







大家好,我们今天就接着上次多模态串讲,来说一说最近使用 transformer encoder 和 decoder 的一些方法。
1 BLIP:一个很有效的、根据图片生成caption的工具
我们要过的第一篇论文叫做blip,题目中有两个关键词,一个就是 Boost drapping,另一个就是unified,也就是他们这篇文章的两个贡献点。
第一个 Boost drapping 其实是从数据集角度出发的,他是说如果你有一个从网页上爬下来的很嘈杂的数据集,这时候你先用它去训练一个模型,接下来你再通过一些方法去得到一些更干净的数据,然后再用这些更干净的数据能不能train出更好的模型。
那第二个贡献点 unified 其实就从Vision-Language Understanding and Generation来看就非常明了,也就是从模型角度出发,这两个方向,一个是understanding,也就是 image text retrieval、VQA、VR、VE 这些我们上次讲过的任务,还有就是 generation 这种生成式任务,比如说 image captioning,就是图像生成字幕这种任务
作者团队全部来自于 Salesforce research。是我们上次讲过 ALBEF 那篇论文的原班人吗?我们一会儿也可以看到 BLIP 这篇论文,它的模型也有很多 ALBEF 的影子,而且它里面也用了很多 ALBEF 的训练技巧。
1.1 引言
研究动机
那接下来我们直接进入引言部分,看看这篇文章的研究动机到底是什么。 BLIP的引言写得非常清晰,他上来就告诉你,我的研究动机有两个部分,一个是从这个模型角度出发,一个是从数据角度出发。
1、从模型上
- 作者说最近的一些方法,它要就是用了 transformer encoder 的一些模型,这里举的这个clip,还有他们自己的 ALBEF。
- 另外一条路就是用了这种编码器解码器 encoder decoder 的结构,比如说后面这个就是 Sim VLM。
虽然说方法都有,但是作者这里说这种 encoder only 的模型,它没法很直接的运用到这种 text generation 的任务里去,比如说图像生成字幕,因为它只有编码器,没有解码器,那它用什么去生成?当然也不是完全不行,但就说不够直接,肯定你要杂七杂八的再加一些模块儿,才能让他去做这种 text generation 的任务。
那对于 encoder decoder 模型来说,它虽然有了decoder,它虽然可以去做这种生成的任务,但是反过来因为没有一个统一的框架,所以说它又不能直接的被用来做这种 image text retrieval 的任务。
那我们读到这儿,其实发现作者这里这个研究动机跟我们上次讲的那个 VLMO 是完全一样,都是说现有的框架 a 可以干什么?不能干什么, b 可以干什么?不能干什么,但是这两条方向都不能一个人把所有的活都干了,所以如何能提出一个unified,一个统一的框架,用一个模型把所有的任务都解决那该多好?那接下来我们很快就可以看到,其实 BLIP 这篇论文就是利用了很多 VLMO里的想法,把它的模型设计成了一个很灵活的框架,从而构造了这么一个 unified framework。
2、从数据上
那另外一个研究动机就是说数据层面,作者说目前就是表现出色的这些方法,比如说 clip ALBEF 和 SIM l m,他们都是在大规模的这种网上爬下来的非常 noisy 的数据集上,也就是这种 image text pair 上去预训练模型的。虽然说当你有足够多、足够大的数据集的时候,它能够弥补一些这些嘈杂数据集带来的影响,也就是说你通过这个把这个数据集变大,你还是能够得到非常好的这个性能的提升的。但是 BLIP 这篇论文就告诉你,使用这种 Noisy 的数据集去预训练还是不好的,它是一个 suboptimal,不是最优解。那如何能够有效地去 clean 这个 Noisy 的 data set 如何能够让模型更好地去利用数据集里的这个图像文本配对信息?在 blip 这篇论文里,作者就提出来了这个 captioner 和 filter 这么一个module。
- captioner 的作用就是说我给定任意一张图片,我就用这个 captioner 去生成一些这个字幕,这样我就会得到大量的这个合成数据 synthetic data。
- 然后同时我再去训练这么一个 filtering model,它的作用就是把那些图像和文本不匹配的对儿都从这个数据集里删掉。比如说在这个例子里,这就是一个巧克力蛋糕。那原来从网上直接爬下的这个图像文本堆儿里的文本写的是 blue sky Bakery in Sunset park,就是说一家位于这个日落公园叫蓝天的蛋糕店,那我们可以很明显的看出来这个图文其实是完全不匹配的。那我们上次也提过,之所以它这个文本是这样,其实是因为有利于这个搜索引擎去搜索,因为大家看到这个蛋糕的图片之后,更想做的是去知道这家蛋糕店在哪,我怎么能去买到这家蛋糕店,这样搜索引擎才能收广告挣钱,这个蛋糕店的店主也能得到更多的客流量。所以大部分你爬下来的那些数据集,不论你爬了几百万、几千万、上亿的主图片文本,对儿里面大部分都是这种不匹配的 Noisy 的文本对儿,
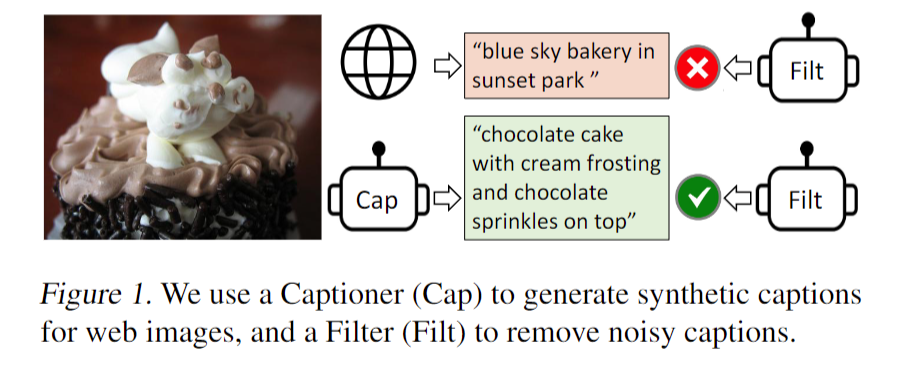
在我们这个时候可以看到作者训练的这个 captain 这个模型,它其实可以生成非常好、非常有描述性的这个文本,那所以在接下来他们训练的这个 filtering 模型来看,他们就会选择这个图像文本对儿去进行模型的训练,而不用原来的那个真实的图形文本对儿去进行训练。
1.2 贡献一:模型结构
那快速过完了引言中的研究动机。接下来我们废话不多说,直接来看文章的图2,看一下 BLIP 整体的这个模型结构。那在看图 2 之前,我想再回顾一下上一期讲的两个方法,因为之前我们说过 ALBEF 的提出就是在 ViLT 和 clip 一系列工作之前的这个经验总结上得到,那我们今天要讲的这个 BLIP 是不是也能用之前的经验总结而得到?那答案是肯定的。
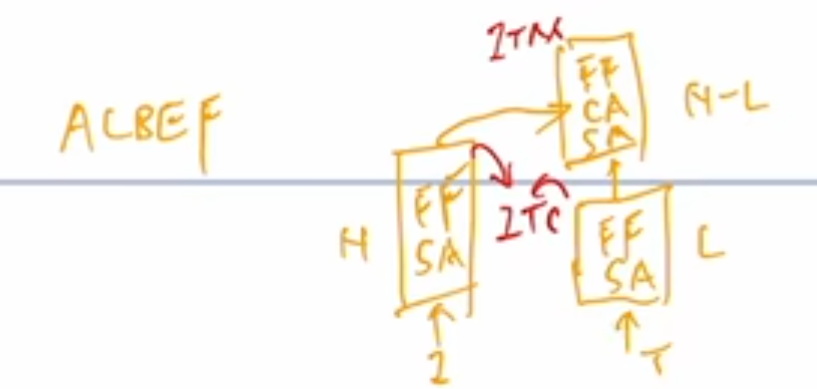
我们首先来看 ALBEF, ALBEF 的模型分成 3 个结构,一个是这个视觉编码器,一个是文本编码器,那还有一个是多模态编码器,对于图像这端来说,就是一个图像进入这个 transformer encoder,它一共有 n 层,然后一个文本进入这个文本的编码器,它有 l 层。然后在得到对应的这个图像文本特征之后,他先做一个 ITC image text contrasted 这个对比学习的loss,去把图像和文本分别的这个特征学好,然后文本特征继续进入这个 self attention layer 去学,然后图像特征通过一个 cross attention layer 进来,然后和文本特征去进行融合,然后经历了 n 减 l 层的这个多模态的编码器之后,最后得到了多模态的那个特征,然后最后用这个多模态的特征去做 image text matching 这个任务,从而去训练更好的模型。
为什么文本这端要把一个 n 层的 transformer encoder 硬生生的 p 成 l 层和 n 减 l 层?至于作者还想大概维持这个计算量不变,就是跟 CLIP 一样,左边一个 12 层的 transformer encoder,右边也是一个 12 层的 transformer encoder,他不想增加更多过量的这个多模态融合这部分的计算量,但是多模态这一部分又特别的重要,然后相对而言文本这端不那么重要,所以他就把这边 12 层的计算量给分成了两部分。
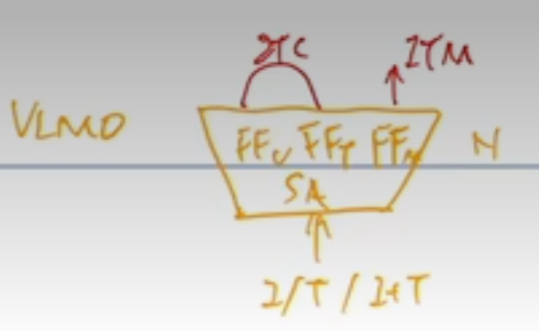
但是同样的问题, VLMO 是怎么解决的? VLMO 觉得你这样 p 来 p 去也太麻烦了,而且也不够灵活。那我们现在来设计一个这个 mixard of expert MOE 这种网络,让它变得极其的灵活,就是说我只有一个网络,我的这个 self attention 层全都是共享参数的,我唯一根据模态不同而改变的地方就是这个 feed forward network,我有我的这个 feed forward 的vision、 feed forward text 和 feed forward 的 Multi model,我用这个地方去区别不同的 modelity 去训练不同的expert。这样我就用统一的一个模型,就是在训练的时候是一个模型,但是我在做推理的时候,我可以根据不同的这个任务去选择这个模型中的某一部分去做推理。而且 VLMO 这篇论文用实验大量的实验证明了这个 self attention 层确实是可以共享参数的,它跟这个模态没什么关系。
那大家一旦收到这个信号之后,肯定还是觉得 VLMO这个结构更简单,至少直观上看起来更简单更优雅。所以说结合了 ALBEF 和 VLMO,作者就推出了 BLIP 这个模型。我们先大体从粗略上来看一下 BLIP 这个模型包含了四个部分
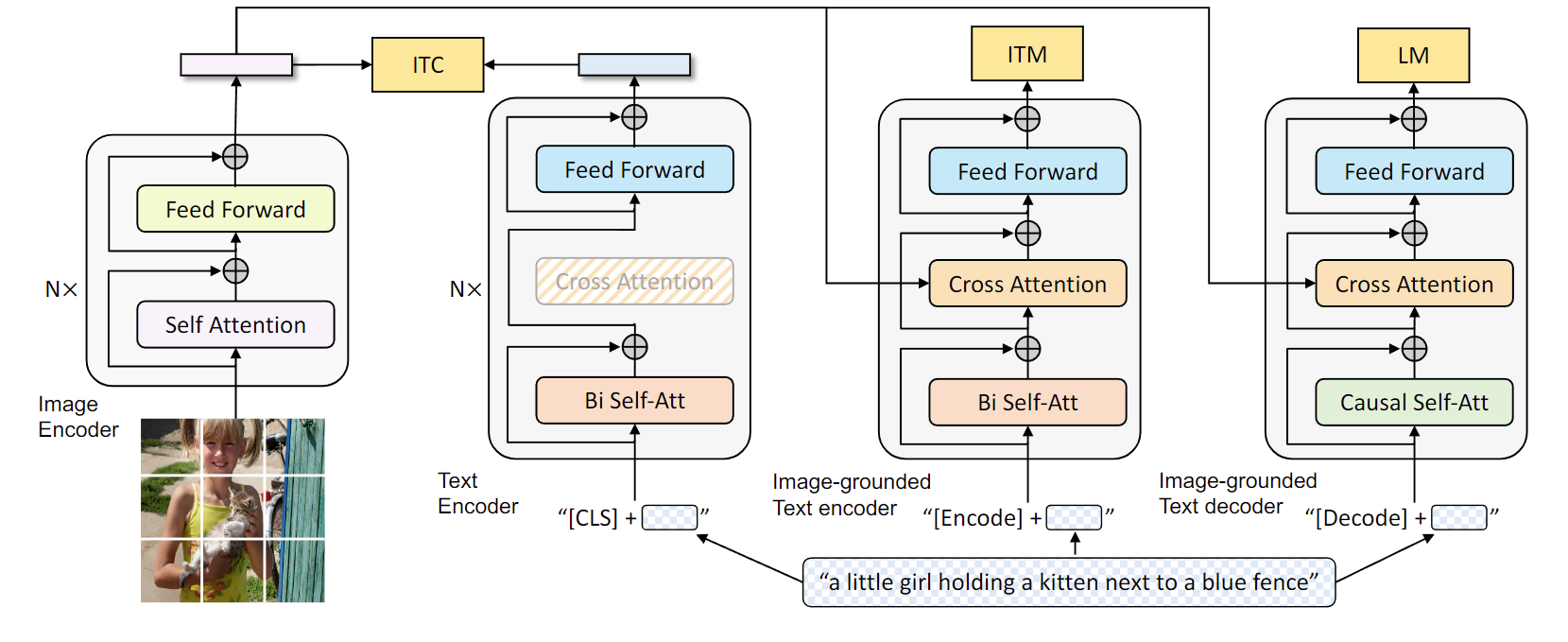
- 一个就是图像这边,它有一个完整的 VIT 的模型,一个 n 层的 VIT 模型,而且是非常标准的 self attention 和 feed forward。
- 然后文本这边它有三个模型,分别用来算三个不同的这个目标函数。这个就跟 VLMO 已经非常像了,它根据你这个输入模态的不同,它根据你这个目标函数的不同,它去选择一个大模型里不同的部分去做这个模型的forward。
- 那对于第一个文本模型来说,这里面它也是 n 层,而不像 ALBEF 里的 l 层了。它的目的是根据你输入的文本去做这么一个 understanding 去做这么一个分类的任务。所以说当得到了这个文本特征之后,他就去跟这个视觉特征去做 ITC loss。
- 那第二个文本模型作者这里说它叫 image grounded taxing coder,就是它是一个多模态的编码器了,它这里是借助了图像的信息,然后去完成一些多模态的任务。很显然那这个就是我们之前要做这个 ITM loss,那这个时候其实我们发现如果你把这个部分直接放到这个上面,其实它不就是 ALBEF 吗?先有一个 n 层的VIT,然后这边有一个 n 层或者 l 层的这个文本端,然后在上面又加了一个这个多模态的端,这个视觉的特征通过这个 cross attention layer 进来,文本端的特征通过这个 self attention layer 进来,然后最后得到一些多模态的特征,然后去算这个 ITML loss。所以如果暂时我们先不看第三个这个文本编码器,其实左边这一部分完完全全就是一个 ALBEF,但是它跟 ALBEF 有一点不同,这是它借鉴了VLMO里,这个 self attention 层是可以共享参数的,所以它就不需要把一个文本模型劈成两个部分去用了,它可以就用一个文本模型,但是共享参数。所以这里我们也可以看到作者说同样的颜色代表同样的参数,就是共享参数的,它不是两个模型。那这里我们可以看到这个 SA 层也是共享参数的,所以相当于第一个文本编码器和第二个文本编码器,它基本就是一样了,它的这个 SA 和 FF 全都是一致的,只不过第二个里头多了一个 cross attention 层,需要新去学习。那所以讲到这儿也就回答了我们刚才的问题,我们确实可以通过看之前的方法总结他们的经验,从而得到接下来的方法的这个大体的模型结构和创新点,
- 但是到这儿我们会发现目前的这个结构,它还是只能做这种 v q A VR VE 这种 understanding 的任务。那怎么去做生成的任务?这个 decoder 在哪?那有了 VLMO 这个想法之后,那一切就变得很简单了,对吧?如果你需要一个decoder,那你就再加一个decoder 不就完了吗?所以你就在后面再加这么一个文本的decoder。但是对于 decoder 来说,它的这个输入输出的形式和尤其是第一层的这个 self attention 是不太一样了,因为这个时候他不能看到完整的这个句子,因为如果他已经看到完整的句子,他再去生成这个句子,那他肯定能 100% 生成出来这个句子,那就训练就没有难度了,那它必须像训练 GPT 模型一样,它把后面的这些句子都挡住都 mask 掉。它只通过前面的这些信息去推测后面的句子到底长什么样,这才叫 text generation。所以说它的第一层用的是 causal 的 self attention,也就是因果关系的这个自注意力</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1608
1608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









