









使用pandas解析JSON Dataset要方便得多。Pandas允许您将列表的列表转换为Dataframe并单独指定列名。
JSON解析器将JSON文本转换为另一种表示必须接受符合JSON语法的所有文本。它可以接受非JSON形式或扩展。实现可以设置以下内容:
- 它接受的文本大小的限制,
- 对嵌套的最大深度的限制,
- 对数字范围和精度的限制,
- 设置字符串的长度和字符内容的限制。
使用大型JSON数据集可能会恶化,特别是当它们太大而无法容纳在内存中时。在这种情况下,命令行工具和Python的组合可以成为探索和分析数据的有效方法。
导入JSON文件
JSON的操作是使用Python数据分析库pandas完成的。
import pandas as pd
现在,您可以使用命令read_json读取JSON并将其保存为pandas数据结构。
pandas.read_json (path_or_buf=None, orient = None, typ=’frame’, dtype=True, convert_axes=True, convert_dates=True, keep_default_dates=True, numpy=False, precise_float=False, date_unit=None, encoding=None, lines=False, chunksize=None, compression=’infer’)
import pandas as pd
# Creating Dataframe
df = pd.DataFrame([['a', 'b'], ['c', 'd']],
index =['row 1', 'row 2'],
columns =['col 1', 'col 2'])
# Indication of expected JSON string format
print(df.to_json(orient ='split'))
print(df.to_json(orient ='index'))
输出:
{"columns":["col 1", "col 2"],
"index":["row 1", "row 2"],
"data":[["a", "b"], ["c", "d"]]}
{"row 1":{"col 1":"a", "col 2":"b"},
"row 2":{"col 1":"c", "col 2":"d"}}
转换object对象到json数据使用dataframe.to_json
DataFrame.to_json(path_or_buf=None, orient=None, date_format=None, double_precision=10, force_ascii=True, date_unit=’ms’, default_handler=None, lines=False, compression=’infer’, index=True)
直接从Dataset读取JSON文件:
import pandas as pd
data = pd.read_json('http://api.population.io/1.0/population/India/today-and-tomorrow/?format = json')
print(data)
输出:
total_population
0 {'date': '2019-03-18', 'population': 1369169250}
1 {'date': '2019-03-19', 'population': 1369211502}
使用Pandas进行嵌套JSON解析:
嵌套的JSON文件可能非常耗时,并且很难将其展平并加载到Pandas中。
我们使用嵌套的“'raw_nyc_phil.json。"'从一个嵌套数组创建一个扁平化的pandas数据框,然后解包一个深度嵌套数组。
import json
import pandas as pd
from pandas.io.json import json_normalize
with open('https://github.com/a9k00r/python-test/blob/master/raw_nyc_phil.json') as f:
d = json.load(f)
# lets put the data into a pandas df
# clicking on raw_nyc_phil.json under "Input Files"
# tells us parent node is 'programs'
nycphil = json_normalize(d['programs'])
nycphil.head(3)

works_data = json_normalize(data = d['programs'],
record_path ='works',
meta =['id', 'orchestra', 'programID', 'season'])
works_data.head(3)
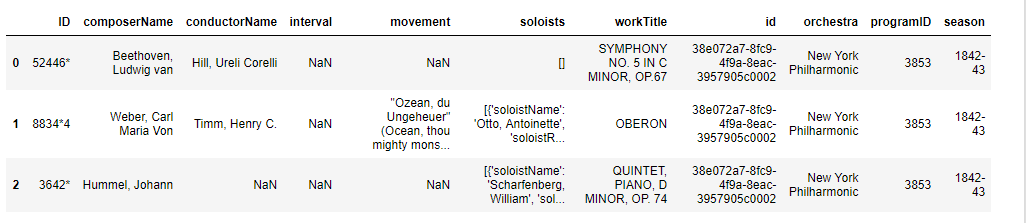
soloist_data = json_normalize(data = d['programs'],
record_path =['works', 'soloists'],
meta =['id'])
soloist_data.head(3)

将Pandas DataFrame导出到JSON文件
让我们看看如何将Pandas DataFrame导出为JSON文件。要执行此任务,我们将使用DataFrame.to_json()和pandas.read_json()函数。
示例1:
# importing the module
import pandas as pd
# creating a DataFrame
df = pd.DataFrame([['a', 'b', 'c'], ['d', 'e', 'f'], ['g', 'h', 'i']],
index =['row 1', 'row 2', 'row3'],
columns =['col 1', 'col 2', 'col3'])
# storing the data in JSON format
df.to_json('file.json', orient = 'split', compression = 'infer', index = 'true')
# reading the JSON file
df = pd.read_json('file.json', orient ='split', compression = 'infer')
# displaying the DataFrame
print(df)

我们可以看到DataFrame已经导出为JSON文件。

示例2:
# importing the module
import pandas as pd
# creating a DataFrame
df = pd.DataFrame(data = [['15135', 'Alex', '25 / 4/2014'],
['23515', 'Bob', '26 / 8/2018'],
['31313', 'Martha', '18 / 1/2019'],
['55665', 'Alen', '5 / 5/2020'],
['63513', 'Maria', '9 / 12 / 2020']],
columns =['ID', 'NAME', 'DATE OF JOINING'])
# storing data in JSON format
df.to_json('file1.json', orient = 'split', compression = 'infer')
# reading the JSON file
df = pd.read_json('file1.json', orient ='split', compression = 'infer')
print(df)
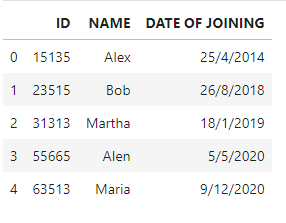
我们可以看到这个DataFrame也被导出为JSON文件。
















 1710
1710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









