







一、需求导向:
做这个python处理XML的原因是当我写完测试脚本上传git的时候,一位国外审核(review)的同事认为我的测试脚本用XML传参的格式在后期需求变动或这其他人接手我的脚本之后可能会出现一些问题一致性和兼容性的问题。并且脚本重复的改动点基本是一样的,这种重复的工作完全就是浪费时间。虽然我连续问了几个Why,我试图说服他不去改,但是最后我还是妥协了,虽然我还是坚信我的XML传参不会有问题....., 最后我选择使用python来完成这个重复工作,算是物尽其用了。
期望如下:
1、XML
2、测试case
testcase Basic_test_case_ITS4_FD_0x134()
{
Basic_test_case(DTC_ADAS_3EA_5CF_134_2D2_09F_562_6B2,CAN_TIMEOUT_ADAS_A06SC_FD_134,2000.0,"TC_1","Basic_test_case_ITS4_FD_0x134");
}
testcase Basic_test_case_ITS4_FD_0x3EA()
{
Basic_test_case(DTC_ADAS_3EA_5CF_134_2D2_09F_562_6B2,CAN_TIMEOUT_ADAS_A08SC_FD_3EA,2000.0,"TC_2","Basic_test_case_ITS4_FD_0x3EA");
}
testcase Basic_test_case_ITS4_FD_0x5CF()
{
Basic_test_case(DTC_ADAS_3EA_5CF_134_2D2_09F_562_6B2,CAN_TIMEOUT_ADAS_A09SC_FD_5CF,2000.0,"TC_3","Basic_test_case_ITS4_FD_0x5CF");
}虽然在XML中看起来就只是小小的变动,但是我原本XML需要传输的参数就必须全部迁移到CAPL脚本中,需要完成的量也比较大。
二、方法分析和准备:
CAPL测试case简单介绍
1、众所周知在CANoe中调用在CAPL中写好的测试case可以有3种方法, 最常用的是直接在CAPL的main函数中调用测试case如下:
testcase Basic_test_case_ITS4_FD_0x134()
{
Basic_test_case(DTC_ADAS_3EA_5CF_134_2D2_09F_562_6B2,CAN_TIMEOUT_ADAS_A06SC_FD_134,2000.0,"TC_1","Basic_test_case_ITS4_FD_0x134");
}
testcase Basic_test_case_ITS4_FD_0x3EA()
{
Basic_test_case(DTC_ADAS_3EA_5CF_134_2D2_09F_562_6B2,CAN_TIMEOUT_ADAS_A08SC_FD_3EA,2000.0,"TC_2","Basic_test_case_ITS4_FD_0x3EA");
}
testcase Basic_test_case_ITS4_FD_0x5CF()
{
Basic_test_case(DTC_ADAS_3EA_5CF_134_2D2_09F_562_6B2,CAN_TIMEOUT_ADAS_A09SC_FD_5CF,2000.0,"TC_3","Basic_test_case_ITS4_FD_0x5CF");
}
void MainTest ()
{
Basic_test_case_ITS4_FD_0x134();
Basic_test_case_ITS4_FD_0x3EA();
Basic_test_case_ITS4_FD_0x5CF()
}2、第二种就是使用XML函数来调用你在CAPL中写好的testcasse,使用XML的好处是可以直接方便的传递你想要传递的参数,而且在下次需求有变更的时候你也可以直接打开XML更改参数值就行,而不用再去看CAPL文件,如下是个例子
<testmodule title="Development - Requirements" version="1.0">
<variants>
<variant name="Basic">Development - Requirements</variant>
</variants>
<preparation>
<initialize title="">
</initialize>
</preparation>
<testgroup title="Test cases" variants="Basic">
<capltestcase title="ITS4_FD_0x134" name="Basic_test_case">
<caplparam name="eDTC" type="int">0xE15287</caplparam>
<caplparam name="eDEM" type="int">97</caplparam>
<caplparam name="iJT2Time" type="float">2000.0</caplparam>
</capltestcase>
<capltestcase title="ITS4_FD_0x3EA" name="Basic_test_case">
<caplparam name="eDTC" type="int">0xE15287</caplparam>
<caplparam name="eDEM" type="int">21</caplparam>
<caplparam name="iJT2Time" type="float">2000.0</caplparam>
</capltestcase>
<capltestcase title="ITS4_FD_0x5CF" name="Basic_test_case">
<caplparam name="eDTC" type="int">0xE15287</caplparam>
<caplparam name="eDEM" type="int">22</caplparam>
<caplparam name="iJT2Time" type="float">2000.0</caplparam>
</capltestcase>
</testgroup>
<completion>
</completion>
</testmodule>3、第三种则是用.net的方式调用,这种方法暂时还没研究过,有兴趣请自学~
分析准备工作
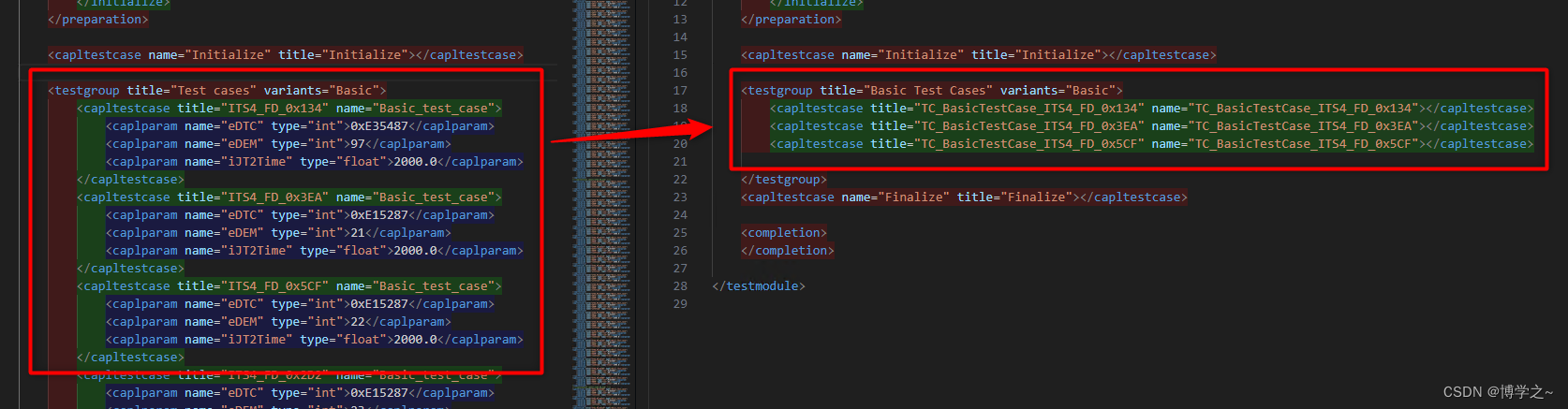
1、需要通过读取XML中相关参数名进行拼接和匹配工作,期望结果如上第一种方法,目前是第二种方法,可以看到在一中的case 名字是二中capltestcase 的属性 title+name,一中的第一个参数是二中第二个属性DTC号将要对应其对应的DTC name,一中的第二个参数是二中第三个属性DEM号对应的DEM name, 一中的第二个参数是二中第四个时间参数iJT2Time。
2、安装python包
在python安装目录下找到到文件夹scripts并复制路径,执行按win+R执行cmd命令,用cd 命令跳到刚复制的文件夹,后执行pip安装python包 et-xmlfile,安装完成准备结束。命令如下
pip install et-xmlfile三、处理xml的函数命令操作介绍
1.导入包并打开xml
import xml.etree.ElementTree as ET
tree = ET.parse(xmlfilepath)
root = tree.getroot()2、查找XML元素所有直接子节点
for n in root:
print(n, n.tag , n.attrib, n.items())
'''结果
<Element 'variants' at 0x000001B570BF54A0> variants {} []
<Element 'testgroup' at 0x000001B570BF5590> testgroup {'title': 'Test cases', 'variants': 'Basic'} [('title', 'Test cases'), ('variants', 'Basic')]
<Element 'capltestcase' at 0x000001B570BF59F0> capltestcase {'name': 'Finalize', 'title': 'Finalize'} [('name', 'Finalize'), ('title', 'Finalize')]
<Element 'completion' at 0x000001B570BF5A40> completion {} []
'''
3、便利所有子节点包含孙子节点
for n in root.iter():
print(n, n.tag)
'''结果
<Element 'testmodule' at 0x00000273EB4754A0> testmodule
<Element 'variants' at 0x00000273EB4754F0> variants
<Element 'variant' at 0x00000273EB475540> variant
<Element 'testgroup' at 0x00000273EB4755E0> testgroup
<Element 'capltestcase' at 0x00000273EB4756D0> capltestcase
<Element 'caplparam' at 0x00000273EB475630> caplparam
<Element 'caplparam' at 0x00000273EB475720> caplparam
<Element 'caplparam' at 0x00000273EB475770> caplparam
<Element 'capltestcase' at 0x00000273EB4757C0> capltestcase
<Element 'caplparam' at 0x00000273EB475810> caplparam
<Element 'caplparam' at 0x00000273EB475860> caplparam
<Element 'caplparam' at 0x00000273EB4758B0> caplparam
<Element 'capltestcase' at 0x00000273EB475900> capltestcase
<Element 'caplparam' at 0x00000273EB475950> caplparam
<Element 'caplparam' at 0x00000273EB4759A0> caplparam
<Element 'caplparam' at 0x00000273EB4759F0> caplparam
<Element 'capltestcase' at 0x00000273EB475A40> capltestcase
<Element 'completion' at 0x00000273EB475A90> completion
'''4、选择性的迭代直接子节点
for n in root.iter('capltestcase'):
print(n, n.tag)
'''结果
<Element 'capltestcase' at 0x0000021056F357C0> capltestcase
<Element 'capltestcase' at 0x0000021056F358B0> capltestcase
<Element 'capltestcase' at 0x0000021056F359F0> capltestcase
<Element 'capltestcase' at 0x0000021056F35B30> capltestcase
'''5、查找元素
print(root.find('capltestcase'))
'''结果
<Element 'capltestcase' at 0x00000248F70F5B30>
'''6、添加元素
for n in root.iter():
if n.tag == 'capltestcase' and n.get('name') == 'Basic_test_case':
exam_node = n.find('caplparam')
exam_node.set("name", "eDDDDD")
for subject in ['math', 'music']:
p = ET.Element(subject)
p.text = '90'
exam_node.append(p)
if os.path.exists('new.xml'):
os.remove('new.xml')
tree.write('new.xml', encoding='utf-8', xml_declaration=True)
'''结果
<capltestcase title="ITS4_FD_0x134" name="Basic_test_case">
<caplparam name="eDDDDD" type="int">
0xE35487
<math>90</math>
<music>90</music>
</caplparam>
<caplparam name="eDEM" type="int">97</caplparam>
<caplparam name="iJT2Time" type="float">2000.0</caplparam>
</capltestcase>
'''7、修改移除元素
for n in root.iter("capltestcase"):
name = n.get('name')
title = n.get('title')
n.set('name',name+title)
n.set('title',name+title)
e=n.findall('caplparam')
for i in range(len(e)):
n.remove(e[i])
tree.write('new.xml')
'''结果
<testmodule title="Development - Requirements" version="1.0">
<variants>
<variant name="Basic">Development - Requirements</variant>
</variants>
<testgroup title="Test cases" variants="Basic">
<capltestcase title="Basic_test_caseITS4_FD_0x134" name="Basic_test_caseITS4_FD_0x134">
</capltestcase>
<capltestcase title="Basic_test_caseITS4_FD_0x3EA" name="Basic_test_caseITS4_FD_0x3EA">
</capltestcase>
<capltestcase title="Basic_test_caseITS4_FD_0x5CF" name="Basic_test_caseITS4_FD_0x5CF">
</capltestcase>
</testgroup>
<capltestcase name="FinalizeFinalize" title="FinalizeFinalize" />
<completion>
</completion>
</testmodule>
'''四、CAPL生成
1、利用上述所提到的XML方法主要利用get函数获取到所需关键信息并保存数组,打开DTC号和DTCname对应文件,打开DEM号和DEMname对应文件, 再根据从XML提取出的DTC号和DEM号找到对应的name提取出来。
def DEM_file_del(self,read_write):
if read_write == 0:
with open(self.dempath,'r',encoding="utf-8") as f1:
file = f1.readlines()
for i in range(len(self.group)):
for j in range(len(file)):
if(file[j].find('='+' '+self.group[i][5])!=-1):
self.DEM.append(file[j].split(' =')[0].strip())
def DTC_file_del(self,read_write):
if read_write == 0:
with open(self.dtcpath,'r',encoding="utf-8") as f3:
file = f3.readlines()
for i in range(len(self.group)):
#print(self.group[i][3])
for j in range(len(file)):
if(file[j].find('='+' '+self.group[i][3])!=-1):
self.DTC.append(file[j].split(' =')[0].strip())2、按照所需格式生成CAPL
def CAN_file_del(self,read_write):
with open(self.canpath,'a+',encoding='utf-8') as f2:
for i in range(len(self.group)):
casename = "testcase " + self.group[i][1]+ '_' + self.group[i][0] + '()\n'
mainpart = "{\n " + self.group[i][1] + '(' + self.DTC[i] + ',' + self.DEM[i] +',' + self.group[i][7]+',' +'"TC_' + str(i+1)+ '"'+',' + '"' + self.group[i][1]+ '_' + self.group[i][0] + '"' +')' + ';\n' +'}\n\n'
f2.write(casename+mainpart)
print(self.canpath+" Wrirte Done")3、全部脚本
import xml.etree.ElementTree as ET
import os
File_name = ['Basic_Test_Case','T_LessThan_JT2_GADE_Enable_6_1','T_LessThan_JT2_GADE_Disable_6_2',
'T_LessThan_JT2_GADE_Unavailable_6_3','T_LessThan_JT2_GADE_NeverReceiveOnce_6_4',
'T_MoreThan_JT2_GADE_Enable_6_5','T_MoreThan_JT2_GADE_Disable_6_6',
'T_MoreThan_JT2_GADE_DisableAfterJT2_6_7','T_MoreThan_JT2_GADE_Unavailiable_6_8',
'T_MoreThan_JT2_GADE_DisableAfterJT2plus1_during_JT2minus05_6_9','T_MoreThan_JT2_GADE_NeverReceiveOnce_6_10',
'LastValue_Enable_ThenMissing_GADE_6_11','LastValue_Disable_ThenMissing_GADE_6_12',
'LastValue_Unavailable_ThenMissing_GADE_6_13','GADE_Disable500_after_JT2minius500_6_14',
'Check_After_PowerOn_GADE_Enable_6_15','Check_After_PowerOn_GADE_Disable_6_16',
'Check_After_PowerOff_GADE_Disable_6_17','Check_JT2_Window_GADE_Enable_6_18',
]
File_name_Xml =[File_name[j]+'.xml' for j in range(len(File_name))]
File_name_Can =[File_name[j]+'.can' for j in range(len(File_name))]
class XML_CAN_Generate:
def __init__(self, DEM_File_Path, DTC_File_path, CAN_File_Path, XML_File_path):
self.dempath = DEM_File_Path
self.canpath = CAN_File_Path
self.xmlpath = XML_File_path
self.dtcpath = DTC_File_path
self.Parameter = []
self.group = []
self.DEM = []
self.DTC = []
self.timeout = []
def DEM_file_del(self,read_write):
if read_write == 0:
with open(self.dempath,'r',encoding="utf-8") as f1:
file = f1.readlines()
for i in range(len(self.group)):
for j in range(len(file)):
if(file[j].find('='+' '+self.group[i][5])!=-1):
self.DEM.append(file[j].split(' =')[0].strip())
def DTC_file_del(self,read_write):
if read_write == 0:
with open(self.dtcpath,'r',encoding="utf-8") as f3:
file = f3.readlines()
for i in range(len(self.group)):
#print(self.group[i][3])
for j in range(len(file)):
if(file[j].find('='+' '+self.group[i][3])!=-1):
self.DTC.append(file[j].split(' =')[0].strip())
def CAN_file_del(self,read_write):
with open(self.canpath,'a+',encoding='utf-8') as f2:
for i in range(len(self.group)):
casename = "testcase " + self.group[i][1]+ '_' + self.group[i][0] + '()\n'
mainpart = "{\n " + self.group[i][1] + '(' + self.DTC[i] + ',' + self.DEM[i] +',' + self.group[i][7]+',' +'"TC_' + str(i+1)+ '"'+',' + '"' + self.group[i][1]+ '_' + self.group[i][0] + '"' +')' + ';\n' +'}\n\n'
f2.write(casename+mainpart)
print(self.canpath+" Wrirte Done")
def XML_file_del(self,read_write):
k=-8
e=[]
tree = ET.parse(self.xmlpath)
root = tree.getroot()
#print(root)
if read_write == 0:
for n in root.iter('capltestcase'):
self.Parameter.append(n.get('title'))
self.Parameter.append(n.get('name'))
for t in n.iter('caplparam'):
self.Parameter.append(t.get('name'))
self.Parameter.append(t.text)
for i in range(len(self.Parameter)//8):
k=k+8
self.group.append(self.Parameter[k:k+8])
if read_write == 1:
for n in root.iter("capltestcase"):
name = n.get('name')
title = n.get('title')
n.set('name',name+title)
n.set('title',name+title)
e=n.findall('caplparam')
for i in range(len(e)):
n.remove(e[i])
tree.write(self.xmlpath)
if __name__=='__main__':
for name_len in range(len(File_name_Can)):
if os.path.exists(File_name_Can[name_len]):
os.remove(File_name_Can[name_len])
P = XML_CAN_Generate("DEM.txt","DTC.txt",File_name_Can[name_len],File_name_Xml[name_len])
P.XML_file_del(0)
P.DEM_file_del(0)
P.DTC_file_del(0)
P.CAN_file_del(0)
P.XML_file_del(1)
















 710
710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











