









联邦学习总结
这两篇文章是我近期对联邦学习的简单总结:链接放上。
并行计算和联邦学习
FATE框架联邦学习
并行计算和联邦学习
并行计算:ResNet-50:25M个参数。参数多、数据大。
而并行计算可以减少时间。并行计算可以减少钟表时间,但并不会减少CPU、GPU计算时间
比如线性回归中,并行梯度下降求得梯度,由于有n个训练样本,做分布式计算时,可以把样本划分到多个机器上,每个机器可以用本地的样本来算的本地的梯度。
每轮计算梯度的代价比较大,样本越多计算量越大,权重的维度越高计算量也越大。
数据并发:每个worker只有部分参数
模型并发:每个worker都有全部的数据,但只有部分的模型参数(较为复杂)
一、节点之间如何通信
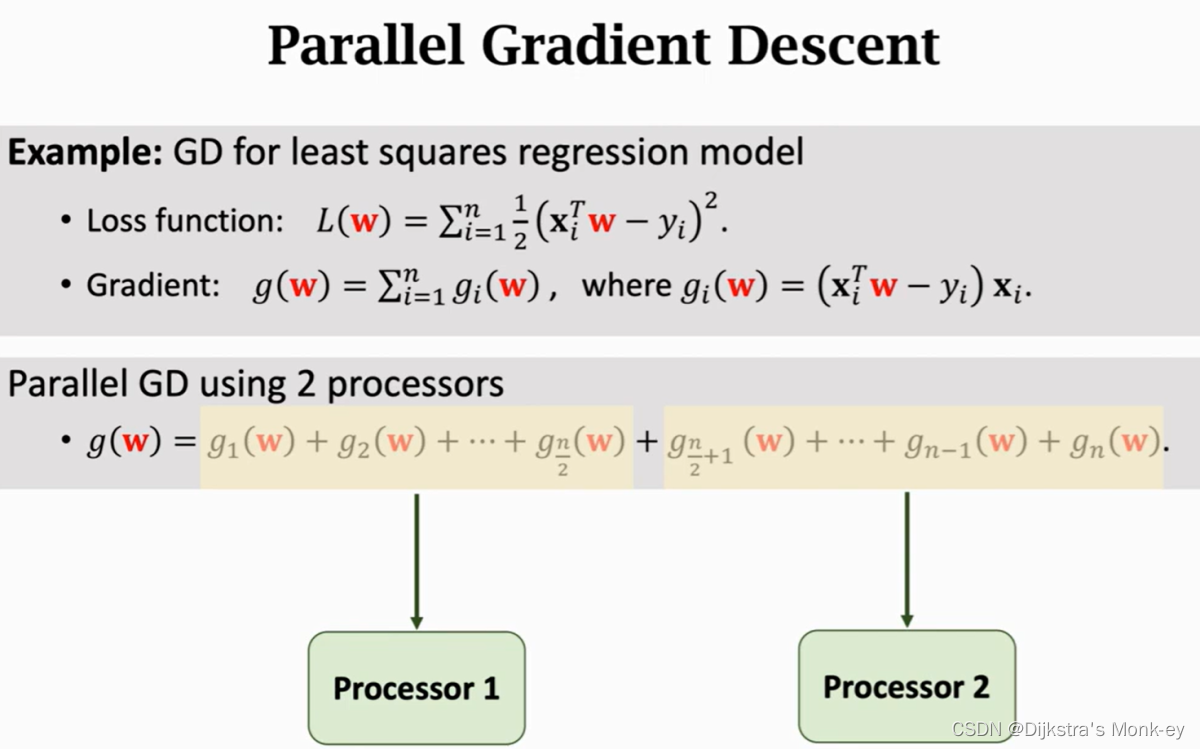
复杂之处在于如何通信:处理器之间的通信问题 : share mempory, message passing
1)共享内存
无法做到大规模的并行,一个主机上内核不可能太多
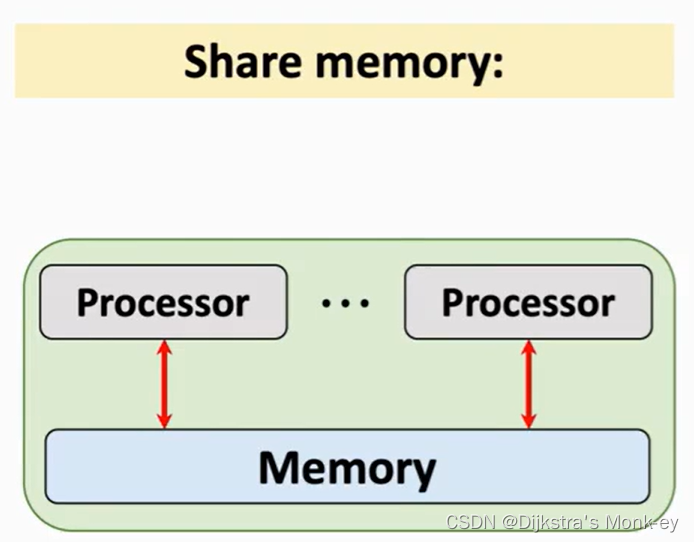
2)消息传递
有多个节点,每个节点都有多个处理器。节点的处理器之间可以共享内存,但是不同节点1看到直接看到节点2的内存。可以将向量打包成很多个package,然后通过网线、TCP/IP协议,将消息发送给另一个节点。
若有多个节点肯定要用message packing,不能用共享内存。
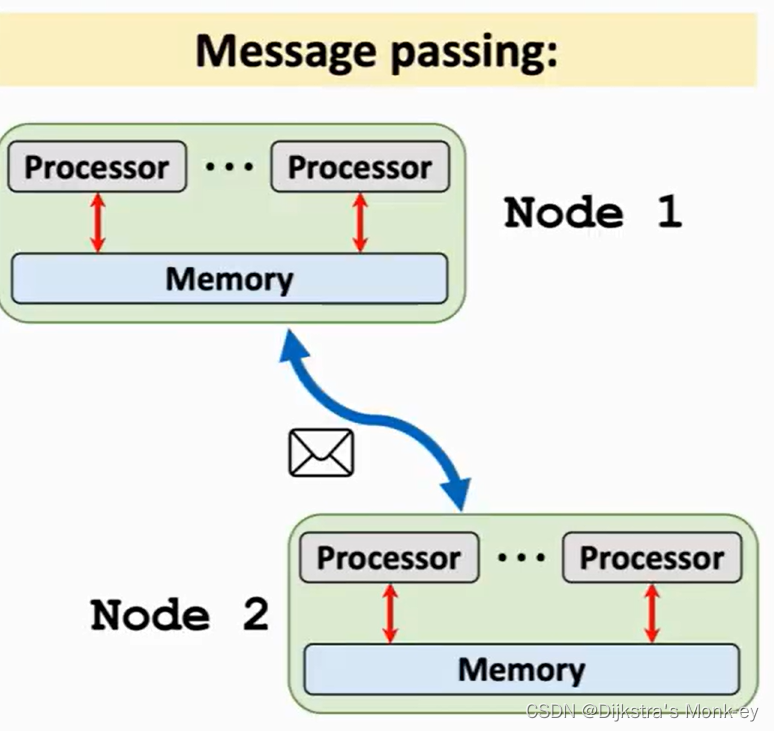
二、如何协调各节点的工作
做并行计算时,一个问题是如何去协调这些节点,让节点可以协同工作?
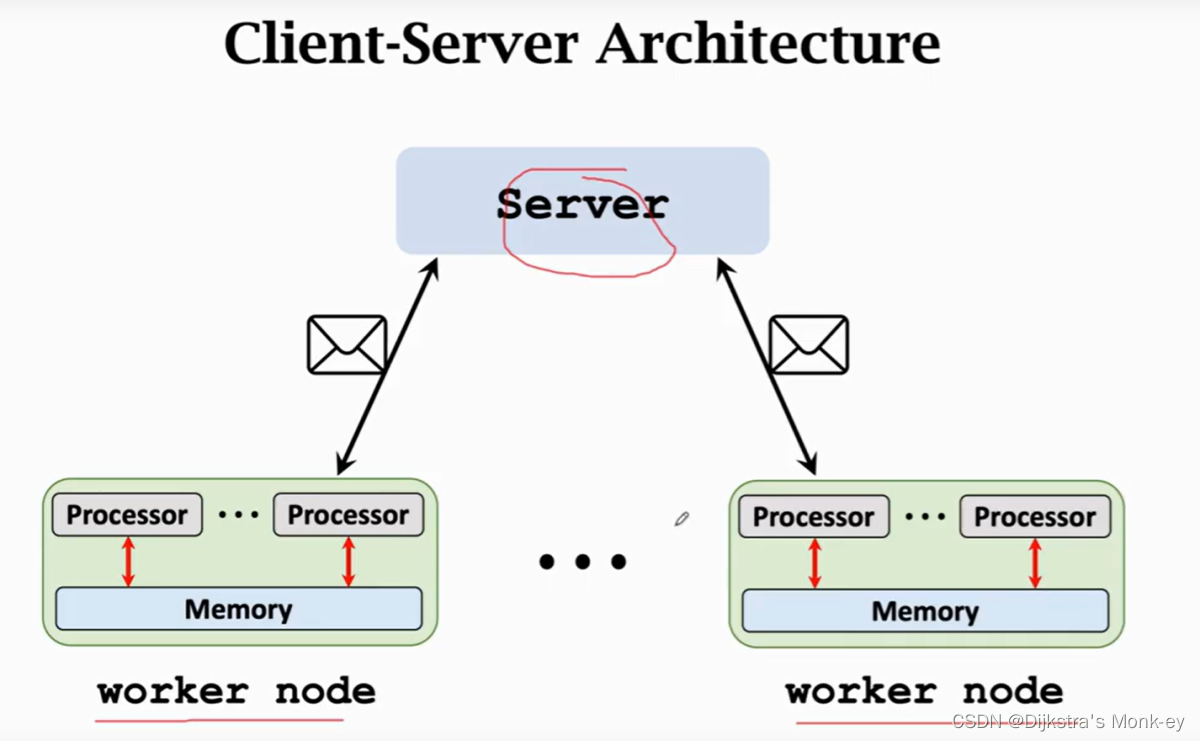
1)C/S架构
把一个节点作为Server,把其他节点作为worker用来做计算。
2)P2P架构
另一种架构是P2P,没有Server。所有的节点都拿来做计算,每个节点之间都有邻居,邻居之间可以通信。
三、常见实现方法
并行梯度下降几种不同的方法实现:
(1)MapReduce
(google开发的系统,C/S,message packing,需等待所有的worker全部完成工作,才能进行下一轮)做并行梯度下降。一种同步算法。该算法可分为以下几个步骤:
1)broadcast
Server需要把模型参数广播出去,每个节点都可以做计算。Server把需要更新的参数 w t w_{t} wt广播给worker。这一步需要Server和Worker之间的通信。
2)Map
要实现某个算法,我们可以自己制定一个函数,所有的节点都执行该函数,这一步叫做map。map操作是由所有的worker并行做的。这一步无需通信。Map ( x i , y i , w t x_{i},y_{i},w_{t} xi,yi,wt)to g i = ( x i T w − y i ) x i g_{i} = (x_{i}^Tw - y_{i})x_{i} gi=(xiTw−yi)xi,n个数据样本会被映射到n个向量: g 1 , g 2 , g 3 , . . . g n g_{1},g_{2},g_{3},...g_{n} g1,g2,g3,...gn。
3)Reduce
Reduce操作也需要通信。Mean、Collect两种函数。每对数据样本是(x, y)。
可以使用
g
=
∑
i
=
1
n
g
i
g = \sum_{i=1}^n g_{i}
g=∑i=1ngi,获取到
w
t
w_{t}
wt方向的梯度。做此操作时,每个worker会把自己本地存的
g
i
g_{i}
gi加起来得到一个向量,worker会将此向量传到Server,而Server会将这些向量加起来。
4)Update
Server会更新权重
w
t
+
1
=
w
t
−
α
⋅
g
w_{t+1} = w_{t} - \alpha·g
wt+1=wt−α⋅g
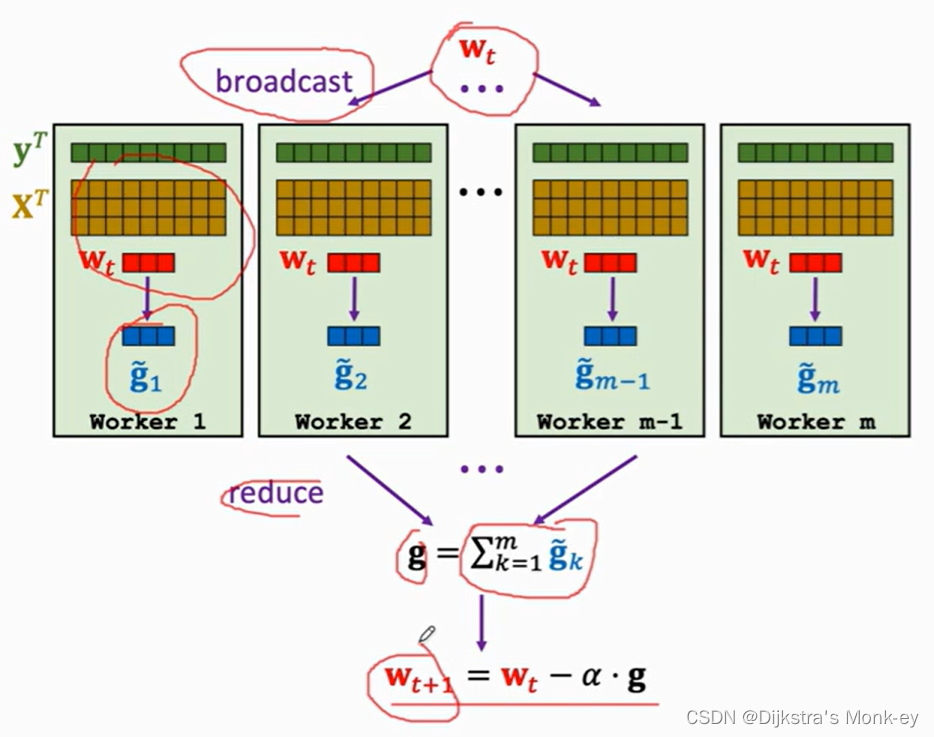
5)系统不断重复以上操作,知道算法收敛。
假设我们使用了m个节点,那么每个节点值存储1/m的数据,每个worker节点只做了1/m的运算。但是计算时间并没有减小到原来的1/m。因为并行计算会有通信和同步的代价,通信和同步都是需要时间的。
做并行计算通常会计算的指标:加速比(Speedup Ratio)
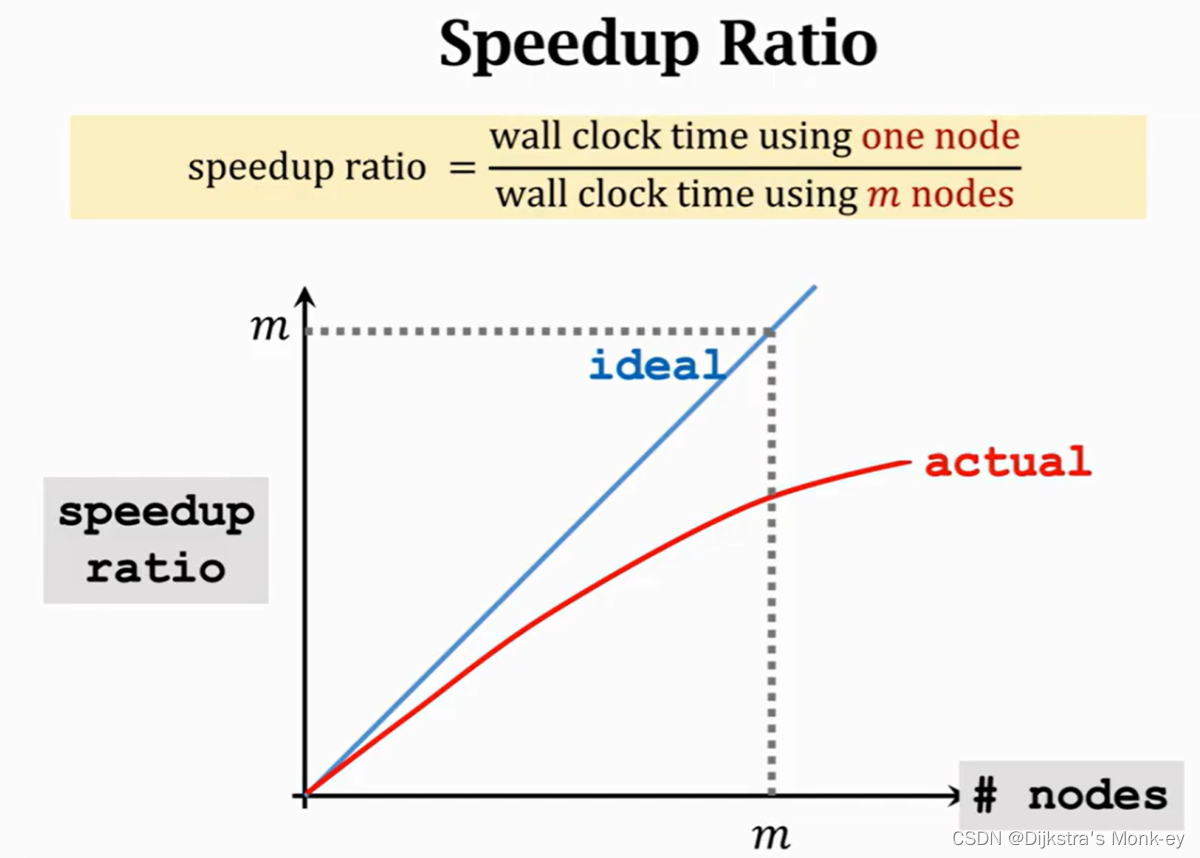
最理想状况就是图中的蓝色直线。而真实环境下加速比是达不到该标准的,一般只会达到红线的标准。
通信代价
1)通信复杂度:Server和Worker之间需要传输的单词数或者比特数。正比于模型的参数,模型越大,通信复杂度就越高。通信复杂度通常也会随结点的数量增长而增长。
2)网络延迟:由计算机网络和软件系统决定
通信所需的时间:通信复杂度/网路带宽+网络延迟。算法通信传输的次数越多,通信代价就越大,因此有必要减少通信次数。
同步代价
通常情况下worker的计算会有快有慢。需要等所有的worker都完成计算之后,系统才可以做reduce。这意味着所有的worker需要等待计算最慢的worker。加入一个节点挂掉重启,该节点就会拖很长时间,成为“Straggler effect”。
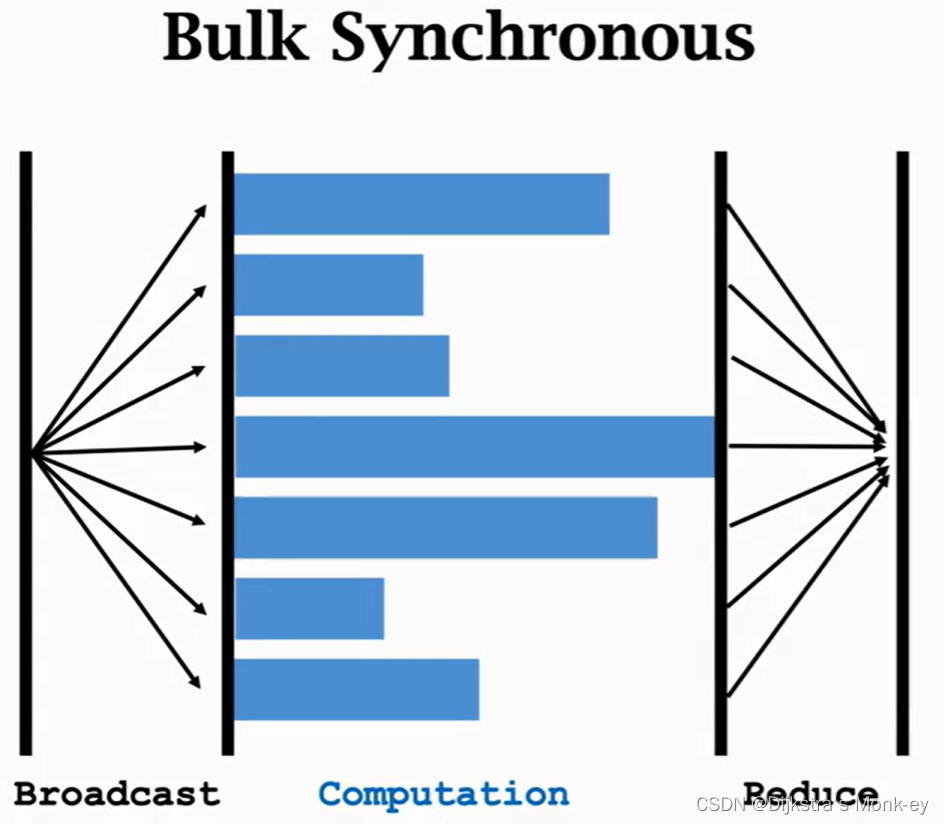
(2)异步并行梯度下降(Parameter Server)
也是C/S架构。worker算梯度,Server更新梯度。这是一种一步算法,效率比同步算法要高。可以用Ray开源系统,比Spark流行很多。

worker端的运算:
每个woker重复以下操作(无需管其他worker,不需同步):
1、向Server发送请求,获取最新的参数w(需要一次通信)
2、通过利用本地的数据和w算出梯度
g
i
~
\tilde{g_{i}}
gi~,
3、把
g
i
~
\tilde{g_{i}}
gi~发送给Server,完成第二次通信。
Server端的运算:
1、从worker获取梯度
g
i
~
\tilde{g_{i}}
gi~;
2、更新参数:
w
t
+
1
=
w
t
−
α
⋅
g
i
~
w_{t+1} = w_{t} - \alpha·\tilde{g_{i}}
wt+1=wt−α⋅gi~

异步算法存在的问题:假如worker3梯度更新得慢,那么Server最终拿到worker3提供的梯度再更新是无意义的。因此一步算法是有要求的。
(3)去中心化的网络(P2P,无Server)
点对点、message packing、邻节点之间通信
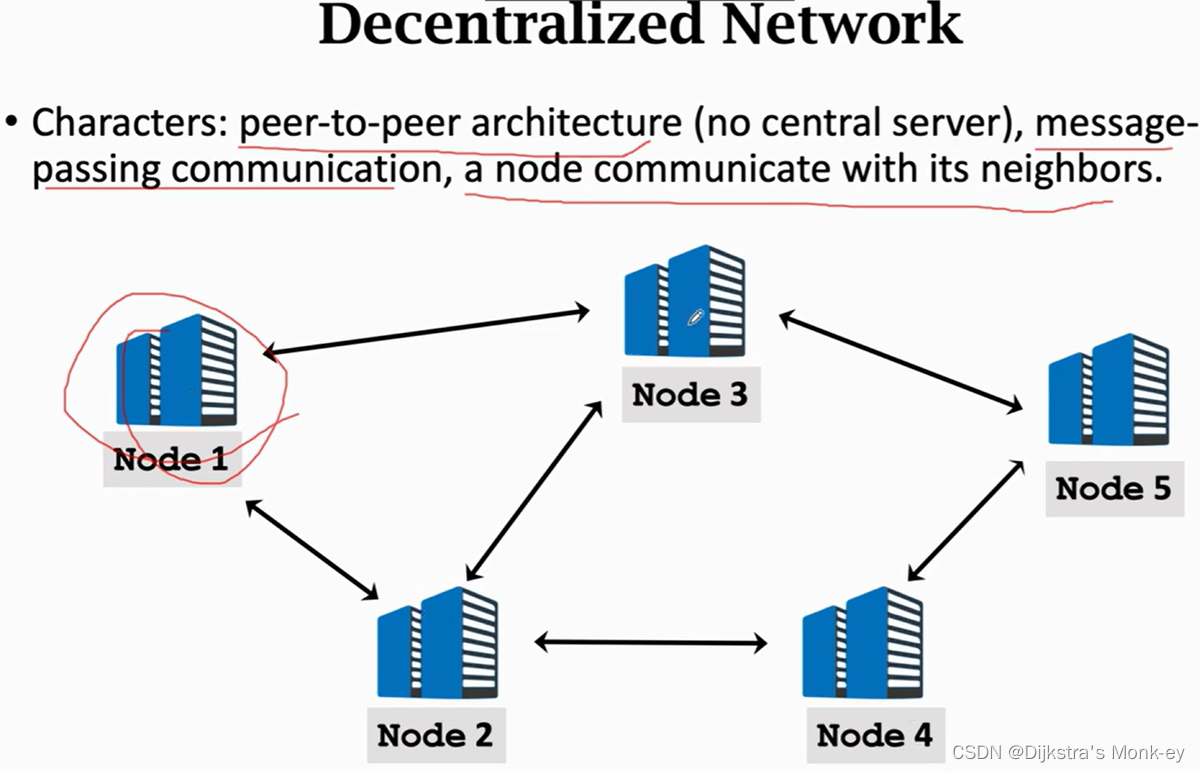
每个节点都只有一部分数据,彼此看不到其他节点的数据。
每个节点重复以下四个步骤,直到算法收敛。
1、用节点本地的数据和当前参数
w
i
~
\tilde{w_{i}}
wi~来计算梯度
g
i
~
\tilde{g_{i}}
gi~;
2、向他们的邻接节点获取邻接节点的参数{
w
k
~
\tilde{w_{k}}
wk~}(需要通信);
3、将
w
i
~
\tilde{w_{i}}
wi~和{
w
k
~
\tilde{w_{k}}
wk~}取加权平均,得到新的参数
w
i
~
\tilde{w_{i}}
wi~;
4、节点本地做梯度下降,更新参数:
w
i
~
←
w
i
~
−
α
⋅
g
i
~
\tilde{w_{i}} \leftarrow \tilde{w_{i}} - \alpha·\tilde{g_{i}}
wi~←wi~−α⋅gi~。
去中心化网络的算法形成一个图。图的连接越紧密,算法收敛越快。
证明该算法必会收敛的文献:

四、并行计算和分布式计算。
可认为分布式计算就是一种并行计算。

联邦学习(Federated Learning)
Google想要建立一个机器学习模型,通过云服务器集群来训练各个用户的移动端APP采集的数据,但是会涉及到侵犯用户隐私的问题。
医院、银行、保险公司不可能轻易把数据交给别人整合到一起训练模型来保证训练结果的准确性。
联邦学习其实本质上就是一种分布式机器学习。但也有区别:
1、Server对worker的控制权大小不同
联邦学习中用户拥有对自己的设备和数据的控制权(犹如美国各州有一定的自治权)。而传统并行计算worker需要接受Server的指令,受Server的控制。
2、Worker的稳定性
联邦学习中的worker往往都是向移动端这样不太稳定的设备(比如容易没电关机),而传统并行计算worker一般都是机房中连着高速宽带、24小时保持开机的稳定的设备。联邦学习设备的计算力也不尽相同,可能计算性能差距很大。
3、通信代价的大小
联邦学习中的通信代价要远远大于传统的并行计算。
4、数据是否独立同分布
传统的分布式机器学习,数据通常是均匀的、随机打乱的,可以假设数据是独立同分布的。而联邦学习中不同的客户端的数据可能差别很大,不能视为独立同分布,因此很多已有的算法便不再适用。
5、节点负载的平衡
联邦学习的节点数据集或大或小,负载很不平衡,权重的分配非常困难。而且不能做负载均衡,不可能把其中一个节点的数据转移到另一个节点。
因此联邦学习遇到的困难很多,另外需要格外注意如何减少通信的次数。核心做法:多做计算,少做通信。
常见算法:
Federated Averaging Algorithm
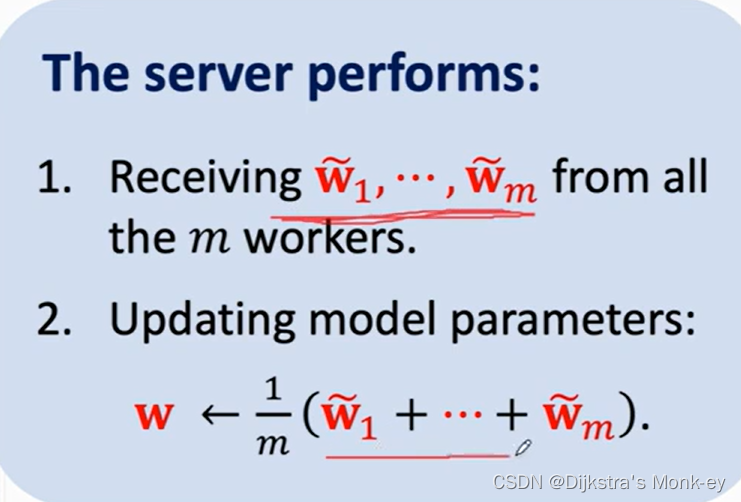
与并行梯度下降算法的不同之处:w在每个节点中直接进行几轮更新,最终再发给服务器,而非在服务器中更新

Server接收到各个节点发送的
w
i
~
\tilde{w_{i}}
wi~之后,取平均作为新的模型参数w。
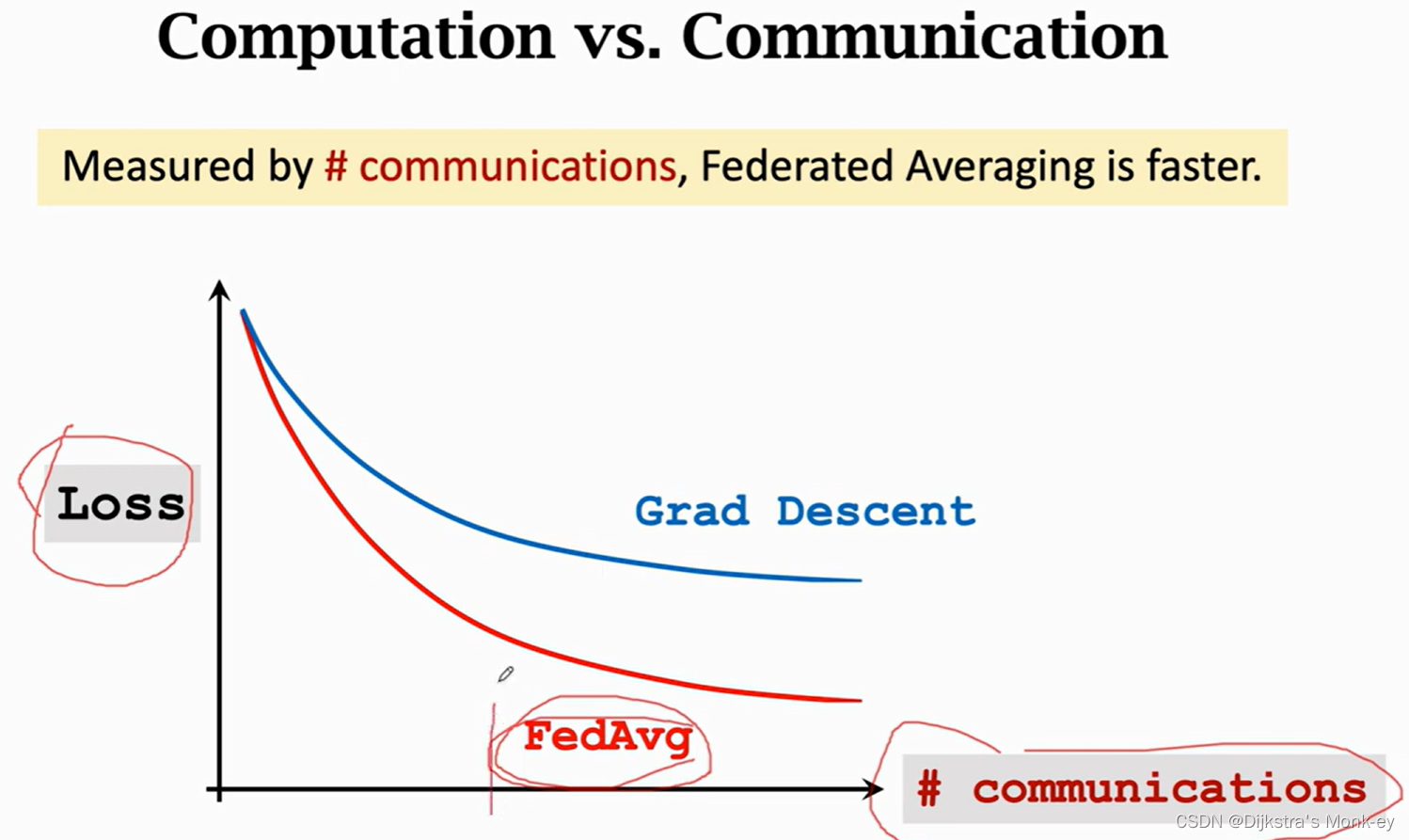
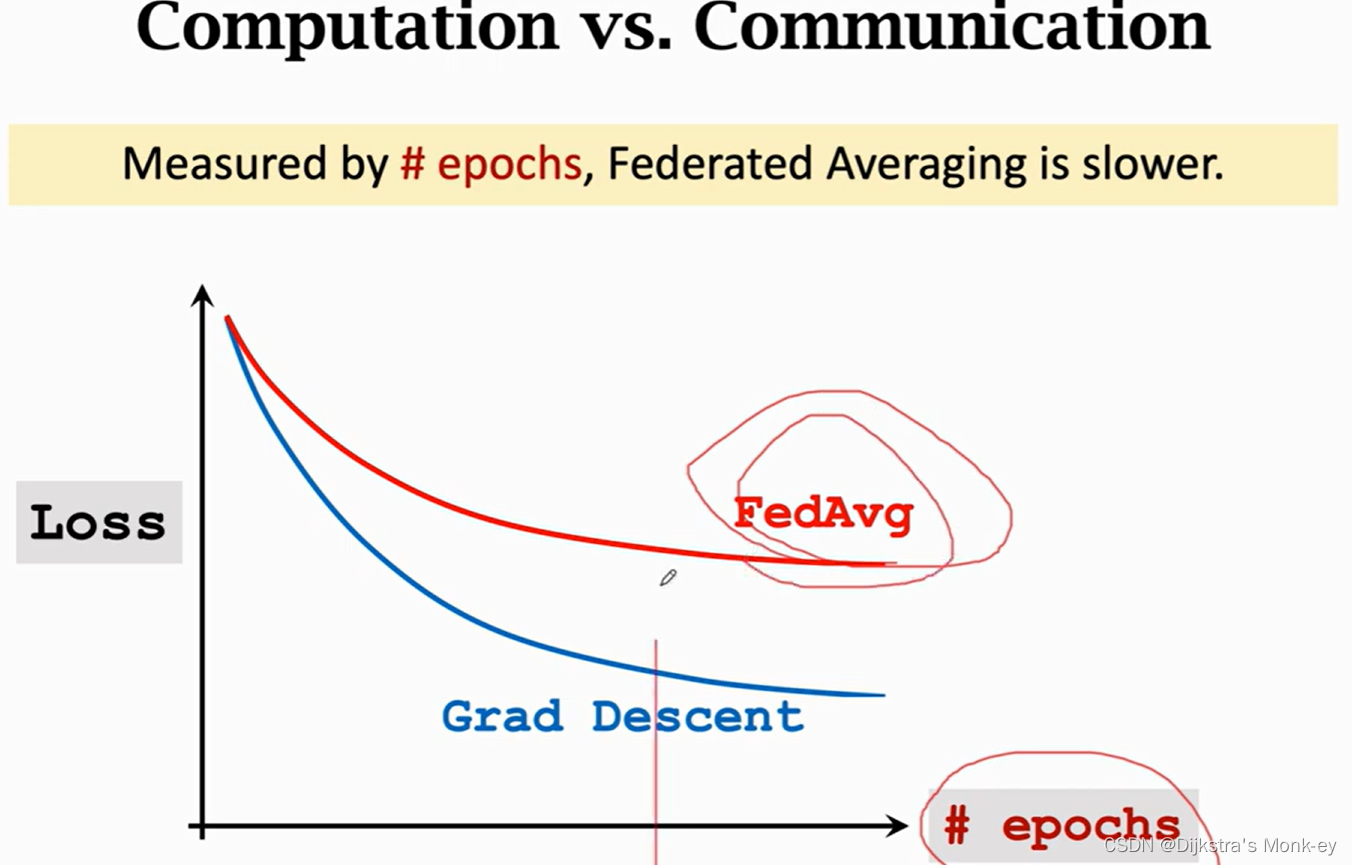
下面这两幅图很好地说明了Federated Averaging Algorithm通过更多的计算量,获取减少通信次数。
【3】证明了FedAvg收敛,而且不需要独立同分布的假设,说明了确实可以用FedAvg做联邦学习。

虽然数据没有离开用户设备,但是梯度被传播到服务器。梯度其实就是把数据做了一个函数变换,几乎携带了所有信息,因此根据梯度是可以反推出数据的。联邦学习中的隐私很容易泄露、遭到攻击。

梯度->用户属性
一种解决措施:利用Diferential Privacy可以往Gradient中加噪声,但是噪声过小不起作用,噪音过大又会影响模型训练学习的效果。
联邦学习的鲁棒性
让联邦学习可以抵御拜占庭错误和恶意的攻击。针对于分布式节点中出现故障节点的现象。如果有节点恶意对自己的数据和标签做修改,那么传给Server的数据就是错误、有害的。
攻击:
1、数据毒药攻击(Data poisoning attack)
worker节点可以将自己的数据、标签做小范围精心设计的修改或扰动,模型会犯一些很特别的错误。worker节点只要能看到模型参数,就可以把自己的模型和标签做一些恶意的扰动之后发送给Server,Server就会犯一些特别的错误或者形成后门。
2、模型毒药攻击(Model posoning attack)
联邦学习需要注意的问题:
1、通信效率算法。但绝大部分只能用在独立同分布的数据上。
2、隐私泄露的保护。随机矩阵变换(未必可行)
3、算法鲁棒性。每个用户不受控制,可能出现“拜占庭将军问题”。















 1381
1381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











