






我的服务器环境:
镜像:Miniconda conda3 || Python 3.8(ubuntu18.04) || Cuda 10.2
GPU:RTX 2080 Ti(11GB) * 1升降配置
CPU:12 vCPU Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50GHz
代码运行环境:
Python == 3.8.0; Torch == 1.12.1 + cu10.2; Torc
hvision == 0.13.1; PIL == 7.2.0
关键代码如下:
import torch.nn
import os
def main():
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
if torch.cuda.is_available():
device = torch.device('cuda')
else:
device = torch.device('cpu')
其中checkpoint = torch.load(args.checkpoint_file)
分析报错信息:
在服务器上找不到可用的GPU设备,只有CPU,提示你映射到CPU。
纠正错误的方法:
1.修改checkpoint = torch.load(args.checkpoint_file, map_location=torch.device('cpu'))则可用CPU运行代码,但这不是我们的最终目的。
2.在网上看了很多帖子,很多都说是cuda、nvidia驱动、pytorch版本不兼容的问题,可参考文章pytorch的问题:解决引用torch,但torch.cuda.is_available() 返回false_pytorch未解析的引用f-CSDN博客3.以下命令在在终端执行
conda list | grep torch:检查torch版本确实是1.12.1。

nvcc --version:查看 CUDA 的版本,输出为10.2.89。
nvidia-smi:查看驱动版本,输出为NVIDIA-SMI 525.89.02 Driver Version: 525.89.02 CUDA Version: 12.0 (其中查阅资料发现该驱动版本适应于cuda12.0,525.89.02 >= cuda10.2,此处是没问题的)。
综上通过查看官网没有发现cuda、nvidia驱动、pytorch版本不兼容的问题。
conda list查看依赖包cond cudatookit, cudnn都是存在的:
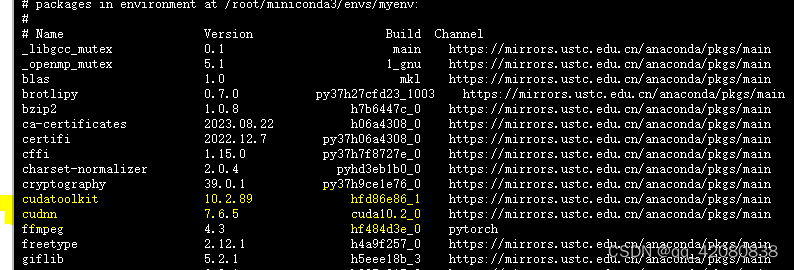
4.通过try.py文件写入以下命令并执行,来检查服务器是否存在可用GPU:
import torch
import os
print(torch.cuda.is_available())
from torch.backends import cudnn
print(cudnn.is_available())观察输出发现服务器的cuda是可用的,不存在版本兼容问题:
![]()
5.try.py代码查看可用的 GPU 设备:
import torch
import os
print(torch.cuda.is_available())
from torch.backends import cudnn
print(cudnn.is_available())
# 设置 PyTorch 的 CUDA_VISIBLE_DEVICES 环境变量
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# 获取可见的 GPU 设备列表
available_gpu_count = torch.cuda.device_count()
if available_gpu_count > 0:
print("Num GPUs Available: ", available_gpu_count)
for gpu_id in range(available_gpu_count):
print("GPU {}: {}".format(gpu_id, torch.cuda.get_device_name(gpu_id)))
else:
print("No GPUs available.")
# 在 PyTorch 中指定使用第一个 GPU
if available_gpu_count > 0:
device = torch.device("cuda:0")
# 在这里,PyTorch会尝试在第一个GPU上执行操作
processor = torch.nn.Sequential(
torch.nn.Linear(512, 512),
# 添加更多 PyTorch 操作
).to(device)
输出显示存在一台可用GPU:

发现关键代码处的问题:
def main():
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
if torch.cuda.is_available():
device = torch.device('cuda')
else:
device = torch.device('cpu')
你在设置CUDA_VISIBLE_DEVICES的时候指定了GPU设备为"1",这可能会导致混淆。通常情况下,当你设置了CUDA_VISIBLE_DEVICES,PyTorch就会在可见的GPU设备上运行,而不考虑其他未被指定的GPU。因此,如果你只有一个GPU,或者指定的GPU编号不正确,可能就会出现无法找到GPU的情况,最终执行了else分支。
确保你指定的CUDA_VISIBLE_DEVICES的值是正确的。如果你只有一个GPU,可以将其设置为"0",而不是"1"。
修改后的代码:
def main():
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
if torch.cuda.is_available():
device = torch.device('cuda')
else:
device = torch.device('cpu')
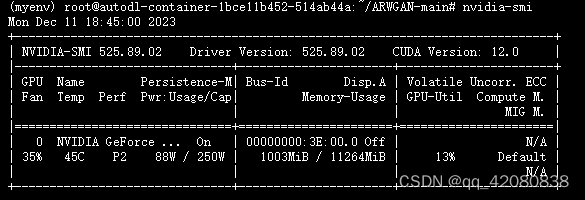
checkpoint = torch.load(args.checkpoint_file)问题解决,终端输入nvidia-smi,查看GPU利用率为 13%:

















 2273
2273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









