







注:这是一篇跨模态小样本度量学习的文章。
动机:
在小样本学习中,模型不足以对新类别产生全面的理解,仅凭视觉去学习特征是不够的,需要通过语义信息去引导视觉感知,让模型更关注新类别的不同之处。如下图:对于耳廓狐这个新类别,视觉模型提取出的特征信息可能有的更关注亮度特征(绿色三角),有的更关注大耳朵特征(红色三角),但是加了语义信息的引导后,模型最后输出的特征均将重心转移至大耳朵这个特征上。
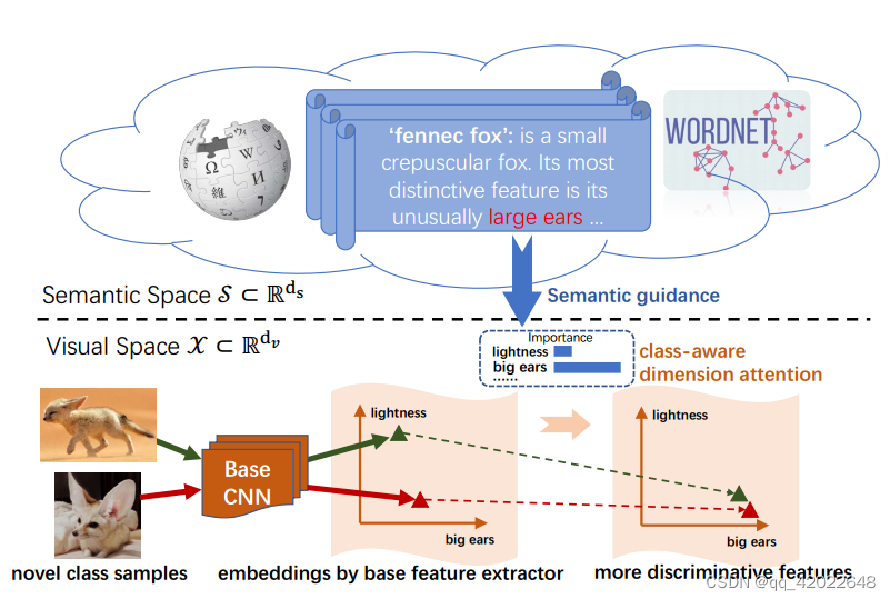
可视化测试:
对于新类别上的支持样本和查询样本,应用语义引导注意(SEGA)、不应用任何注意(No_Att)、应用语义注意的相反版本(Inv_Att)。假设模型没见过黑脚雪貂图片,如果忽略标签语义信息,容易将条纹背景作为该类别的关键特征,本文的方法(SEGA)可以根据语义知识判断出它是一只动物。

框架图:
根据视觉特征提取器获得每张图片对应的视觉特征向量,再计算对应的Visual Prototype,根据语义注意力生成器得到语义注意力,元素点乘得到每个类别对应的分类器权重,最后计算Query的特征向量,和分类器权重求余弦相似度作分类。
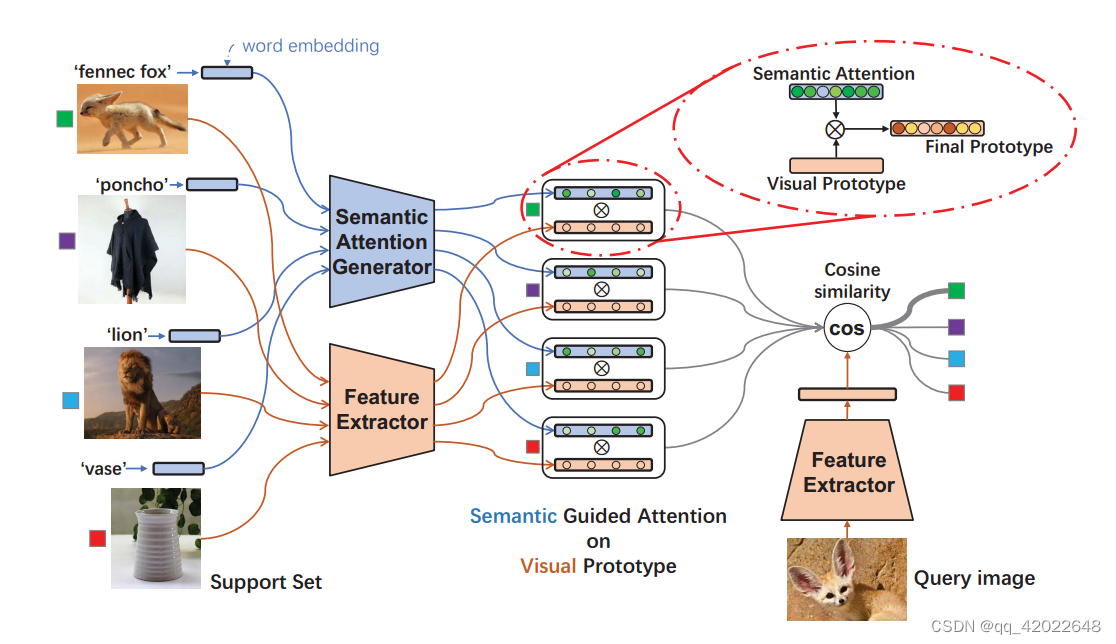
Visual Prototype:
普通的原型就是求特征向量的均值,但是作者认为这种过于直接,会忽略掉视觉先验信息(意思就是没用到基类中的权重),是一个可学习的权重矩阵,用来将新类别样本的视觉特征向量转换成query向量,
是基类中的向量,
表示求余弦相似度,如果query和第j个key向量相似度最高,则倾向于采用第j个基本类别对应的分类器权重,
和
是可学习的参数。
普通的原型:
增强的原型:
视觉原型:
Semantic Attention:
将语义信息通过MLP映射到视觉空间
中,MLP的最后一层为Sigmod函数,生成的
每一个分量都在(0,1)区间内(这里的语义信息选择类标签的词嵌入作为语义知识库S,
是c类别的词嵌入)
可以理解为语义信息在视觉空间中的选择因子,目的是根据语义信息选择出更重要的视觉特征(例如耳廓狐的大耳朵)即
(元素点乘得到分类器权重)















 1518
1518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









