







1、异常检测
实现一个异常检测算法来检测服务器计算机中的异常行为。这些特性测量每台服务器的吞吐量(mb/s)和响应延迟(ms)。在这个数据集中,你将拟合一个高斯分布,然后找到概率很低的值,因此可以被视为异常。然后,将异常检测算法应用到具有多个维度的更大的数据集。
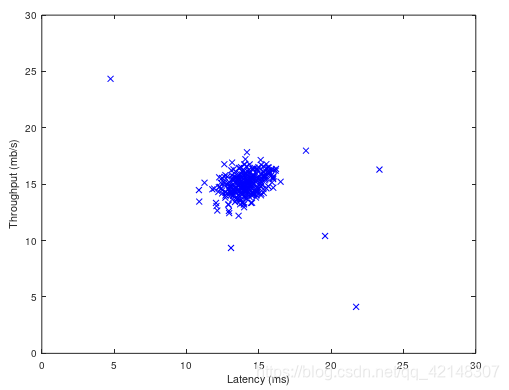
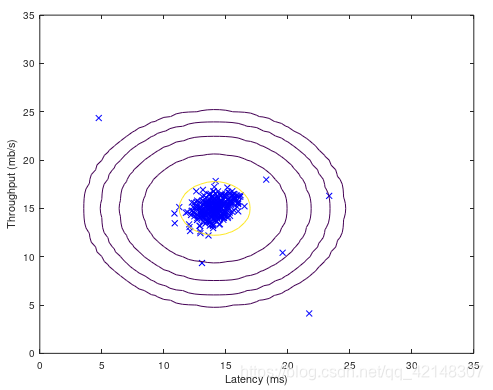
将所需要的数据集ex8data1.mat复制到D:\Machine Learning\ex8目录下,然后利用plot函数可视化数据集:
1.1高斯分布
要执行异常检测,首先需要使模型适合数据的分布。
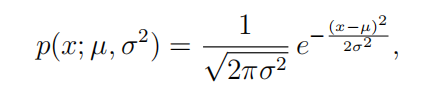
1.2估计高斯参数
使用以下公式估计第i个特征的参数(µi,σi2):
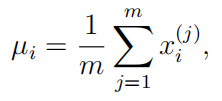
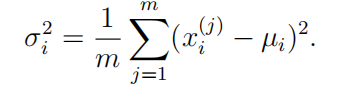
在当前目录下建立estimateGaussian.m文件,
function [mu sigma2] = estimateGaussian(X)
%返回均值和方差
[m, n] = size(X);
mu = zeros(n, 1);
sigma2 = zeros(n, 1);
for i = 1:n
mu(i) = sum(X(:, i)) / m;
sigma2(i) = sum((X(:, i) - mu(i)) .^ 2) / m;
end;在当前目录下建立multivariateGaussian.m文件。该函数的作用就是计算出每个个例分布的概率值:
function p = multivariateGaussian(X, mu, Sigma2)
%返回每个个例预测的概率值
k = length(mu);
%个例数
if (size(Sigma2, 2) == 1) || (size(Sigma2, 1) == 1)
Sigma2 = diag(Sigma2);
%如果该参数是矩阵,构造一个对角矩阵。
end
X = bsxfun(@minus, X, mu(:)');
p = (2 * pi) ^ (- k / 2) * det(Sigma2) ^ (-0.5) * ...
exp(-0.5 * sum(bsxfun(@times, X * pinv(Sigma2), X), 2));
%pinv求矩阵的逆矩阵,times数组乘,minus减
end根据estimateGaussian函数返回的均值和方差,以及建立网格点上每个点对应的概率值,可视化拟合的高斯分布的轮廓。在当前目录下建立visualizeFit.m文件:
function visualizeFit(X, mu, sigma2)
[X1,X2] = meshgrid(0:.5:35);
%生成网格采样点,x1,x2轴有35*2个点,一共70*70个点
Z = multivariateGaussian([X1(:) X2(:)],mu,sigma2);
%得到每个点对应的概率值
Z = reshape(Z,size(X1));
%把Z数据重组,按照X1的维数重组35*35
plot(X(:, 1), X(:, 2),'bx');
%先画出个例点
hold on;
if (sum(isinf(Z)) == 0)
%isinf(Z)判断数组元素是否无界,有界就返回0
contour(X1, X2, Z, 10.^(-20:3:0)');
%前三个参数分别对应x,y,z,等高线在10的-20次方和10的0次方之间,每次指数增加3来画
end
hold off;
end
1.3选择阈值,ε
你已经估计了高斯参数,你可以研究在这个分布下哪些例子有很高的概率,哪些例子有很低的概率。例如概率很低更可能是我们数据集中的异常。确定哪些示例是异常的一种方法是根据交叉验证集选择一个阈值ε,使用交叉验证集中的F1分数来选择阈值ε。
数据集1中yval=1对应于异常示例,yval=0对应于正常示例。
在当前目录下建立selectThreshold.m文件,返回两个值:第一个是选定的阈值ε。如果示例x具有低概率p(x)<ε,则将其视为异常。该函数还应该返回F1分数,对于许多不同的ε值,您将通过计算当前阈值正确和错误地分类多少个示例来计算结果F1分数。
F1分数使用查准率(prec)和召回率(rec)计算:
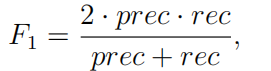
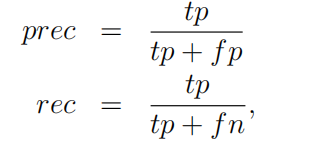
function [bestEpsilon bestF1] = selectThreshold(yval, pval)
%返回值第一个是最佳的ε,第二个是相对应的F1值。
%第一个参数是Xval坐标点是否为异常点,第二个是Xval计算得来的概率值
bestEpsilon = 0;
bestF1 = 0;
F1 = 0;
stepsize = (max(pval) - min(pval)) / 1000;
%设置ε增加的步长
for epsilon = min(pval):stepsize:max(pval)
cvP = pval < epsilon;
tp = sum((yval == 1) & (cvP == 1));
%预测为真结果为真
fp = sum((yval == 0) & (cvP == 1));
%预测为真,结果为假
fn = sum((yval == 1) & (cvP == 0));
%预测为假,结果为真
prec = tp / (tp + fp);
%查准率
rec = tp / (tp + fn);
%召回率
F1 = 2 * prec * rec / (prec + rec);
if F1 > bestF1
bestF1 = F1;
bestEpsilon = epsilon;
end
end
end在Octave中调用该函数,同时将出现异常的点标记出来:
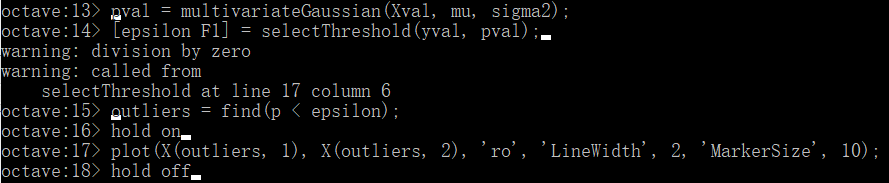


您应该看到epsilon的值约为8.99e-05。
1.4高维数据集
之前我们用的X是二维的,现在我们将ex8data2.mat数据集复制到当前目录下,该数据集X是11维的,同样地进行相关一致的操作:
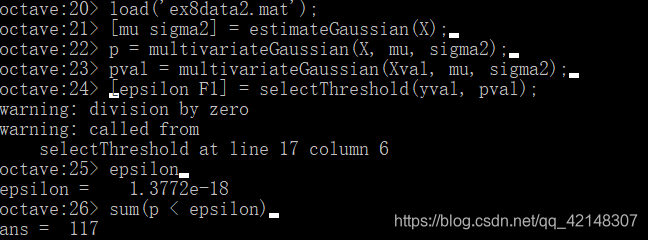
估计高斯参数(µi和σi2),评估用于估计高斯参数的训练数据X的概率,并对交叉验证集Xval进行评估。最后,利用selectThreshold找到最佳阈值ε。你应该看到ε值约为1.38e-18,并发现117个异常。
2、 推荐系统
将实现协作过滤学习算法并将其应用于电影数据集收视率。这个数据集由1到5的等级组成。这个数据集有nu=943个用户,nm=1682部电影。
在当前目录下复制ex8_movies.mat文件,加载文件,然后可视化数据集:
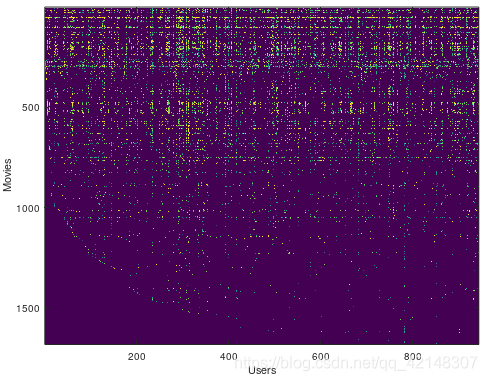
在当前目录下建立cofiCostFunc.m文件,该函数计算协作fitlering目标函数和梯度。在实现成本函数和梯度之后,在当前目录下建立了fmincg.m文件来学习协同过滤的参数。这两个函数在之前均实现过,不具体详解。
2.1电影分级数据集
矩阵R是一个二值指标矩阵,其中R(i,j)=1,如果用户j给电影i评分,则R(i,j)=0。协同过滤的目的是预测用户尚未评分的电影的收视率,即R(i,j)=0的条目。这将允许我们向用户推荐预测收视率最高的电影。
在Octave中加载ex8_movieParams.mat文件,为了加速,我们缩小了数据集使用大小:
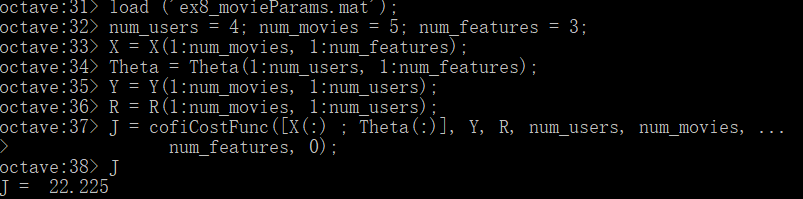
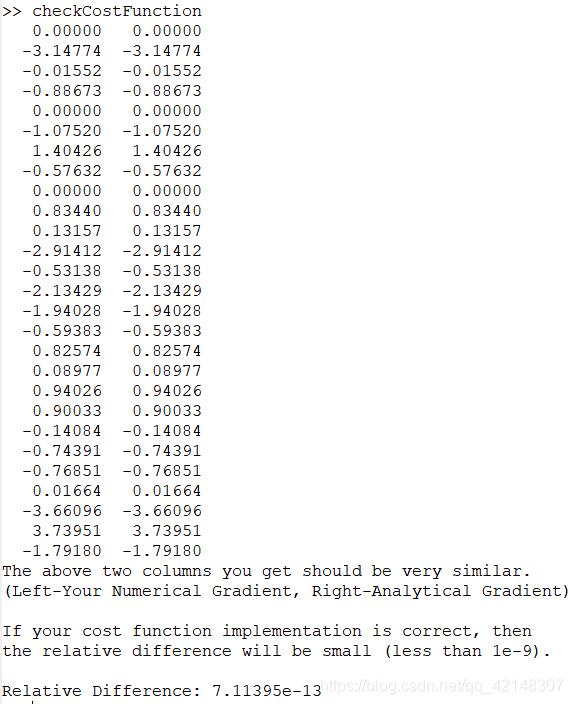
运行一个梯度检查(checkCostFunction)以数字方式检查梯度,在当前目录下建立checkCostFunction文件,这个之前也实现过。
在checkCostFunction函数中需要调用computeNumericalGradient,此函数作用就是求出相应点的数学公式计算的梯度,之前实现过。
2.3学习电影推荐
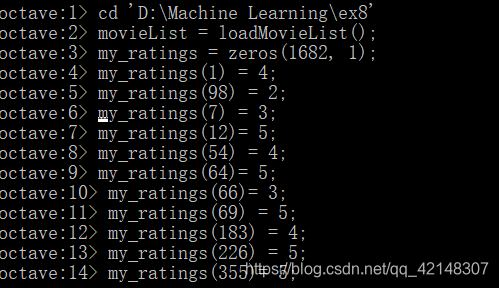
可以输入自己的电影首选项,以便稍后算法运行时,您可以获得自己的电影推荐!可以在文件movie中找到数据集中所有电影及其编号的列表idx.txt文件.
首先将电影列表文件movie_ids.txt复制到当前目录下,并且在当前目录下建立loadMovieList.m文件来加载电影列表:
function movieList = loadMovieList()
fid = fopen('movie_ids.txt');
n = 1682;
movieList = cell(n, 1);
%创建一个n*1数组,每个元素存放一个字符串
for i = 1:n
line = fgets(fid);
%获得一个字符串
[idx, movieName] = strtok(line, ' ');
%碰到空格符作为字符串分隔符,每个字符串电影前面的序号给idx,后面字符串给movieName
% Actual Word
movieList{i} = strtrim(movieName);
%strtrim从字符串中删除前导和尾随空白字符
end
fclose(fid);
end加载相应的电影列表后,给一部分电影评级:
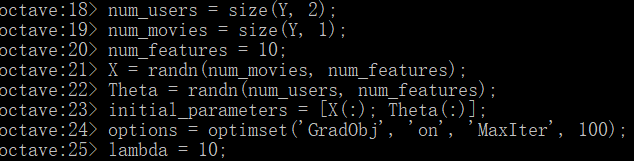
将ex8_movies.mat文件复制到当前目录下,该文件R指1682个电影被943位用户是否评分的状况。Y指1682个电影被943位用户评级状况。加上刚刚自己评级的部分电影,Y包含的用户数就变成了944位。

先使用随机初始化的矩阵来训练theta矩阵:

在当前目录下建立normalizeRatings.m文件,完成均值一体化处理:
function [Ynorm, Ymean] = normalizeRatings(Y, R)
%对没有任何评分的矩阵进行均值一体化处理
[m, n] = size(Y);
Ymean = zeros(m, 1);
Ynorm = zeros(size(Y));
for i = 1:m
idx = find(R(i, :) == 1);
Ymean(i) = mean(Y(i, idx));
Ynorm(i, idx) = Y(i, idx) - Ymean(i);
end
end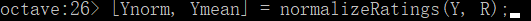

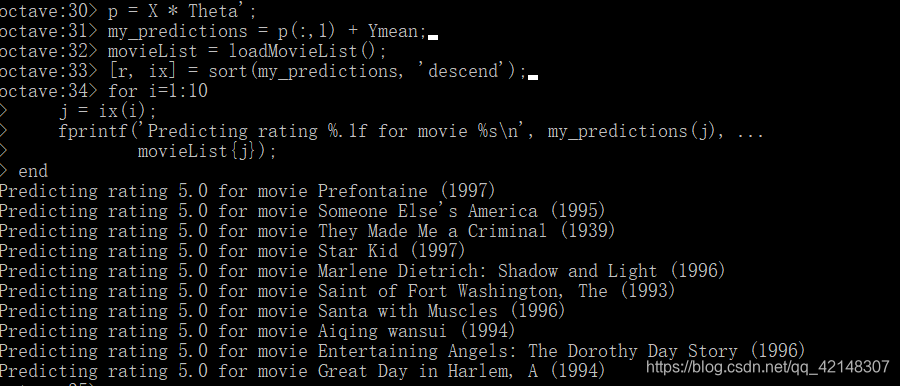
现在来根据用户打分的电影的评级以及训练出的theta矩阵,来预测用户没有没有评级电影的评级,选出预测的最高的10部电影评级,来向用户推荐10部电影,用户打分在第一列:
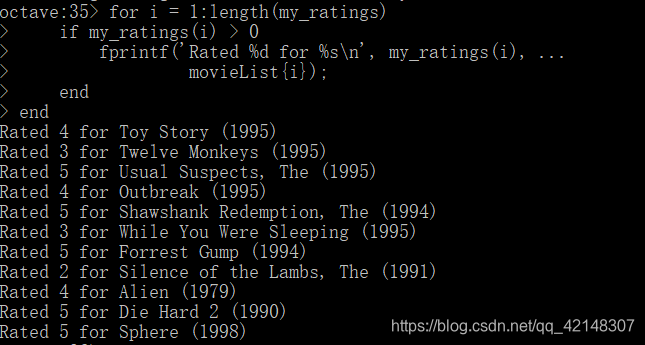
来看一下自己打过分的电影,进行比较:
















 3238
3238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











