







Java乱码问题的记录与解决方案。
本文记录,本人在java中碰到的乱码的问题,及解决方案。供他人参考!
一、复制文件的乱码。
a,全局乱码:设置读写时候的编码
* FileReader是使用默认码表读取文件, 如果需要使用指定码表读取, 那么可以使用InputStreamReader(字节流,编码表)
* FileWriter是使用默认码表写出文件, 如果需要使用指定码表写出, 那么可以使用OutputStreamWriter(字节流,编码表)
BufferedReader br = //高效的用指定的编码表读
new BufferedReader(new InputStreamReader(new FileInputStream("UTF-8.txt"), "UTF-8"));
BufferedWriter bw = //高效的用指定的编码表写
new BufferedWriter(new OutputStreamWriter(new FileOutputStream("GBK.txt"), "GBK"));
int ch;
while((ch = br.read()) != -1) {
bw.write(ch);
}
br.close();
bw.close();
b,个别汉字的乱码(一般为最后一个字的乱码)
文件复制的时候不能用字节流:
fis = new FileInputStream(file);
bis = new BufferedInputStream(fis);
reader = new BufferedReader (new InputStreamReader(bis));
//之所以用BufferedReader,而不是直接用BufferedInputStream读取,是因为BufferedInputStream是InputStream的间接子类,
//InputStream的read方法读取的是一个byte,而一个中文占两个byte,所以可能会出现读到半个汉字的情况,就是乱码.
//BufferedReader继承自Reader,该类的read方法读取的是char,所以无论如何不会出现读个半个汉字的.
StringBuffer result = new StringBuffer();
while (reader.ready()) {
result.append((char)reader.read());
}
解决方案:其实java封装了copy文件的方法。 Files.copy
beginFilename:复制的文件 endFilename:复制的路径 两个都是文件的全路径
File compileClassFile=new File(beginFilename);
if(!compileClassFile.exists()){
list.add("未能找到ava文件");
return list;
}
File outClassFile=new File(endFilename);
/**option: ATOMIC_MOVE 原子性的复制
COPY_ATTRIBUTES 将源文件的文件属性信息复制到目标文件中
REPLACE_EXISTING 替换已存在的 文件 */
Files.copy(compileClassFile.toPath(),
outClassFile .toPath(),
StandardCopyOption.REPLACE_EXISTING);
二、java 程序中的汉字的编码转换
说明:先清楚,需要转换的字符串是什么编码格式。然后用相应的编码,将目标字符串用此编码,解码为二进制的。再对这个二进制码,进行需要的编码,进行转化。
作用:将ISO-8859-1的汉字编码,转成UTF-8。
n_title是目标字符串。
n_title=new String(n_title.getBytes("ISO-8859-1"), "UTF-8");
三、Request与Response的乱码
request :客户端向服务器端发送
get请求:传递数据时在url地址栏中就已经进行过编码了,所以我们得到的可能是乱码.tomcat得到这些数据时,在使用request.getParamter方法时,默认使用ISO-8859-1去解码.
解决方案一:代码转码
String username = request.getParamter(“username”);
username = new String(username.getBytes(“ISO-8859-1”),”UTF-8”);
解决方案二:在tomcat的server.xml中设置
< Connector connectionTimeout="20000" port="8080" protoco="HTTP/1.1" >
post请求:传递数据时,post以流的方式,我们可以指定它的编码.在request.getParamter之前加上
Request.setCharacterEncoding(“UTF-8”);
此方法是设置请求体里面的文字编码,对get方法没有作用,因为get方法的参数是在url中.
*response: 服务器向客户端返回数据
以字符流输出: response.getWriter().write(“111”); 此方法默认写出去的编码为iso-8859-1
解决:response.setCharacterEncoding(“UTF-8”);//设置写出去的编码,此编码要与浏览器相对应
以字节流输出: response.getOutputStream().write(“我爱编程”.getBytes());
String 类中,getBytes()方法默认使用UTF-8编码
如果想让服务器端出去的中文,在客户端能够正常显示,只要保证一点,即:响应出去的代码和浏览器解析时使用的代码一致。
解决:response.getOutputStream().write(“我爱编程”.getBytes(“UTF-8”));//默认使用utf-8
不管是字节流还是字符流,只要是response的数据,统一使用下面的,就没有问题
response.setHeader("Content-Type","text/html;charset=UTF-8");
四、XML的乱码
1、文档创建的时候的默认的编码
事件:文档声明:<?xml Version=”1.0” encoding=”utf-8”?>
在浏览器解析的会出现乱码.
原因:文档创建时,默认选择GBK编码,文档储存的编码与解析的不一样,出现的乱码
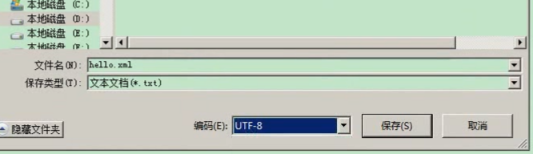
解决方案:一、如图将编码改成gbk,或者ANSI(本地编码,默认为GBK)
解决方案:二、将文档声明改成 <?xml Version=”1.0” encoding=”gbk”?>














 2497
2497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









