






序言:
因为这节,就要开始求最短路径了,开始涉及到图的存储问题,我先说一下具体的算法思想:
求最短路径主要有两种算法:
- 求单源最短路径,即求从起点,到图上任意一点的距离最小,这个是迪杰斯特拉算法,存储用邻接表存储。
- 求任意两点间的最短路径,这个是弗洛伊德算法,存储用邻接矩阵来存储。
首先说一下弗洛伊德算法:
弗洛伊德算法目的是求任意两点间的最短路径。


总结下来就是:将图用邻接矩阵来存储,然后依次考察【1,N】这些节点,依次考察是否可以加入路径中构成当前的最短路径。例如:当前在考察节点ans[ i ] [ j ] ,考察加入节点1时的情况,这时我们就要算ans[ i ] [ 1 ] + ans[ 1 ] [ j ] 和上面的那个距离哪个短,然后选择短的来更新ans[ i ] [ j ] 。
普通的算法代码:这个算法代码是没有考虑优化的情况

从图中可以明显的看到,数据结构采用了三维数组,每一个当前加入节点的k的矩阵生成,都需要k-1状态下的矩阵,数据量庞大。但是考虑一个问题:
对于一个特定的元素ans[ i ] [ j ] 当我们向其中考察任意节点的时候,它的计算形式如图所示:
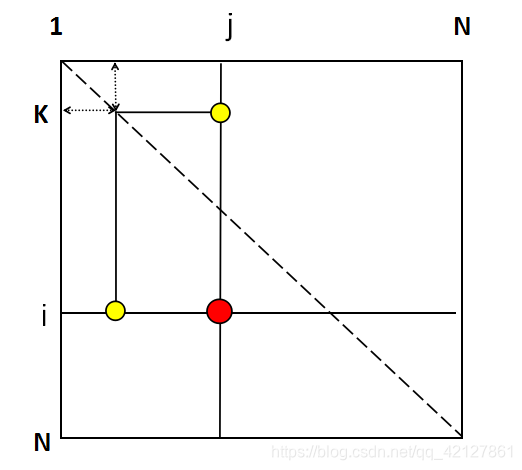
当我们考察红色的点,且经过K点时,红色的点是由黄色的点决定的,而对于单独考虑黄色的点,它在本次更新K节点的时候,它的值是由ans[i][k]+ans[k][k]与ans[i][k]所决定的,而ans[k][k]=0,故相当于未变,所以对于本次更新,它保持不变,进一步推广,即当我们考察任意一个节点M加入路径时,以M节点为横纵的两条线上的所有的矩阵值均不变,而恰巧,更新每一个矩阵中的值的时候,就是基于这两条线的所以这时候我们就可以把三维矩阵中的那个表示K的那一维去掉,使原来的矩阵降维成二维矩阵。
如:

此时代码极其简单。
第一题:



思路: 这就简单了,就是简单地弗洛伊德算法。
代码如下:
#include<stdio.h>
int ans[101][101];
int main(){
int n,m;
freopen("in.txt","r",stdin);
while(scanf("%d%d",&n,&m)!=EOF){
if(n==0&&m==0)break;
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
ans[i][j]=-1;//矩阵初始化,用-1代表无穷
}
ans[i][i]=0;//使得每一个节点到自己距离为0;
}
while(m--){
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
ans[a][b]=ans[b][a]=c;//对于无向图邻接矩阵关于主对角线对称
}
for(int k=1;k<=n;k++){
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
if(ans[i][k]==-1||ans[k][j]==-1){
continue;
}
if(ans[i][j]==-1||ans[i][j]>ans[i][k]+ans[k][j]){
ans[i][j]=ans[i][k]+ans[k][j];
}
}
}
}//弗洛伊德算法,时间复杂度 O(n^3)
printf("%d\n",ans[1][n]);
}
return 0;
}
注: 弗洛伊德算法,当两节点之间有多余的边时,选择权值小的边写入邻接矩阵。
下面介绍一下迪杰斯特拉算法:
所谓迪杰斯特拉算法就是求单源对短路径的问题,如上题,因为是求1到n之间的最短路径,如果用弗洛伊德算法,未免有点浪费。故采用迪杰斯特拉算法: 迪杰斯特拉算法维持一个当前已知的最短路径的数组。并不断更新。
如下:Dis [ n ] 数组

每一个元素都存储源点到当前节点的路径的最小值。而每一次选择节点,就选择当前节点里面未被选过的节点的最小值,如上图,假设Dis[1]未被选过,则此次就选择节点1,如果节点1已经被选择了,则此时只能选择节点4,即Dis[4]作为当前选择的节点。选择节点后,更新Dis数组,如果从当前选择的节点到Dis数组中未被走过的节点的长度小于原来的数值,则更新。依次下去,知道图中所有点都已经被选择过为止。
如上题:用迪杰斯塔拉算法解法如下:
#include<stdio.h>
#include<vector>
using namespace std;
struct E{
int next;
int c;
};
vector<E> edge[101];//使用邻接表形式来存储图
//模板代码
bool mark[101];
int Dis[101];
int main(){
int n,m;
freopen("in.txt","r",stdin);
while(scanf("%d%d",&n,&m)!=EOF){
if(n==0&&m==0)break;
for(int i=1;i<=n;i++)edge[i].clear();
while(m--){
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
E tmp;
tmp.c=c;
tmp.next=b;
edge[a].push_back(tmp);
tmp.next=a;
edge[b].push_back(tmp);
}
//迪杰斯特拉模板算法开始
for(int i=1;i<=n;i++){
Dis[i]=-1;
mark[i]=false;
}//初始化所有节点都没有被选中
Dis[1]=0;
mark[1]=true;
int newP=1;//选中源点
for(int i=1;i<n;i++){
//因为每一个点都需要被选中,而此时源点已经被选中,所以只需要循环n-1次
for(int j=0;j<edge[newP].size();j++){
int t=edge[newP][j].next;
int c=edge[newP][j].c;
if(mark[t]==true)continue;//如果当前节点已经被选中过了,则跳过
if(Dis[t]==-1||Dis[t]>Dis[newP]+c){
Dis[t]=Dis[newP]+c;
}//根据选中点来更新Dis数组
}
int min=123123123;
for(int j=1;j<=n;j++){
if(mark[j]==true)continue;
if(Dis[j]==-1)continue;
if(Dis[j]<min){
min=Dis[j];
newP=j;
}
}
//每一次更新后,均遍历一次Dis数组,选择可到达的,并且未被选中的节点作为下一个选中点
mark[newP]=true;
}//模板算法结束
printf("%d\n",Dis[n]);
}
return 0;
}
总之:迪杰斯特拉的核心就是一个Dis数组,思想是:在更新未被选中的节点的值,选择未被选中的节点中的距离最小值。
第二题:


思路: 这道题与上一题的区别仅在于,多了一个开销问题,而这个也仅仅只是加一个条件而已。
代码如下:
#include<stdio.h>
#include<vector>
using namespace std;
struct Edge{
int next;
int cost;
int length;
};
vector<Edge> edge[1001];
int Dis[1001];
bool mark[1001];
int Cost[1001];
int main(){
int n,m;
freopen("in.txt","r",stdin);
while(scanf("%d%d",&n,&m)!=EOF){
if(n==0&&m==0)break;
for(int i=1;i<=n;i++){
edge[i].clear();
Dis[i]=-1;
Cost[i]=0;
mark[i]=false;
}
for(int i=0;i<m;i++){
int a,b,d,p;
scanf("%d%d%d%d",&a,&b,&d,&p);
Edge tmp;
tmp.next=b;
tmp.length=d;
tmp.cost=p;
edge[a].push_back(tmp);
tmp.next=a;
edge[b].push_back(tmp);
}
int s,t;
scanf("%d%d",&s,&t);
Dis[s]=0;
mark[s]=true;
Cost[s]=0;
int newP=s;
for(int i=1;i<n;i++){
for(int j=0;j<edge[newP].size();j++){
int next=edge[newP][j].next;
int length=edge[newP][j].length;
int cost=edge[newP][j].cost;
if(mark[next]==true)continue;
if(Dis[next]==Dis[newP]+length&&Cost[next]>Cost[newP]+cost){
Cost[next]=Cost[newP]+cost;
}//当路径长度一样,则判断开销大小
if(Dis[next]=-1||Dis[next]>Dis[newP]+length){
Dis[next]=Dis[newP]+length;
Cost[next]=Cost[newP]+cost;
}
}
int min=123123123;
for(int i=1;i<=n;i++){
if(mark[i]==true)continue;
if(Dis[i]==-1)continue;
if(Dis[i]<min){
min=Dis[i];
newP=i;
}
}
mark[newP]=true;
}
printf("%d %d",Dis[t],Cost[t]);
}
return 0;
}














 161
161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









