







指针使用分析:
提及指针早已不再感觉到陌生,大一初识C语言,老师就一再强调指针的重要性。而然一直以来对其的认识仅停留在“指针:指向其他数据的内存位置的变量”。现在我们不妨以指针如何用开始,再次探究指针。
先来看一段代码:
#include<iostream>
using namespace std;
int main(){
int *p;
cout << p << endl;
return 0;
}
声明一个int型指针,不妨先看一下其里有什么?编译控制台打印:一串十六进制数值。不禁疑问这串十六进制数值是什么?
对编译原理有简单了解的都清楚,上述C++代码经过编译器,首先会编译为汇编代码,汇编代码大概如以下形式:
mov 8(%rsp), %rax;
取出内存栈帧地址为:rsp(初始地址->堆栈寄存器)+8(偏移量)中的内容,然后放入rax寄存器中。汇编代码又会经过编译链接等步骤,最终变成可执行文件。
根据上述分析,可以推出:打印的结果应该是p内存中的内容。验证推断:我们不妨改变其内存地址中的内容,若与我们期望的内容一致,则推断成立。
int a = 10;
cout << &a << endl;
使用c提供的取地址操作符:&。获取a在内存中的地址。
p指向a,并且再次打印p中的内容:
#include<iostream>
using namespace std;
int main(){
int *p;
cout << p << endl;
int a = 10;
cout << &a << endl;
p = &a;
cout << p << endl;
return 0;
}
推论得证!
在此基础上,我们不妨再来探究一下指针的指针,加深一下对指针的印象。
p也是c的一种类型,像上述a一样,其在内存中也占有地址空间(汇编代码)。因此不妨先以上述类似的过程来理解指针的指针。
#include<iostream>
using namespace std;
int main(){
int **pp;
cout << pp << endl;
int *p;
cout << &p << endl;
pp = &p;
cout << pp << endl;
return 0;
}
结论同上述一样。
#include<iostream>
using namespace std;
int main(){
int **pp;
cout << pp << endl;
int *p;
cout << &p << endl;//取p的地址
cout << p << endl;//打印p中的内容
pp = &p;
cout << pp << endl;//取pp中的内容
cout << *pp << endl;//取pp指向的内容
return 0;
}
上述代码,又添加了验证pp指向的内存空间的内容。此过程是否同计组原理中的间接寻址极为相似。通过上述分析,不难推断出指针的一般行为。
进一步理解指针:
问题一:
存在整型变量a,以下等式是否成立?
a = *&a
不妨通过编译器试验一下:
if(x == *&x)
printf("yes\n");
else
printf("no\n");
分析: 上述等式不难理解,先获取a的地址,相当于新建一个指针,再通过*运算符取所指内存空间里的值,因此上述等式相等也就不难分析出来了。
指针类型分析:
C语言存在各种类型的指针声明,我们不禁会有疑问:指针不是存储别人的地址吗?为什么还要存在类型?
先看下32位机器上各数据类型以及指针的内存大小(单位:字节);
#include<iostream>
using namespace std;
int main(){
char *p_char;
char c;
cout << sizeof(c) << "\t" << sizeof(p_char) << endl;
short *p_short;
short s;
cout << sizeof(s) << "\t" << sizeof(p_short) << endl;
int *p_int;
int i;
cout << sizeof(i) << "\t" << sizeof(p_int) << endl;
float *p_float;
float f;
cout << sizeof(f) << "\t" << sizeof(p_float) << endl;
double *p_double;
double d;
cout << sizeof(d) << "\t" << sizeof(p_double) << endl;
long *p_long;
long l;
cout << sizeof(l) << "\t" << sizeof(p_long) << endl;
long long *p_llong;
long long ll;
cout << sizeof(ll) << "\t" << sizeof(p_llong) << endl;
return 0;
}
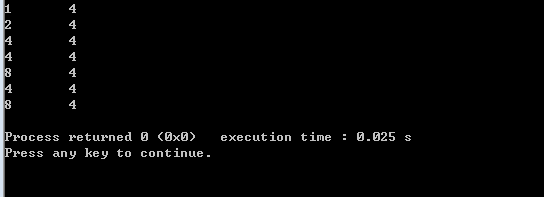
上述现象不难解释,32位机器内存地址需要4字节表示,因此各类指针所占内存大小皆为4字节。既然内存大小都一样,为什么还要区分类型呢?要想深入了解这些,不妨借助数组来进行探究说明。
数组也是一个指针,它指向数组在内存中的起始地址:
#include<bits/stdc++.h>
using namespace std;
#define N 6
int main(){
int ars[N];
for(int i = 0; i < N; i++)
ars[i] = rand() % 10;
for(int i = 0; i < N; i++)
cout << ars[i] << " ";
cout << endl;
for(int i = 0; i < N; i++)
cout << *(ars + i) << " ";
return 0;
}
运行上述代码,可以发现两次打印内容相同。为什么会出现这种情况?

如上图所示,我们可以将内存抽象理解为一个超大的数组,给定初始地址(也就是数组第一个元素的内存地址),每次加上偏移量也就可以确定数组中的其他元素。例如访问ars[2],即为ars+(2*4),ars为数组初始地址,2为访问第二个元素,4为int类型所占字节大小。看到这我们似乎可以得出指针为什么存在不同类型的答案了,如上述例子,数据类型为int类型,所以计算其偏移地址时最终会再乘上4,若数组类型为double,自然其偏移量会再乘上8,。原来其区别不同类型的原因是为了方便计算寻址。这种区分仅作用于汇编层面(C代码->编译器->汇编->汇编编译器->链接->可执行文件)。就像机器语言并不知道源操作数和目的操作数是有符号还是无符号一样,只能通过具体指令区别。
参考文献《深入理解计算机系统》















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









