







本篇文章的学习资源来自Java学习视频教程:Java核心技术(高阶)_华东师范大学_中国大学MOOC(慕课)
本篇文章的学习笔记即是对Java核心技术课程的总结,也是对自己学习的总结
文章目录
Java核心技术(高阶):深层原理
——学习Java的高级特性,理解和开发框架软件
导学
回归到Java深层次的原理特性
- Java泛型和反射
- Java代理和注解
- 内部类
- Lambda表达式和stream流处理
- Java类加载机制和安全策略
- Java模块化编程
- Java字节码
- JVM和内存管理
第一章 Java语法糖
1、语法糖(Syntax sugar)和环境设置
2、语法糖(1)foreach和枚举
foreach
优点:
- 语法更简洁
- 避免越界错误
缺点:
- foreach只能只读操作,不能修改和删除元素
- foreach遍历的时候,是不知道当前元素的具体位置索引
- foreach只能正向遍历,不能反向遍历
- foreach不能同时遍历2个集合
- for和foreach性能接近
枚举类型
枚举变量:变量的取值只在一个有限的集合内
enum类型
- enum关键字声明枚举类,且都是Enum的子类(但不需要写extends)
- enum内部有多少个值,就有多少个实例对象
- 不能直接new枚举类对象
- 除了枚举内容,还可以添加属性/构造函数/方法
- 构造函数只能是default或者private,内部调用
- 枚举方法
- 所有的enum类型都是Enum的子类,也继承了相应的方法
- ordinal()返回枚举值所在的索引位置,从0开始
- compareTo()比较两个枚举值的索引位置大小
- toString()返回枚举值的字符串表示
- valueOf()将字符串初始化为枚举对象
- values()返回所有的枚举值
eg:
enum Size {
SMALL,MEDIUM,LARGE,EXTRA_LARGE;
}
Size s1 = Size.SMALL;
Size s2 = Size.SMALL;
Size s3 = Size.MEDIUM;
System.out.println(s1 == s2); //true
System.out.println(s1 == s3); //false
**小结:**foreach和enum建议使用
3、语法糖(2)不定项参数和静态导入
不定项参数
- 普通函数的形参列表是固定个数/类型/顺序
- 不定项参数
- 类型后面加3个点,如int…/double…/String…/
- 可变参数,本质上是一个数组
- 不定项参数的限制条件
- 一个方法只能有一个不定项参数,且必须位于参数列表的最后
- 重载的优先级规则1:固定参数的方法,比可变参数优先级更高
- 重载的优先级规则1:调用语句,同时与两个带可变参数的方法 匹配,则报错
**静态导入:**import static导入一个类的静态方法和静态变量
**小结:**不定项参数:注意方法重载的优先级,建议少用;静态导入,注意“*”不滥用
4、语法糖(3)自动拆箱和装箱、多异常并列、数值类型和优化
自动装箱和拆箱
- 简化基本类型和对象转换的写法
- 装箱:基本类型的值被封装为一个包装类对象
- 拆箱:一个包装类对象被拆开并获取相应的值
- 自动装箱和拆箱的注意事项
- 装箱和拆箱是编译器的工作,在class中已经添加转换。虚拟机没有自动装箱和拆箱的语句
- ==:基本类型是内容相同,对象是指针是否相同(内存同一个区域)
- 当一个基础数据类型与封装类进行==、+、-、*、/运算时,会将封装类进行拆箱,对基础数据类型进行运算
Integer a1 = 1000;
int a2 = 1000;
Integer a3 = 2000;
Long a4 = 2000L;
long a5 = 2000L;
System.out.println(1000==1000L);//基本数据类型比较,只需内容相同 true
System.out.println(a1 == a2); //拆箱再进行数值比较 true
System.out.println(a3 == (a1 + a2)); //拆箱再进行数值比较 true
System.out.println(a4 == (a1 + a2)); //拆箱再进行数值比较 true
System.out.println(a5 == (a1 + a2)); //拆箱再进行数值比较 true
System.out.println(a3.equals(a1+a2)); //equals要求同类,且内容相同 true
System.out.println(a4.equals(a1+a2)); //equals要求同类,且内容相同 false
System.out.println(a4.equals((long) (a1+a2))); //equals要求同类,且值相同 true
//System.out.println(a3 == a4); //不同类型不能比较
多异常并列
- 多个异常并列在一个catch中
- 多个异常之间不能有(直接/间接)继承关系
try{
test();
}
catch(IOException | SQLException ex){
//JDK7开始,支持一个catch写多个异常
//异常处理
}
整数类型用二进制赋值
- 避免二进制计算
- byte/short/int/long
byte a1 = (byte) 0b00100001;
short a2 = (short) 0b1010000101000101;
int a3 = 0b10100001010001011010000101000101;
int a4 = 0b101;
int a5 = 0B101; //B可以大小写
long a6 = 0b1010000101000101101000010100010110100001010001011010000101000101L;
final int[] s1 = { 0b00110001, 0b01100010, 0b11000100, 0b10000100 };
小结:多异常并列不建议使用,针对每一种类型异常单独处理
5、语法糖(4)接口方法
- Java最初的设计中,接口的方法都是没有实现的、公开的
- Java8推出接口的默认方法/静态方法(都带实现的),为Lambda表达式提供支持
接口的默认方法
- 以default关键字标注,其他的定义和普通函数一样
- 默认方法不能重写Object中的方法
- 实现类可以继承/重写父接口的默认方法
- 接口可以继承/重写父接口的默认方法
- 当父类和父接口都有(同名同参数)默认方法,子类继承父类的默认方法
- 子类实现了2个接口(均有同名同参数的默认方法),那么编译失败,必须在子类中重写这个default方法
public default void move()
{
System.out.println("I can move.");
}
接口的静态方法
- 该静态方法属于本接口的,不属于子类/子接口
- 接口的默认方法:可以传给后代的类/接口的;接口的静态方法:只属于当前接口,不会传给后代的类/接口
- 子类(子接口)没有继承该静态方法,只能通过所在的接口名来调用
Java9接口的私有方法(带实现的)
- 解决多个默认方法/静态方法的内容重复问题
- 私有方法属于本接口,只在本接口内使用,不属于子类/子接口
- 子类(子接口)没有继承该私有方法,也无法调用
- 静态私有方法可以被静态/默认方法调用,非静态私有方法被默认方法调用
小结:接口的方法,建议少用。如有Lambda表达式需求,可使用
6、语法糖(5)try-with-resource和ResourceBundle文件加载
ResourceBundle
- Java8及以前,ResourceBundle默认以ISO-8859-1方式加载Properties文件,需要利用native2ascii工具对文件进行转义
- jdk9及以后,ResourcecBundle默认以UTF-8方式加载Properties文件。
- jdk9及以后,已经删除native2ascii工具
- 新的Properties文件直接以UTF-8保存
- 已利用native2ascii工具转化后的文件,不受影响。即ResourceBundle若解析文件不是有效的UTF-8,则以ISO-8859-1方式加载
7、语法糖(6)var类型和switch
var
- Java10推出var:局部变量推断
- 避免信息冗余
- 对齐了变量名
- 更容易阅读
- 本质上还是强类型语言,编译器负责推断类型,并写入字节码文件。因此推断后不能更改。
- var的限制
- 可以用在局部变量上,非类成员变量
- 可以用在for/foreach循环中
- 声明时必须初始化
- 不能用在方法(形式)参数和返回类型
- 大面积滥用会使代码整体阅读性变差
- var只在编译时起作用,没有在字节码中引入新的内容,也没有专门的JVM指令处理var
建议:var变量只在局部变量中使用
switch
- 支持的类型:byte/Byte,short/Short,int/Integer,char/Character,String,Enum
- 不支持:long/float/double/boolean
第二章 Java泛型
1、泛型入门
泛型:Generic Programming,编写的代码可以被很多不同类型的对象所重用
- 泛型类:ArrayList,HashSet,HashMap等
- 泛型方法:Collections.binarySearch,Arrays.sort等
- 泛型接口:List,Iterator等
泛型的本质:参数化类型,避免类型转换,代码可复用
- 同类:
- C++的模板(Template)
- C#的泛型
2、自定义泛型设计
自定义泛型设计
- 泛型类:整个类都被泛化,包括变量和方法
- 泛型方法:方法被泛化,包括返回值和参数
- 泛型接口:泛化子类方法
泛型类
-
具有泛型变量的类
-
在类名后用<T>代表引入类型
- 多个字母表示多个引入类型,如<T,U>等
- 引入类型可以修饰成员变量/局部变量/参数/返回值
- 泛型类不需要关键字
public class GenericTest<T> { private T lower; private T upper; public GenericTest(T lower, T upper) { this.lower = lower; this.upper = upper; } public T getLower() { return lower; } }泛型类调用
GenericTest<Integer> v1=new GenericTest<>(1,2);
泛型方法
- 具有泛型参数的方法
- 该方法可在普通类/泛型类中
- <T>在修饰符后,返回类型前
public static <T> T getMiddle(T... a) {
return a[a.length / 2];
}
泛型方法调用
String s1=getMiddle("abc","def","ghi");
泛型接口
- 和泛型类相似,在类名后加<T>
- T用来指定方法返回值和参数
- 实现接口时,指定类型
- 泛型接口,T也可以再是一个泛型类(不推荐)
3、泛型类型限定
泛型
- 编写的代码可以被很多不同类型的对象所重用
- 特定场合下,需要对类型进行限定(使用某些特定方法)
泛型限定
- <T extends Comparable>约定T必须是Comparable的子类
- 注意:extend固定,后面可以多个,以&拼接,如<T extends Comparable & Serializable>
- extends限定可以有多个接口,但只能有一个类,且类必须排第一位
泛型通配符
问题引出:Pair<Apple>和Pair<Fruit>之间是不存在任何关系的,也不能通用,为了弥补这个不足,引入泛型通配符
- 上限界定符,Pair<? extends S>
- Pair能接收的参数类型,是S自身或子类
- 只能get,不能set,编译器只能保证出来的类型,但不保证放入的对象是什么类型
- 下限界定符,Pair<? super S>
- Pair能接收的类型参数,是S的自身或超类
- 只能set,不能get。编译器保证放入的是S本身或超类,但不保证出来是什么具体类型
4、泛型实现的本质和约束
JVM里面没有泛型对象,而是采用类型擦除技术,只有普通的类和方法。
类型擦除
- 擦除泛型变量,替换为原始类型,无限定为Object,有限定则为第一个类型
- 擦除泛型变量后,为了保证类型的安全性,需要自动进行类型转换。(这是编译器的工作)
- 重载泛型方法翻译(自动桥方法)
5、Java类型协变和逆变
类型变化关系
- A,B是类型,f(.)表示类型转换,–>表示继承关系,如A–>B,表示A继承于B
- f(.)是协变的,如果A–>B,有f(A)–>f(B)
- f(.)是逆变的,如果A–>B,有f(B)–>f(A)
- f(.)是不变的,当上述两种都不成立,即f(A)和f(B)没有任何关系
- f(.)是双变的,如果A–>B,有f(A)–>f(B)和f(B)–>f(A)
eg:
-
Java数组是协变的
class A{} //第一代 class B extends A{} //第二代 class C extends B{} //第三代 B[] array1 = new B[1]; array1[0] = new B(); A[] array2 = array1; try { array2[0] = new A(); // compile ok, runtime error array2[0] = new C(); // compile ok, runtime ok } catch (Exception ex) { ex.printStackTrace(); } -
Java**(原始的)泛型是不变的**
- String是Object的子类,list<String>和List<Object>没有关系
-
泛型可采用通配符,支持协变和逆变
- <? extends A>支持协变
- <? super B>支持逆变
-
ArrayList<? extends A> list3 = new ArrayList<B>(); //协变 ArrayList<? super B> list4 = new ArrayList<A>(); //逆变
方法情况:返回值是协变的
第三章 Java反射
1、反射入门
反射(Reflection):
- 程序可以访问、检测和修改它本身状态或行为的能力,即自描述和自控制
- 可以在运行时加载、探知和使用编译期间完全未知的类
- 给Java插上动态语言特性的翅膀,弥补强类型语言的不足
反射作用:
- 在运行中分析类的能力
- 在运行中查看和操作对象
- 基于反射自由创建对象
- 反射构建出无法直接访问的类
- set或者get到无法访问到的成员变量
- 调用不可访问的方法
- 实现通用的数组操作代码
- 类似函数指针的功能
创建对象的方法:
- 静态编码&编译
- 克隆(clone)
- 序列化(serialization)和反序列化(deserialization)
- 反射1
- 反射2
克隆实例:
public class B implements Cloneable {
public void hello()
{
System.out.println("hello from B");
}
protected Object clone() throws CloneNotSupportedException
{
return super.clone();
}
}
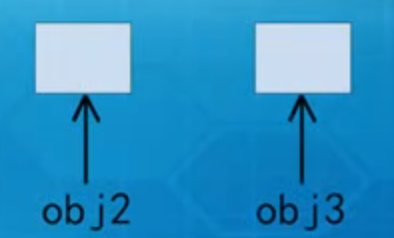
//obj3 是obj2的克隆对象 没有调用构造函数
B obj2 = new B();
obj2.hello();
B obj3 = (B) obj2.clone();
obj3.hello();
序列化和反序列化实例:
public class C implements Serializable {
private static final long serialVersionUID = 1L;
public void hello() {
System.out.println("hello from C");
}
}
//第三种 序列化 没有调用构造函数
//序列化会引发安全漏洞,未来将被移除出JDK,请谨慎使用!!!
C obj4 = new C();
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("data.obj"));
out.writeObject(obj4);
out.close();
ObjectInputStream in = new ObjectInputStream(new FileInputStream("data.obj"));
C obj5 = (C) in.readObject();
in.close();
obj5.hello();
序列化和反序列化注意事项:
- 可以通过序列化来存储对象的状态
- 使用ObjectOutputStream来序列化对象。用FileOutputStream链接ObjectOutputStream来将对象序列化到文件上
- 对象必须实现序列化接口才能被序列化。如果父类实现序列化,则子类自动地实现,而不管是否有明确的声明
- 当对象被序列化时,整个对象版图都会被序列化。这代表它的实例变量所引用的对象也会被实例化。
- 如果有不能被实例化的对象,执行期间就会抛出异常
- 除非该实例变量被标记为transient,否则,该变量在还原的时候会被赋予null或基本数据类型的默认值
- 在解序列化时,所有的类都必须能让JVM找到
- 读取对象的顺序必须与写入的顺序相同
- readObject()的返回类型是Object,因此解序列化回来的对象还需要转换成原来的类型
- 静态变量不会被序列化,因为所有对象都是共享同一份静态变量
反射实例
//第四种 newInstance 调用构造函数
Object obj6 = Class.forName("A").newInstance();
Method m = Class.forName("A").getMethod("hello");
m.invoke(obj6);
A obj7 = (A) Class.forName("A").newInstance();
//第五种 newInstance 调用构造函数
Constructor<A> constructor = A.class.getConstructor();
A obj8 = constructor.newInstance();
obj8.hello();
2、反射关键类
反射:在运行中分析类的能力
Class:类型标识
三种获取方式:
String s1 = "abc";
Class c1 = s1.getClass();
System.out.println(c1.getName());
Class c2 = Class.forName("java.lang.String");
System.out.println(c2.getName());
Class c3 = String.class;
System.out.println(c3.getName());
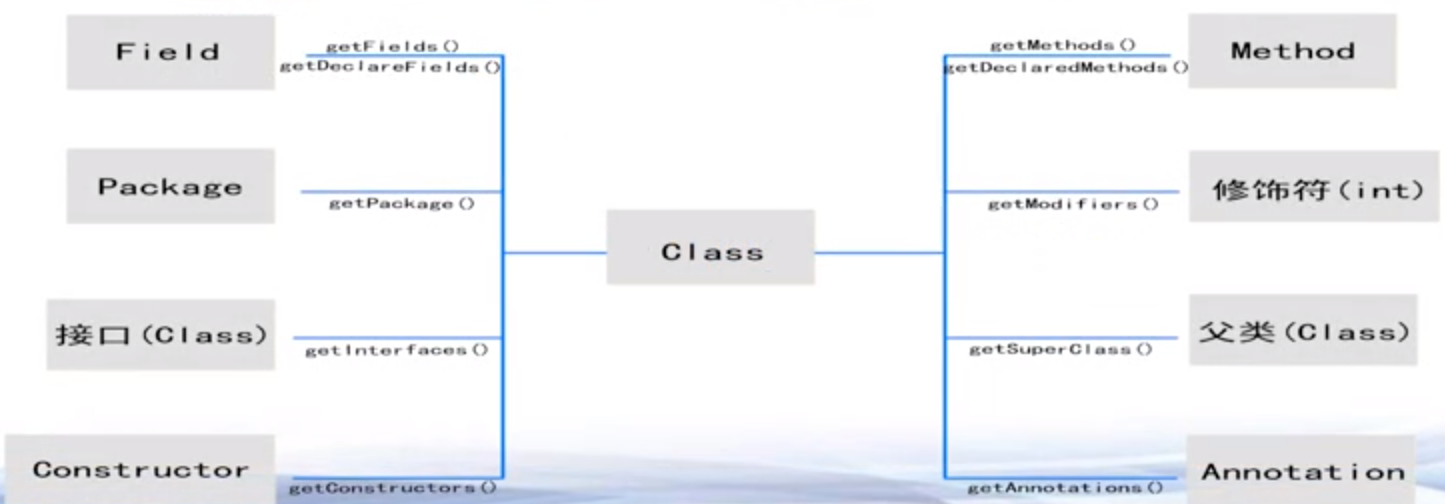
- 成员变量、方法、构造函数、修饰符、包、父类、父接口……
注:
- getFields():返回本类和所有父类所有的public成员变量;getDeclaredFields():返回本类自己定义的成员变量,包括private的变量,但不包括父类的变量
- getMethods():返回本类和所有父类所有的public方法;getDeclaredMethods():返回本类自己定义的方法,包括private的方法,但不包括父类的方法
通过反射调用方法
method.setAccessible(true); //临时将private方法转为public,以方便使用方法
method.invoke(obj,null); //invoke调用某个方法,参数:对象,实参。静态方法可以不用new对象
通过反射获取构造函数,进而创建类
3、反射应用
反射应用
-
数据库连接
-
class.forName("com.mysql.cj.jdbc.Driver");
-
-
数组扩容
- java的数组一旦创建,其长度不再更改
- 新建一个大数组(相同类型),然后将旧数组的内容拷贝过去
public static void main(String[] args) { int[] a = { 1, 2, 3, 4, 5 }; a = (int[]) goodCopy(a, 10); } public static Object goodCopy(Object oldArray, int newLength) { // Array类型 Class c = oldArray.getClass(); // 获取数组中的单个元素类型 Class componentType = c.getComponentType(); // 旧数组长度 int oldLength = Array.getLength(oldArray); // 新数组 Object newArray = Array.newInstance(componentType, newLength); // 拷贝旧数据 System.arraycopy(oldArray, 0, newArray, 0, oldLength); return newArray; } -
动态执行方法
-
JSON和Java对象互转
-
Tomcat的Servlet对象创建
-
MyBatis的OR/M
-
Spring的Bean容器
-
org.reflections包介绍
- Reflection的增强工具包
- Java runtime metadata analysis
4、编译器API
反射:
- 可以查看对象的类型标识
- 可以动态创建对象,访问器属性,调用其方法
- 前提:类(class文件)必须先存在
编译器API
- 对.java文件即时编译
- 对字符串即时编译
- 监听在编译过程中产生的警告和错误
- 在代码中运行编译器(并非:runntime命令行调用javac命令)
JavaComplier
- 自Java1.6推出,位于javax.tools包中
- 可用在程序文件中的java编译器接口(代替javac.exe)
- 在程序中编译java文件,产生class文件
- run方法:较简单。可以编译java源文件,生成class文件,但不能指定输出路径,只能在源码所在目录下生成class文件。可以监控错误信息
- getTask方法:更强大的功能。可以编译java源文件,包括在内存中的java文件(字符串),生成class文件。
run方法:
public static void successCompile() {
JavaCompiler compiler = ToolProvider.getSystemJavaCompiler();
// 第一个参数:输入流,null表示默认使用system.in
// 第二个参数:输出流,null表示默认使用system.out
// 第三个参数:错误流,null表示默认使用system.err
// 第四个参数:String... 需要编译的文件名
// 返回值:0表示成功,其他错误
int result = compiler.run(null, null, null, "F:/temp/Hello1.java", "F:/temp/Hello2.java");
System.out.println(0 == result ? "Success" : "Fail");
}
public static void failCompile() throws UnsupportedEncodingException {
ByteArrayOutputStream err = new ByteArrayOutputStream();
JavaCompiler compiler = ToolProvider.getSystemJavaCompiler();
int result = compiler.run(null, null, err, "F:/temp/Hello3.java");
if (0 == result) {
System.out.println("Success");
} else {
System.out.println("Fail");
System.out.println(new String(err.toByteArray(), Charset.defaultCharset().toString()));
}
}
getTask方法
Java编译器API作用:
- JSP编译
- 在线编程环境
- 在线程序评判系统(Online Judge系统)
- 自动化的构建和测试工具
第四章 Java代理
1、代理模式和静态代理
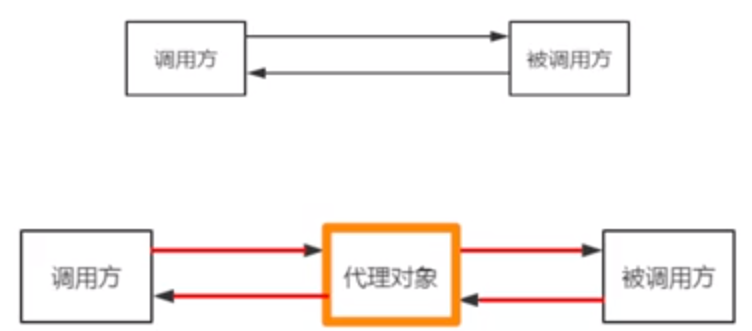
代理(Proxy):代替处理
代理模式(委托模式):为目标对象提供(包装)了一个代理,这个代理可以控制对目标对象的访问
- 外界不用直接访问目标对象,而是访问代理对象,由代理对象再调用目标对象
- 代理对象中可以添加监控和审查处理
Java代理:静态代理和动态代理
静态代理
- 代理对象持有目标对象的句柄
- 所有调用目标对象的方法,都调用代理对象的方法
- 对每个方法,需要静态编码(理解简单,但代码繁杂)
eg:
Subject //Interface,对象接口
public interface Subject{
public void request();
}
SubjectImpl //目标对象
class SubjectImpl implements Subject{
public void request(){
System.out.println("I am dealing the request.");
}
}
StatucProxy //静态代理对象,一般来说,静态代理对象和目标对象实现同一接口
class StaticProxy implements Subject{
//实际目标对象
private Subject subject;
public StaticProxy(Subject subject){
this.subject = subject;
}
public void request(){
System.out.println("PreProcess");
subject.request();
System.out.println("PostProcess");
}
}
StaticProxyDemo //静态代理模式
public class StaticProxyDemo {
public static void main(String args[]){
//创建实际对象
SubjectImpl subject = new SubjectImpl();
//把实际对象封装到代理对象中
StaticProxy p = new StaticProxy(subject);
p.request();
}
}
静态代理模式
- 隐藏实际的目标对象
- 对方法的实现前后可以进行前置处理和后置处理
2、动态代理
动态代理
- 对目标对象的方法每次被调用,进行动态拦截
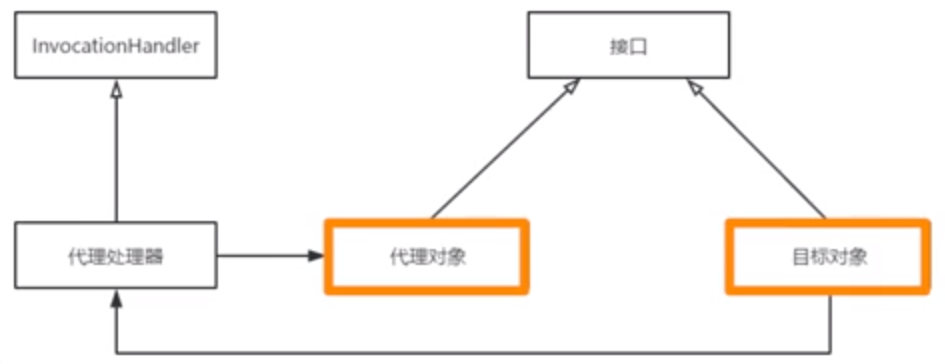
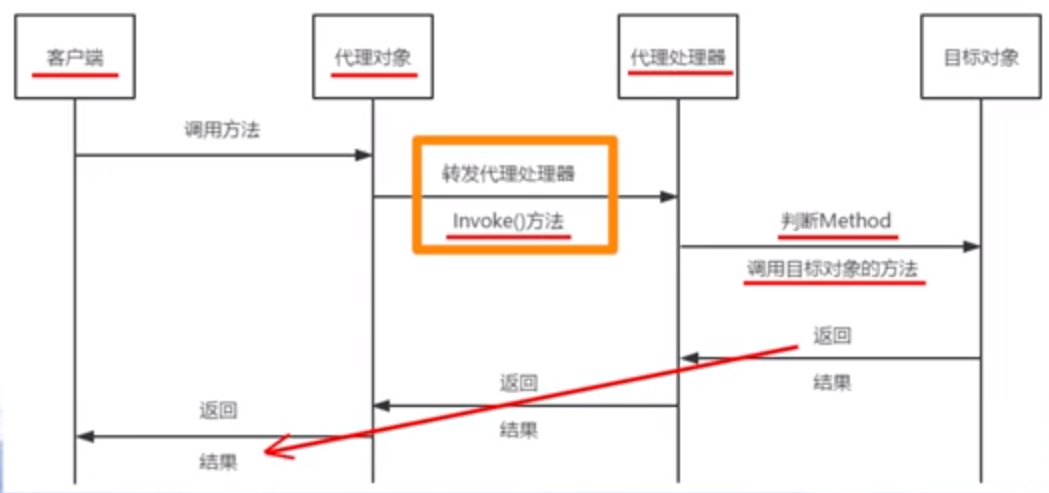
代理处理器
- 持有目标对象的句柄
- 实现InvocationHandler接口
- 实现invoke方法
- 所有的代理对象方法调用,都会转发到invoke方法来
- invoke的形参method,及时指代理对象方法的调用
- 在invoke内部,可以根据method,使用目标对象不同的方法来相应请求
eg:
ProxyHandler //代理处理器
class ProxyHandler implements InvocationHandler{
private Subject subject;
public ProxyHandler(Subject subject){
this.subject = subject;
}
//此函数在代理对象调用任何一个方法时都会被调用。
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println(proxy.getClass().getName());
//定义预处理的工作,当然你也可以根据 method 的不同进行不同的预处理工作
System.out.println("====before====");
Object result = method.invoke(subject, args);
System.out.println("====after====");
return result;
}
}
DynamicProxyDemo //动态代理模式
public class DynamicProxyDemo {
public static void main(String[] args) {
//1.创建目标对象
SubjectImpl realSubject = new SubjectImpl();
//2.创建调用处理器对象
ProxyHandler handler = new ProxyHandler(realSubject);
//3.动态生成代理对象
Subject proxySubject =
(Subject)Proxy.newProxyInstance
(SubjectImpl.class.getClassLoader(),
SubjectImpl.class.getInterfaces(), handler);
//proxySubject真实类型com.sun.proxy.$Proxy0
//proxySubject继承Proxy类,实现Subject接口
//newProxyInstance的第二个参数,就是指定代理对象的接口
//4.客户端通过代理对象调用方法
//本次调用将自动被代理处理器的invoke方法接收
proxySubject.request();
System.out.println(proxySubject.getClass().getName());
System.out.println(proxySubject.getClass().getSuperclass().getName());
}
}
代理对象
- 根据给定的接口,由Proxy类自动生成的对象
- 类型com.sun.proxy.$Proxy0,继承自java.lang.reflect.Proxy
- 通常和目标对象实现同样的接口(可另实现其它的接口)
- 实现多个接口
- 接口的排序非常重要
- 当多个接口里面有方法同名,则默认以第一个接口的方法调用
eg:
ProxyHandler //代理处理器
class ProxyHandler implements InvocationHandler{
private Subject subject;
public ProxyHandler(Subject subject){
this.subject = subject;
}
//此函数在代理对象调用任何一个方法时都会被调用。
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println(proxy.getClass().getName());
//定义预处理的工作,当然你也可以根据 method 的不同进行不同的预处理工作
System.out.println("====before====");
Object result = method.invoke(subject, args);
System.out.println("====after====");
return result;
}
}
MultipleInterfacesProxyTest //多接口代理模式,以第一个接口为主
public class MultipleInterfacesProxyTest {
public static void main(String[] args) throws Exception {
Cook cook = new CookImpl();
ClassLoader cl = MultipleInterfacesProxyTest.class.getClassLoader();
ProxyHandler handler = new ProxyHandler(cook);
//生成代理类型
Class<?> proxyClass = Proxy.getProxyClass(cl, new Class<?>[]{Cook.class,Driver.class});//这一步,如果交换接口顺序,编译就会报错
//生成代理对象
Object proxy = proxyClass.getConstructor(new Class[]{InvocationHandler.class}).
newInstance(new Object[]{handler});
System.out.println(Proxy.isProxyClass(proxyClass));
Proxy p = (Proxy) proxy;
System.out.println(p.getInvocationHandler(proxy).getClass().getName());
System.out.println("proxy类型:" + proxyClass.getName());
//代理对象都继承于java.lang.reflect.Proxy,但是获取父类确是Object而不是Proxy
Class father = proxyClass.getSuperclass();
System.out.println("proxy的父类类型:" + father.getName());
Class[] cs = proxy.getClass().getInterfaces();
for(Class c:cs)
{
System.out.println("proxy的父接口类型:" + c.getName());
}
System.out.println("=====================");
Method[] ms = proxy.getClass().getMethods();
for(Method m:ms)
{
System.out.println("调用方法 " + m.getName() + ";参数为 " + Arrays.deepToString(m.getParameters()));
}
System.out.println("=====================");
Cook c = (Cook) proxy;
c.doWork();
Driver d = (Driver) proxy;
d.doWork();
}
}
3、AOP编程
AOP:Aspect Oriented Programming
面向切面编程(VS 面向对象编程)
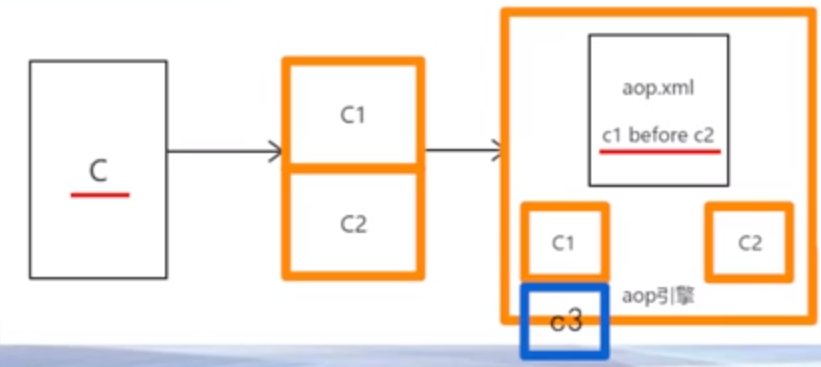
- 面向切面:将通用需求功能从众多类中分离出来,使得很多类共享一个行为,一旦发生变化,不必修改很多类,而只需修改这个行为即可
- 不是取代OOP编程,而是OOP的补充
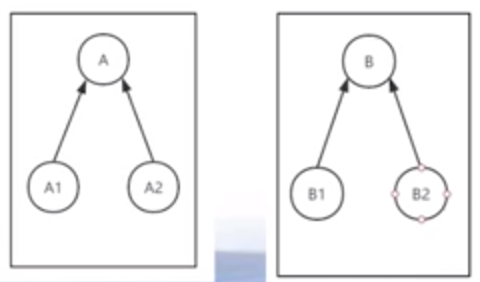
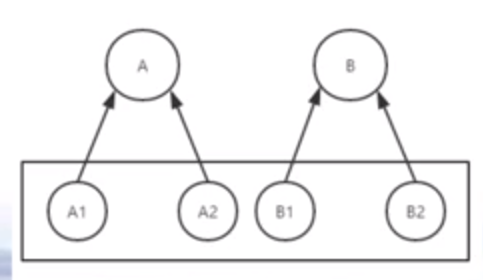
面向切面编程优点:
- 分离代码的耦合(高内聚,低耦合)
- 业务逻辑变化不需要修改源代码/不用重启
- 加快编程和测试速度
第五章 Java注解
1、注解入门
注解(Annotation):
- 位于源码中(代码/注释/注解),使用其他工具进行处理的标签
- 注解用来修饰程序的元素,但不会对被修饰的对象有直接的影响
- 只有通过某种配套的工具才会对注解信息进行访问和处理
- 主要用途
- 提供信息给编译器/IDE工具
- 可用于其他工具来产生额外的代码/配置文件等
- 有一些注解可在程序运行时访问,增加程序的动态性
2、Java预定义的普通注解
(部分注解)
| 注解 | 含义 | 用途 |
|---|---|---|
| @Override | 继承和覆写 | 修饰方法,检查该方法是父类的方法;强制该函数代码必须符合父类中该方法的定义;避免代码错误 |
| @Deprecated | 废弃 | |
| @SuppressWarnings | 压制警告 | 压制各种不同类型的警告信息,使得编译器不显示警告;警告类型名称是编译器/IDE工具自己定义的,Java规范没有强制要求 |
| @SafeVarargs | 不会对不定项参数做危险操作 | |
| @FunctionInterface | 声明功能性接口 |
@SuppressWarnings
- SuppressWarnings(“unchecked”) 忽略unchecked警告信息
- SuppressWarnings(“deprecated”) 忽略deprecated警告信息
- SuppressWarnings({“unchecked”,“deprecated”}) 忽略两种警告信息
- SuppressWarnings(value={“unchecked”,“deprecated”}) 同上
- SuppressWarnings(“all”) 忽略所有警告信息
- 其他警告类型
- cast,忽略类转型警告
- serial,忽略实现Serializable接口的,没有定义serialVersionUID
3、自定义注解
eg:
//带着一个成员属性的一个注解
public @interface SingleTest{
int value() default 0;
//String para();
}
注解可以包括的类型:
- 8种基本数据类型
- String
- Class
- enum类型
- 注解类型
- 由前面类型组成的数组
eg:
public @interface BugReport {
enum Status {UNCONFIRMED, CONFIRMED, FIXED, NOTABUG};
boolean showStopper() default true;
String assiganedTo() default "[none]";
Status status() default Status.UNCONFIRMED;
String[] reportedBy();
}
注解使用:使用时可以给注解成员赋值
注解使用的位置:
- @Target可以限定位置
4、Java预定义的元注解
元注解:用来修饰注解的注解
| 元注解 | 注解说明 | |
|---|---|---|
| @Target | 设置目标范围 | |
| @Retention | 设置保持性 | |
| @Inherited | 注解继承 | |
| @Repeatable | 此注解可以重复修饰 | |
| @Document | 文档 |
Retention(保留)
- 实例:@Retention(RetentionPolicy.RUNTIME)
- 这个注解用来修饰注解的存在范围
- RetentionPolicy.SOURCE注解仅存在源码,不在class文件。eg:override
- RetentionPolicy.CLASS这是默认的注解保留策略。注解存在于.class文件,但是不能被JVM加载。
- RetentionPolicy.RUNTIME这种策略下,注解可以被JVM运行时访问到。通常情况下,可以结合反射来做一些事情。
Target
- 限定目标注解作用位置
- ElementType.ANNOTATION_TYPE(注:修饰注解)
- CONSTRUCTOR/FIELD/LOCAL_VARIABLE/METHOD/PACKAGE/PARAMETER/TYPE
Inherited
- 让一个类和它的子类都包含某个注解
- 普通的注解没有继承功能
Repeatable
- 表示被修饰的注解可以重复应用标注
- 需要定义注解和容器注解
RepeatableAnnotation //重复元注解
@Retention(RetentionPolicy.RUNTIME)
@Repeatable(RepeatableAnnotations.class)
public @interface RepeatableAnnotation {
int a() default 0;
int b() default 0;
int c() default 0;
}
RepeatableAnnotations //重复元注解容器
@Retention(RetentionPolicy.RUNTIME)
public @interface RepeatableAnnotations {
RepeatableAnnotation[] value();
}
Student //方法类
public class Student {
@RepeatableAnnotation(a=1,b=2,c=3)
@RepeatableAnnotation(a=1,b=2,c=4)
public static void add(int a, int b, int c)
{
if(c != a+b)
{
throw new ArithmeticException("Wrong");
}
}
}
Main
public static void main(String[] a) throws Exception
{
String className = "repeatable.Student";
for (Method m : Class.forName(className).getMethods())
{
if (m.isAnnotationPresent(RepeatableAnnotations.class))
{
RepeatableAnnotation[] annos = m.getAnnotationsByType(RepeatableAnnotation.class);
for (RepeatableAnnotation anno : annos)
{
System.out.println(anno.a() + "," + anno.b() + "," + anno.c());
try
{
m.invoke(null,anno.a(),anno.b(),anno.c());
} catch (Throwable ex) {
System.out.printf("Test %s failed: %s %n", m, ex.getCause());
}
}
}
}
}
Documented
- 指明这个注解可以被Javadoc工具解析,形成帮助文档
5、注解的解析
RetentionPolicy.RUNTIME:注解在class文件中,被JVM加载,可用反射解析注解
- Class.getAnnotations() 获取注解数组
- Class.isAnnotation() 是否有注解
- Class.isAnnotationPresent(Class annotationClass) 是否是某个注解
- Method/Field/Constructor.getAnnotations()/isAnnotationPresent(Class annotationClass)
RetentionPolicy.CLASS:注解在class文件中,但没有被JVM加载
- 只能使用字节码工具进行特殊处理
RetentionPolicy.SOURCEC:注解在java文件中,不在class文件中,也不会被JVM加载
- 只有在源码级别进行注解处理
- Java提供注解处理器来解析带注解的源码,产生新的文件
6、RUNTIME注解的实现本质
注解:Annotation
- 位于源码中(代码+注释+注解),使用其他工具进行处理的标签
- 根据RetentionPolicy的不同,分成三种类型的注解:
- SOURCE:注解在源码,不在class文件
- CLASS:注解在源码和class文件,但JVM不加载
- RUNTIME:注解在源码和class文件中,JVM加载
7、注解的应用
第六章 嵌套类
1、嵌套类入门
嵌套类(Nested classes):简单地说,就是在一个类的内部创建另一个类。
- 静态嵌套类:类前面有static修饰符
- 非静态嵌套类:又名内部类,Inner classes
- 普通内部类(成员内部类) (放在类的内部)
- 局部内部类(Local classes) (放在方法的内部)
- 匿名内部类(Anonymous classes)
为什么需要嵌套类:
- 不同的访问权限要求,更细粒度的访问控制
- 简洁,避免过多的类定义
- 更好的封装
嵌套类学习重点:
- 嵌套类的语法
- 嵌套类和其他类的关系
- 嵌套类访问外部包围类
- 外部包围类访问嵌套类
- 第三方类访问嵌套类
2、匿名内部类和局部内部类
匿名内部类:Anonymous classes
- 没有类名的内部类,必须继承一个父类/实现一个父接口
- 在实例化以后,迅速转型为父类/父接口
- 这种类型的对象,只能new一个对象,之后以对象名字操作
- 注意事项:
- 匿名内部类中不能定义静态变量和静态方法,除非是常量
- 没有类名,没有构造函数,能用父类/父接口的构造函数
- 没有类名,外部包围类和其他类也无法访问到匿名内部类
局部内部类:Local classes (放在方法的内部)
- 只能活在这个代码块中,代码块结束后,外界无法使用该类
- 外部包围类.this.变量名,可以访问到外部包围类的成员变量
- 注意事项:
- 同匿名内部类,不能定义静态变量和静态方法,除非是常量
匿名内部类和局部内部类总结:
- 两者几乎相似
- 局部内部类可以重用,匿名内部类不可以重用
- 匿名内部类更简洁
3、普通内部类和静态嵌套类
普通内部类
-
注意事项
-
同匿名内部类,不能定义静态变量和静态方法,除非是常量
-
可以用private/default(不写)/protected/public控制外界访问
-
和外部包围类的实例相关,一个普通内部类实例肯定是在一个外部包围类的实例中
-
在第三方类中,需要先创建外部包围类实例,才能创建普通内部类的实例,不允许单独的普通内部类对象存在
创建方式:
外部包围类.new.普通内部类();
-
静态嵌套类
-
与其他三类不同:静态嵌套类可以定义静态成员
-
只能访问到外部嵌套类的静态成员
- 可通过包围类的对象进行访问非静态成员
-
第三方需要通过外部包围类才可以访问到静态嵌套类,并创建其对象。但是不需要外部包围类的实例
创建方式:
new 外部包围类.静态嵌套类(); -
静态嵌套类和一个顶层类并没有什么区别,纯粹是为了packaging的方便
4、嵌套类对比
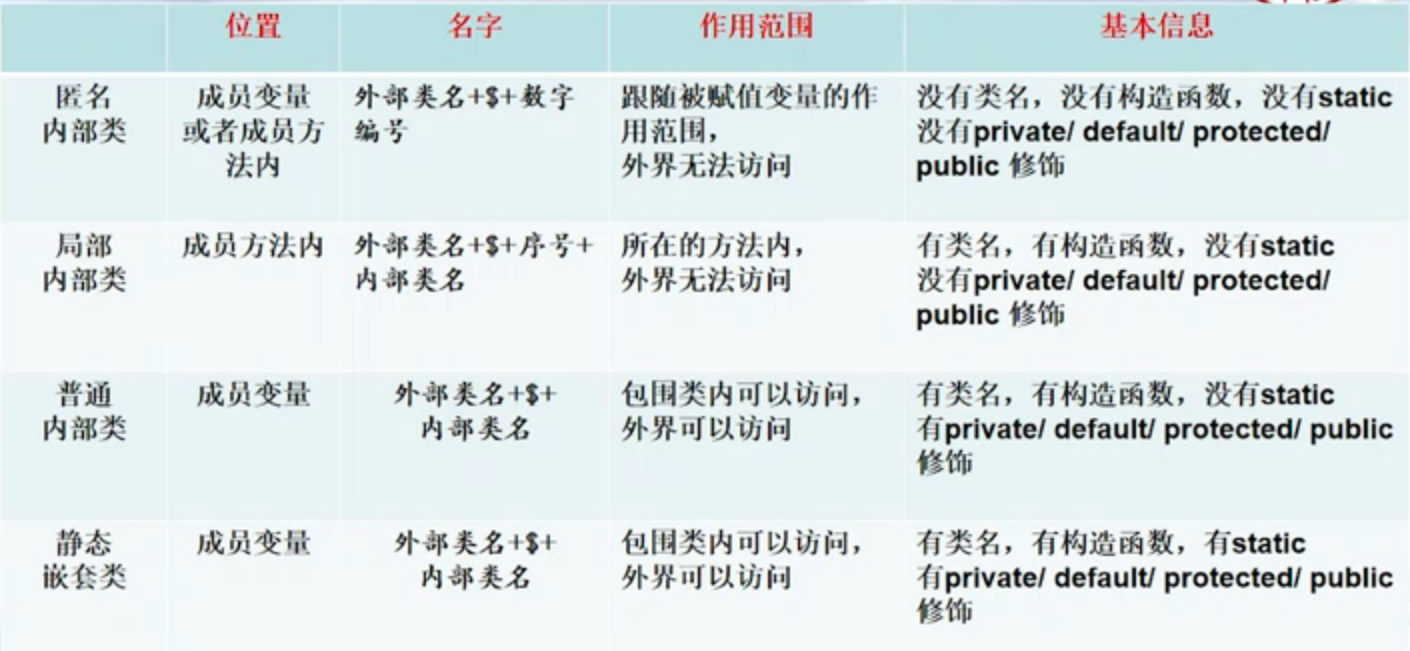
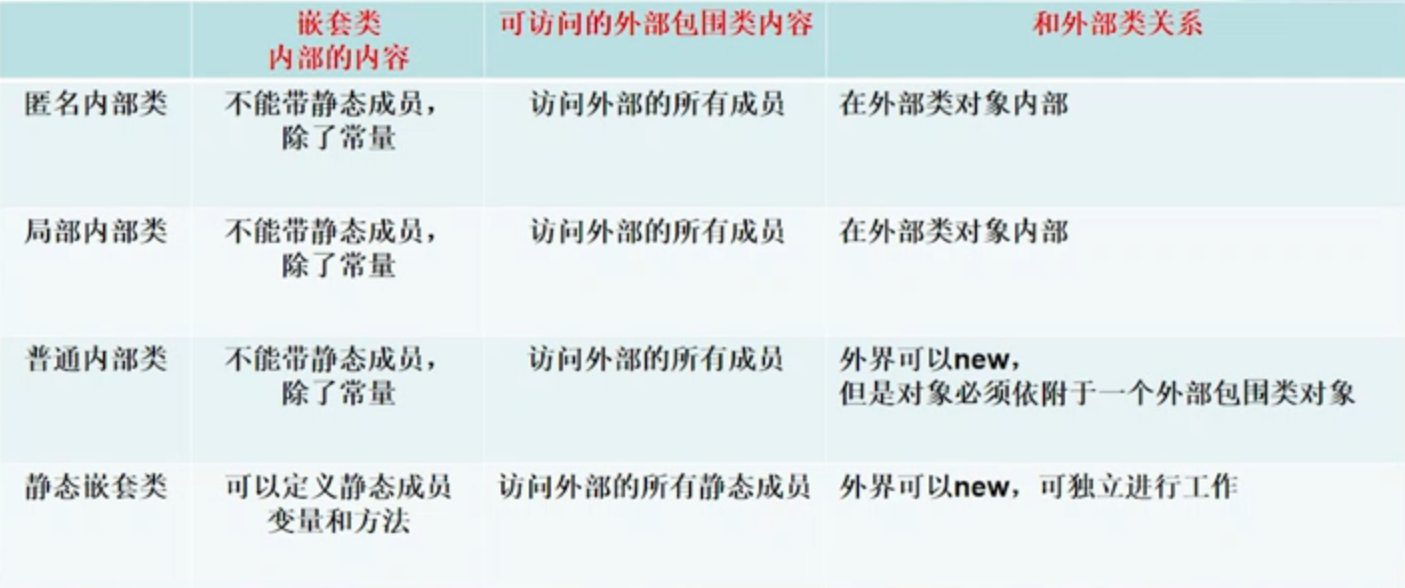
5、嵌套类应用
匿名内部类:
- 无需类名,用过即焚,使用广泛
- 该类的对象只要一个,且方法只有一个,代码短
- Android中常用匿名内部类
局部内部类:
- 介于匿名内部类和普通内部类之间,使用较少
- 只用一次,就用匿名内部类,简便
- 使用多次,就上升到普通内部类,整个类都可以使用
普通内部类:
- 广泛应用在具有母子结构的类,内部类对象和外部类保持联系
- 如Map和Map.Entry等
静态嵌套类:
- 和普通类一致,只是“碰巧”声明在一个外围类的内部
- 如果不需要访问外围类的非静态成员,尽量将普通内部类变更为静态嵌套类
- 节省普通内部类和外围类的联系开销
- 使得外围类对象更容易被垃圾回收器回收
第七章 Lambda表达式
1、Lambda表达式入门
Lambda表达式:传递方法/代码块(函数式程序语言设计)
Lambda表达式形式:
(input parameters) -> expression
- 参数,箭头,一个表达式
(String first,String second) -> first.length()-second.length()
- 参数,箭头,{多个语句}
(first,second) ->{
//形参可以不写类型,可以从上下文推断出来
int ressult = (-1) * (first.length() - second.length());
return result;
}
Lambda表达式
类似于匿名方法,一个没有名字的方法
参数,箭头,表达式语句
可以忽略写参数类型
坚决不声明返回值类型。如果有返回值类型,返回值类型会在上下文推断出来的,无需声明
没有权限修饰符
单句表达式,将直接返回值,不用大括号
特例
带return语句,算多句,必须使用大括号
无参数,仅保留括号,箭头,表达式
一个参数,可省略括号
2、函数式接口
函数式接口(Functional Interface)
- 是一个接口,符合Java接口的定义
- 只包含一个抽象方法的接口
- 可以包括其他的default方法、static方法、private方法
- 由于只有一个未实现的方法,所以Lambda表达式可以自动填上这个尚未实现的方法
- 采用Lambda表达式,可以自动创建出一个(伪)嵌套类的对象(没有实际的嵌套类class文件产生),然后使用,比真正嵌套类更加轻量,更加简洁高效
个人理解:
Lambda表达式只能应用于函数式接口中,函数式接口中,只有一个未实现的方法,即有定义而无实现;Lambda表达式有实现而无定义。故而,Lambda表达式自动替换函数式接口中的抽象方法的实现。
Comparator接口:有2个未实现的方法
- compare、equals
- 任何实现Comparator接口的类,肯定继承了Object,也就有equals实现
自定义函数式接口
@FunctionalInterface
//系统自带的函数式接口注解,用于编译器检查
public interface StringChecker {
public boolean test(String s);
}
public static void main(String[] args) {
String[] arr = new String[]{"Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"};
StringChecker evenLength = s -> {
if (s.length() % 2 == 0)
return true;
return false;
};
for (String s : arr) {
if (evenLength.test(s)) {
System.out.println("s = " + s);
}
}
}
系统自带的函数式接口
- 涵盖大部分常用的功能,可以重复使用
- 位于java.util.function包中
- 常用的函数式接口
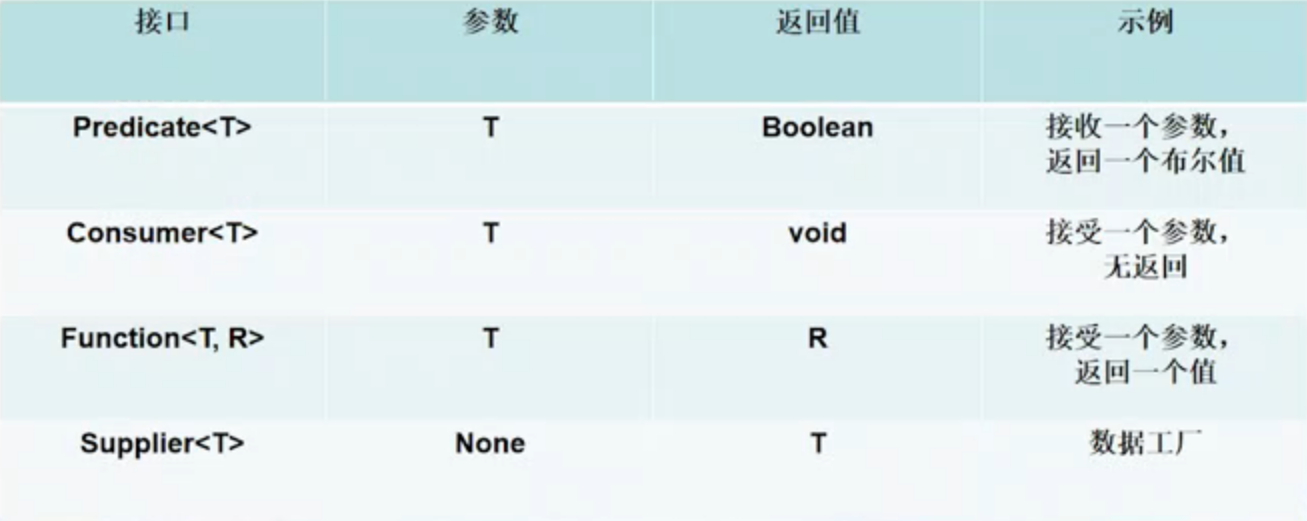
| 函数式接口 | 方法 |
|---|---|
| predicate | test |
| consumer | accept |
| supplier | get |
| function | apply |
eg:
predicate
String[] arr = new String[]{"Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"};
Predicate<String> oddLength = s -> s.length() % 2 == 0 ? false : true;
for (String s : arr) {
if (oddLength.test(s)){
System.out.println("s = " + s);
}
}
consumer
Consumer<String> printer=s -> System.out.println("printer = " + s);
for (String p : arr) {
printer.accept(p);
}
function
Supplier<String> supplier = () -> arr[m];
System.out.println("supplier = " + supplier.get());
3、方法引用
方法引用:Method Reference
- Lambda表达式支持传递现有的类库函数
eg:
String[] arr = new String[]{"Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"};
Arrays.sort(arr, String::compareToIgnoreCase);
System.out.println("Arrays.toString(arr) = " + Arrays.toString(arr));
方法引用:
- Class::staticMethod,如Math::abs方法,等价于x->Math.abs(x)
- Class::instanceMethod,如String::compareToIgnoreCase方法,等价于(x,y)->x.compareToIgnoreCase(y)
- object::instanceMethod,如System.out::println方法,等价于x->System.out.println(x)
- 支持this::instanceMethod调用
- 支持super::instanceMethod调用
- Class::new,调用某类构造函数,支持单个对象构建
- Class[]::new,调用某类构造函数,支持数组对象构建
4、Lambda表达式应用
- 类似于匿名方法,一个没有名字的方法
- 被赋值后,可以看做是一个函数式接口的实例(对象)
- 但是Lambda表达式没有存储目标类型的信息
注意:
-
Lambda表达式没有变量遮蔽问题,因为它的内容和嵌套块有着相同的作用域
- 所以,在Lambda表达式中,不可以声明与(外部嵌套块)局部变量同名的参数或者局部变量
-
Lambda的this指代。表达式中的this,是指创建这个表达式的方法的this参数。
- 因为Lambda表达式是先在方法中执行完毕后,再将函数式接口中的方法替换
- 所以Lambda表达式缺点:无法获得自身的引用(this)
-
优先级:即使用时优先考虑
- 方法引用>Lambda表达式>嵌套类
- Lambda表达式:系统自带函数式接口>自定义函数式接口
第八章 Java Stream流
1、流的概述
Stream流:a sequence elements from source that supports aggregate operations
Stream流的两个特性:
- pipelining:很多流操作也是返回一个流(流对象的流操作返回流对象)
- Internal Iteration:流操作进行迭代,用户感知不到循环遍历(流自动进行内部迭代)
Stream语法
- 类似SQL语句,遵循“做什么而非怎么做”原则
流的工作流程
- 流的创建
- 流的转换,将流转换为其他流的中间操作,可包括多个步骤(惰性操作)
- 流的计算结果。这个操作会强制执行之前的惰性操作。这个步骤以后,流就不会再用了。
- 注意:只有经过第三步流计算,才能执行第二步的流转换。也就是说,第二步只是将表达式写出,而并没有启动运行
2、流的创建
流的创建
1、Collection接口的stream方法
Stream<String> stream = new ArrayList<String>().stream();
2、Arrays.stream可以将数组转为Stream
Stream<String> b1 = Arrays.stream("a,b,c,d,e".split(","), 3, 5);
3、利用Stream类进行转化
- of方法,直接将数组转化
Stream<Integer> c1 = Stream.of(new Integer[5]);
- empty方法,产生一个空流
Stream<String> d1 = Stream.empty();
- generate方法,接收一个Lambda表达式
Stream<String> generate = Stream.generate(() -> "hello");
Stream<Double> generate1 = Stream.generate(Math::random);
- iterate方法,接收一个种子,和一个Lambda表达式
Stream.iterate(1.0, n -> n * 2);
4、其他类/方法产生Stream流
- Files.lines方法
Stream<String> contents = Files.lines(Paths.get(fileName));
- Pattern的splitAsStream方法
Stream<String> words = Pattern.compile(",").splitAsStream("a,b,c");
基本类型流(只有三种)
- IntStream,LongStream,DoubleStream
IntStream s1 = IntStream.of(1, 2, 3, 4, 5);
s1 = Arrays.stream(new int[]{1, 2, 3});
s1 = IntStream.generate(() -> (int) (Math.random() * 100));
s1 = IntStream.range(1, 5); //1,2,3,4 step 1
s1 = IntStream.rangeClosed(1, 5); //1,2,3,4,5
IntStream s2 = IntStream.of(1, 2, 3, 4, 5);
Stream<Integer> s3 = s2.boxed(); //基本类型流-->对象流
IntStream s4 = s3.mapToInt(Integer::intValue); //对象流-->基本类型流
并行流
- 使得所有的中间转换操作都将被并行化
- Collections.parallelStream()将任何集合转为并行流
- Stream.parallel()方法,产生一个并行流
- 注意:需要保证传给并行流的操作不存在竞争
IntStream stream1 = IntStream.range(1, 100000000);
long evenNum = stream1.parallel().filter(n -> n % 2 == 0).count();
System.out.println("evenNum = " + evenNum);
3、流的转换
流的转换,是从一种流到另外一种流
- 过滤,去重
- 排序sorted
- 转化
- 抽取/跳过/连接
- 其他
过滤filter
-
filter(Predicate<? super T> predicate) -
接收一个Lambda表达式,对每个元素进行判定,符合条件的留下
去重distinct
- 对流的元素进行过滤,去除重复,只留下不重复的元素
转化map
- 利用方法引用/Lambda表达式对流每个元素进行函数计算,返回stream
转化
- 抽取limit:限制返回流的元素个数
- 跳过skip:跳过前面的n个元素
- 连接concat:将流的结果连接起来
其他
- 额外调试peek:
Stream<Double> limit = Stream.iterate(1.0, n -> n * 2).peek(n -> System.out.println("number:" + n)).limit(5);
4、Optional类型
Optional<T> 解决NullPointerException异常问题
- 一个包装器对象
- 数据对象容器
- Java用来解决NullPointerException的一把钥匙
- 在流运算中,避免对象是否null的判定
- 要么包装了类型T的对象,要么没有包装任何对象(还是null)
- 如果T有值,那么直接返回T的对象
- 如果T是null,那么可以返回一个替代物
Optional<String> s1 = Optional.of(new String("abc"));
String s2 = s1.get();
System.out.println("s2: " + s2); //abc
Optional<String> s3 = Optional.empty();
String s4 = s3.orElse("def");
System.out.println("s4: " + s4); //def
Optional<T>创建
- of方法
- empty方法
- ofNullable方法,对于对象有可能为null情况下,安全创建
Optional<String> s5 = Optional.of(new String("abc"));
Optional<String> s6 = Optional.empty();
String s7 = null;
Optional<String> s8 = Optional.ofNullable(s7);
//s7不为Null,s8就是s7, 否则s8就为Optional.empty()
Optional<T>使用
- get,获取值,不安全的用法。NoSuchElementException异常
- orElse方法,获取值,如果为null,采用替代物的值
- orElseGet方法,获取值,如果为null,采用Lambda表达式值返回
- orElseThrow方法,获取值,如果为null,抛出异常
- ifPresent方法,判断是否为空,不为空返回true
- ifPresent(Consumer),判断是否为空,如果不为空,则进行后续Consumer操作,如果为空,则不做任何事情
- map(Function),将值传递给Function函数进行计算。如果为空,则不计算
5、流的计算结果
流的计算
-
约简
-
简单约简(聚合函数):count/max/min/……
- count
- max/min(Comparator),最大/小值,需要比较器
- findFirst(),找到第一个元素;findAny(),找到任意一个元素
- anyMatch(Predicate),如有任意一个元素满足Predicate,返回true;AllMatch,所有元素满足Predicate,返回true;noneMatch(Predicate),如没有任何元素满足Predicate,返回true
-
自定义约简:reduce
- reduce,传递一个二元函数BinaryOperator,对流元素进行计算。如求和,求积、字符串拼接等
Optional<Integer> sum = s1.reduce(Integer::sum); Optional<Integer> product = s2.reduce((x,y)->x*y);
-
-
查看/遍历元素:iterator/forEach
-
存放到数据结构中
- toArray(),将结果转为数组
- collect(Collectors.toList()),将结果转为List
- collect(Collectors.toSet()),将结果转为Set
- collect(Collectors.toMap()),将结果转为Map
- collect(Collectors.joining()),将结果连接起来
6、流的应用
stream应用注意事项:
-
一个流,一次只能一个用途,不能多个用途,用了之后不能再用

-
避免创建无限流
//无限流 IntStream.iterate(0, i -> i + 1) .forEach(System.out::println); //需要对流元素进行限制 IntStream.iterate(0, i -> i + 1) .limit(10).forEach(System.out::println); //又一个无限流 IntStream.iterate(0, i -> ( i + 1 ) % 2) .distinct().limit(10).forEach(System.out::println); -
注意操作顺序
-
谨慎使用并行流
- 底层使用Fork-Join Pool,处理计算密集型任务
- 数据量过小不用
- 数据结构不容易分解的使用不用,如LinkedList等
- 数据频繁拆箱装箱不用
- 设计findFirst或者limit的时候不用
-
Stream VS Collection
- stream和collection两者可以相互转化
- 如果数据可能无限,用stream
- 如果数据很大很大,用stream
- 如果调用者将使用查找/过滤/聚合等操作,用stream
- 当调用者使用过程中,发生数据改变,而调用者需要对数据一致性有较高要求,用Collection
第九章 Java模块化
1、Java模块化概述
模块化必须遵循的三个原则:
- 强封装性:一个模块必须能够对其他模块隐藏其部分代码
- 定义良好的接口:模块必须向其他模块公开良好且稳定的接口
- 显式依赖:明确一个模块需要哪些模块的支持才能完成工作
java9开始引入新的模块化系统:Jigsaw拼图
- 以模块(module)为中心
- 对JDK本身进行模块化
- 提供一个应用程序可以使用的模块系统
- 优点
- 可靠的配置
- 强封装性
- 可扩展开发
- 安全性
- 性能优化
2、模块创建和运行
Java Jigsaw
-
自Java 9推出,以模块为中心
-
在模块中,仍以包-类文件结构存在
-
每个模块中,都有一个module-info.java
- 说明这个模块依赖哪些其它的模块,输出本模块中哪些内容
module java.prefs{ requires java.xml; //本模块需依赖的模块 exports java.util.prefs; //输出给别人使用 }
3、模块信息文件
4、服务
5、Java模块化应用
第十章 Java字节码
1、Java字节码概述
2、Java字节码文件构成
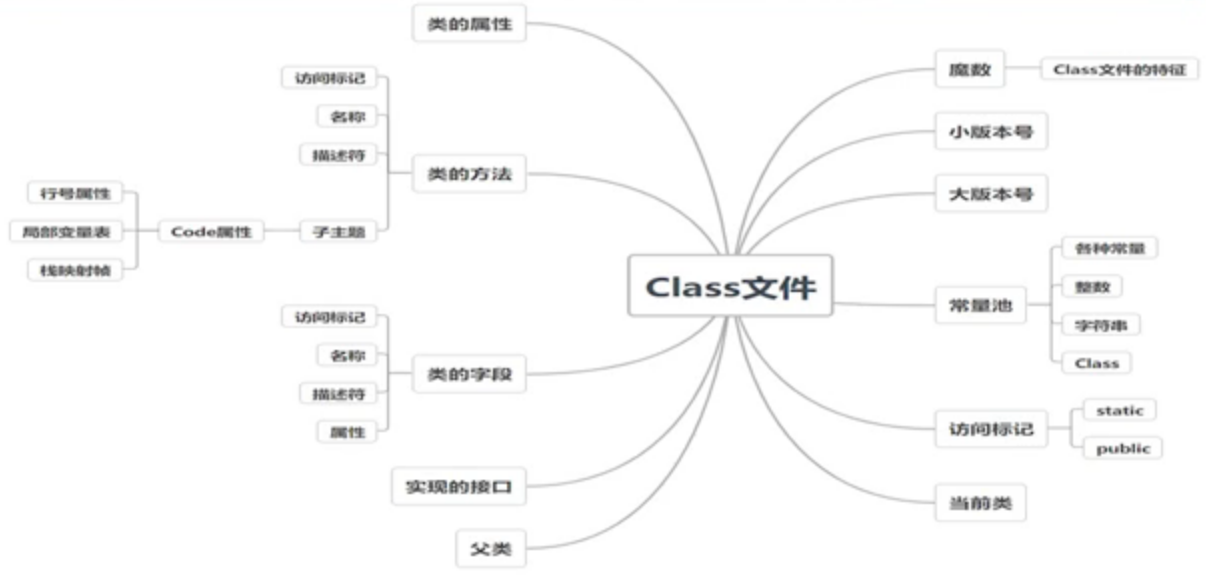
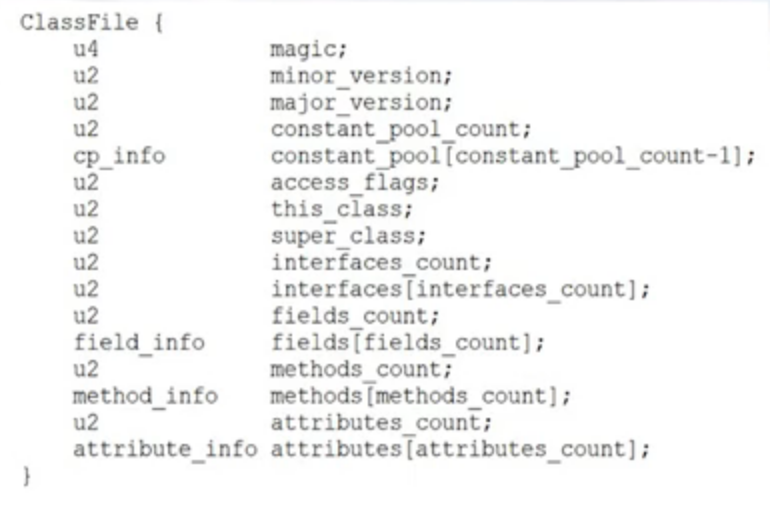
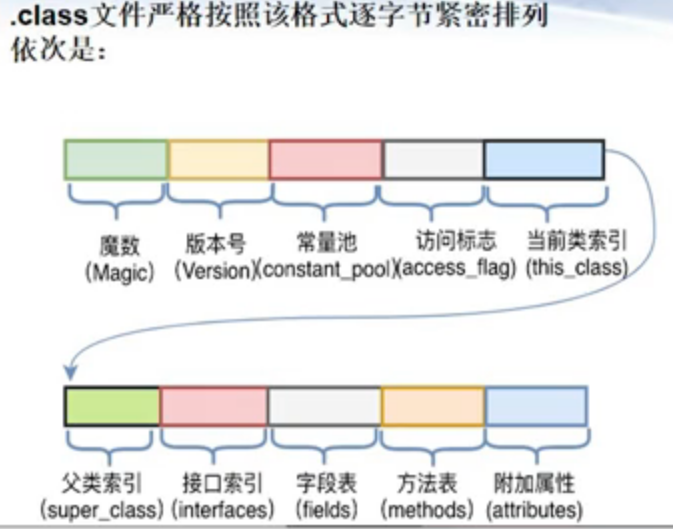
jdk提供了javap来对class文件做反汇编
- 前4个字节为魔数,十六进制表示为0xCAFEBABE,标识该文件为class文件
- 第5、6字节表示次版本号,第7、8字节表示主版本号
- 主版本号与jdk版本有映射关系
- 常量池 主要存放两大类常量
- 字面量,如文本字符串、final的常量值等
- 符号引用
- 类和接口的全限定名
- 字段的名称和修饰符
- 方法的名称和描述符
- 访问标志 (类的修饰符,即该Class是类还是接口,以及其修饰符)
- 类索引、父类索引、接口索引集合
- 描述的是当前类/父类/接口集合的全限定名,保存的是常量池中的索引值
- 字段表 成员变量
- 方法表 成员方法
- 附加属性。该项存放了在该文件中类或接口所定义属性的基本信息
- 属性信息相对灵活,编译器可自由写入属性信息,JVM会忽略不认识的属性信息
3、Java字节码指令分类
- 加载和存储指令
- 用于将数据在栈帧中的局部变量表和操作数栈之间来回传输
- 将一个局部变量加载到操作栈:iload,lload.fload,dload,aload等
- 将一个数值从操作栈存储到局部变量表:istore,Istore,fstore,dstore,astore等
- 将一个常量加载到操作栈:bipush,sipush,Idc,Idc_w,Idc2_w,aconst_null,iconst_m1等
- 运算指令
- iadd,isub,imul,idiv等
- 类型转换指令
- 对象/数组创建与访问指令
- 操作栈管理指令
- pop,dup等
- 控制转移指令
- ……
-
JVM指令由操作码和零至多个操作数组成
- 操作码
- 操作数(操作所需参数)
-
JVM的指令集是基于栈而不是寄存器
- 字节码指令控制的是JVM操作栈
4、Java字节码操作
ASM:是生成、转换、分析class文件的工具包(第三方库)
5、Java字节码增强
- 字节码操作:通常在字节码使用之前完成
- 源码、编译、(字节码操作)、运行
- 字节码增强:运行时对字节码进行修改/调换
6、Java字节码混淆
字节码保护
- 字节码加密
- 对字节码进行加密,不再遵循JVM制定的规范
- JVM加载之前,对字节码解密后,再加载
- 字节码混淆
- 被混淆的代码依然遵循JVM制定的规范
- 变量命名和程序流程上进行等效替换,使得程序的可读性变差
- 代码难以被理解和重用,达到保护代码的效果
ProGuard
- 最著名的Java字节码混淆器
- 除了混淆,还具有代码压缩、优化、预检等功能
- 可以命令行运行,也可以集成到IDE
- 也可以与Maven相结合
- 注意事项
- 反射调用类或者方法,可能失败
- 对外接口的类和方法,不要混淆,否则调用失败
- 嵌套类混淆,导致调用失败
- native的方法不要混淆
- 枚举类不要混淆
- ……
7、Java字节码总结和展望
第十一章 Java类加载器
1、Java类加载机制
类加载器ClassLoader
- 负责查找、加载、校验字节码的应用程序
- java.lang.ClassLoader
- load(String className)根据名字加载一个类,返回类的实例
- defineClass(String name,byte[] b,int off,int len)将一个字节流定义一个类
- findClass(String name)查找一个类
- findLoadedClass(String name)在已加载的类中,查找一个类
- 成员变量ClassLoader parent;
- JVM四级类加载器
- 启动类加载器(Bootstrap),系统类rt.jar
- 扩展类加载器(Extension),jre/lib/ext
- 应用类加载器(App),classpath
- 用户自定义加载器(Plugin),程序自定义
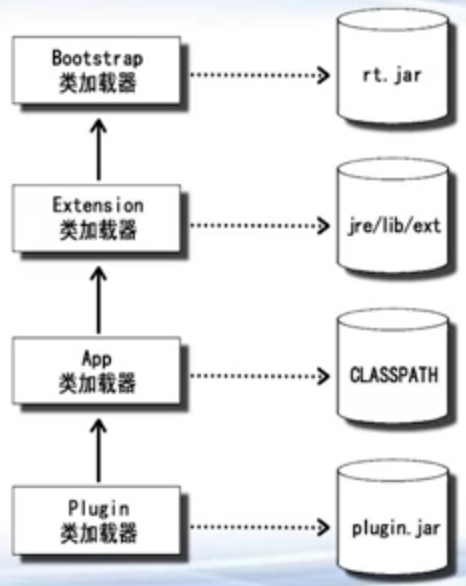
- 类加载器双亲委托模型
- 首先判断是否已经加载
- 若无,找父加载器(父父类加载器)加载
- 若再无,由当前加载器加载
eg:
public class ClassLoaderTree {
public static void main(String[] args) {
ClassLoader c = ClassLoaderTree.class.getClassLoader();
while(null != c)
{
System.out.println(c.getClass().getName());
c = c.getParent();
}
if(null == c){
System.out.println("BootstrapLoader is implemented by C ");
}
}
}
结果:
jdk.internal.loader.ClassLoaders$AppClassLoader
jdk.internal.loader.ClassLoaders$PlatformClassLoader
BootstrapLoader is implemented by C
2、Java类双亲委托加载扩展
Java严格执行双亲委托机制
- 类会由最顶层的加载器来加载,如没有,才由下级加载器加载
- 委托是单向的,确保上层核心的类的正确性
- 但是上级类加载器所加载的类,无法访问下级类加载器所加载的类
- 例如,java.lang.String无法访问自定义的一个Test类
- Java是一个遵循契约设计的程序语言,核心类库提供接口,应用层提供实现
- 核心类库是BootstrapClassLoader加载
- 应用层是AppClassLoader加载
- 典型例子是JDBC和XML Parser等
解决问题:如何使得上层类加载器的类能够使用下级类加载器的类
- 双亲委托的补充
- 执行java,添加虚拟机参数-Xbootclasspath/a:path,将类路径配置为Bootstrap等级
- 使用ServiceLoad.load方法,来加载(底层加载器所加载的类),如JDBC
- java.sql.DriverManager是Bootstrap加载器加载的,需要访问到com.mysql.jdbc.Driver类
3、自定义类加载路径
用户自定义类加载器
-
自定义加载路径
- 弥补类搜索路径静态的不足
- URLClassLoader,从多个URL(jar或者目录)中加载类
-
自定义类加载器
- 继承ClassLoader类
- 重写findClass(String className)方法
自定义加载路径
- 继承于ClassLoader
- 程序运行时增加新的类加载路径
- 可从多个来源中加载类
- 目录
- jar包
- 网络
- addURL添加路径
- close方法关闭
eg:
//URL支持http, https, file, jar 四种协议
URL url = new URL("file:D:\\software\\IDM\\download\\Java核心技术_高阶\\PMOOC11-03-First\\bin\\");
//URL url = new URL("file:C:/Users/Tom/Desktop/PMOOC11-03-First.jar");
//程序运行时,添加一个classpath路径
URLClassLoader loader = new URLClassLoader(new URL[]{url});
Class<?> c = loader.loadClass("edu.ecnu.Hello");
//采用反射调用
Method m = c.getMethod("say");
m.invoke(c.newInstance());
System.out.println(c.getClassLoader());
System.out.println(c.getClassLoader().getParent());
4、自定义类加载器
自定义类加载器
- 继承ClassLoader类
- 重写findClass(String className)方法
- 使用时,默认先调用loadClass(className)来查看是否已经加载过,然后委托双亲加载,如果都没有,再通过findClass加载返回
- 在findClass中,首先读取字节码文件
- 然后,调用defineClass(className,bytes,off,len)将类注册到虚拟机中
- 可以重写loadClass方法来突破双亲加载(不推荐使用)
eg:
自定义类加载器CryptoClassLoader
public Class<?> findClass(String name) throws ClassNotFoundException
{
try
{
byte[] classBytes = null;
//读取Hello.class文件,得到所有字节流
classBytes = loadClassBytes(name); //自定义的一个方法,获取hello.class文件字节流
//调用defineClass方法产生一个类,并在VM中注册
Class<?> cl = defineClass(name, classBytes, 0, classBytes.length);
if (cl == null) throw new ClassNotFoundException(name);
return cl;
}
catch (IOException e)
{
throw new ClassNotFoundException(name);
}
}
自定义类加载器调用
ClassLoader loader = new CryptoClassLoader();
//loadClass去加载Hello类
//loadClass是ClassLoader默认方法,通过委托双亲去加载类
//如加载不到,则调用findClass方法加载
Class<?> c = loader.loadClass("edu.ecnu.Hello");
Method m = c.getMethod("say");
m.invoke(c.newInstance());
System.out.println(c.getClassLoader().getClass().getName());
注意:同一个类可以被不同层级的加载器加载,且作为2个类对待
5、Java类加载器总结与展望
JVM四级类加载器的动态性
- 使用虚拟机参数-Xbootclasspath,将jar或目录提高到Bootstrap等级
- 使用ServiceLoader和SPI机制,实现上层加载器的类,访问下层加载器的类
- 使用URLClassLoader,可以在运行时增加新的classpath路径
- 使用自定义的ClassLoader,可以通过重写findClass方法动态加载字节码,还可以在加载字节码过程中进行修改/校验等操作
第十二章 JVM内存管理
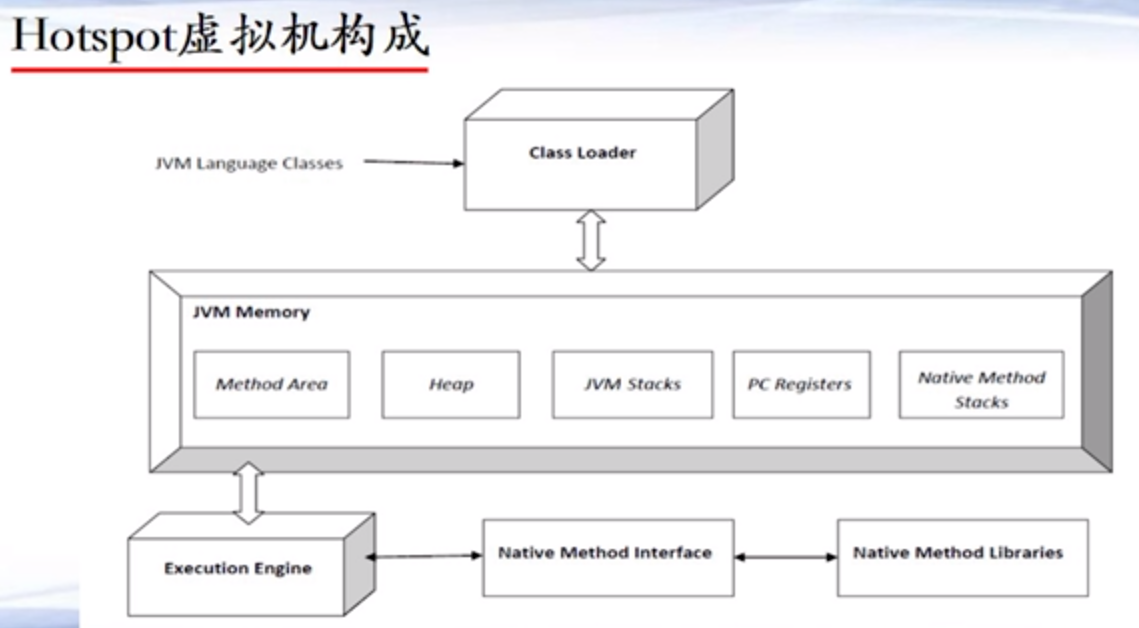
1、JVM概述
2、JVM内存分类
Java自动内存管理
- 传统程序语言:由程序员手动内存管理
- C/C++,malloc申请内存和free释放内存
- 由于程序员疏忽或程序异常,导致内存泄漏
- 现代程序语言:自动内存管理
- Java/C#,采用自动内存管理
- 程序员只需要申请使用,系统会检查无用的对象并回收内存
- 系统统一管理内存,内存使用相对高效,但也会出现异常
JVM内存分类
- 线程私有内存
- 寄存器(程序计数器)(Program Counter Register)
- Java虚拟机栈(JVM Stack)
- 本地方法栈(Native Method Stack)
- 多线程共享内存
- 堆(Heap)
- 方法区(Method Area)
- 运行时常量池
程序计数器(Program Counter Register)
- 一块小内存,每个线程都有
- PC存储当前方法
- 线程正在执行的方法称为该线程的当前方法
- 当前方法为本地(native)方法时,pc值未定义(undefined)
- 当前方法为非本地方法
JVM栈
- 每个线程有自己独立的Java虚拟机栈,线程私有
- Xss设置每个线程栈大小
- Java方法的执行基于栈
- 引发的异常
- 栈的深度超过虚拟机规定深度,StackOverflowError异常
- 无法扩展内存,OutOfMemoryError异常
本地方法栈
- 存储native方法的执行信息,线程私有
堆
- 虚拟机启动时创建,所有线程共享,占地最大
- 对象在堆上分配内存
- 垃圾回收的主要区域
- 设置大小
- Xms初始堆值,Xmx最大堆值
- 引发的异常 无法满足内存分配要求,OutOfMemoryError异常
方法区
- 存储JVM已经加载类的结构,所有线程共享
- 运行时常量池、类信息、常量、静态变量等
- JVM启动时创建,逻辑上属于堆(Heap)的一部分
- 很少做垃圾回收
- 运行时常量池(Run-Time Constant Pool)
- Class文件中常量池的运行时表示
- 属于方法区的一部分
- 动态性:Java语言并不要求常量一定只有在编译期产生

3、JVM内存参数
堆
- 共享,内存大户,存储所有的对象和数组
- Xms初始堆值,-Xmx最大堆值
栈
- 线程私有,存储类中每个方法的内容
- Xss最大栈值
4、Java对象引用
JVM内置有垃圾收集器
- GC,Garbage Collector
- 自动清除无用的对象,回收内存
垃圾收集器的工作职责
- 什么内存需要收集(判定无用的对象)
- 什么时候回收(何时启动,不影响程序正常运行)
- 如何回收(回收过程,要求速度快/时间短/影响小)
Java对象的生命周期
- 对象通过构造函数创建,但是没有析构函数回收
- 对象存活在离它最近的一对大括号中
垃圾收集器基于对象引用判定无用对象
- 零引用,互引用等
Java四种对象引用:
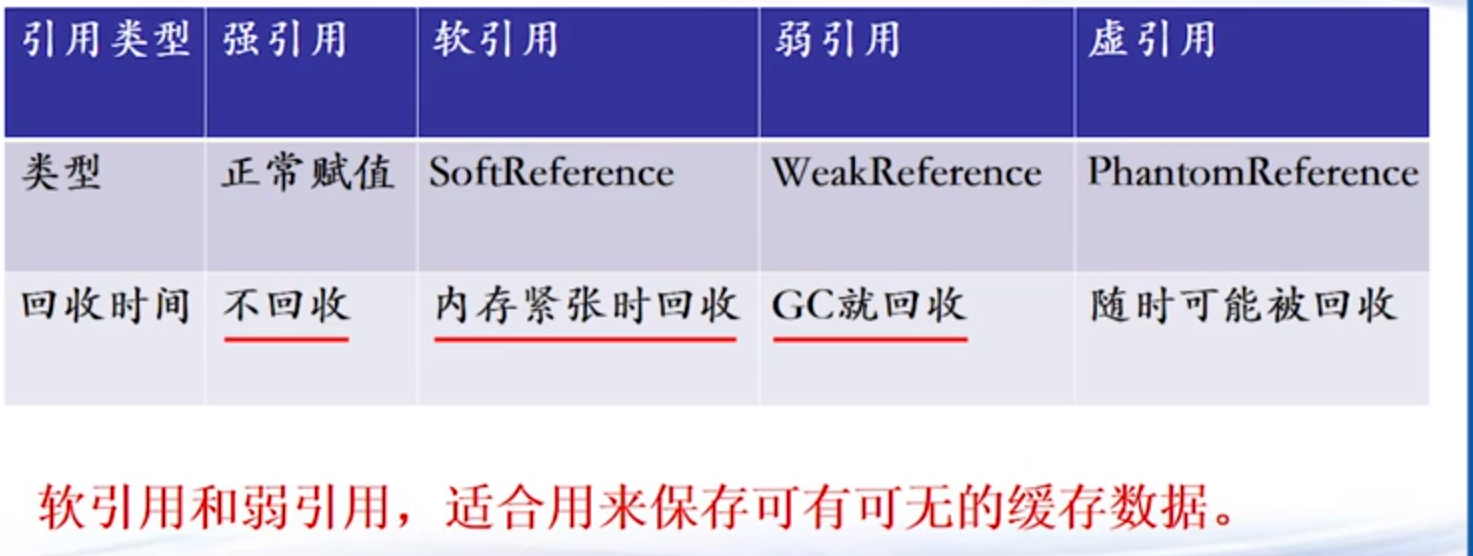
WeakReference:只能存活到下一次垃圾回收前
5、垃圾收集算法
垃圾收集器如何回收(回收过程,要求速度快/时间短/影响小)
1、引用计数法
- 每个对象都有一个引用计数器。有引用,计数器+1,当引用失效,计数器-1。计数器为0,的对象,将被回收
- 优缺点
- 优点:简单,效率高
- 缺点:无法识别对象之间相互循环引用
2、标记-清除
- 标记阶段:标记出所有需要回收的对象
- 回收阶段:统一回收所有被标记的对象
- 优缺点
- 优点:简单
- 缺点:效率不高;内存碎片
3、复制算法
- 将可用内存按容量划分为大小相等的两块,每次只使用其中的一块
- 当这一块的内存用完了,就将还存活着的对象复制到另外一块上面
- 然后再把已使用过的内存空间一次清理掉
- 优缺点
- 优点:简单、高效
- 缺点:可用内存减少;对象存活率高时复制操作较多
4、标记-整理
- 标记阶段:与“标记-清理”算法一样
- 整理阶段:让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存
- 优缺点
- 优点:避免碎片产生;无需两块相同内存
- 缺点:计算代价大,标记清理+碎片整理;更新引用地址
5、分代收集(现在标准JVM普遍采用的垃圾收集算法)
- Java对象的生命周期不同,有长有短
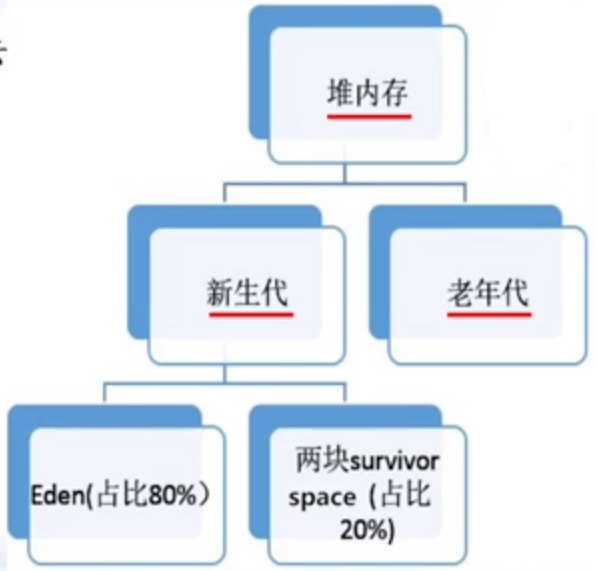
- 根据对象存活周期,将内存划分新生代和老年代
- 新生代
- 主要存放短暂生命周期的对象
- 新创建的对象都先放在新生代,大部分新建对象在第一次gc时被回收
- 老年代
- 一个对象经过几次gc仍存活,则放入老年代
- 这些对象可以存活很长时间,或者伴随程序一生,需要常驻内存的,可以减少回收次数
- 针对各个年代特点采用合适的收集算法
- 新生代 复制算法
- 老年代 标记清除或标记整理

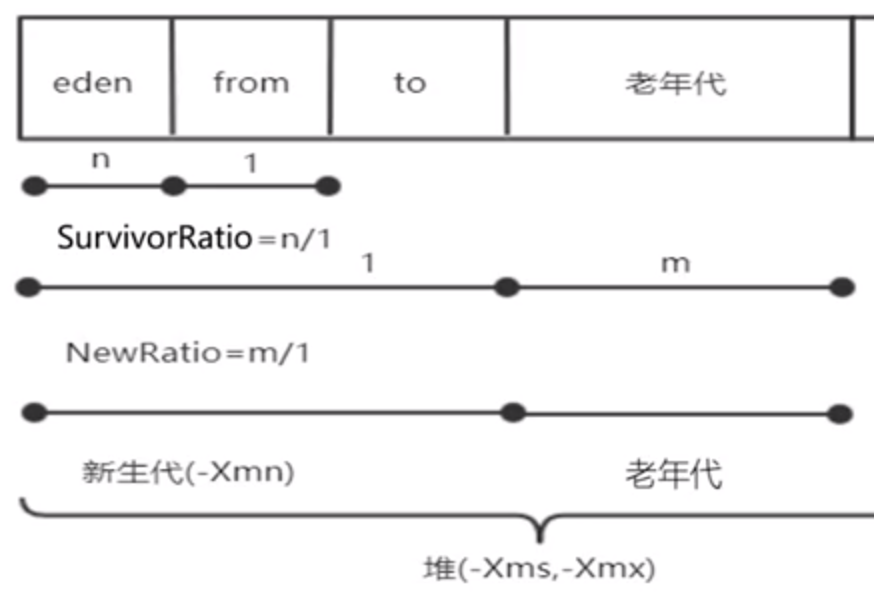
6、JVM堆内存参数和GC跟踪
堆内存参数
-
Xms初始堆大小
-
Xmx最大堆大小
-
Xmn新生代大小
-
XX:SurvivorRatio设置eden区/from(to)的比例
-
XX:NewRatio设置老年代/新生代比例
-
XX:PrintGC/XX:+PrintGCDetails打印GC的过程信息
eg:
/**
* 来自于《实战Java虚拟机》
* -Xmx20m -Xms20m -Xmn1m -XX:SurvivorRatio=2 -XX:+PrintGCDetails -XX:+UseSerialGC
* 新生代1M,eden/s0=2, eden 512KB, s0=s1=256KB
* 新生代无法容纳1M,所以直接放老年代
*
* -Xmx20m -Xms20m -Xmn7m -XX:SurvivorRatio=2 -XX:+PrintGCDetails -XX:+UseSerialGC
* 新生代7M,eden/s0=2, eden=3.5M, s0=s1=1.75M
* 所以可以容纳几个数组,但是无法容纳所有,因此发生GC
*
* -Xmx20m -Xms20m -Xmn15m -XX:SurvivorRatio=8 -XX:+PrintGCDetails -XX:+UseSerialGC
* 新生代15M,eden/s0=8, eden=12M, s0=s1=1.5M
*
* -Xmx20m -Xms20m -XX:NewRatio=2 -XX:+PrintGCDetails -XX:+UseSerialGC
* 新生代是6.6M,老年代13.3M
* @author Tom
*
*/
public class NewSizeDemo {
public static void main(String[] args) {
byte[] b = null;
for(int i=0;i<10;i++)
{
b = new byte[1*1024*1024];
}
}
}
现有垃圾收集器
-
串行收集器(Serial Collector)
-
并行收集器(Parallel Collector)
-
……
注意:本章所学的JVM内存管理和Java并发内存模型不同
第十三章 Java运行管理
1、Java运行管理概述
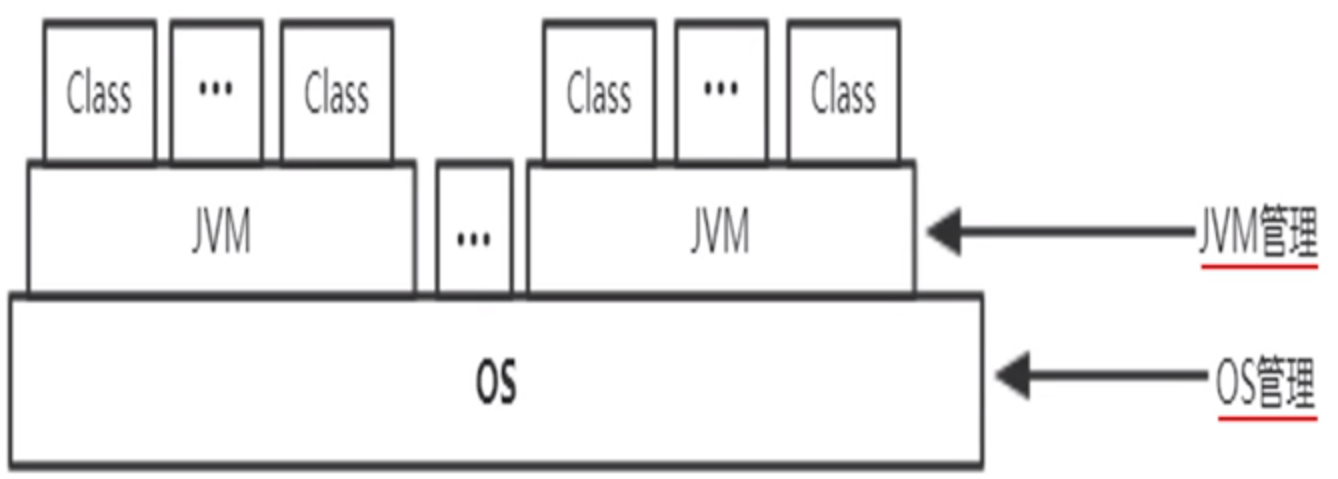
OS管理
- 进程级别的管理(黑盒)
- CPU/内存/IO等具体性能监控
JVM管理
- 线程/程序级别的管理(白盒)
- 查看虚拟机运行时各项信息
- 跟踪程序的执行过程,查看程序运行时信息
- 限制程序对资源的使用
- 将内存导出为文件进行具体分析
- ……
2、OS层管理
Linux平台管理
- top命令 查看系统中最占资源的部分
- vmstat命令 查看系统整体的CPU/内存/IO/Swap等信息
- iostat命令 查看系统详细的IO信息
Windows平台管理
- 任务管理器
- perfmon工具(性能监视器)(Process Explorer)
3、JDK管理工具
jdk管理工具
- 编译/运行工具:javac/java
- 打包工具:jar
- 文档工具:javadoc
- 国际化工具:native2ascii
- 混合编程工具:javah
- 反编译工具:javap
- 程序运行管理工具:jps/jstat/jinfo/jstack/jstatd/jcmd
4、可视化管理工具
可视化Java管理工具
- JConsole
- Visual VM
- Mission Control
JConsole
- 监管本地Java进程
- 监管远程Java进程
- 需要远程进程启动开启JMX服务
- 静态监控
Visual VM
- 可以查看、统计,也可以支持插件扩展
- 动态监控
- jvisualvm
Mission Control
- jmc
- 带有商业化色彩
5、堆文件分析
jmap
- jdk自带的命令
- 可以统计堆内对象实例
- 可以生成堆内存dump文件
6、JMX
JMX
- Java Management eXtensions
- JMX是一个为应用程序植入管理功能的框架
- 用户可以在任何Java应用程序中使用这些代理和服务实现管理
JVM本身就是构架在JMX的基础之上
7、Java运行安全
Java提供安全管理器
-
对程序的行为进行安全判定,如违反,报错
-
加载安全策略文件
- 一个权限集合,包含各种权限,规定哪些程序可以做哪些功能
-
默认情况下,普通程序不加载安全管理器
-
启用安全管理器的两种方式
-
System.setSecurityManager(new SecurityManager()); -
加上启动参数
java -Djava.security.manager -Djava.security.policy=My.policy HelloWorld -
安全策略文件
-
建立代码来源和访问权限的关系
-
代码来源
- 代码位置
- 证书集
-
权限
- 由安全管理器负责加载的安全属性
-
系统默认的安全策略文件
-
%JAVA_HOME%/jre/lib/security/java.policy
-
-
可以自定义权限类,继承Permission类
第十四章:高阶总结
Spring
- Spring MVC框架和Spring Boot开发模式
- 最主要的特点
- IoC/DI,Inversion of Control/Dependency Injection 一种解决对象耦合的重要方法
- AOP,Aspect Oriented Programming 一种解决方法耦合的重要方法
Java核心技术(高阶)
- 着重高阶语法:语法糖、泛型、反射、代理、注解、嵌套类、Lambda、stream等
- 阐述底层原理:字节码、类加载器、JVM内存管理、Java运行管理等















 674
674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









