







目录
3.1.1 taskflow应用介绍:词法分析子任务:中文分词和词性标注,它们用了同样的模型方案
3.1.2 taskflow应用介绍:词法分析子任务:命名实体识别
PaddleNLP飞桨自然语言处理开发库,提供一些文本领域的核心API可供调用;在此基础上有一些自研的预训练模型,覆盖全场景应用;在此基础上提供了产业级的预置任务taskflow
taskflow,旨在提供开箱即用的NLP预置任务能力,在中文场景上提供产业级效果和极致预测性能。目前的2.1版本开放了八个应用场景。
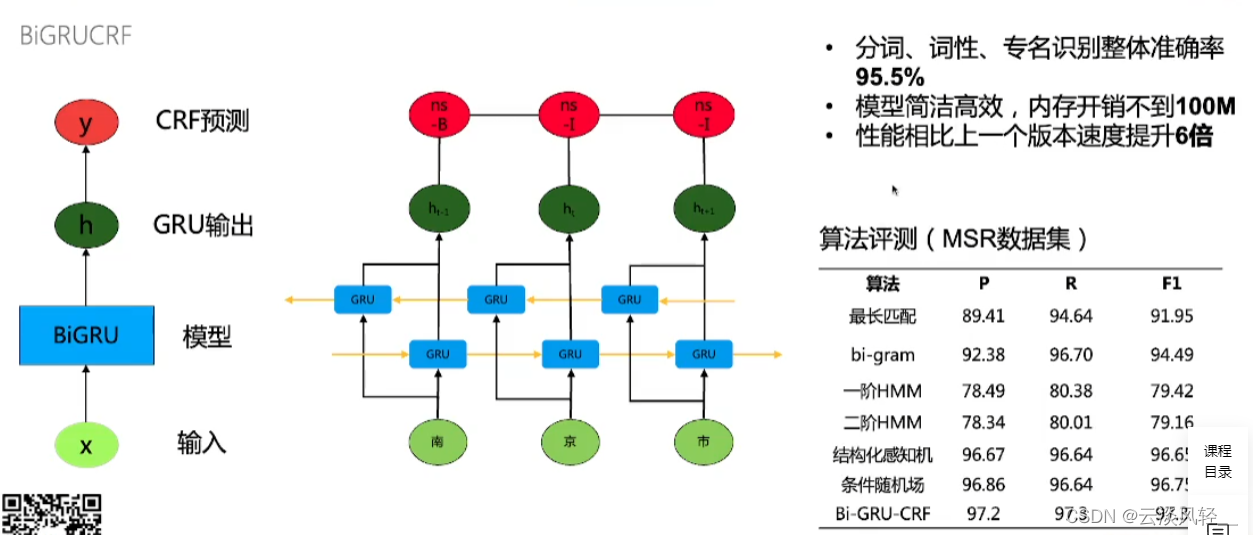
- 分词和词性标注,使用了同样的模型方案,模型简洁高效,速度提升了六倍,准确率95.5%
- 命名实体识别,针对传统NER的不足:粒度切分不一致、词兼类和只能识别部分实体等;taskflow引入了解语框架:分词粒度稳定,能识别完整实体边界,词性区分度更高
- 文本纠错,基于ERNIE-CSC模型,模型分为两层:检测模块和矫正模块;语料来源是千万级别的,模型效果sota;可用于搜索,也可以直接集成到OCR和ASR等产业应用中
- 句法分析,提供了两种模型方案,1 Deep biaffine attention模型 2 将1中的BiLSTM换位ERNIE encoder,让模型通过预训练模型获取更强大的中文语义能力,但随着准确率的提升,参数量级也增加了,可应用于离线场景
- 情感分析,随着电子商务和社交网络的兴起,带主观性的用户评价和评论,可分析人群的情感倾向。提供的模型方案是,使用百度在ACL2020上提出的基于情感知识增强的预训练模型SKEP,可通过无监督在海量语料中挖掘情感知识,再把情感搭配和情感词mask掉,作为预训练目标,让模型有情感倾向预测的能力。模型效果sota。自然语言理解应用:消费决策,舆情分析。自然语言生成应用:生成式问答,智能写诗
一、PaddleNLP
飞桨自然语言开发库:API可直接调用,丰富的模型库,产业级预置任务Taskflow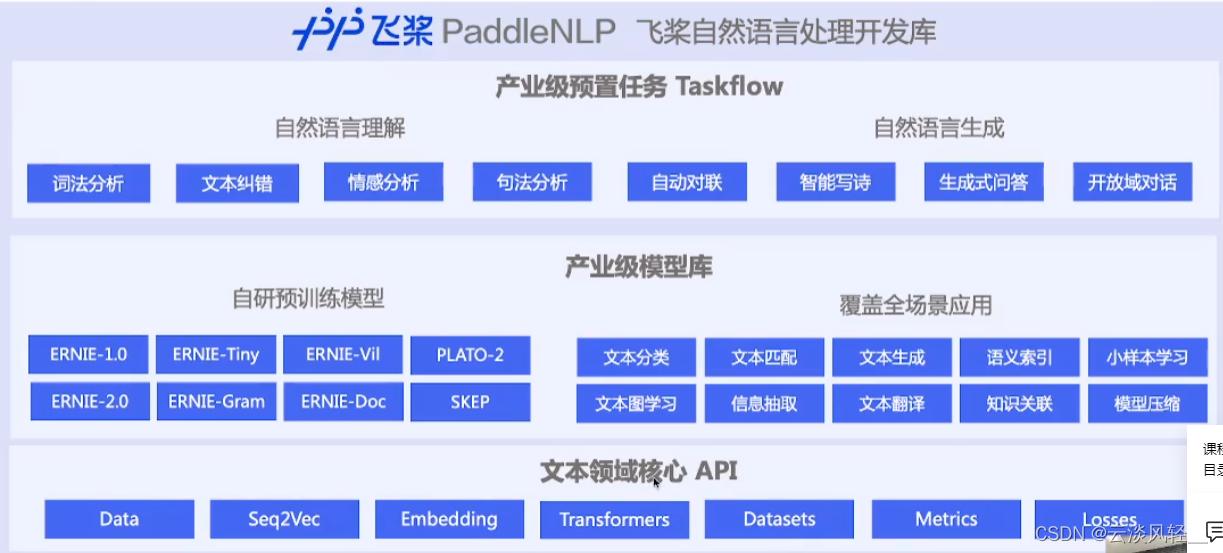
二、PaddleNLP Taskflow
2.1 目标和意义
taskflow旨在提供开箱即用(一行代码就可以调用)的NLP预置任务能力,在中文场景上提供产业级的效果与极致的预测性能。
2.2 taskflow架构
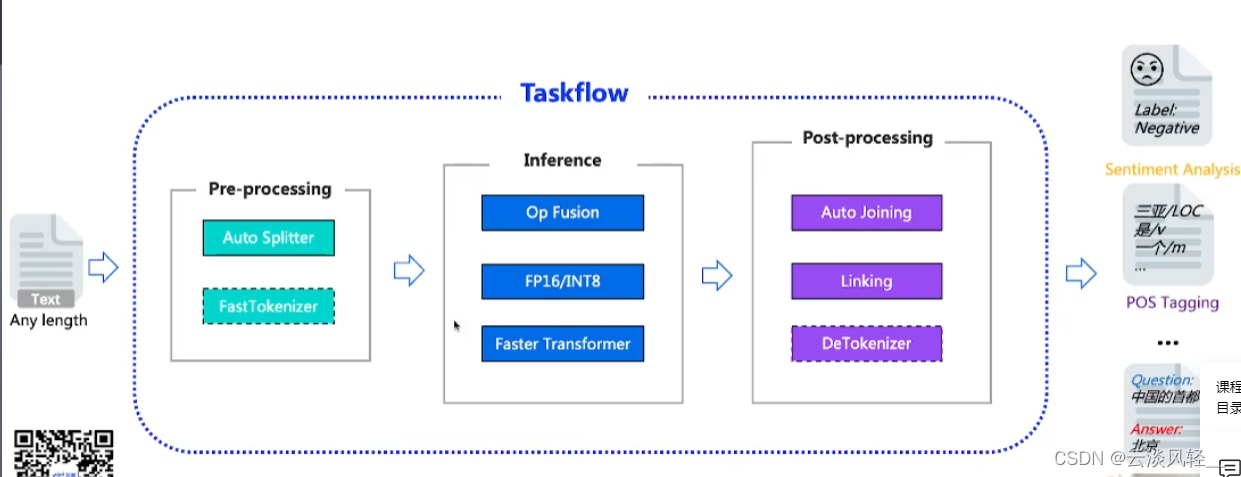
- 如图,taskflow架构由三部分组成,设计了一个auto splitter的模块来支持任意长度文本输入不用担心文本截断;fast tokenizer模块把原先在python层的文本处理的过程内置到了底层框架的计算流图中,实现了从数据到张量的过程的加速;
- 推理过程中,算子融合、精度转换来提升模型性能,并用了主流的加速模块faster transformer来显著提升翻译和文本对话的处理速度;
- 经过taskflow之后可用于具体任务
2.3 taskflow三大特点
- 中文:
- 针对中文语言特色
- ERNIE家族预训练模型
- 源于产业实践的网络结构
- 依托产业级海量数据:模型有海量数据来强化
- 全面:
- 自然语言理解
- 自然语言生成
- 内置了8+任务场景,用户可用一行代码来完成一键预测功能
- 快速:
- 动静统一的架构设计,目前的深度学习模型还是以动态图为主,因为开发起来比较方便,但是速度慢
- 原生推理引擎
- 算子融合:工程上的优化策略
三、taskflow应用介绍
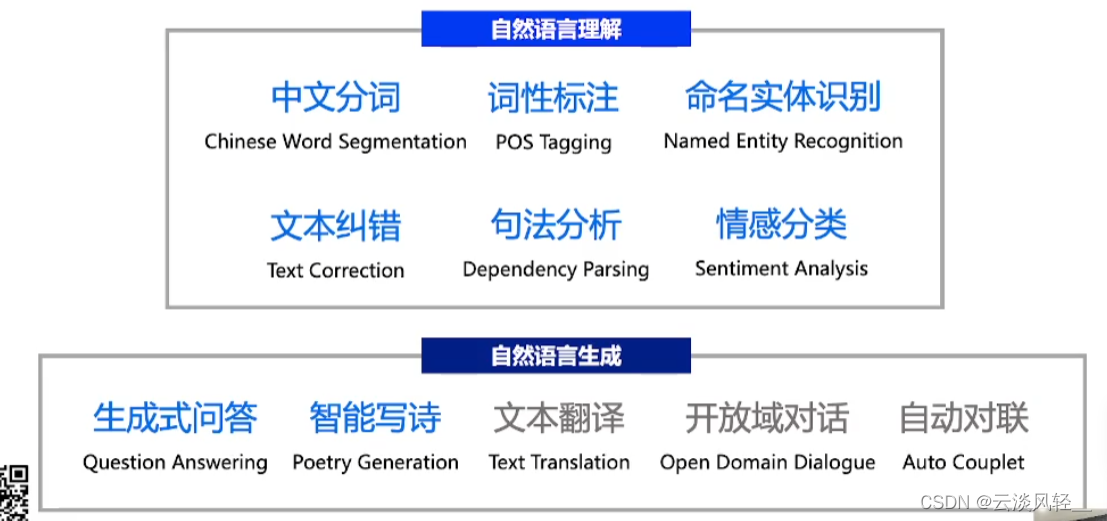
目前PaddleNLP2.1版本开放了八个应用场景
3.1 词法分析
- 任务定义:
- 就是利用计算机对自然语言的形态(morphology)进行分析,判断词的结构和类别等。
- 简单而言就是分词并对每个词进行分类,包括:分词、词性标注、命名实体识别三个任务
- 词是自然语言表意的基础单位:“张”可以是姓,也可以表“张开”的意思
- 词法分析是自然语言处理基础且重要的任务
- 是信息检索、信息抽取等应用的重要基础
- 可用于辅助其他自然语言任务,如句法分析、文本分类、问答对话等
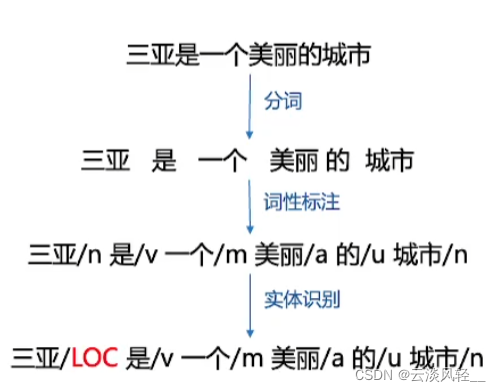
3.1.1 taskflow应用介绍:词法分析子任务:中文分词和词性标注,它们用了同样的模型方案
- 分词:
- 就是将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列
- 应用:搜索(先分词作为query,进行匹配(反向索引算法:先对网页标题做分词,再以关键词作为key,根据搜索的分词结果和网页标题的分词结果来反向索引文档))

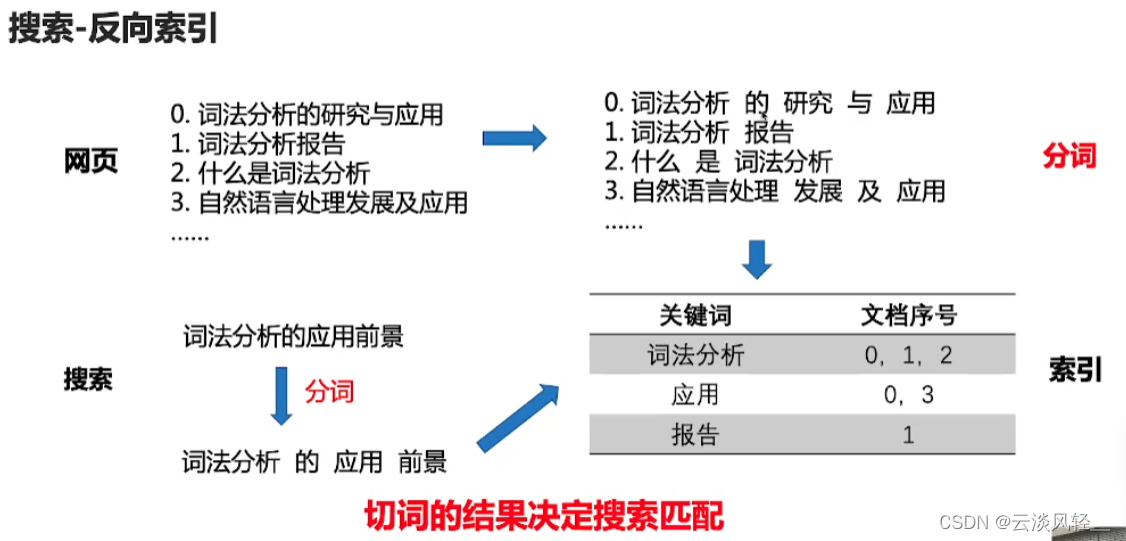
- 词性标注:为自然语言文本中的每个词赋予一个词性。
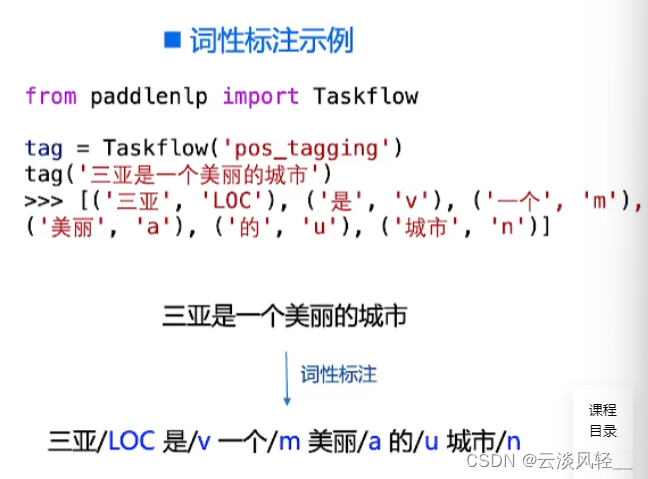
- 模型方案:
3.1.2 taskflow应用介绍:词法分析子任务:命名实体识别
- 任务定义:旨在识别自然语言文本中具有特定意义的实体(时间、地点、人物、机构、作品)

- 传统NER方案的不足
- 粒度切分不一致,基础粒度、混合粒度
- 词兼类现象严重,区分特征弱(n/nz/nt/nw/vn/an)
- 只识别部分实体类
公司名称和文件名称不应当被切分,出现这种问题的原因是,我们在训练分词模型时通常用基础粒度结合混合粒度的方法导致粒度切分不一致;词兼类现象:名词有普通名词、动名词等等;标签不够的原因只能识别部分实体类

- 针对上述问题提出了 传统NER工具的不足,PP在taskflow中引入了“解语:百科知识树”框架
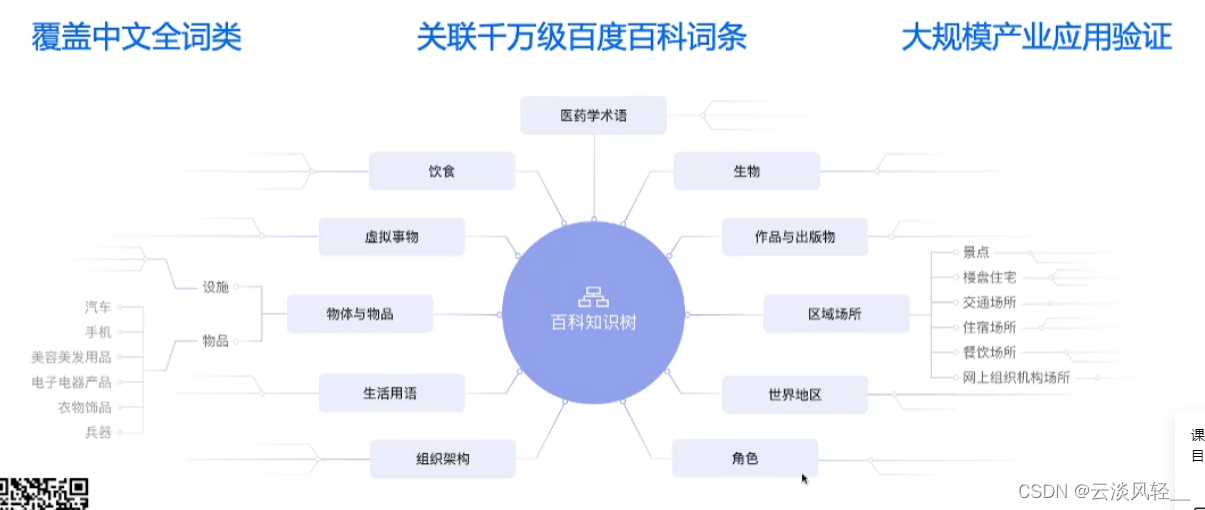
- taskflowNER,基于解语框架的命名实体识别
- 对比分词粒度稳定,能够识别完整实体边界
- 对比传统NER(20+类别标签)覆盖面广且词性区分度高,共66种标签类别

3.2 taskflow应用介绍:文本纠错
- 任务定义:是一项NLP基础任务,其输入是一个可能含有语法错误的中文句子,其输出是一个正确的中文句子


3.2.1 文本纠错的模型方案

- 基于ERNIE-CSC模型
- 模型结构分为两层:检测模块,判断文本中的字是否是错别字;矫正模块,对判定出错误的词进行纠正。
- 纠错模型的语料来源是来自百度线上挖掘的千万级文本
- 模型效果是sota的
3.2.2 文本纠错的应用场景
- 搜索:用户在搜索时输入了错别字,经过文本纠错来匹配到更精确的结果
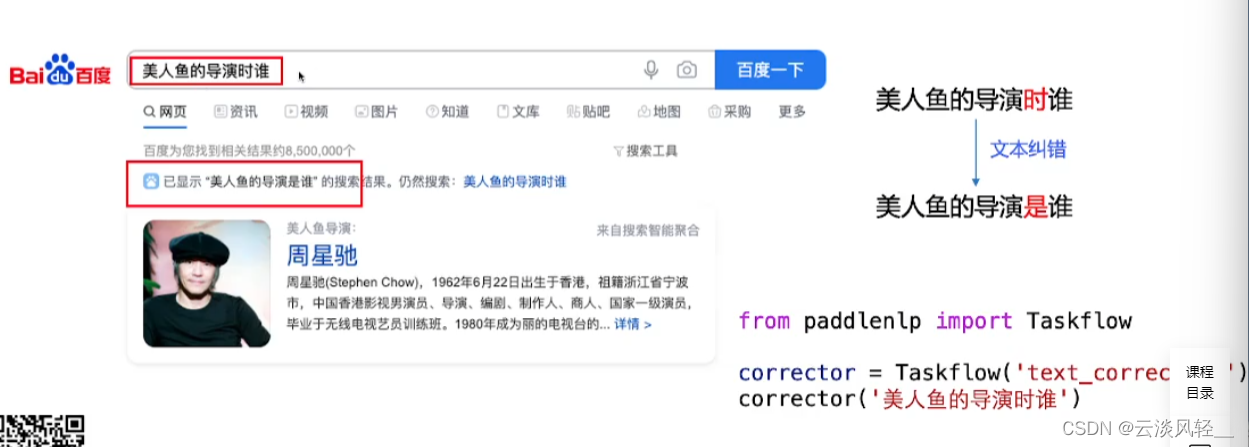
- 可直接集成到OCR、ASR等产业应用中,手写文字识别中因为手写的不规范或者图片模糊导致识别错误需要纠错;语音识别中的口音和语调导致的识别错误需要纠错

3.3 taskflow应用介绍:句法分析
- 任务定义:目的是确定句子的语法结构或句子中词汇之间的依存关系。通过句法关联建立起词与此之间的从属关系,这种从属关系由支配词和从属词联结而成。

- 句法分析模型的好坏,数据集的质量非常重要。这里依据的是百度自建的数据库:DuCTB1.0,中文依存句法数据库,包含近100万句子。语料来自搜索query、网页句子,覆盖了手写、语音等多种输入形式,同时覆盖了新闻论坛等多种场景。包含14种标注依存关系。
3.3.1 句法分析:模型方案
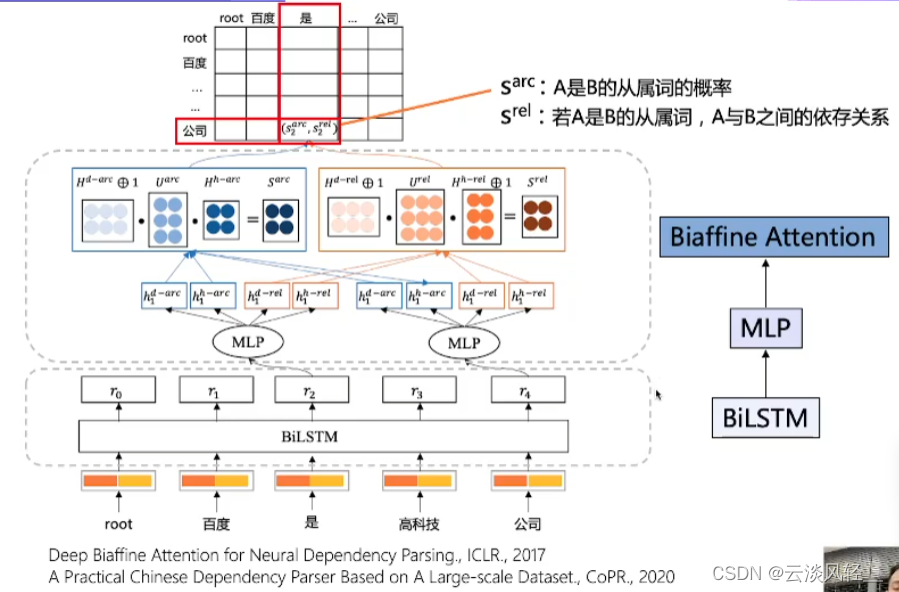
- 如上图,句法分析用的是非常经典的deep biaffine attention模型
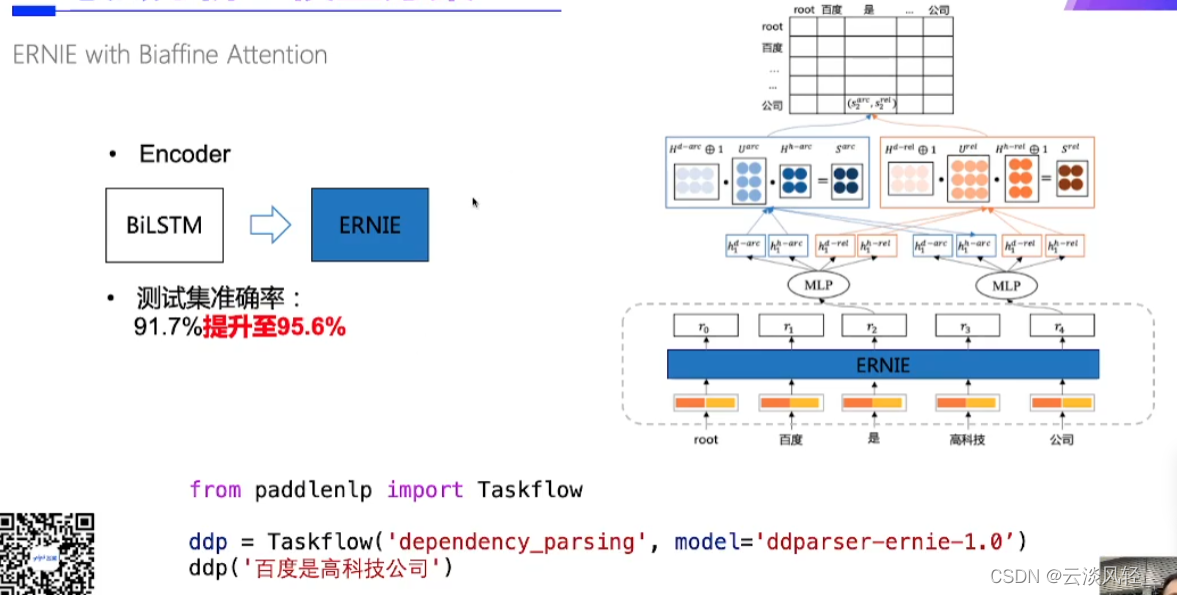
- 如上图,预训练模型的出现为NLP定义了新范式,我们在句法分析模块也做了全新版本,就是把BiLSTM换成了ERNIE encoder,让模型获取更强大的中文语义能力。通过这一升级,模型的准确率也提升了。参数量级增加了,准确率增加了,离线场景,实时性要求不高的场景可以用这个ddparsor-enrnie-1.0模型
3.3.2 句法分析:应用场景
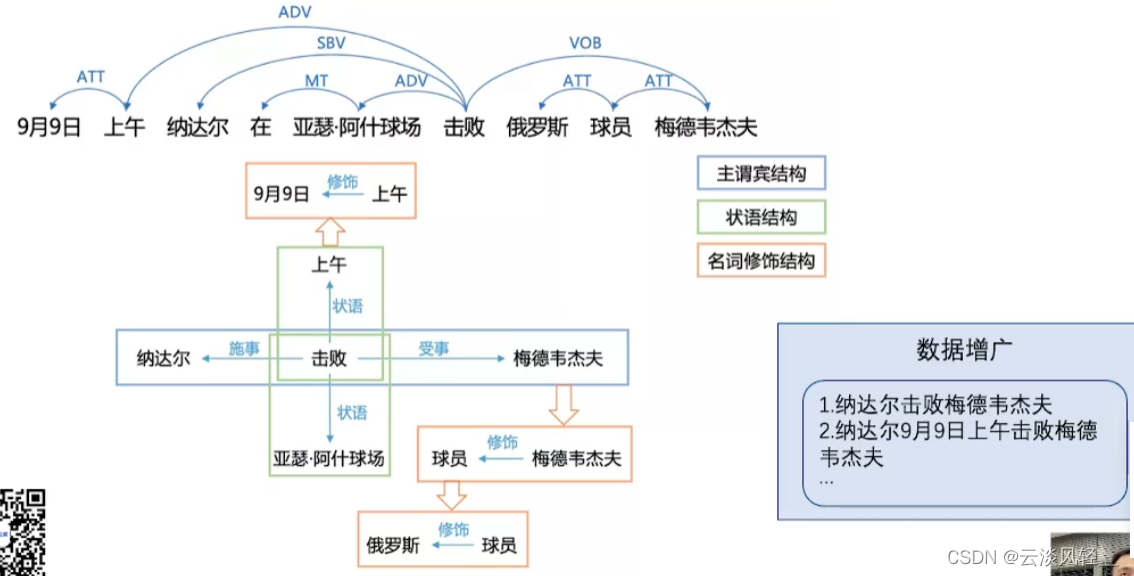
- 如上图,通过句法分析抽取一系列结构,抽取的主干结构让句子变得精炼。加上一些词语,保持语义不变,可以做到语义增广。
3.4 taskflow应用介绍:情感分析
- 随着电子商务的兴起,情感分析逐渐成为一个热门的研究领域
- 技术背景: 如下图,文本可以分为客观性文本和主观性文本,随着电子商务和社交网络的兴起,用户的评价和评论带着主观性,也可以帮助软件进行迭代更新
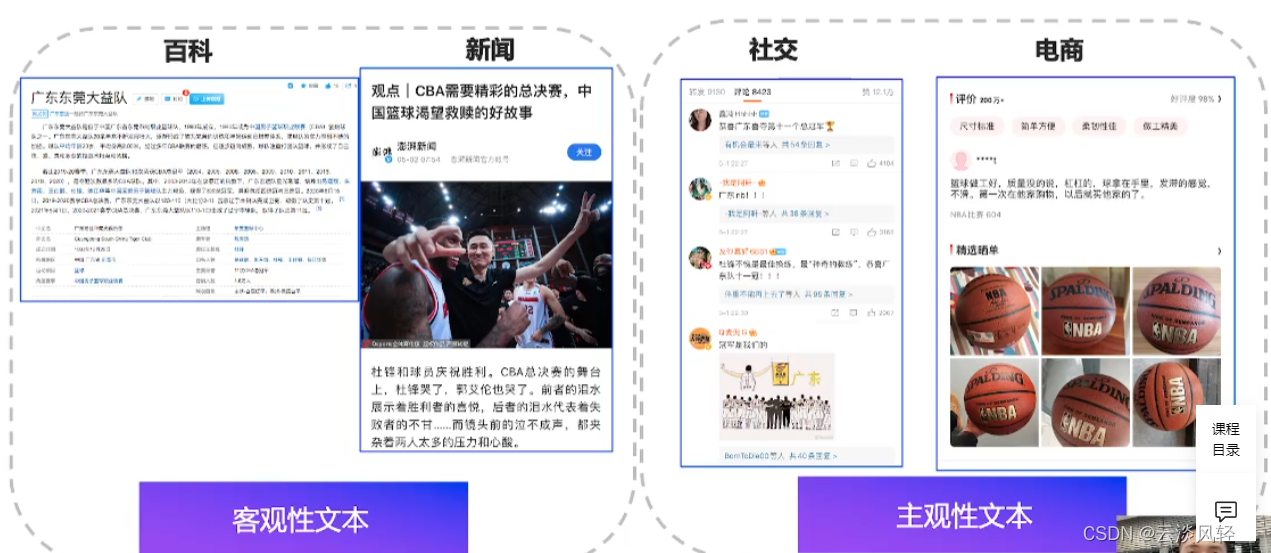
- 任务定义 :情感分析又称意见挖掘,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程,具体来说,对于给定的主观文本,输出如下五元组:


3.4.1 情感分析:模型方案
- 无监督方法挖掘情感知识
- 情感知识屏蔽的预训练模型
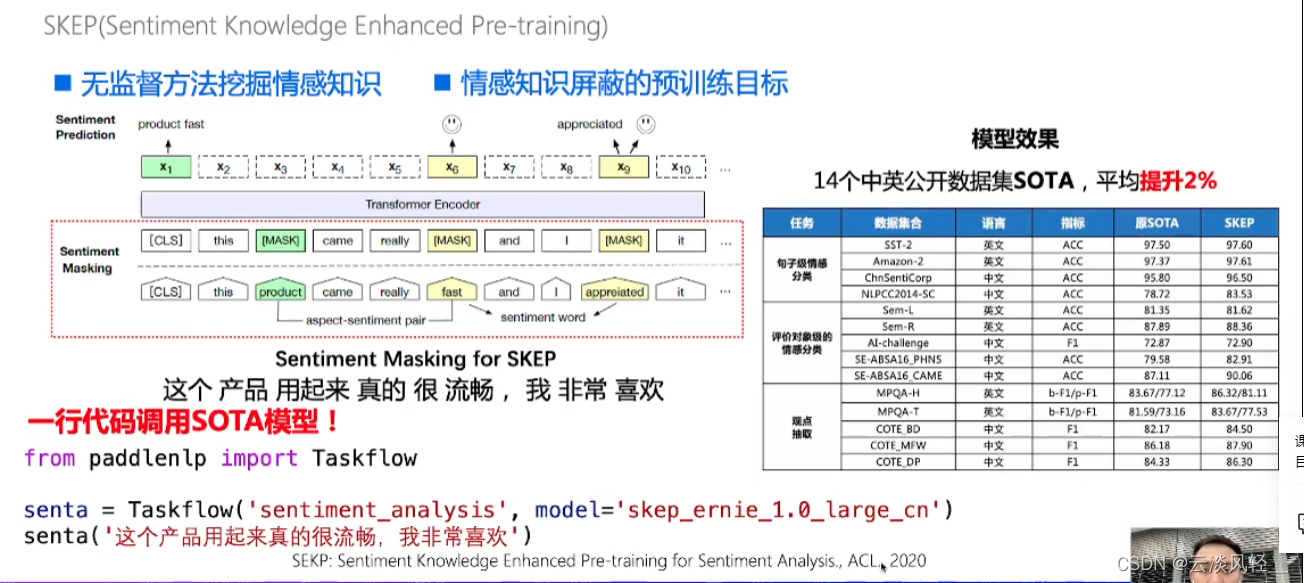
- 如上图, 用到的是SKEP模型,是百度在ACL2020上提出的基于情感知识增强的预训练模型,可以通过无监督的方式在海量语料中挖掘出情感知识“喜欢”,把情感搭配和情感词mask掉,作为预训练目标,让模型有情感倾向预测的能力。
- 模型效果:在14个中英公开数据集上都sota
3.4.2 情感分析:应用场景
自然语言理解应用
- 消费决策:通过评价内容得到商品的好评度,好评标签“好用”“舒适”
- 舆情分析:通过用户的评论,可以得到大概的舆论导向
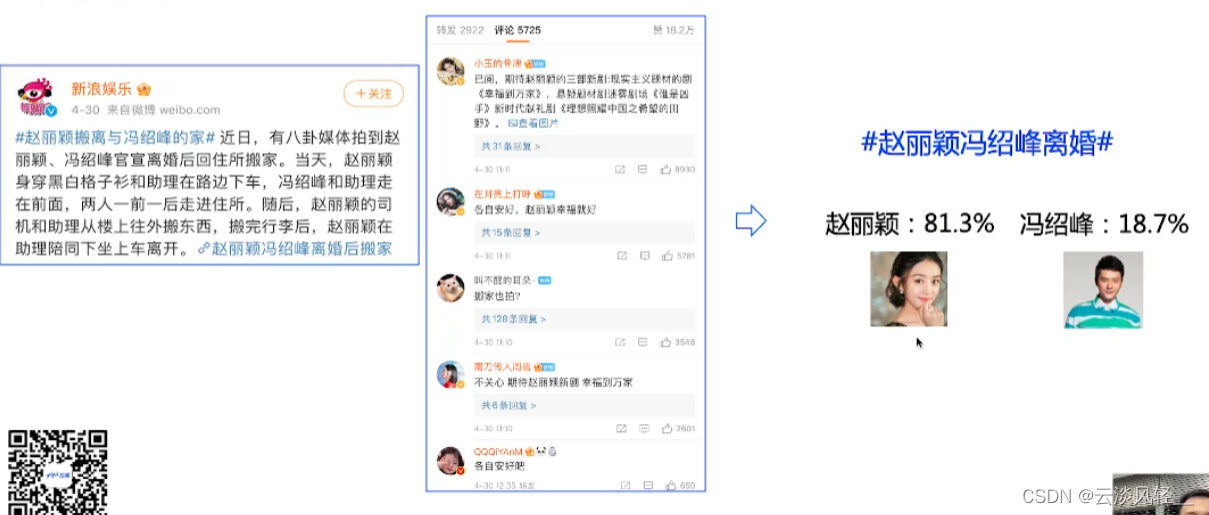
自然语言生成应用
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









