目中帖子发布成功/失败的提示使用该技术。
事务管理
什么是事务?
事务是由N步数据库操作序列组成的逻辑执行单元,这一系列操作要么全执行,要么全放弃执行。即一旦开始,必须全部执行完。
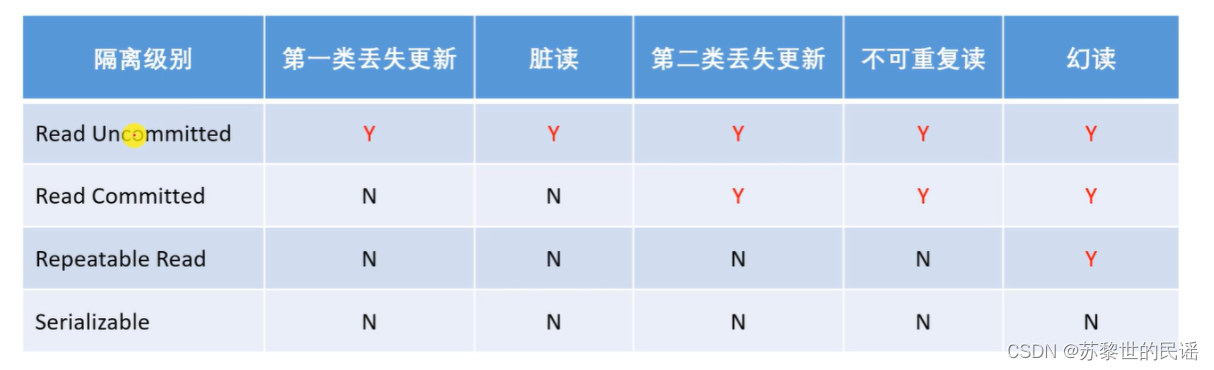
常见的并发异常有哪些?
- 第一类丢失更新:某一个事务回滚,会导致另一个事务已更新的数据丢失。
- 第二类丢失更新:某一个事务提交,会导致另一个事务已更新的数据丢失。
- 脏读:某一个事务读取了另一个事务未提交的数据。
- 不可重复读:某一个事务对同一个数据前后读取的结果不一致。
- 幻读:某一个事务对同一个表前后查询的行数不一致。
常见的隔离级别有哪些?
- Read Uncommitted:读取未提交的数据。
- Read Committed:读取已提交的数据。
- Repeatable Read:可重复读。
- Serializable:串行化。
事务的实现机制有哪些?
-
悲观锁(数据库)
- 共享锁(S锁):事务A对某数据加了共享锁,其他事务只能加共享锁,不能加排他锁。(只读不写)
- 排他锁(X锁):事务A对某数据加了排他锁,其他事务不能加共享锁,也不能加排他锁。(不读不写)
-
乐观锁(自定义)
更新前检查版本号/时间戳,若未变化则更新,否则取消本次更新。
统一捕获异常
怎样实现统一捕获异常?
服务器的三层结构中,错误会层层向上传递,所以只需要在表现层(controller)统一处理错误即可。
在Spring Boot的项目某一路径下,加上对应的错误页面,发生错误时会自动跳转。
AOP
什么是AOP?
面向切面编程,是一种编程思想,是对OOP(面向对象编程)的补充。将业务模块共同调用的逻辑封装起来,降低耦合,可以进一步提高编程效率。如下图:右上角为系统组件,这些组件横跨了多个业务组件,像切开它们一样(面向切面)。
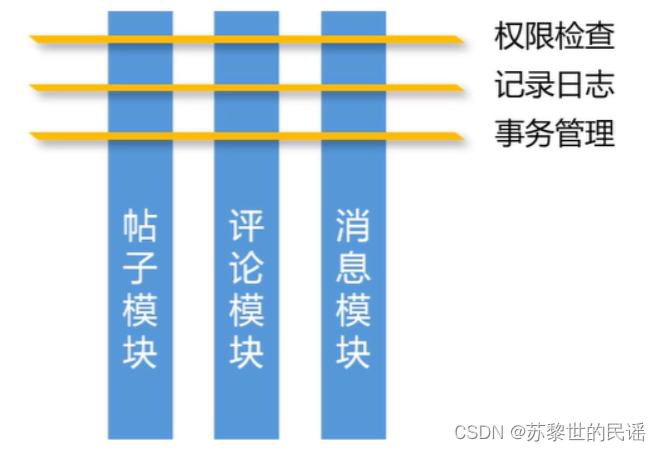
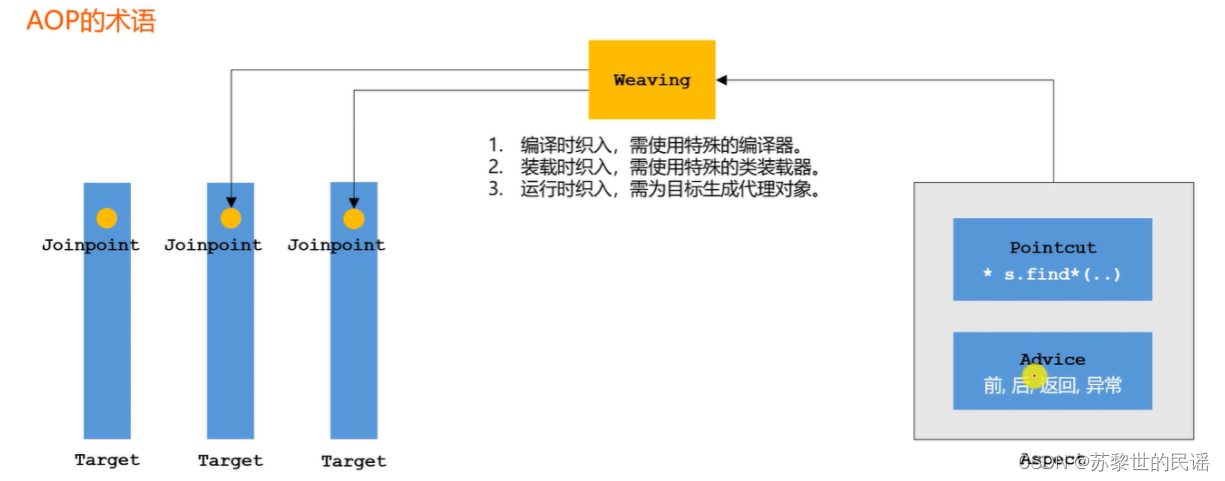
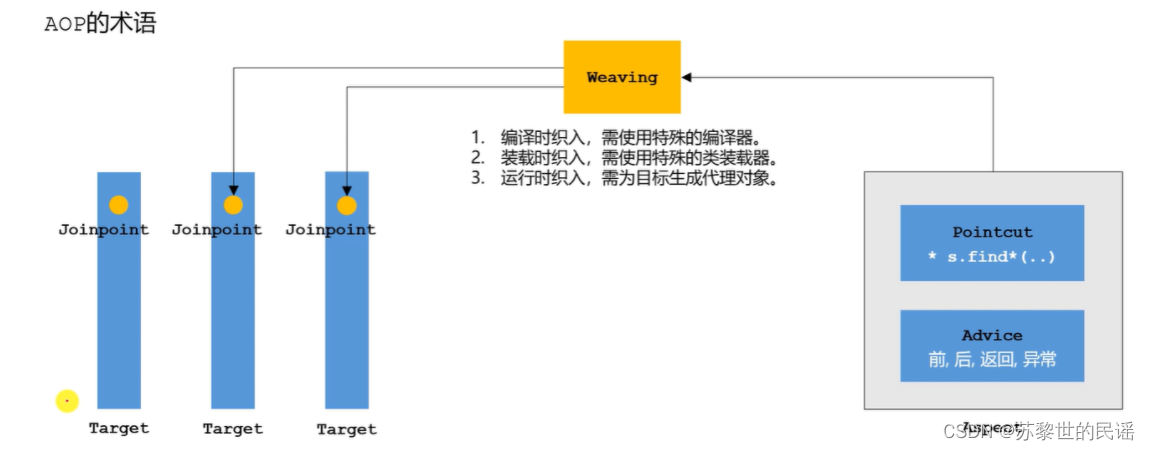
AOP的常用术语有哪些?
我们只需要编写Aspect封装组件的代码,通过Weaving(织入)到目标代码的连接点(Jionpoint)进行控制。
切点(Pointcut)控制织入的具体位置;
通知(Advice)控制织入的具体逻辑。
什么是Spring AOP?
Spring AOP本质上基于动态代理,当要代理的对象实现了某接口,会使用JDK动态代理,在运行时通过创建接口的代理实例,织入代码。当要代理的对象没有实现接口,则使用Cglib技术(编译时增强),通过子类代理织入代码。
怎样实现统一记录日志?
本项目中,将aspect织入所有业务模块,通过这段代码,实现统一记录日志。

4
Redis
什么是NoSQL?
在我们日常的Java Web开发中,一旦涉及大数据量的需求,只使用数据库来保存数据的系统会因为面向磁盘,磁盘读/写速度比较慢的问题而存在严重的性能弊端。这时就需要引入NoSQL技术,它是一种基于内存的数据库,并且提供一定的持久化功能。
为什么引入Redis?
在日常对数据库的访问中,读操作的次数远超写操作,比例大概在 1:9 到 3:7,如果每次都去数据库读数据,性能太低。
所以我们将一些常用数据存储在内存中,读写速度快。同时Redis可以将数据以快照或日志的形式存储在硬盘上,从而保证安全性。
哪些数据适合放入缓存?
同时满足以下三个条件:
- 常用
- 读操作远多于写
- 数据量小
什么是Redis?
Redis是一款基于键值对的NoSQL数据库。管理缓存中的数据。可以存储键和五种不同数据类型的映射。其中,键必须是字符串类型,值可以是:字符串、哈希散列表、列表(栈与队列均可)、无序集合、有序集合。
项目中Redis的作用?
存储验证码、登录凭证、用户信息。
MyBatis
找了半天,在项目里看不到它的身影,原来在dao层定义接口,用xml文件实现mapper,就是用到了它。
什么是MyBatis?
是一款持久层框架
什么是持久化?
持久化是将数据在瞬时状态与持久状态相互转换的机制。
如:将缓存数据存入数据库,文件IO
为什么要引入持久化?
- 内存中数据一旦断电就会丢失,需要保证数据的可用性
- 将数据存入内存成本高,维护难度大
为什么要使用MyBatis?
- 数据存取。帮助我们将数据存入数据库和从数据库中取出数据
- 代码复用。使用框架可以避免每次连接数据库、取出数据的封装等一系列冗余操作,提高代码复用性
- 解耦。通过dao层将sql与业务逻辑分离
5
消息队列
什么是阻塞队列?
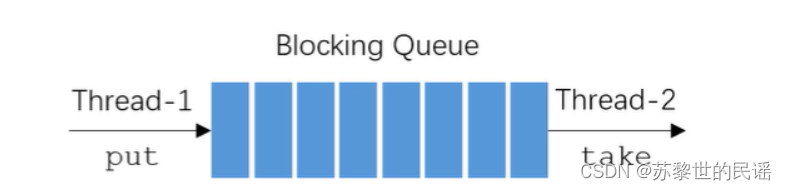
阻塞队列,一种内部进行加锁控制的队列,它是线程安全的。当队列满时,生产者生产被阻塞;当队列空时,消费者消费被阻塞。
为什么要使用消息队列?
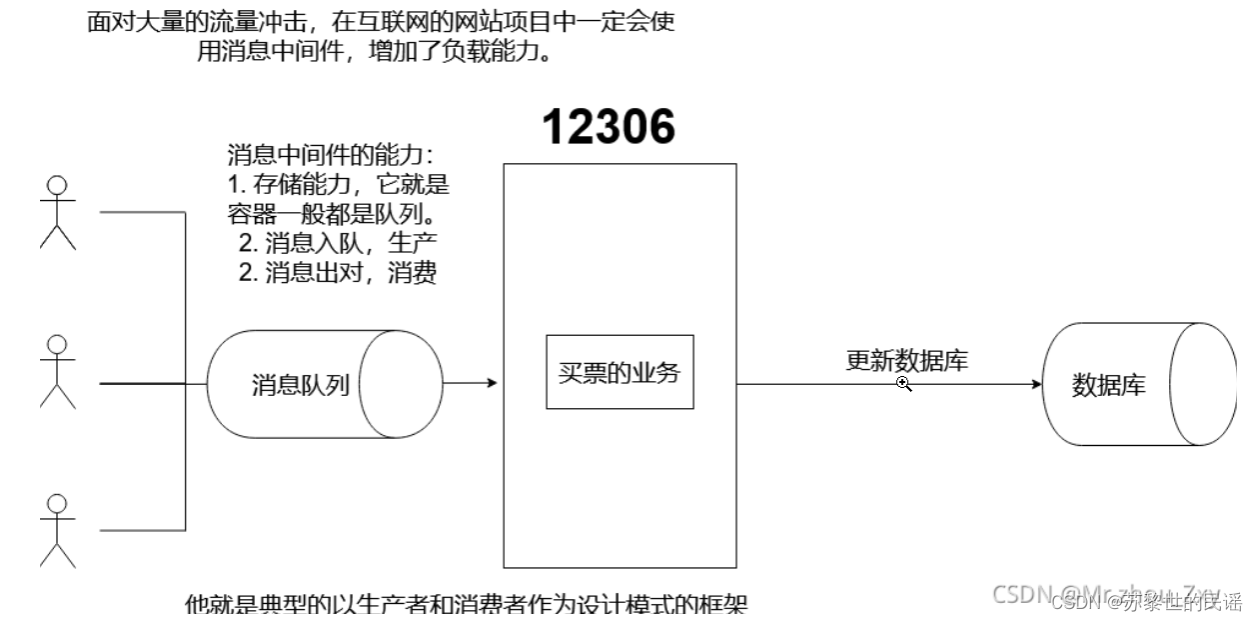
如图,12306购票系统,在将买票业务呈现在用户面前之前,使用一个消息队列,用于控制消息入队和出队的速度。如果没有它,把全部数据存入数据库,系统肯定要崩!
什么是消息队列?
消息队列(MQ),是一种消息中间件,同时也是一种更高性能的阻塞队列。通过topic对数据进行分类,支持多个业务的多组数据。
消息队列的分类?
MQ分为两种:
- P2P : peer to peer
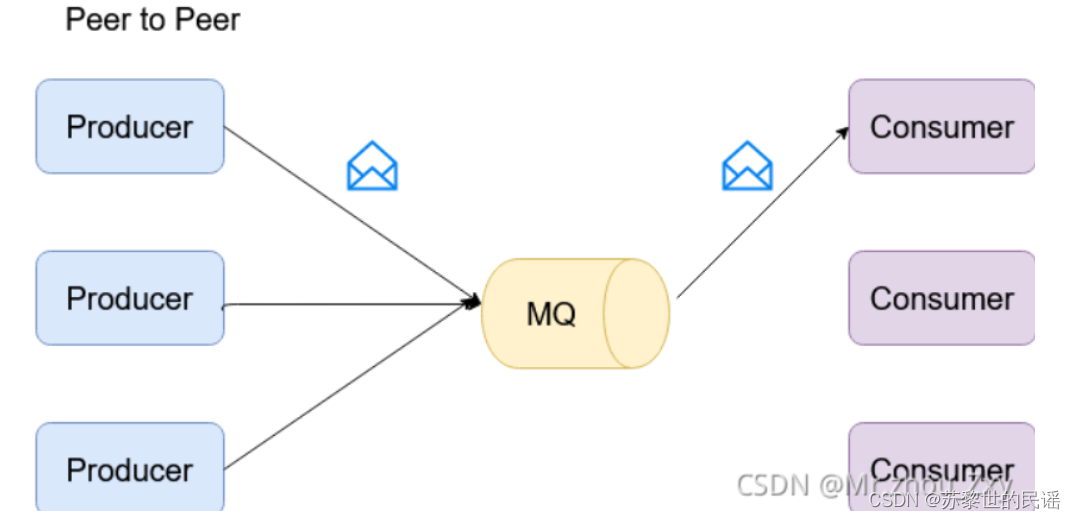
该模式中,一条数据只能被一个消费者消费,消费后即出队。 - Pub/Sub : 发布与订阅
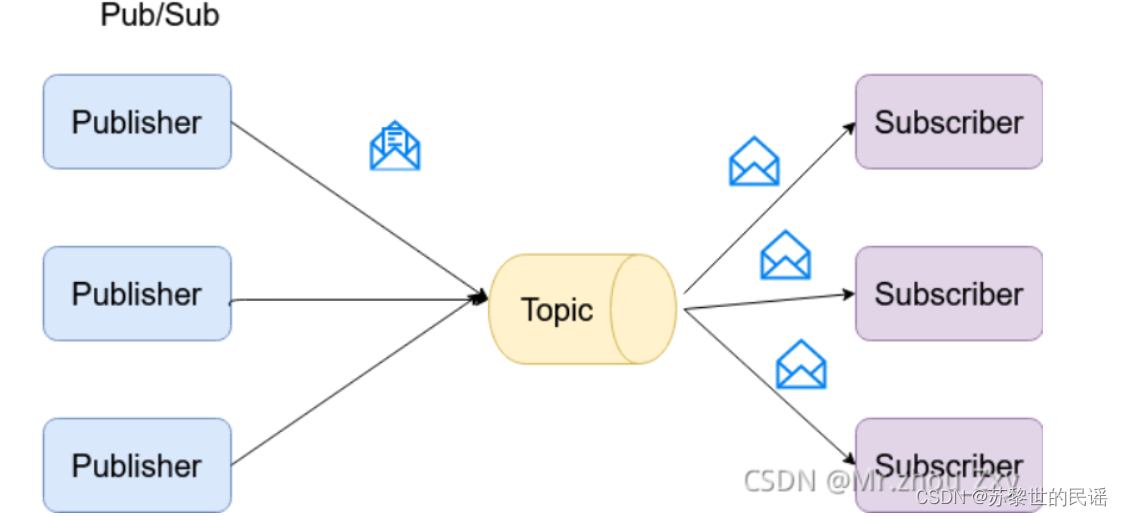
该模式中,一条数据可以被多个消费者消费,数据存在某个位置,消费者按索引获取。
Kafka
什么是Kafka?
kafka 是一个分布式的基于消息的发布-订阅的消息队列,已经不只是消息队列的功能了。
应用:消息系统、日志采集、用户行为追踪、流式处理。
Kafka有哪些特点?
高吞吐量:处理TB级数据;
消息持久化:存储在硬盘中,顺序读写,性能高于随机读写内存;
高可靠性:分布式部署;
高拓展性:添加服务器很容易。
Push or Pull?
面试官问到了这个问题,做个记录
producer使用push模式发布消息,consumer使用pull模式消费消息。push是被动的,pull是主动的。
push模式的目标是尽可能快地处理消息,producer可以这样,但consumer需要考虑后续处理消息的能力,如果速率过快可能会导致服务器拒绝服务或网络拥塞。所以主动pull显然更适合。
Kafka的常用术语?
broker:kafka服务器;
Zookeeper:用于管理集群的中间件;
Topic:主题,生产者发布消息到该位置;
Partition:分区,将Topic分为多个区,便于管理;
Offset:各分区内的索引,消费者消费消息要用到。
Kafka的启动命令?
启动zookeeper
bin\windows\zookeeper-server-start.bat config\zookeeper.properties
1
启动server
bin\windows\kafka-server-start.bat config\server.properties
1
创建topic
kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
1
查看Topic
kafka-topics.bat --list --bootstrap-server localhost:9092
1
生产者生产数据
kafka-console-producer.bat --broker-list localhost:9092 --topic test
1
消费者消费数据
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
1
在项目哪里用到了Kafka?
当有点赞,评论,关注、发帖、删帖请求时,Producer发布消息。
当队列中有消息时,Consumer主动消费消息。
一直很纳闷,EventConsumer这个类里的方法,在项目任何地方都没被调用,它是怎么执行的?原来是Kafka一直监听信道,一有消息就主动pull了
6
Elasticsearch
搜索引擎的原理是什么?
建立倒排索引(反向索引):
将通过诗名找诗句,转化为 -> 先通过关键词找诗名,再找出诗句
这就是百度,谷歌的搜索原理,通过关键词找帖子标题,再点进去看详情。
什么是Elasticsearch?
- 一个分布式的、Restful风格的搜索引擎。
- 支持对各种类型的数据的检索。
- 搜索速度快,可以提供实时的搜索服务。
- 便于水平拓展,每秒可以处理PB级海量数据。
Elasticsearch术语有哪些?
与Mysql对应:左边是Elasticsearch术语
版本6.0以前:索引 -> 数据库,类型 -> 表,文档 -> 行,字段 -> 列
版本7.0以后:索引 -> 表,文档 -> 行,字段 -> 列
文档一般是JSON类型,存储一行数据
如何在Elasticsearch中建立索引?
Elasticsearch 把操作都封装成了 HTTP 的 API,我们只需给 Elasticsearch 发送 HTTP 请求
所以只要学习Elasticsearch 的HTTP API就行
怎样保证高可用?
Elasticsearch 是主从架构,会对数据进行切分,每一个分片保存多个副本,放在不同节点上。
建立索引的请求先发给master,master建立索引后将状态同步到slave
应用场景?
一个典型应用就是 ELK 日志分析系统。e用于搜索,l用于采集,k用于可视化。这个系统可以将多台服务器的日志汇总在一起,通过Elasticsearch搜索,还能接入实时计算和实时报警功能。
项目中的作用?
将帖子保存至Elasticsearch服务器
从Elasticsearch服务器搜索帖子
7
Spring Security
什么是Spring Security?
Spring Security是一款强大的身份验证和访问控制框架。提供了完善的认证机制和方法级的授权功能。
它的核心是一组过滤器链,不同的功能经由不同的过滤器。
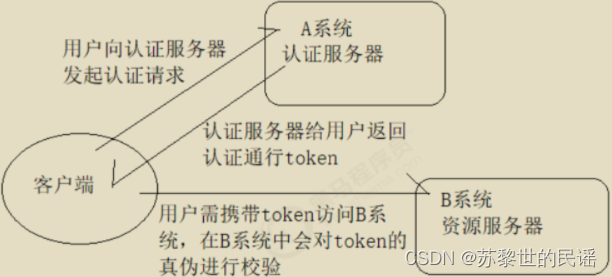
为什么京东下单和付款不需要重复登录?
这里就要引入一个概念:单点登录。
就是在一个多应用系统中,只要在其中一个系统上登录之后,不需要在其它系统上登录也可以访问其内容。举个例子,京东那么复杂的系统肯定不会是单体结构,必然是微服务架构,比如订单功能是一个系统,交易是一个系统…那么我在下订单的时候登录了,付钱难道还需要再登录一次吗,如果是这样,用户体验也太差了吧。实现的流程就是我在下单的时候系统发现我没登录就让我登录,登录完了之后系统返回给我一个Token,就类似于身份证的东西;然后我想去付钱的时候就把Token再传到交易系统中,然后交易系统验证一下Token就知道是谁了,就不需要再让我登录一次。
什么是Token?
上面提到的Token就是JWT(JSON Web Token),是一种用于通信双方之间传递安全信息的简洁的、URL安全的表述性声明规范。一个JWT实际上就是一个字符串,它由三部分组成,头部、载荷与签名。
黑客伪造Token怎么办?
JWT在加密解密的时候会用到同一个密钥,这将会带来一个弊端,如果被黑客知道了密钥的内容,那么他就可以去伪造Token了。所以为了安全,我们可以使用非对称加密算法RSA。
创建两个密钥,公钥和私钥。公钥公开,私钥私有。用公钥加密报文,只能通过私钥解密报文,这样就算报文被截获,也无法破译。
在项目中的应用?
- 三种用户类型:用户,管理员,版主。将主要界面授权给三者;置顶和加精授权给版主;删帖和访问数据页面授权给管理员。权限不够时设置提醒。
- 在拦截器中编写用户身份认证的逻辑,并存入SecurityContext,以便于Security进行授权
CSRF攻击
什么是CSRF攻击?
病毒网站窃取浏览器的cookie,获取用户凭证ticket,用其模拟用户向服务器提交表单,从而获利。
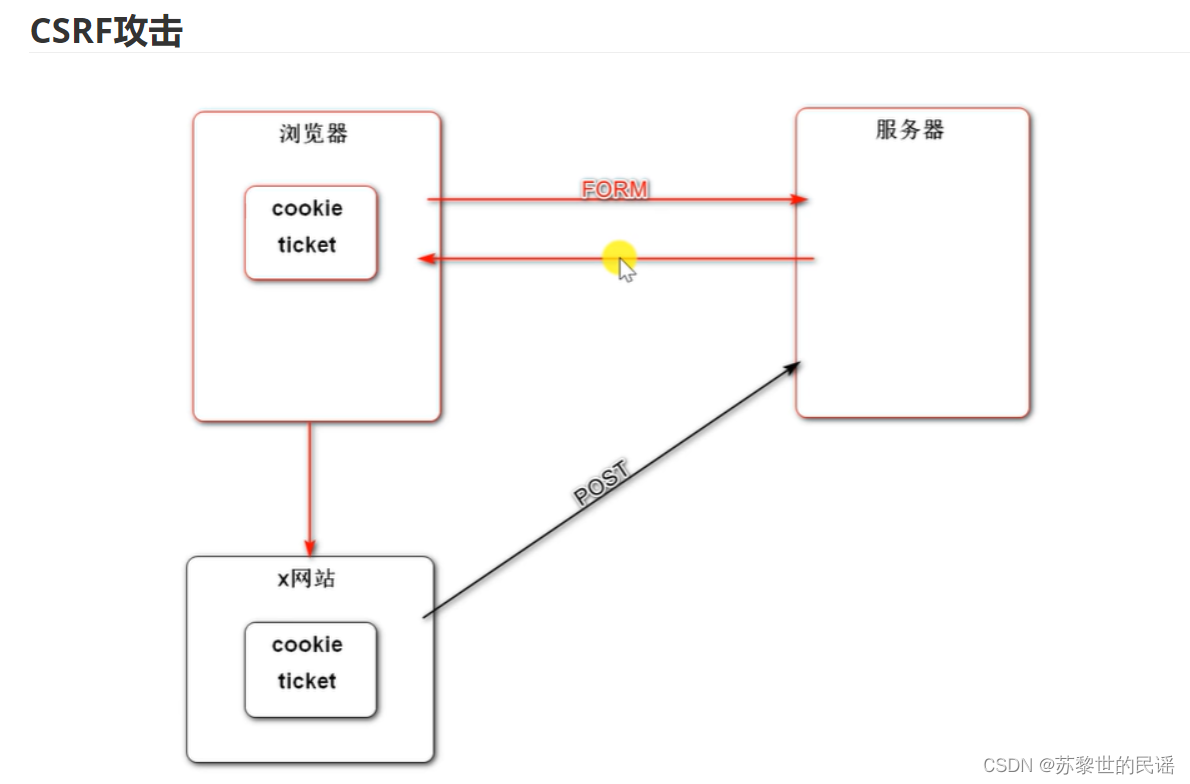
攻击的应对方法?
服务器发送tocken给浏览器,再次收到请求后检查tocken,此信息病毒网站无法获取。

Quartz
什么是Quartz?
我们系统中创建了 N 个任务,每个任务都有指定的时间进行执行,而这种多任务的执行策略就是任务调度。
Quartz是一款开源的“任务调度库”
Quartz的体系结构是什么?
一是执行的任务,二是触发器(可以理解为设置闹钟),三是调度器。连在一起就是我们使用调度器将任务和触发器绑定在一起执行,以达到在指定的时间点执行或循环执行任务。
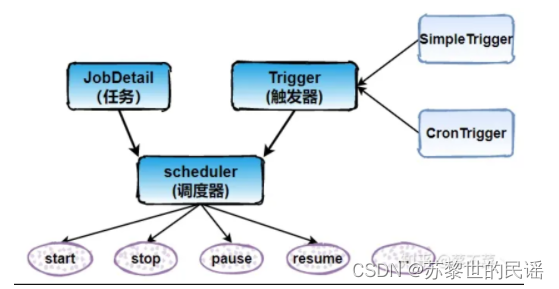
- 任务 Job
我们想要调度的任务都必须实现org.quartz.job接口,然后实现接口中定义的execute()方法即可
- 触发器 Trigger
Trigger 作为执行任务的调度器。我们如果想要凌晨1点执行备份数据的任务,那么 Trigger 就会设置凌晨1点执行该任务。
- 调度器 Scheduler
Scheduler 为任务的调度器,它会将任务 Job 及触发器 Trigger 整合起来,负责基于 Trigger 设定的时间来执行 Job
Quartz在项目中的应用?
用于更新帖子分数,用Elasticsearch进行搜索时,该分数作为一个排序字段。计算方法:加精75,评论10,点赞2
循环执行任务,每五分钟执行一次。
Caffeine
什么是Caffeine?
Caffeine是一款本地缓存组件,Redis是一款分布式缓存组件,项目中两个都用到了,二者并不冲突。Caffeine基于LRU算法实现,设置多种缓存策略。
为什么要使用Caffeine?
Redis是分布式的,需要网络开销,本地缓存不用。对于一些秒杀系统或数据量小的缓存,用Caffeine。
项目中的应用?
将帖子列表和帖子总数放入本地缓存
Nginx
什么是Nginx?
Nginx是一款轻量级的Web服务器、反向代理服务器,内存占用少,启动快,高并发。
什么是正向代理?
一般情况下,我们通过内网无法访问github,这时需要连接VPN(虚拟专用网络)再进行访问,这个过程是正向代理。
代理的对象是客户端,代理过程对服务器透明。
作用:
- 突破访问限制
- 提高访问速度
- 隐藏客户端真实IP
什么是反向代理?
客户端访问的是,拥有真正服务器部分信息的代理服务器。
代理的对象是服务器端,代理过程对客户端透明。
- 隐藏服务器真实IP
- 负载均衡
- 提高访问速度
- 提供安全保障
项目中的应用?
在java后端代码中并未体现
CDN
什么是CDN?
内容分发网络。将目标服务器的资源分发到世界各地,距离用户群体更近,提高了访问速度。
CDN与镜像有什么区别?
镜像是对完整内容的复制,CDN是智能化缓存部分内容。
8
项目总结
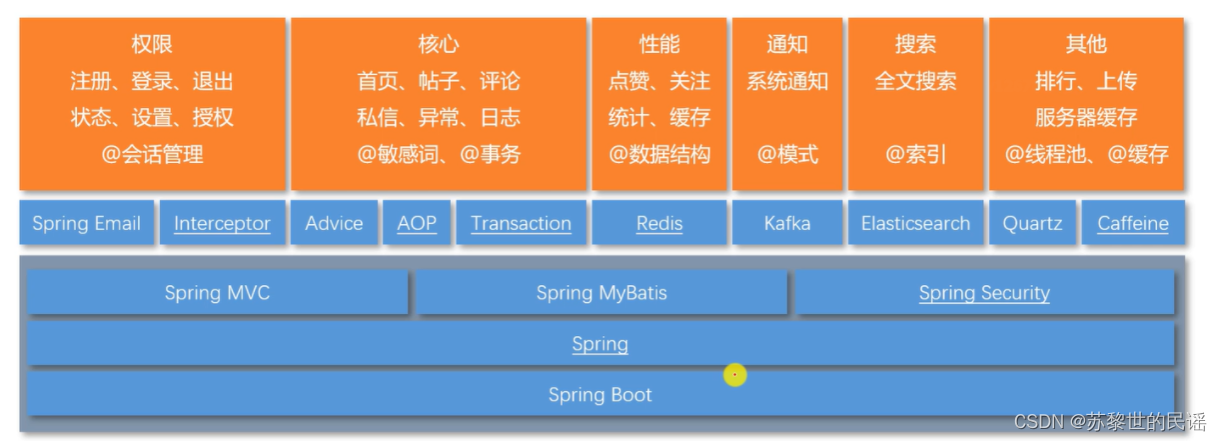
Spring Boot:降低项目核心组件开发难度
Spring:核心技术
- Spring MVC:解决前后端请求处理的问题
- Spring Security:提高安全性,身份认证和管理权限
其他组件:
- Spring Email:发邮件
- Interceptor:拦截器,拦截请求
- Advice:通知,用于统一记录日志,结合AOP来看
- AOP:面向切面,主要用于记录业务层日志
- Transaction:事务模块
- Redis:提供高性能存储的k-v数据库,五种数据结构
- MyBatis:一种持久层框架,与数据库交互
- Kafka:生产者消费者模式,处理系统通知
- Elasticsearch:一种搜索引擎,以索引方式存储数据
- Quartz:进行任务调度
- Caffeine:管理本地缓存
网站架构图
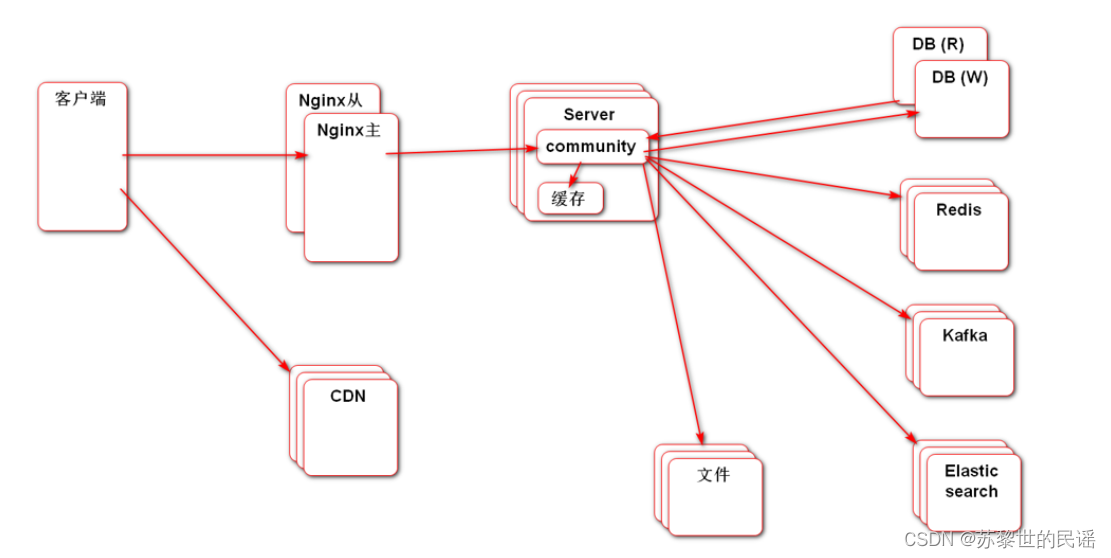
- 客户端:浏览器或APP
- Nginx:对服务器做反向代理,多个服务器时可负载均衡
- CDN:第三方缓存服务器,部署在各地,提高性能
- Server:本地服务器
- DB:数据库,读写分离
- Redis:实现二级缓存,先访问本地缓存,没有的话访问Redis,还没有访问DB
- Kafka:消息队列,控制生产者消费者速率
- Elasticsearch:搜索引擎
- 文件:文件服务器
HR关注的问题:性能、可靠性、安全性
研究透一个 比 明白两个 更好
常见面试题
MySQL
- 存储引擎
- InnoDB:支持事务
- 事务
- 事务的特性:原子性、一致性、隔离性、持久性
- 事务的隔离性
- 并发异常:第一类丢失更新、第二类丢失更新、脏读、不可重复读、幻读
- 隔离级别:Read Uncommitted、 Read Committed、 Repeatable Read、 Serializable
- Spring事务管理
- 声明式事务
- 编程式事务
- 锁
- 范围
- 表级锁:开销小、加锁快,发生锁冲突的概率高、并发度低,不会出现死锁。
- 行级锁(InnoDB):开销大、加锁慢,发生锁冲突的概率低、并发度高,会出现死锁。
- 类型
- 共享锁(S):行级,读取一行
- 排他锁(X):行级,更新一行
- 意向共享锁(IS):表级,准备加共享锁
- 意向排他锁(IX):表级,准备加排他锁
- 范围
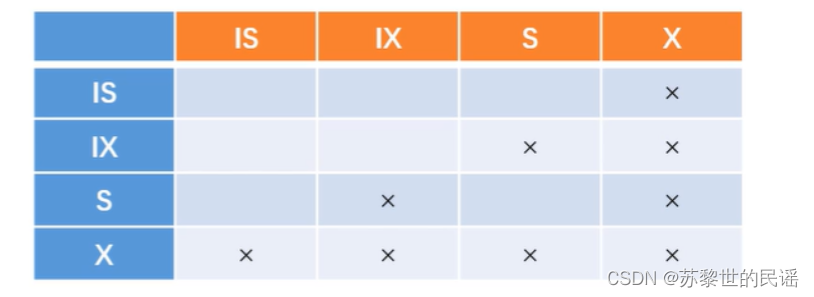
- 间隙锁(NK):行级,使用范围条件时,对此时范围内不存在的记录加锁。一是为了防止幻读,二是为了满足恢复和复制的需要。
1
- 加锁
- 数据查询语句DQL(
SELECT),操纵DML(INSECT,DELECT,UPDATE),定义DDL(CREATE),控制DCL(GRANT) - 增加行级锁之前,自动加意向锁
- 在执行DML之前,InnoDB自动加排他锁
- 执行DQL,默认不加锁
- 数据查询语句DQL(
- 死锁
- 场景描述
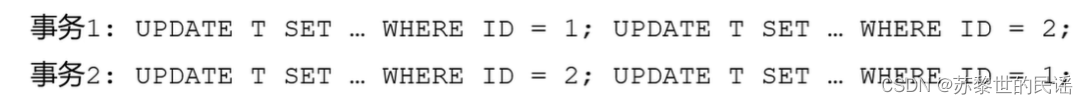
此种情况若事务1执行一半,同时事务2执行一半,二者分别对ID=1和ID=2的数据加了X锁,导致后面的命令无法执行,陷入死循环。
-
解决方案
InnoDB自动检测这种情况,将一个事务回滚,另一个事务继续执行;设置超时等待参数
-
避免死锁
首先,当不同的业务访问多个表时,约定相同的顺序访问这些表;
之后,当访问批量数据时,约定线程以相同的顺序访问数据;
如果要更新记录,应直接申请X锁,而不是S锁再转换X锁。
- 索引
- B+Tree
- 数据分块存储,每一块称为一页;
- 所有的值都是按顺序存储的,并且每一个叶子到根的距离相同;
- 非叶节点存储数据的边界,叶子节点存储指向数据行的指针;
- 通过边界缩小查找的范围,从而避免全局扫描,加快查找速度。
- B+Tree
Redis
- 数据类型

值有七种数据类型
- 过期策略
- 将过期的key放在一个独立的字典里,不会立刻删除。因为每一个key都删除效率太低。
- 惰性删除:当客户端访问key时,检查是否过期,过期则删除;
- 定期扫描:默认每秒扫描10次。
- 先从字典中随机选择20个key;
- 删除其中过期的key;
- 若删除的比例超过25%,则重新执行一轮
- 淘汰策略
- 当内存超出最大限制时,需要淘汰一些数据腾出空间
- 两种主流策略:淘汰剩余寿命(TTL)最短的;淘汰访问次数最少的(近似LRU算法)
- 近似LRU算法:每个key维护一个时间戳,淘汰时随机选择5个key,淘汰最旧的key。如果还超,就继续淘汰。
- 缓存穿透
- 查询根本不存在的数据,缓存里肯定没有,只能提交给数据库查询。这种请求一多,数据库负载过大就崩了。
- 解决方案:
- 在数据库未查询到,给客户端返回空值的同时,将空值存入缓存。下次访问直接返回空。
- 在缓存层之前设置布隆过滤器,将所有key存入,若请求无效的key,直接过滤。
- 缓存击穿
- 访问量很大的数据,在缓存失效瞬间,大量请求涌入存储层。
- 解决方案:
- 在一个线程访问时加互斥锁,其他线程等待。访问结束,缓存中已有数据,其他线程访问缓存即可。
- 设置永不过期,物理上
- 设置逻辑过期时间,当发现一个value逻辑过期,使用一个单独的线程重建缓存,逻辑上
- 缓存雪崩
- 缓存击穿的升级版。有大量的热门缓存,同时失效。或缓存服务器宕机。
- 解决方案:
- 避免同时过期,附加一个随机数
- 构建高可用的Redis缓存
- 构建多级缓存,本地缓存
- 启用限流和降级措施,对数据库限流,服务降级
- 分布式锁
- 分布式部署中,经常将数据读到内存,修改后返回给数据库。但这一操作可能被多个进程同时进行,读和写不是原子操作,需要加锁
- 基本原理:
- 同步锁:在多个线程都能访问到的地方,做一个标记,标记该数据的访问权限
- 分布式锁:在多个进程都能访问到的地方,做一个标记,标记该数据的访问权限
- 实现方式:
- 基于数据库实现分布式锁
- 基于Redis实现分布式锁
- 基于Zookeeper实现分布式锁
- Redis实现锁的原则
- 独享。在任一时刻,只有一个客户端持有锁
- 无死锁。即使持有锁的客户端崩溃或网络被分裂,锁依然可以被获取
- 容错。只要Redis大部分节点活着,客户端就可以获取和释放锁
Spring
- Spring IoC

- Spring AOP
- Spring MVC
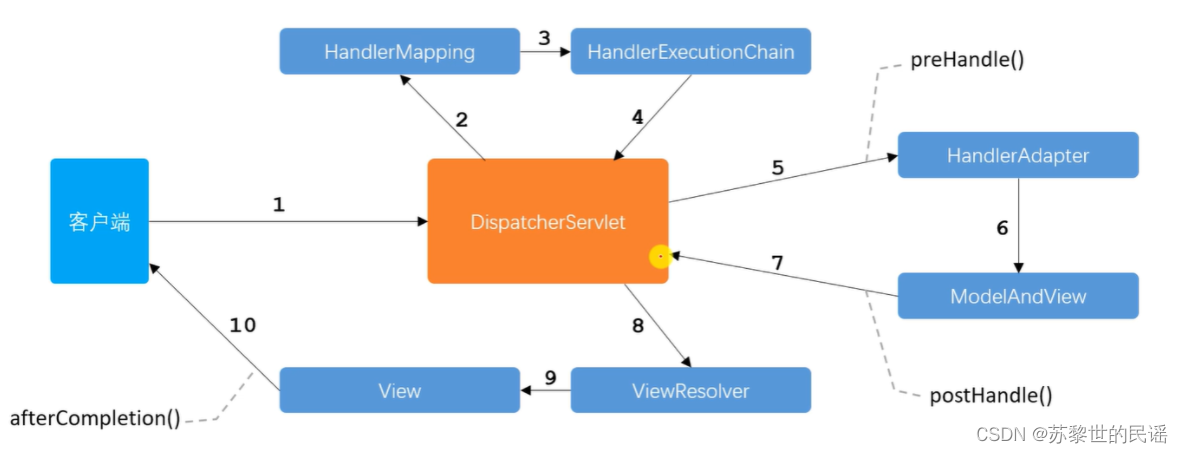
- 调度顺序:
- 客户端发送请求给调度程序(DispatcherServlet)
- DS调度HandlerMapping组件,HM将Adapter返回给DS
- HM调用HandlerAdapter组件,获取其中的Controller,将模型数据和视图返回给DS
- DS调用视图解析器(ViewResolver),将ModelAndView发给它
- VR根据此找到对应的模板引擎,由模板引擎做为客户端做渲染














 795
795











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









