







 本文详细解析了HTTP协议的工作原理,重点关注了请求头和响应头中的关键信息,包括User-Agent的重要性以及网络爬虫如何处理URL、状态码和伪装User-Agent。同时介绍了爬虫数据抓取的基础原理和常用工具如Selector的运用。
本文详细解析了HTTP协议的工作原理,重点关注了请求头和响应头中的关键信息,包括User-Agent的重要性以及网络爬虫如何处理URL、状态码和伪装User-Agent。同时介绍了爬虫数据抓取的基础原理和常用工具如Selector的运用。
Web请求全过程解析(重点必看)


协议简单了解
'''
HTTP 协议
协议: 就是两个计算机之间为了能够流畅的进行沟通而设置的一个君子协定.常见的协议有TCP/IP.SOAP协议,HTTP协
议,SMTP协议等等...
HTTP协议,Hyper Text Transfer Protocol (超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务
器传输超文本到本地浏览器的传送协议.直白点儿,就是浏览器和服务器之间的数据交互遵守的就是HTTP协议.
HTTP协议把一条消息分为三大块内容.无论是请求还是响应都是三块内容
请求:
1 请求行->请求方式(get/post) 请求url地址 协议
2 请求头->放一些服务器要使用的附加信息
3
4 请求体->一般放一些请求参数
响应:
1 状态行->协议 状态码 200 302 404 500
2 响应头->放一些客户端要使用的一些附加信息 cookie, 验证信息, 解密的key
3
4 响应体->服务器返回的真正客户端要用的内容(HTML, json)等
F12-->打开浏览器的开发者工具
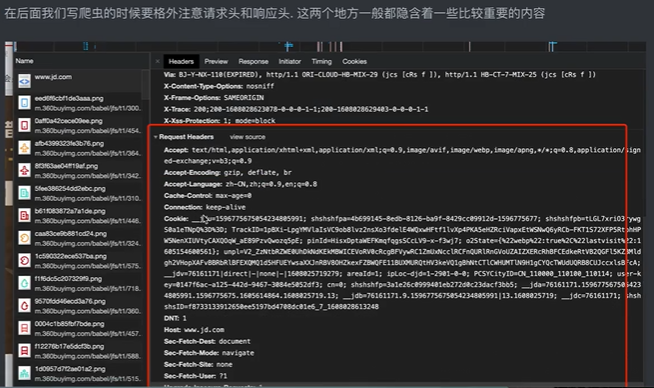
请求头中最常见的一些重要内容(爬虫需要):
1. User-Agent :请求载体的身份标识(用啥发送的请求)
2. Referer: 防盗链(这次请求是从哪个页面来的 ?反爬会用到)
3. cookie: 本地字符串数据信息(用户登录信息,反爬的token)
响应头中一些重要的内容:
1. cookie: 本地字符串数据信息(用户登录信息,反爬的token)
2. 各种神奇的莫名其妙的字符串(这个需要经验了,一般都是token字样,防止各种攻击和反爬
请求方式:
GET: 显示提交
POST: 隐示提交
'''后面我们重点关注 请求头和响应头。
HTTP协议
URL初步概念
web scraperweb scraperweb scraper
那么实际上浏览器用的是一种叫html标记的语言来进行解析网络请求的。
html标记语言 :
就是URL!
我们给浏览器输入的地址,实际上就是一个url(Uniform Resource Locator) 统一资源定位符 。
URL的一般格式是: protocol:// hostname[:port] / path / [;parameters][?query]#fragment
基本上是由三部分组成:
1 协议(HTTP呀,FTP呀~~等等)
2 主机的IP地址 (或者域名)
3 请求主机资源的具体地址(目录,文件名等)
其中:
第一部分和第二部分用 “://” 分割
第二部分和第三部分用 “/” 分割
1://2/3 —–> http://www.itcast.cn/channel/teacher.shtml#ac
下面看几个URL例子:
http://xianluomao.sinaapp.com/game
其中协议 http,计算机域名 xianluomao.sinaapp.com,
请求目录 game
http://help.qunar.com/list.html
其中协议 http,计算机域名 help.qunar.com 文件 list.html
网络爬虫的主要处理对象就是类似于以上的URL,爬虫根据URL地址取得所需要的文件内容,然后对它进一步的处理。
常见响应状态码
HTTP 响应状态码 https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status#参见
信息响应 (100–199)
成功响应 (200–299)
重定向消息 (300–399)
客户端错误响应 (400–499)
服务端错误响应 (500–599)
User-Agent
浏览器 就是世界上被允许的身份 。那么如果你不想你的爬虫代码成为一个路人,你需要伪装成一个被公认的浏览器 。
伪装的办法当然就是给自己的请求加上一个对应的User-Agent头啦。
web scraper
Chrome⽹上应⽤商店下载:
https://chrome.google.com/webstore/detail/web-scraper/jnhgnonknehpejjnehehllkliplmbmhn
web scraper 原理浅析
1、选择器(selector)参数讲解

2、爬⾍数据抓取原理(如何应⽤到所有⽹⻚)

3、选中元素顺序原理

4、csv ⽂件讲解

5、selector 操作选项讲解

6、sitemap 详情选项讲解


















 1663
1663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









