







 本文通过实例探讨NMF(非负矩阵分解)降维的本质,分析不同数据分布对其结果的影响,并对比PCA,揭示NMF在处理相似数据分布时的优势及局限。
本文通过实例探讨NMF(非负矩阵分解)降维的本质,分析不同数据分布对其结果的影响,并对比PCA,揭示NMF在处理相似数据分布时的优势及局限。
一、NMF的本质
1.当数据完全一样时
# 将如下数据的行向量用NMF降到3维,初始化策略全部用nndsvd,不能用random,下同
X=np.array([[5,5,5,5],
[5,5,5,5],
[5,5,5,5],
[5,5,5,5]])
结果是这样的:

2.当数据分布全部递增时
# 原数据
X=np.array([[1,2,3,4],
[1,2,3,4],
[1,2,3,4],
[1,2,3,4]])
结果是这样的:
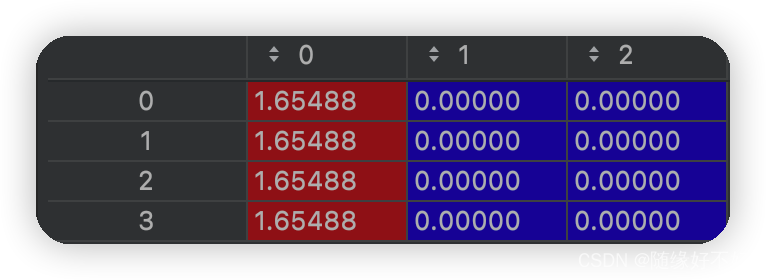
可以得出结论:
当原数据分布完全一样时,降维后数据的特征分布会全部趋向于第一个特征。
3.分布一样,将数字增大
# 原数据
X=np.array([[10,20,30,40],
[1,2,3,4],
[1,2,3,4],
[1,2,3,4]])
结果是这样的:

可以得出结论:
在分布相同的情况下,原数据的数字越大,降维后数据的数字也越大
4.三个分布相同,第四个有差异
# 原数据
X=np.array([[1,2,3,4],
[1,2,3,4],
[1,2,3,4],
[1,2,3,5]])
结果:
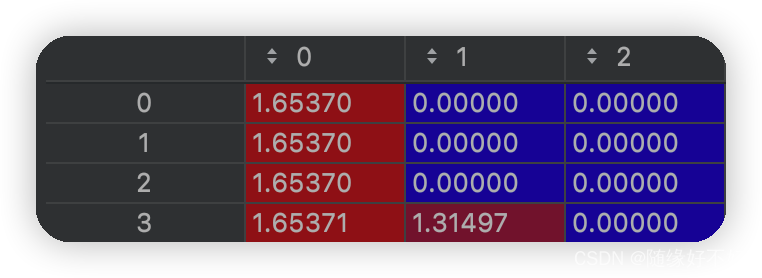
第4个数据在第一个特征的基础上还增加了第二个特征1.31,比例为1:0.79。
其他三个数据全都只有第一个特征。
5.将5改成6
X=np.array([[1,2,3,4],
[1,2,3,4],
[1,2,3,4],
[1,2,3,6]])
结果:
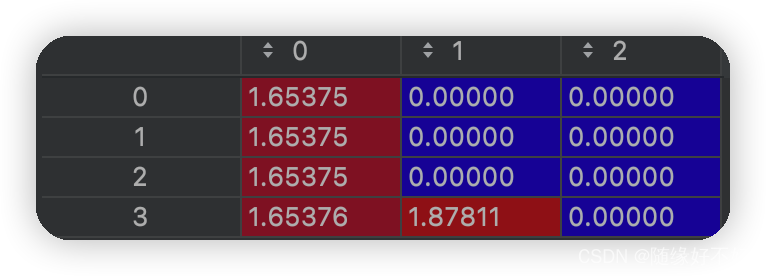
可以看到,降维后的第四个数据的第二个特征变大了,变为1.87,比例为1:1.13。
6.当把6增加到10
# 原数据
X=np.array([[1,2,3,4],
[1,2,3,4],
[1,2,3,4],
[1,2,3,10]])
结果:

反而是前三个数据多出了特征二。
可以得出结论:
NMF会先找原数据的主流分布。这个主流分布受数量和大小的影响。比如实验4中,主流分布就是前三个数据的分布。而在实验4中,当第四个原数据的最后一位增加到10之后,虽然他只有一个人,但他比其他三个人的数据都要大,就得听他的,主流分布就是他的分布。
- 原数据越偏向于主流分布,降维后的数据就越趋向于一个特征;
- 反之,就会出现第二个特征。
7.把后两个数据全部搞乱
# 原数据
X=np.array([[1,2,3,4],
[1,2,3,4],
[2,2,1,4],
[2,3,1,0]])
结果:

可以看到这时候的分布已经比较混乱了。前两个数据无疑是主流分布,但他们的优势已经不不大了,所以他们也出现了少许的第二特征:0.00886。
后面两个特征相对于主流分布来说已经比较混乱,所以分别出现了第三和第二特征。
NMF降维的本质
- 先定主流分布,取决于各个数据分布的数量以及数据的相对大小之间的博弈。某一分布的数据越多,越有可能成为主流分布;该数据的值越大,越有可能成为主流分布;
- 和主流分布越相似的原数据,降维后的特征会趋向于特征一。反之会出现更多的特征;
- 和主流分布有小的差异,但有差异的部分差得特别大的分布(如实验6),则降维后的数据,特征数量不一定多,但特征一和其余特征的比值会很大;
二、以鸢尾花数据为例进行分析
将鸢尾花数据用NMF降到2维,提取矩阵W:
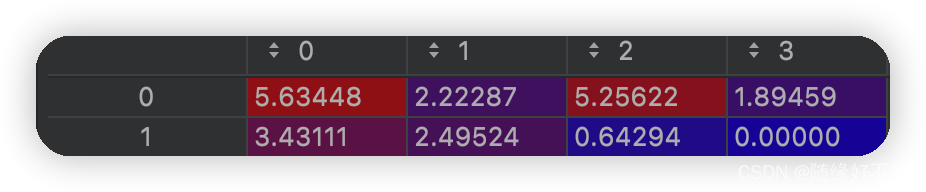
很明显第3、4个原特征被列为了主流分布,我们还观察到第1个原特征和第2个原特征,其降维后的特征的比例分别是:
5.63:3.43
2.22:2.49
很明显第一个比值更大,也就是说第1个原特征和第3、4个特征的分布更相似。我们知道对于鸢尾花数据,其第3、4个特征的效果是更较好的,所以第一个原特征应该好与第二个原特征才对。
用实验证明:
用第1个特征聚类后的nmi:

用第2个特征聚类后的nmi:

的确如此!
三、和PCA的比较
PCA是看方差。将原数据的坐标轴变换方向,使得丢掉一定个数的维度之后,方差能够最大。
NMF是看分布。分布越相似的数据,降维后分布越相似。
如果原数据中有一些分布不好,但是数值又大的特征存在,NMF是会受影响的。
在聚类算法中,NMF比较依赖归一化策略。

















 797
797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









