







 VinDR-SpineXR是一个深度学习框架,用于脊柱X射线图像的异常检测和分类。研究者构建了一个包含10468张脊柱X射线图像的大规模数据集,由放射科医师手动注释13种异常。框架包括分类和检测网络,分别用于判断扫描是否异常和定位病变。在独立的测试集上,该框架展示了88.61%的AUROC和33.56%的mAP@0.5。数据集和代码将公开发布,以促进进一步研究。
VinDR-SpineXR是一个深度学习框架,用于脊柱X射线图像的异常检测和分类。研究者构建了一个包含10468张脊柱X射线图像的大规模数据集,由放射科医师手动注释13种异常。框架包括分类和检测网络,分别用于判断扫描是否异常和定位病变。在独立的测试集上,该框架展示了88.61%的AUROC和33.56%的mAP@0.5。数据集和代码将公开发布,以促进进一步研究。
VinDr-SpineXR: A deep learning framework for spinal lesions detection and classification from radiographs
VinDR-SpineXR:一种用于从X光片中检测和分类脊柱病变的深度学习框架
时间:2021
开源地址(未发布):https://github.com/vinbigdata-medical/vindr-spinexr
摘要
在临床实践中,X光片被用作识别脊柱异常的最重要的成像工具。然而,对于放射科医师来说,评估脊柱骨病变是一项具有挑战性的任务。这项工作旨在开发和评估一个名为VinDr SpineXR的基于深度学习的框架,用于脊柱X射线异常的分类和定位。首先,我们构建了一个大型数据集,其中包括来自5000项研究的10468张脊柱X射线图像,每项图像均由经验丰富的放射科医师手动注释,并在13个类别的异常发现周围设置边界框。使用这个数据集,我们然后训练一个深度学习分类器来确定脊柱扫描是否异常,并在总共13个中定位7个关键发现的检测器.VinDrSpineXR在来自1000个研究的2078个图像的测试集上进行评估,与训练集分开。它显示了图像级别分类任务的接收器工作特性曲线(AUROC)下面积为88.61%(95%CI 87.19%,90.02%)和平均平均精度(mAP@0.5)病变级别定位任务的33.56%。这些结果可作为概念验证,并为这方面的未来研究奠定基础。为了鼓励进步,数据集,代码和训练有素的深度学习模型将公开发布。
介绍
1.1、介绍
在脊柱损伤的评估中,传统的放射照相或X射线比许多其他成像方式提供有价值的信息的能力[20,29]。它已成为广泛用于识别和监测各种脊柱异常的主要工具。从X射线可以观察到广泛的脊柱状况,如骨折、骨赘、骨质疏松症、椎体塌陷或肿瘤[2,24]。在临床实践中,放射科医生通常通过存储在医学数字成像和通信(DICOM)标准中的X射线扫描来解释和评估脊柱。可以基于与正常区域相比病变的密度,强度和几何形状的差异来识别异常发现。
机器学习的快速发展,特别是深度神经网络,在从医学成像数据中识别疾病方面显示出巨大的潜力[26]。将这些系统整合到日常临床工作中可能会带来更有效、更准确的诊断和治疗[12]。这项研究中,我们的目标是开发和验证一个基于深度学习的计算机辅助诊断(CAD)框架,称为VinDR-SpineXR,它能够对脊柱X光中的异常发现进行分类和定位。我们建议的系统的训练和验证都是在我们自己的数据集上进行的,放射科医生的注释是一个强有力的基础事实。
1.2、相关工作
近年来,开发具有很高临床价值的CAD工具来支持放射科医生解释肌肉骨骼(MSK)X射线已被广泛研究【6】。分析脊柱X光的方法侧重于使用射线纹理来检测几种特定的病理,如脊椎骨折【10】、骨质疏松【9】或骨溶解【31】。目前,深卷积网络14(CNNs)在从X射线【11,16,17,21,25,30,33】的MSK分析中显示出了显著的改进。这些研究大多集中在自动骨折检测和定位方面[11,16,21,30,33]。据我们所知,目前还没有研究致力于开发和评估综合系统,用于根据X射线扫描对多发性脊柱病变进行分类和定位。缺乏具有高质量图像和人类专家注释的大型数据集是关键障碍。为了填补这一空白,这项工作集中于创建一个重要的脊柱X射线基准数据集,这些数据集由经验丰富的放射科医生在病变水平上进行手动注释。我们还建议基于我们的数据集开发和评估一个基于深度学习的框架,该框架包括一个正常和异常分类器,然后是一个病变检测器,该检测器用边界框定位多个类别的发现。这两项任务在临床实践中都是有益的:正常和异常分类器帮助对患者进行分类,而病变检测器有助于加快读取过程,并补充放射科医生的观察。
1.3贡献
我们在这篇论文中的贡献有两个方面。首先,我们提出了一个新的大规模数据集,包括来自5000项研究的10469张脊柱X射线图像,这些图像由放射科医生用13种类型的异常进行手动注释。这是迄今为止最大的数据集,它为开发有监督的学习目标检测算法提供放射科医生的包围盒注释。表1提供了公开可用的MSK数据集的摘要,其中之前的两个脊椎数据集[5,11]在大小上明显小于我们的数据集。此外,人类专家对脊柱异常的注释在这些数据集中是不可用的。其次,我们开发和评估了VinDR-SpineXR-一个能够对多个脊柱病变进行分类和定位的深度学习框架。我们的主要目标是在发布的数据集上提供最先进的深度学习方法的重要基线性能,这可能有助于进一步的模型开发和新型CAD工具的比较。为了促进新的进展,我们已经在我们项目的网页上向公众提供了该数据集。实验中使用的代码可以在Github上找到。
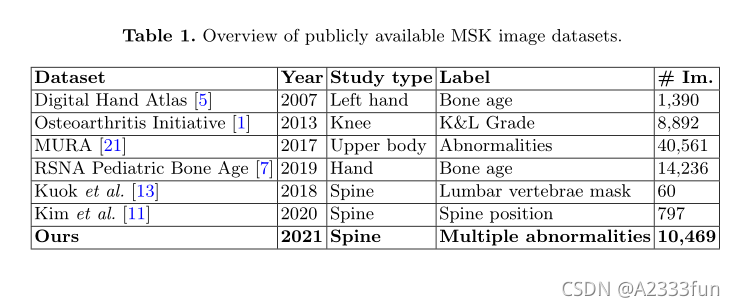
表1.公开可用的MSK图像数据集概述
2、提出的方法
2.1、总体框架
提出的深度学习框架(见图1)包括两个主要部分:(1)分类网络,它接受脊柱x线作为输入,并预测它是正常还是异常扫描;(2)检测网络接收相同的输入并预测异常发现的位置。为了最大限度地提高框架的检测性能,我们提出了一个决策规则来合并两个网络的输出。
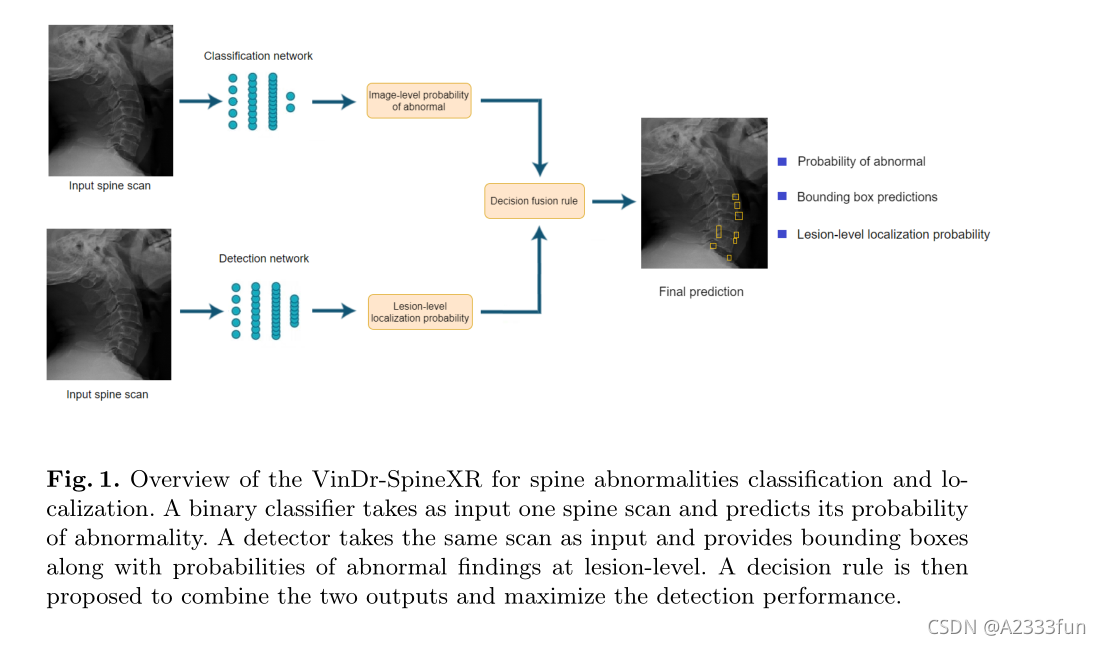
图1所示。VinDr-SpineXR用于脊柱异常分类和定位的概述。二值分类器以一次脊柱扫描为输入,预测脊柱扫描异常的概率。检测器接受与输入相同的扫描,并提供边界框以及病变级别异常发现的概率。在此基础上,提出了一种决策规则,将两种输出结合起来,使检测性能最大化。
2.2、数据集
数据收集
为了开发自动病变检测系统,需要有病变水平标注的脊柱x线片。本研究回顾性收集了2010-2020年不同基层医院PACS (Picture Archive and Communication System)中5万多张DICOM格式脊柱原始图像。数据收集过程是在我们与参与的医院合作下进行的。由于本研究不影响临床护理,因此放弃了患者的同意。为了确保患者受保护健康信息(PHI)的安全,已删除与图像相关的所有患者可识别信息。保留了一些对评估脊柱状况很重要的DICOM属性,如患者的年龄和性别。
数据注释
为了标注数据,我们开发了一个内部标签框架,称为VinDr Lab[18],它建立在PACS之上。这是一个基于网络的框架,允许多名放射科医生同时远程工作。此外,它还提供了一组全面的注释工具,帮助最大化人工注释器的性能。从原始数据中随机选取5000份脊柱研究,剔除异常值(例如身体其他部位或低质量部位的扫描)。所有这些扫描都被上传到标签框架,并分配给3名参与的放射科医生,他们至少有10年的经验,这样每次扫描都由一名放射科医生进行注释。在这个步骤中,放射科医生决定扫描是异常还是正常,并在扫描上标出每个异常的确切位置。放射科医生提供的标签和注释被作为模型开发和后续验证的基础事实。在此过程中,除了患者的年龄和性别外,放射科医生对相关的临床信息一无所知。最后,来自5000项研究的10468张脊柱图像中有13个异常发现:强直、椎间盘间隙狭窄、植骨、椎间孔狭窄、骨折、骨赘、硬化病变、脊椎滑脱、软骨下硬化、外科植入物、椎体塌陷、异物和其他病变。“无发现”标签的目的是表示没有任何异常。为了开发深度学习算法,我们在研究层面将标记的数据集随机分层,分为4000项研究的开发集和1000项研究的测试集。
-
表2总结了数据特征,包括患者人口统计和每个标签的流行率通过边界框的数量。
-
图2显示了几个具有代表性的样本,其中有来自我们数据集的异常结果,也有没有异常结果的。
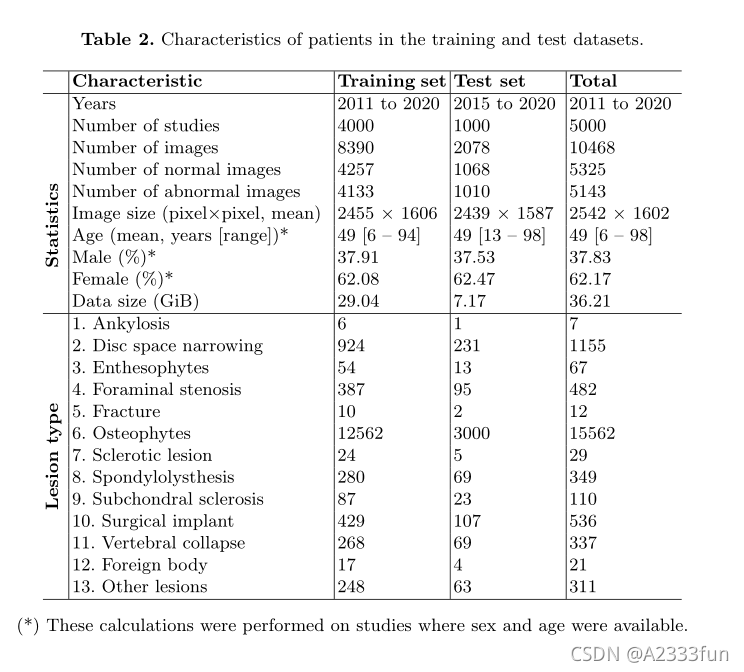
表2:训练和测试数据集中患者的特征。
(*)这些计算是在有性别和年龄的研究中进行的。
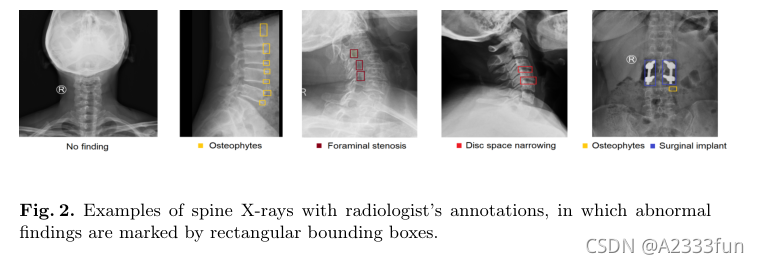
图2所示。脊柱x光的例子与放射科医生的注释,其中异常发现被矩形框标记。
2.3、模型开发
网络架构和训练方法
为了将脊柱x射线图像分为正常或异常,部署了三个cnn (DenseNet-121, DenseNet-169, DenseNet-201)。众所周知,这些网络[8]对x射线解释是有效的[21,22]。每个网络接受脊柱的图像作为输入,输出对应正常或异常扫描的二进制标签。我们使用训练集中的4257张正常脊柱图像和4133张异常脊柱图像(反映任何病变)来优化网络的权重。在此阶段,我们使用SGD优化器优化图像级标签与网络输出之间的交叉熵损失。三个模型的平均集合作为最终的分类器。如果图像异常概率大于最佳阈值,则在推断阶段认为图像异常。特别地,我们通过最大化Youden’s index 来实现分类器最佳阈值c*:
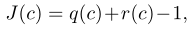
其中灵敏度q和特异性r是截止值c的函数。
对于检测任务,我们的目标是定位7个重要病变:骨赘、椎间盘间隙狭窄、手术植入物、椎间孔狭窄、脊椎滑脱、椎体塌陷和其他病变。由于阳性样本数量有限,其余病变视为“其他病变”。目前已经部署了最先进的检测器,即Faster R-CNN[23]、retina anet[15]、EfficientDet[28]和Sparse R-CNN[27]。选择更快的R-CNN[23]作为基于主播的两级检测器的代表,首先提出一组候选区域,然后对其位置进行分类和细化。retanet[15]和EfficientDet[28]都是单状态检测器,直接定位和分类密集提出的锚盒。与之前的检测器不同的是,Sparse R-CNN[27]从一组初始的提议开始,然后使用注意机制对这些盒子进行反复的细化和分类。所有网络都经过训练,使用随机梯度下降(SGD)优化器定位脊柱病变。在学习阶段,将边界盒回归损失和区域级分类损失共同最小化。为了提高检测器的泛化性能,在训练过程中引入了目标检测的数据增强策略[34]。
决策融合规则
给定一个输入图像x,我们将ˆp(abnormal|x)表示为反映图像异常概率的分类器输出。为了最大化损伤检测器的性能,我们提出如下启发式融合规则。对于预测p(abnormal|x)≥c的任何物体,所有损伤检测结果将保留。对于p(abnormal|x)< c∗,仅保留置信度高于0.5的预测边界盒。


















 6308
6308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









