







本文内容源自百度强化学习 7 日入门课程学习整理
感谢百度 PARL 团队李科浇老师的课程讲解
一、离散动作 VS 连续动作
1.1 区别
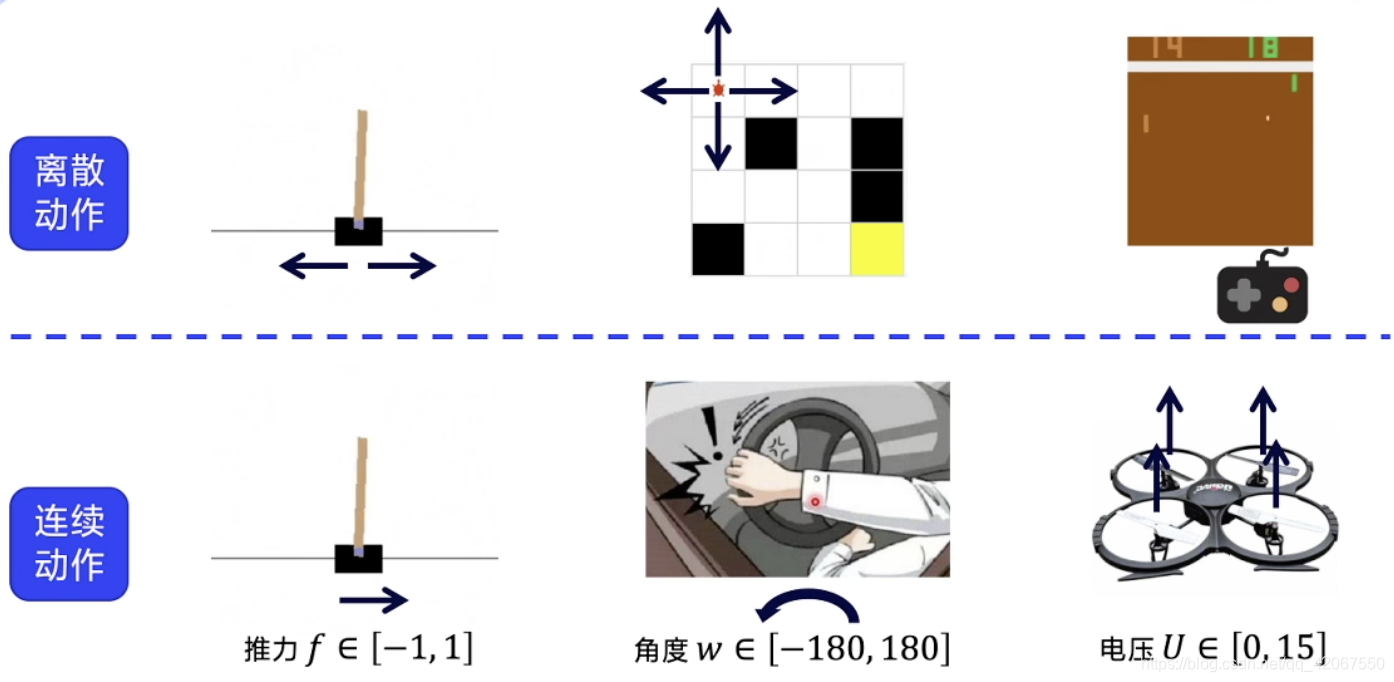
离散动作:
- 动作都是可数的
- 比如在 CartPole 环境中,向左推动小车,或者向右推动(力量是不变的)
- 比如在 FrozenLake 环境中,向上下左右 4 个方向移动
- 在 Atari 的 Pong 环境中,球拍上下移动
连续动作:
- 动作是连续的浮点数
- 比如在另一种 CartPole 环境中,设定推力为 -1~1,包含了方向又包含了力度
- 比如开车,方向盘的旋转角度:-180~180
- 四轴飞行器,控制马达的电压:0~15
1.2 神经网络修改
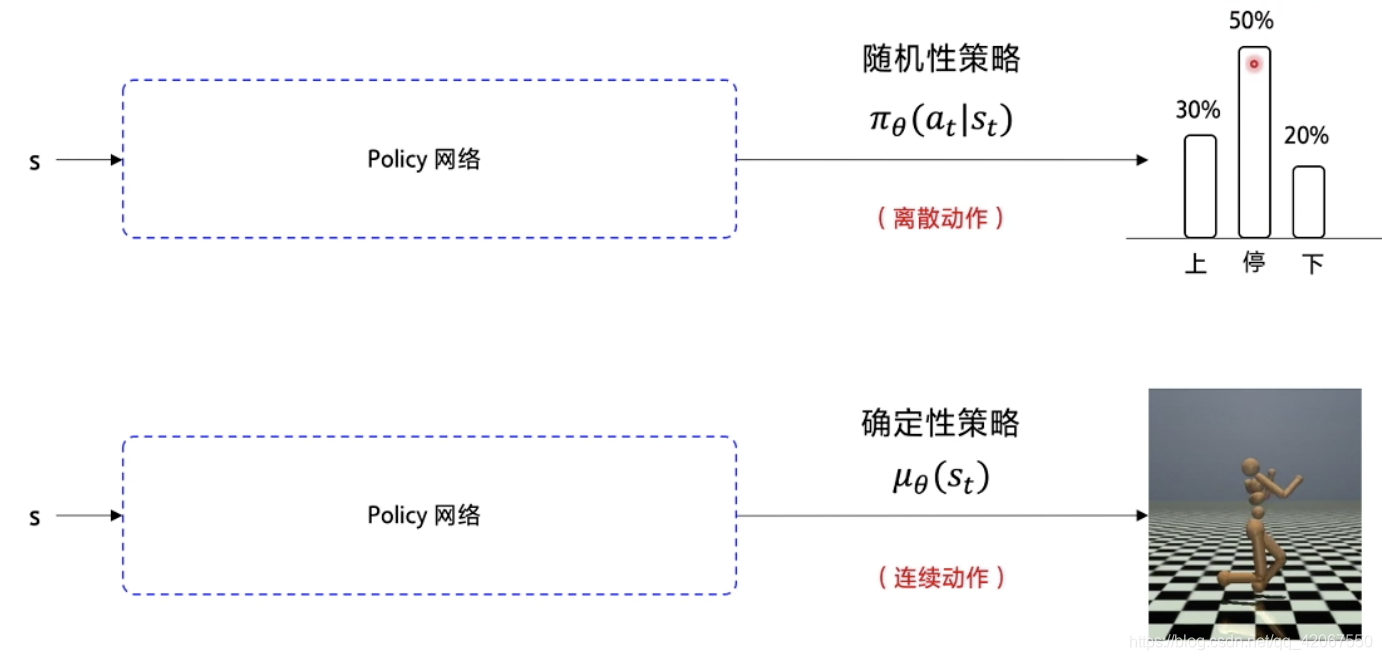
在连续动作空间中,Sarsa,Q-learning,DQN,Policy Gradient 都无法处理
所以我们要用一个替代方案:
- 在 Policy Gradient 中,输入状态 s,使用策略网络输出不同动作的概率
- 随机性策略: π θ ( a t ∣ s t ) π_θ(a_t|s_t) πθ(at∣st)
- 在连续动作环境下,输出的是一个具体的浮点数,这个浮点数代表具体的动作(比如包含了方向和力的大小)
- 确定性策略: μ θ ( s t ) μ_θ(s_t) μθ(st)
1.3 激活函数选择
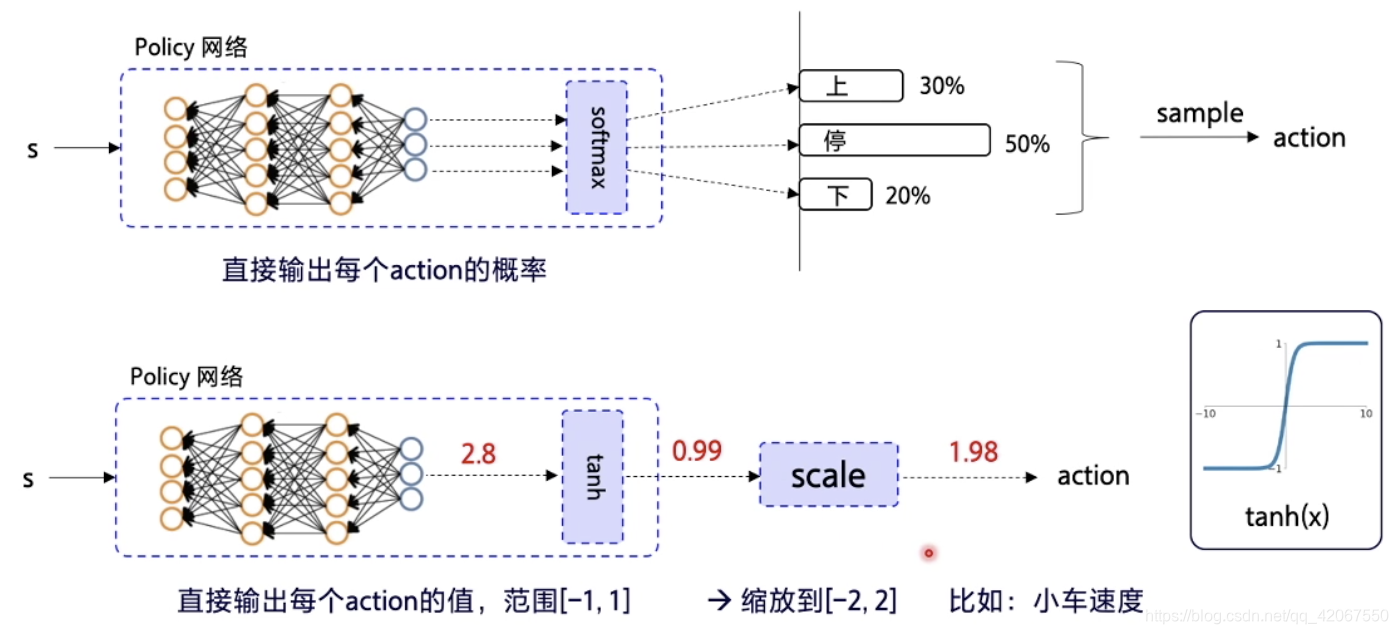
离散动作环境:
- 输出层使用 softmax,确保每个动作输出概率加总为 1
连续动作环境:
- 输出层使用 tanh,即输出为 -1~1 之间的浮点数
- 经过缩放,对应到实际动作
二、DDPG(Deep Deterministic Policy Gradient)
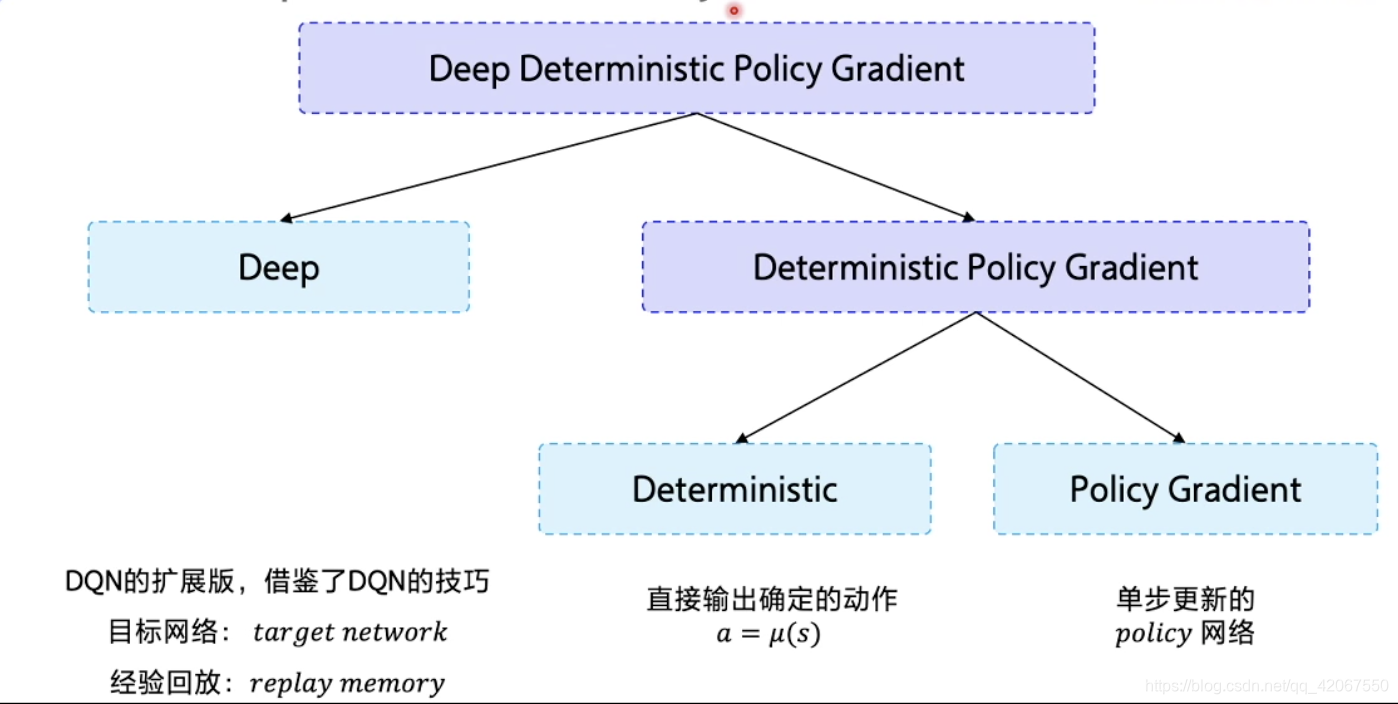
DDPG 算法可以理解为 DQN 在连续动作网络中的修正版本
- Deterministic:代表直接输出确定性动作 a = μ ( s ) a=μ(s) a=μ(s)
- Policy Gradient:是策略网络,但是是单步更新的策略网络
该算法借鉴了 DQN 的两个工程上的技巧:
- 目标网络:target network
- 经验回放:replay memory
2.1 从 DQN 到 DDPG
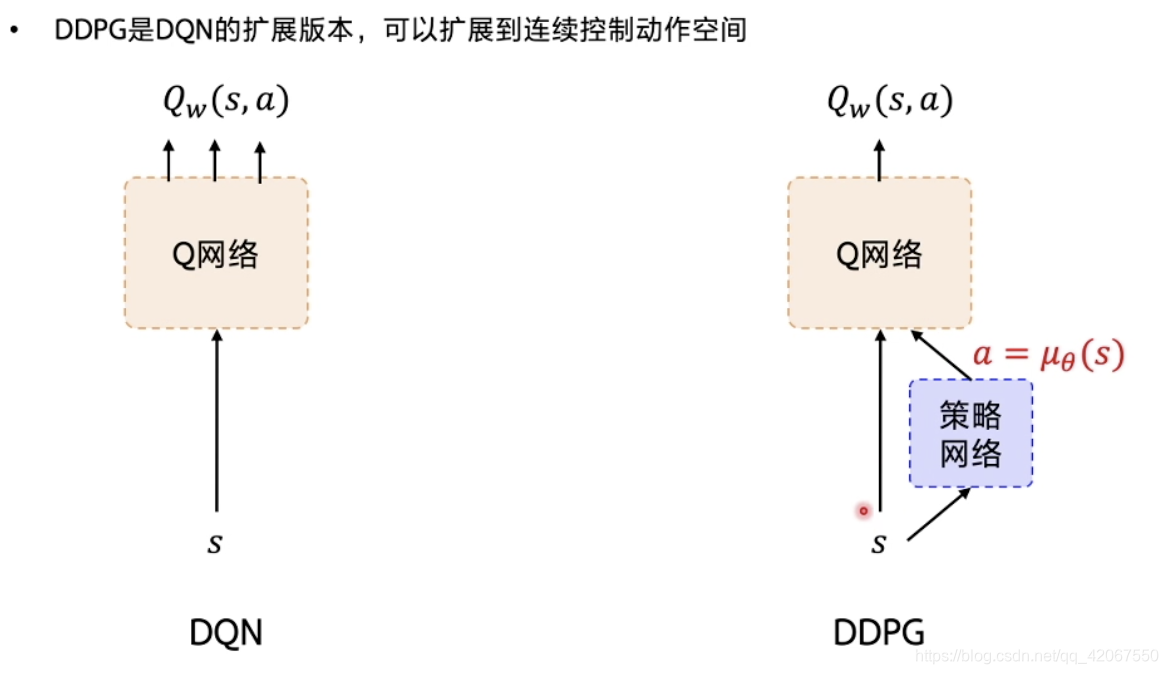
在 DQN 的基础上,加了一个策略网络 Policy Gradient,用来直接输出动作值
- 在 DQN 中,只有 Q 网络输出 不同动作对应的 Q 值
- 所以 DDPG 需要同时学习 2 个网络:Q 网络 和 策略网络
- Q 网络: Q w ( s , a ) Q_w(s,a) Qw
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









