







目录
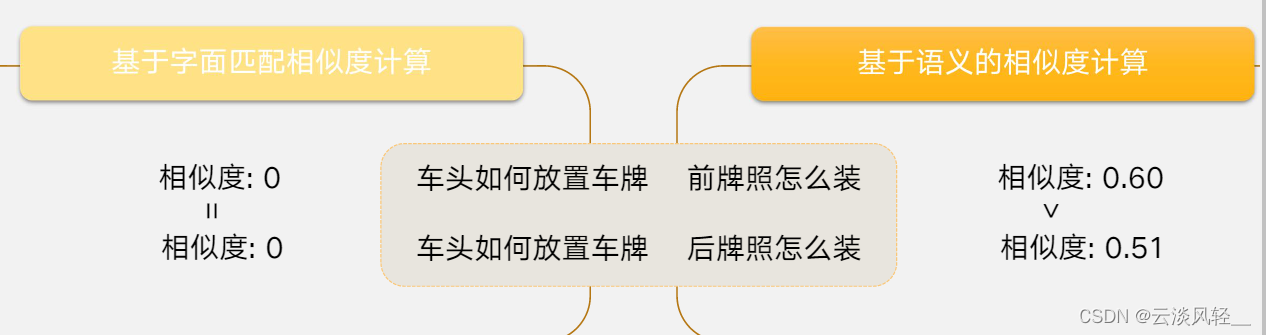
- 语义检索系统:不同于基于字面匹配检索,在语义层面的检索泛化效果更好。
- 语义检索系统方案的一些问题:用什么架构?各模块用什么模型?模型如何调优?有多少训练数据?训练数据的形式?语义检索效果如何自动化评估?等
- PaddleNLP语义检索系统给出的回答:架构:recall+ranking,模型:ERNIE-Gram,千万级无监督语料
1 搜索核心技术发展
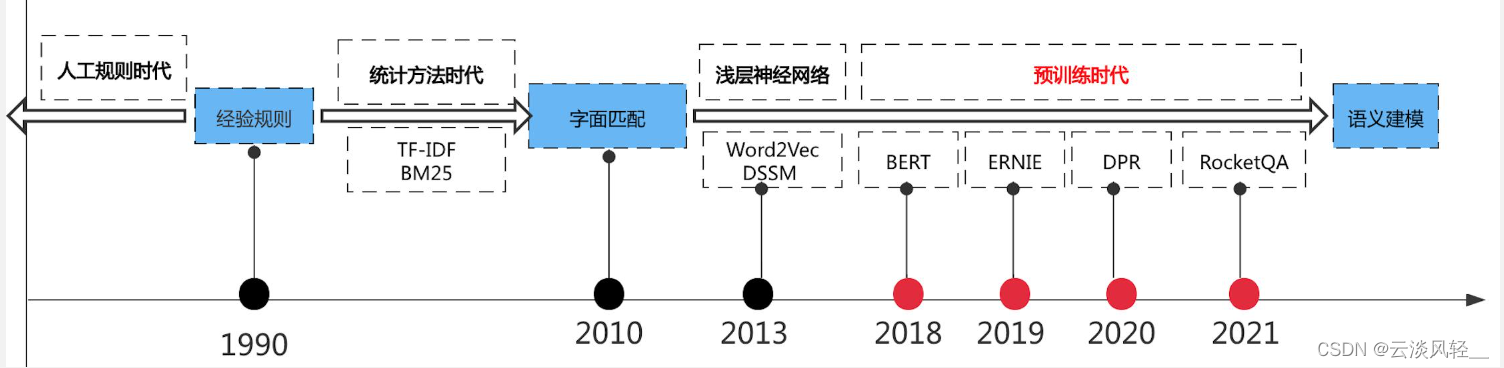
- 基于规则的时代:需要人工写先验规则,效果一般
- 统计方法时代:基于字面匹配的方法
- 神经网络方法
- 预训练时代:预训练模型->端到端系统
1.1 基于字面匹配的检索流程
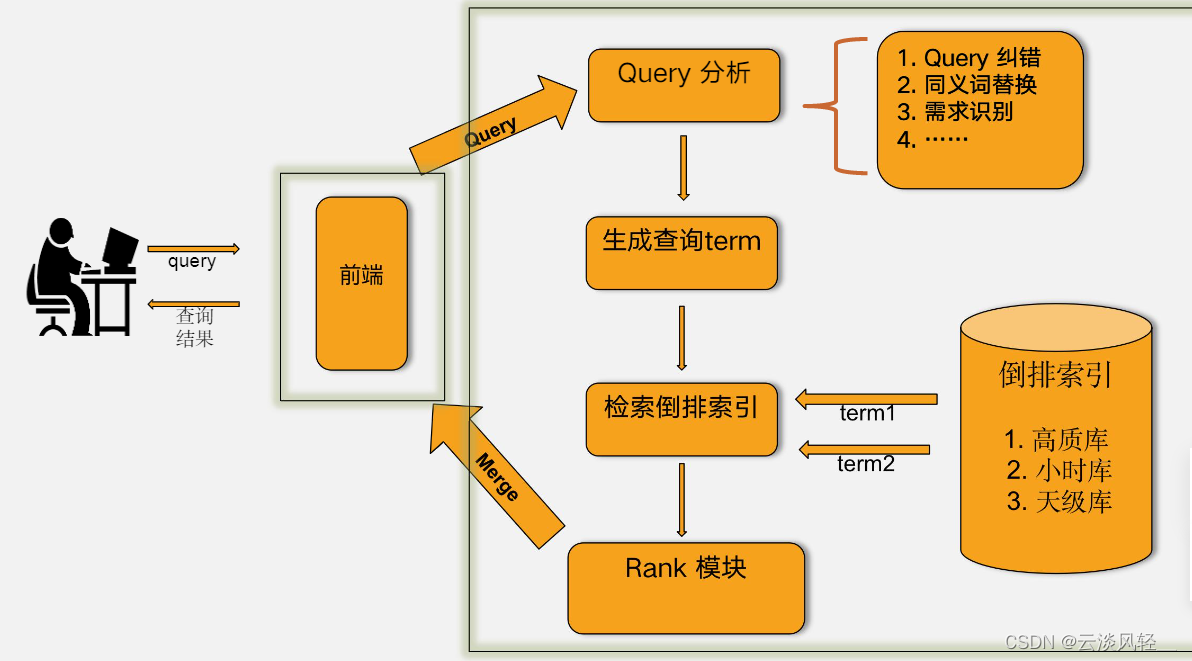
传统基于字面匹配的检索的痛点:
- 语义鸿沟:无法解决语义问题。
- 没有标注数据
- 不清楚语义检索系统方案

2 PaddleNLP语义检索系统
回答以上痛点问题
2.1 语义检索系统架构:recall+ranking
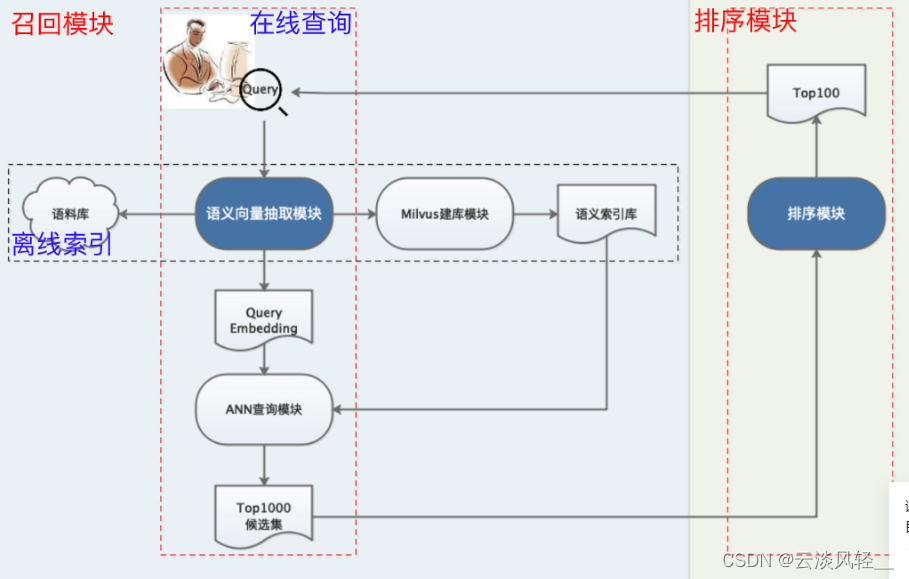

2.2 PaddleNLP语义检索系统的特色
- 简单易用:案例详细、一站式支持训练预测ann引擎和部署
- 没有标注数据也能做语义检索:(痛点2)
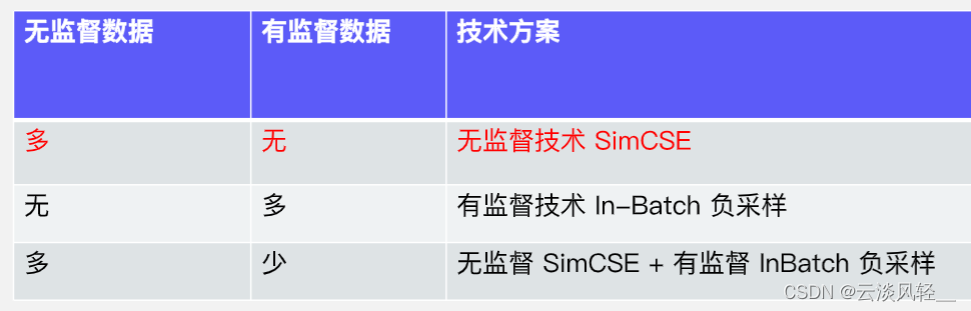
- 高性能
2.3 PaddleNLP语义检索系统的召回阶段的核心技术
2.3.1 无监督对比学习SimCSE

监督信号=语义相似的关系
如何构造监督信号:一句话多次进行随机编码,语义是相似的。此时的训练目标就是,让构造出来的向量与原来的接近,与其他的远离 
2.3.2 有监督in-batch负采样

负例对的来源:与不相关的样例的搭配
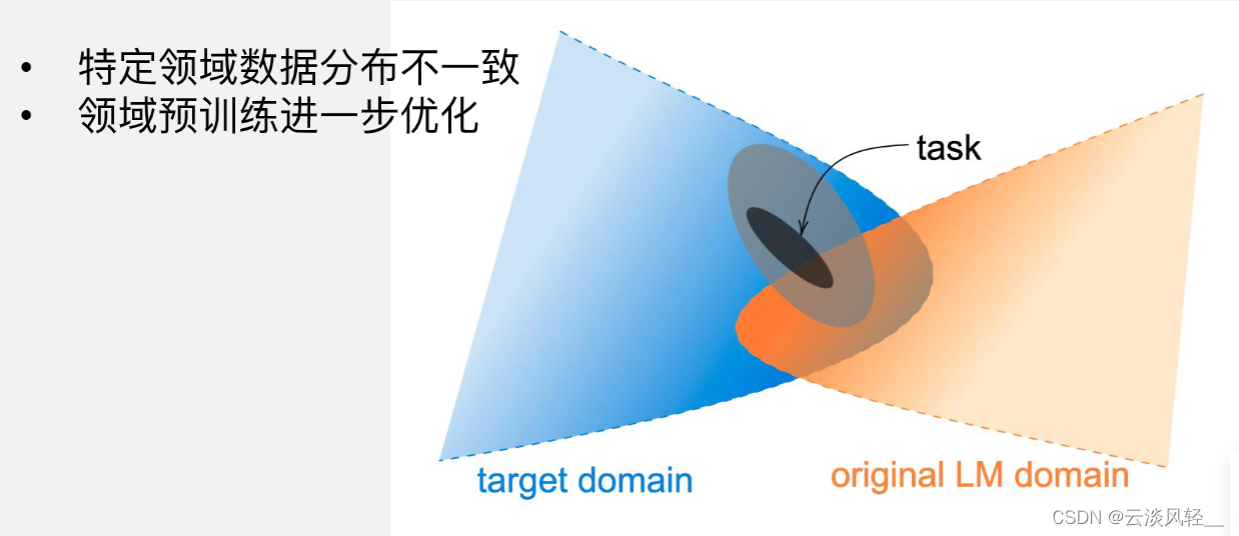
2.3.3 领域预训练优化
2.4 PaddleNLP语义检索系统的排序阶段的核心技术
2.4.1 排序技术
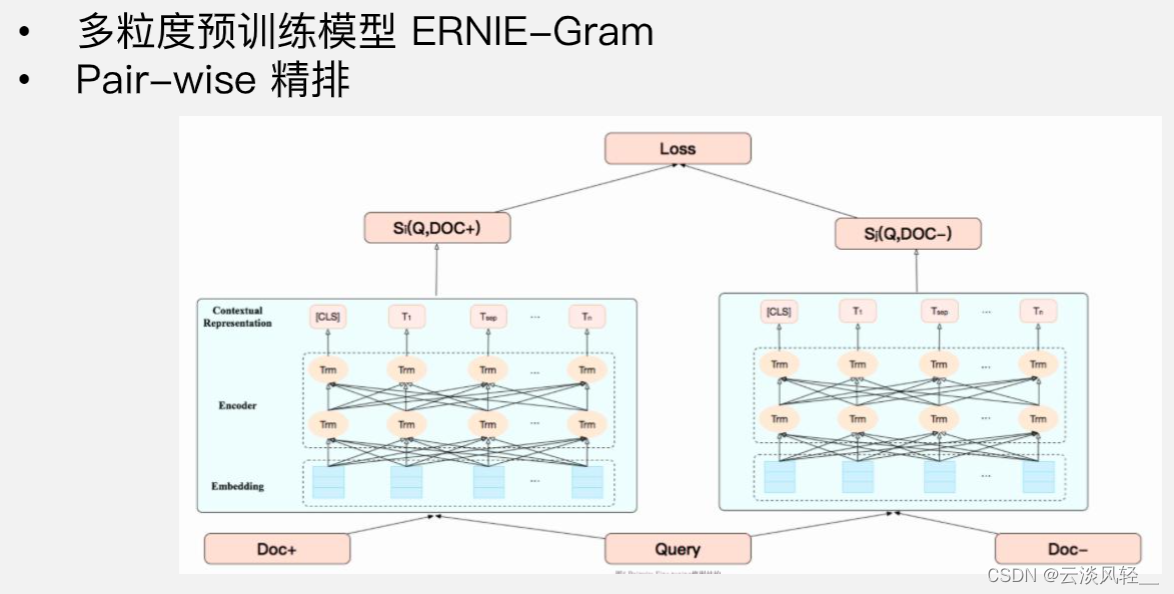
ERNIE-gram做热启动,把正样本和query拼起来求相似度,负样本和query拼起来求相似度,最后的loss优化就是让正样本的相似度尽可能大,负样本的尽可能小
3 语义检索应用案例
根据用户看过的视频来推荐相关视频,全部短视频title生成语义向量,接下来就可以做召回了
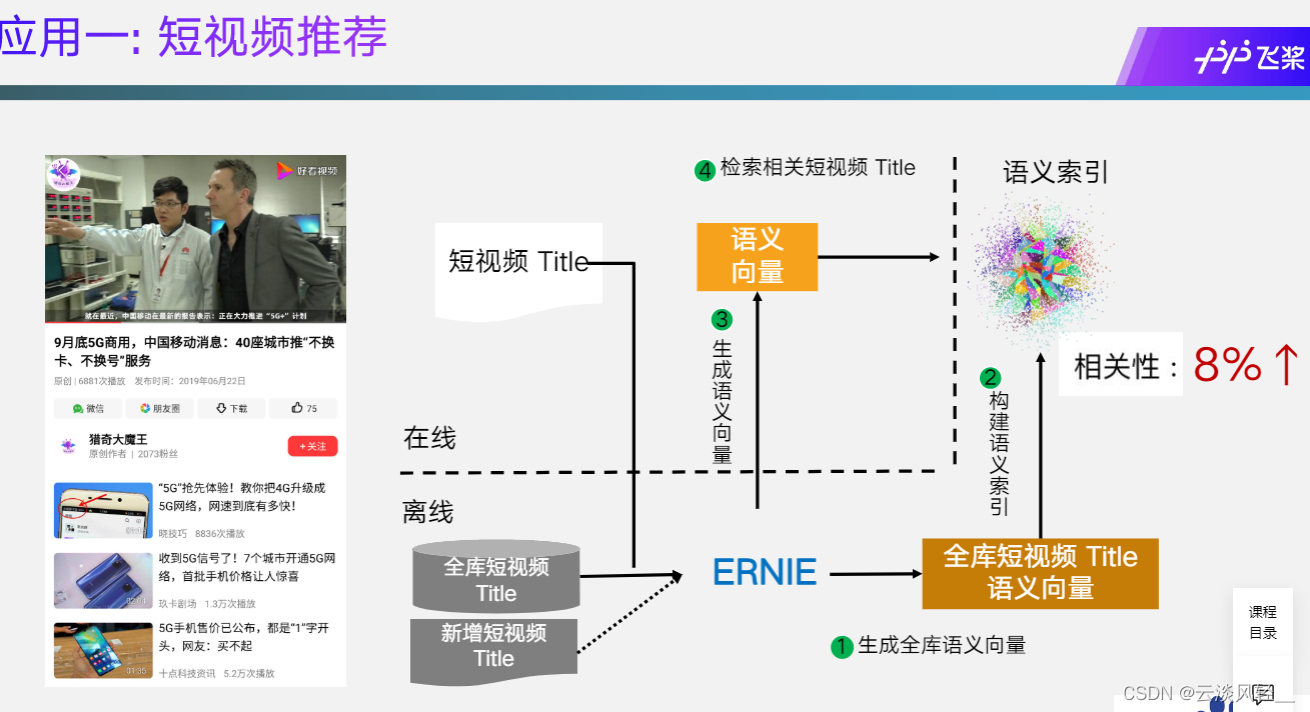
是有语义泛化的效果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









