







第一章 Ubuntu系统入门
uname -a #查看内核版本
cat etc/issue #查看系统版本
#linux查看进程号
ps aux #显示所有用户的所有进程信息,包括进程号(PID)
ps -ef #显示所有进程信息,包括进程号(PID)
ps -ef | grep <进程名> #通过进程名过滤显示进程信息,包括进程号(PID)
#查看磁盘分区表
fdisk -l #查看所有磁盘分区表
fdisk -l /dev/sda #查看指定磁盘分区表
#查看CPU使用率
top #实时显示系统的运行状况,包括CPU和内存、进程的信息
#查看内存
free -h #显示系统的内存使用情况,-h表示人类可读的格式(如MB、GB)
#查看文本尾行
tail -n 50 /路径 #这里查看倒数50行往下的内容1.1 Linux磁盘管理
1.1.0 扇区|簇|块|页等概念
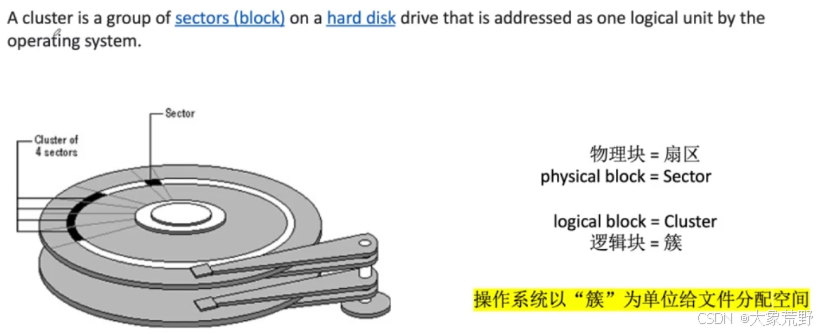
以下概念需要理解:
柱面、磁头、磁道、扇区。
机械硬盘旋转时,磁头沿着柱面移动,同半径的圆会形成一个柱状的扫描面,即柱面,扫描留下的环形区域被称为磁道,磁道按照等长弧段划分,就形成扇区。
磁道从外向内编号,编号越小的磁道离盘心越近,存储密度也越高。
扇区之间通过间隙分隔,避免磁头读写时发生混淆。
磁盘自身读写基本单位是扇区。
常见的扇区大小为512B。硬盘以扇区为单位进行读写。
操作系统读写磁盘的基本单位是簇/块。Linux为簇,Windows为块。
操作系统读写内存的基本单位是页。页通常也是4kb。
由于操作系统无法对数目众多的扇区进行寻址,所以操作系统就将相邻的扇区组合在一起形成一个簇,然后再对簇进行管理。(每个簇可以包括2、4、8、16、 32或64个扇区)
块(簇)是 操作系统与磁盘(硬盘)交互的最小数据单元(在linux系统中称为块,在windows系统中称为簇)。操作系统从硬盘中拿一块数据,即完成一次磁盘IO。
块(数据块)的大小在硬盘格式化时被指定,一般有1K,2K,4K(最常用)。如果块的大小设置为4K,那么磁盘要读取8个扇区(512B)之后,才将数据块传给操作系统。
另外,数据块也是DOS下数据存储的最小单元。例如,如果一个文件的大小为1K,而块的大小为4K,那么该文件还是会占用一个块,块中剩下的3K被空闲出来,不能用于存储其他数据。因此,设置块的大小时,需要考虑要存储文件的大小。
(DOS,早期的磁盘操作系统,无界面,现在被图形界面操作系统取代了)
文件系统就是操作系统的一部分,所以文件系统操作文件的最小单位是块/簇。
磁盘控制器,其作用除了读取数据、控制磁头等作用外,还有的功能就是映射扇区和磁盘块的关系。
扇区是对硬盘而言,是物理层的。
块和簇是对文件系统而言,是逻辑层的。页是对内存而言的,也是逻辑层的。
磁盘控制器是用来映射两层的。
磁盘块与扇区的大小
磁盘块是一个虚拟概念。所以大小由操作系统决定,操作系统可以配置一个块多大。
而扇区是物理概念,硬盘出厂规定好的。
一个块大小=一个扇区大小*2的n次方。
4k对齐
硬盘容量不断扩展,使得之前定义的每个扇区512字节不再是那么的合理,于是将每个扇区512字节改为每个扇区4096 个字节,也就是现在常说的“4K扇区”。
随着NTFS成为了标准的硬盘文件系统,其文件系统的默认分配单元大小(簇)也是4096字节,为了使簇与扇区相对应,即使物理硬盘分区与计算机使用的逻辑分区对齐,保证硬盘读写效率,所以就有了“4K对齐”的概念。
新标准的”4K扇区”的硬盘在厂商为了保证与操作系统兼容的前提下,也将扇区模拟成512B,会默认定义为4096字节大小为一个簇,但因为其引导区占用了一个磁道共63个扇区,真正的文件系统在63号扇区之后。
我们通过计算得出前63个扇区大小为:512Bx63=32256B
并按照默认簇大小得出63扇区为:32256B÷4096B=7.875簇
即从第63个扇区结束,往后的每一个簇都会跨越两个物理单元,占据前一个单元的一小部分和后一个单元的一大部分。
而“4K对齐”主要是将硬盘的模拟扇区(512B)对齐到8的整数倍个“实际”4K扇区,即4096B*8=32768B,其正好跨过了63扇区的特性,从第64个扇区对齐。
块与页的关系
操作系统经常与内存和硬盘这两种存储设备进行通信,类似于“块”的概念,都需要一种虚拟的基本单位。
所以,与内存操作,是虚拟一个页的概念来作为最小单位。
与硬盘打交道,就是以块为最小单位。
一个页一般也是4KB,
页表是一种数据结构,用于存储虚拟地址到物理地址的映射关系。每个页表项对应虚拟内存中的一个页,包含该页在物理内存中的页框号以及其他控制信息。
页框是物理内存中被划分出来的固定大小的块,用于存放页的内容。页框的大小与页的大小相同,以保证虚拟内存和物理内存之间的映射关系。
缺页的概念
缺页是引入了虚拟内存后的一个概念。
操作系统启动后,内存中维护着个虚拟地址表,进程需要的虚拟地址在虚拟地址表中记录。
一个程序被加载运行时,通常只有部分页面被加载到内存,其他页面则保留在磁盘上。当CPU试图访问一个未驻留在内存中的页面时,就会发生缺页。
此时,操作系统需要从磁盘中调入该页面到内存,这个过程称为缺页中断处理。
1.1.1 Linux磁盘管理基本概念
关键词:
Linux 磁盘管理
挂载点
/etc/fstab文件
分区
ls /dev/sd*
联系描述:
Linux 磁盘管理体系通过“挂载点”概念替代了 Windows 中的“分区”概念,将硬盘部分以文件夹形式呈现。系统通过 /etc/fstab 文件记录硬盘挂载情况,指定分区挂载位置。
使用 ls /dev/sd* 命令可查看 SATA 硬盘及外部存储设备(如 U 盘、SD 卡)的设备文件,设备文件名中的字母和数字分别代表硬盘和分区编号。插入外部设备时,系统会动态分配新设备文件,用户可通过再次执行该命令确认设备连接状态。
Linux 的磁盘管理体系与 Windows 有显著不同。
在 Linux 中,通常不使用“分区”这一术语,而是采用“挂载点”的概念。
挂载点是将硬盘的一部分以文件夹的形式呈现给用户,用户看到的是以文件夹形式存在的挂载点,而非像 Windows 中的 C 盘、D 盘等。
Linux 系统通过 /etc/fstab 文件详细记录硬盘挂载的情况,该文件指定了分区如何被挂载到系统的不同位置。例如,/ was on /dev/sda1 during installation 表示根目录 / 被挂载在 /dev/sda1 这个分区上。
文件名中的 sd 表示 SATA 设备,后面的字母(如 a、b 等)代表不同的硬盘,数字(如 1、2 等)代表硬盘上的分区编号。Serial ATA,串口硬盘。
/dev/sda1代表挂载的 sd类型设备 硬盘a 分区1

在 Linux 中,可以使用 ls /dev/sd* 命令来查看所有以 /dev/sd 开头的设备文件,这些文件代表 SATA 硬盘或其他外部存储设备。
当插入 U 盘或 SD 卡等外部设备时,系统会根据设备的接入顺序动态分配新的设备文件(如 /dev/sdb、/dev/sdc 等),并创建相应的分区文件(如 /dev/sdb1、/dev/sdb2)。用户可以通过再次执行 ls /dev/sd* 命令来查看新增的设备文件,从而确认外部设备已成功连接到系统。

像上图就有 sda硬盘设备、sdb为u盘设备,sdb1为U盘分区,就一个分区。
简而言之,Linux 通过挂载点的方式管理磁盘分区,并使用 /etc/fstab 文件记录系统启动时需要自动挂载的设备或分区信息。用户可以通过查看 /dev/sd* 设备文件来识别系统中的硬盘和外部存储设备。
常用指令:
df -h #查看当前目录磁盘空间情况
free -h #查看当前内存使用情况1.1.2 磁盘分区工具
fdisk是一个用于磁盘分区的工具,支持MBR和GPT分区表。
MBR分区的全称是Master Boot Record,即主引导记录,也叫主引导扇区。
GPT分区的全称是GUID Partition Table,即全局唯一标识符分区表。
MBR分区表最多支持4个主分区,或者3个主分区加1个拓展分区,
而GPT则支持更多分区,通常可达128个主分区。
分区表紧跟在bootloader程序后,
MBR是硬盘上的特殊区域,包含引导程序和分区表,是启动操作系统的关键。
随着技术进步,MBR因分区数量限制和不支持大分区等局限性,逐渐被GPT分区表替代。但在旧系统或特定需求下,MBR仍被广泛使用。
fdisk分区工具
磁盘管理命令 - fdisk
fdisk是一个用于磁盘分区的强大工具,它可以用于管理磁盘分区。
fdisk -l #列出全部磁盘设备的分区信息
fdisk -l /dev/sda #列出sda设备的分区信息
lsblk #列出系统上所有可用的块设备及其相关信息。
#典型的块设备包括硬盘、U盘、SD卡、等,包括ROM和RAM。
#磁盘设备是块设备的一种,可理解成只包含ROM。
Loop设备是Linux中的回环设备,将一个文件映射成一个块设备,从而可以像访问物理硬盘一样访问这个文件。这种特性是通过内核中的回环设备驱动程序实现的。常用于挂载文件系统镜像。
上图的sda是挂载的磁盘文件分区。
fdisk进行MBR分区
假设想对名为/dev/sdb的U盘进行分区,可以使用以下命令:
fdisk /dev/sdb
# 进入fdisk交互界面后,依次输入以下命令:
n # 创建新分区,可以默认直接回车
p # 创建主分区,可以默认直接回车
2 # 输入分区号,默认设置为2,可以默认直接回车
[起始扇区] # 设置起始扇区,可以默认直接回车
[结束扇区] # 设置结束扇区,可直接回车;+分区大小
w # 将分区表写入磁盘并退出
#如果分区后无法发现分区结果,请{刷新分区表}后再次查看: partprobe /dev/sdb

p 创建主分区,然后给出分区号。给起始扇区,给空间大小,保存退出。
注意创建新分区时,可以选择分区类型。分区类型有:主分区、拓展分区、逻辑分区。
如果要分区的 存储设备 sda,是第一次分区,那么可以选择主分区、拓展分区。
MBR分区最多能有 4 个主分区,或 三个主分区,一个拓展分区。
拓展分区不能单独存在,如果将磁盘设备创建成拓展分区,则必须在拓展分区基础上创建逻辑分区。


删除一个分区。在 fdisk的交互界面,用d命令+分区号。

gdisk分区工具 GPT分区
GPT支持更多的分区数量,通常支持多达128个主分区,无需创建扩展或逻辑分区,
而MBR最多只能支持4个主分区或3个主分区加多个逻辑分区。
gdisk 用法和 fdisk类似。
gdisk -l /dev/sdb #查看指定设备分区信息
gdisk /dev/sdb #对指定设备分区1.1.3 APT下载工具
如果想查看本地哪些软件可以更新的话可以使用如下命令:
sudo apt-get update #看哪些软件能更新
sudo apt-get check #检查软件之间的依赖关系
sudu apt-get upgrade 软件名 #更新指定软件
sudo apt-get install 软件名 #安装软件
sudo apt-get remove 软件名 #卸载指定软件
#/etc/apt/sources.list文件可更换软件源apt-get 默认将软件包安装在 /usr 目录下,
可执行文件在 /usr/bin,
库文件在 /usr/lib,
配置文件和文档在 /usr/share。
使用国内镜像源可以提高下载速度。编辑 /etc/apt/sources.list文件,将原有的软件源注释掉,并添加国内镜像源,然后运行 sudo apt update更新软件源列表。
sudo apt-get update 更新软件源。
1.1.4 压缩/解压工具
###解压缩
tar -vxf 文件名 #解压到当前目录
tar -vxf 文件名 -C 路径 #解压到指定路径
# -v 代表verbose,给出详细信息
# -x 代表 解压缩
# -f 代表后面要跟文件名
#tar 命令本身并不直接提供压缩功能,
#但它可以与多种压缩工具(如 gzip, bzip2, xz 等)结合使用,以创建压缩的归档文件
tar cvf 压缩后的路径 源路径
#c 表示创建归档文件
#z 表示通过 gzip 压缩
unzip 文件名 #解压.zip压缩文件1.1.5 Ubuntu下文本编辑
Gedit编辑器
gedit xxx.c #打开xxx.cVi/Vim编辑器
vim是vi的强化版,支持语法高亮和各种插件。vi只实现了基本的插入、删除、替换等功能。
vim常用的一些指令,
比如 i 插入模式,v 可视化模式,/ 查找模式,: 3,5 + d 代表删除第3~5行
G代表到文本第一行,gg代表到文本最后一行
0代表到第一列,$代表到最后列
u撤销,ctrl+r反撤销,d删除,x剪切,y复制,p粘贴
1.2 Linux文件系统
操作系统的基本功能之一就是文件管理,而文件的管理是由文件系统来完成的。
1.2.1 文件系统简介及类型
文件系统简介
在Linux系统中,文件系统是负责管理存储设备上数据的机制,它将硬盘上的二进制数据转换为人类可读的文件形式。由于存储设备(如硬盘、U盘、SD卡等)的物理结构各异,Linux支持多种文件系统以适配不同的使用场景。
Linux文件系统类型
Linux支持多种文件系统,现在磁盘管理一般用的 ext4文件系统:
ext2:
早期文件系统,虽然曾经是Linux的标准文件系统,但由于缺乏日志功能,已不推荐使用。
ext3:
在ext2基础上增加了日志功能,提高了系统的可靠性和数据完整性。
ext4:
更先进的文件系统:在ext3基础上进一步提升了性能和可靠性,增加了更多功能。
兼容性:向下兼容ext3和ext2,可轻松挂载这些旧版文件系统。
如何查看当前Linux系统使用的文件系统
在Linux终端中,可以使用df命令结合-T选项来查看磁盘分区及其文件系统类型。
df -T -h
#df 命令(disk free)用于报告文件系统的磁盘空间使用情况。
#-T 选项 用于在输出中显示文件系统类型。这对于理解不同分区或设备上的数据是如何组织的非常有用。
#-h 选项 用于以易于阅读的格式显示文件大小,自动选择 KB、MB、GB 等单位,而不是默认的字节数。#df -T -h
Filesystem Type Size Used Avail Use% Mounted on
udev devtmpfs 7.8G 0 7.8G 0% /dev
tmpfs tmpfs 1.6G 1.4M 1.6G 1% /run
/dev/sda1 ext4 48G 20G 26G 44% /
tmpfs tmpfs 7.8G 0 7.8G 0% /dev/shm
tmpfs tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup
/dev/loop0 squashfs 91M 91M 0 100% /snap/core/10185
/dev/loop1 squashfs 180M 180M 0 100% /snap/gimp/270
...1.2.2 Linux 文件系统结构
Linux 文件系统结构与 Windows 有显著不同。
Linux 使用单一的根目录(/)来组织所有文件和文件夹,
而 Windows 使用多个盘符(如 C:, D: 等)。
Linux 中,每个用户默认有自己的主目录(例如 /home/username),是根目录下的一个特定文件夹。

1.2.3 Linux文件类型
查找文件的命令:
find 路径 文件名* #找出路径下以通配符开头的所有文件 #注意找文件还可以用find + 选项 +参数 来用 uid gid之类的参数来找 find . -name 'kernel' #找出当前路径下为kernel的文件或文件夹名, find . -type f -name 'kernel' #只找文件,不包括目录 find . -type f -mtime +7 #查找当前路径下 修改时间在7天前的文件 find . -name 'kernel' 2>/dev/null #忽略没有权限访问的目录的错误信息find使用-name时默认是递归的。 find直接+名字时不递归。
查找文件中包含指定内容的行命令:
grep "example" filename.txt #找文件中包含特定文本的行 grep "[0-9]\{3\}" filename.txt #正则表达式搜索包含3个连续数字的行 grep -i "example" filename.txt #忽略大小写 grep -r "example" filename.txt #递归查找grep默认是不递归的。
可使用 ls -l 来查看文件夹下文件的详细信息。
文件类型、用户/组/其他权限、硬链接数、所有者、所属组、文件大小、最后修改时间、文件名
目录的硬链接数至少有两个:目录名本身和目录中的.项。
目录的文件大小,表示的是目录本身的大小,
- 普通文件,一些应用程序创建的,比如文档、图片、音乐等等。
d 目录文件。
c 字符设备文件,Linux 驱动里面的字符设备驱动,比如串口设备,音频设备等。
b 块设备文件,存储设备驱动,比如硬盘,U 盘等。
l 符号连接文件,相当于 Windwos 下的快捷方式。
s 套接字文件。
p 管道文件,主要指 FIFO 文件

第二章 HelloWorld
2.1 交叉编译 hello.c
在linux环境下,写好hello.c,可以使用gcc编译器进行编译。输出得到可执行文件hello。
gcc hello.c -o hello上述命令得到的可执行文件hello可以在ubuntu中运行,但是无法在ARM平台运行。因为gcc编译器是针对PC机的,编译得到的机器指令是x86的。
要在PC平台编译出ARM板上可执行的程序,需要使用交叉编译工具链,比如
arm-buildroot-linux-gnueabihf-gcc hello.c -o hello 这样得到的hello程序才可以在ARM板子上运行。
2.2 请回答这样几个问题
1、怎么确定交叉编译器中头文件的默认路径?
在交叉编译器的目录下,执行
find -name stdio.h会发现头文件位于一个名为“include”的目录里。
2、怎么自己指定头文件目录?
使用交叉编译器时,使用 -I <头文件目录> 这样的选项
3、怎么确定交叉编译器中库文件的默认路径?
进入交叉编译器的目录里,执行
find -name lib可以得到 xxx/lib、xxx/usr/lib、,库文件夹下包含很多.so文件。share object,共享对象
4、怎么自己指定库文件目录、指定要用的库文件?
编译时,加上 -L <库文件目录>,用来指定库文件目录。
编译时,加上 -labc ,用来指定库文件 libabc.so。
第三章 GCC编译器的使用
源文件需要经过编译才能生成可执行文件。在Windos下进行开发时,集成开发环境(Visual Studio)已经将各种编译工具直接封装好了。Linux下也有集成开发工具,但更多时候是直接使用编译工具。
PC 机常用的编译工具链为gcc、g++等,它们编译出来的程序在 x86或x86_64 平台上运行。
要编译出能在 ARM 平台上运行的程序,必须使用交叉编译工具 xxx-gcc、xxx-ld 等(不同版本的编译器的前缀不一样,比如 arm-linux-gcc)。
3.1 GCC编译过程(精简版)
一个C/C++文件要经过预处理、编译、汇编、链接,才能变成 .elf 格式的,二进制可执行文件。//早期文件格式版本是.out,不支持符号、动态链接等特性。
linux文件不关心后缀,但是关心编码格式,比如 .elf 就是可执行常用的格式。
Linux可执行文件没有文件后缀。但是有数据存储格式,常见 .elf 存储格式。
GCC <-E -S -c> -o <.i .s .o> //预处理、编译、汇编、链接 源码、汇编指令、二进制、可执行
GCC input.o -o output_executable //链接
GCC -c main.c -o main.o //可以直接生成.o目标文件
GCC main.c -o main //可以直接生成.elf可执行文件
3.1.1 常用编译选项

3.1.2 编译多个文件
可以统一编译、链接。
gcc xxx1.c xxx2.c -o xxx也可以分开汇编成 .o二进制文件,再链接。
3.1.3 制作、使用动态库
第一步,将二进制.o文件通过 gcc -shared 命令制作成 .so共享文件。
gcc -shared libsub.o -o sub.so -l <库文件> -L <库目录>第二步,
将 libsub.so放到 Ubuntu 的/lib目录,
然后在生成可执行文件的时候,使用 -l 指定使用的库文件, -L 指定动态库,也就是 .so 文件所在的目录。
/*在链接生成可执行文件时,使用动态库*/
gcc main.o -o test -lsub -L
//注意这里指定 -l指定使用的库文件时,-lsub表示库文件名libsub,库文件都是以lib开头2、如果不将 库文件 放到 /lib 下,也可以放在某个目录比如 /a,然后执行 export 将/a 添加到环境变量里面,动态链接库的搜索路径里。
/*
将 `/a` 目录添加到系统的动态链接库搜索路径中。
具体来说,这个命令做了以下几件事情:
- `LD_LIBRARY_PATH`: 是一个环境变量,用于指定动态链接库(shared library)的搜索路径。
- `$LD_LIBRARY_PATH`: 表示当前 `LD_LIBRARY_PATH` 变量的值。
- `:/a`: 表示要将 `/a` 目录添加到动态链接库搜索路径中。
*/
export LD_LIBRARY_PATH = $LD_LIBRARY_PATH:/a //注意仅当前shell窗口生效
3.1.4 制作、使用静态库
ar crs xxx.o -o libxxx.a指令用于创建静态库,.a 静态库,通常称为归档文件(archive file)。
ar crs xxx.o -o libxxx.a #创建静态库
#ar是指ar 归档工具
# c代表归档文件不存在则拆功能键,存在则替换
# r代表向归档文件插入文件
#归档文件是一种包含多个文件或目录的文件集合,
#但它在文件系统层面上被当作一个单独的文件来处理gcc main.o libsub.a -o test //.o 文件和 .a 文件 -o 链接成可执行文件注意:
使用动态库 .so文件时,要在制作.so文件,或者链接可执行文件时, 加上-fPIC参数,表示生成的文件是位置无关代码。
比如动态库中的全局变量,如果被多个可执行文件使用,如果这个全局变量涉及到绝对地址,就会导致安全问题。而位置无关代码会把动态库的这些涉及绝对地址的东西放到数据段和BSS段,而不会放在代码段,用来确保安全性。
`-fPIC` 用于生成位置无关代码(Position Independent Code,PIC)。
动态链接库 .so 允许程序在运行时加载。
静态链接库 .a 将代码和数据整合到可执行文件中。
3.1.5 其他有用的选项
gcc -E main.c // 查看预处理结果,比如头文件是哪个
gcc -E -dM main.c > 1.txt // 把所有的宏展开,存在 1.txt 里
gcc -Wp,-MD,abc.dep -c -o main.o main.c // 生成依赖文件 abc.dep,后面 Makefile 会用
echo 'main(){}'| gcc -E -v - // 它会列出头文件目录、库目录(LIBRARY_PATH)
//将字符串 'main(){}' 作为源代码输入到 GCC 编译器中,
//仅执行预处理阶段,并显示详细的操作信息。编译时加上 -Wall 可打开警告。
第四章 Makefile的使用
在Linux中使用make命令来编译大程序,因为几百个.c不可能一个一个去编译。
描述哪些文件需要编译、哪些需要重新编译的文件就叫做 Makefile,Makefile 就跟脚本文件一样,Makefile 里面还可以执行系统命令。
IDE其实也有 makefile文件,只不过对 makefile进行了封装。
make 命令所执行的动作依赖于 Makefile文件。最简单的Makefile文件如下:
hello: hello.c
gcc -o hello hello.c
clean:
rm -f hello将上述 4 行存为 Makefile 文件(注意必须以 Tab 键缩进第 2、4 行,不能以空格键缩进),放入 01_hello 目录下,然后直接执行 make 命令即可编译程序,执行“make clean”即可清除编译出来的结果。
make 命令根据文件更新的时间戳来决定哪些文件需要重新编译,这使得可以避免编译已经编译过的、没有变化的程序,可以大大提高编译效率。要想完整地了解 Makefile 的规则,请参考《GNU Make 使用手册》,以下仅粗略介绍。
Makefile 其实就是封装了SHELL命令
4.1 Makefile概述
4.1.1 Makefile 规则
Makefile 包含一个或多个规则,每个规则定义了如何生成一个或多个目标文件,这些目标文件依赖于其他文件(称为依赖文件)。
规则包含:
目标:要生成的文件。
依赖:生成目标所需的其他文件。
命令:用于生成目标的命令,每个命令前必须有 TAB 字符。
当使用 make 命令时,它会查找 Makefile 文件,并确定如何更新目标文件。
如果目标文件不存在或依赖文件比目标文件新,则执行相应的命令。
# 定义终极目标 main
main: main.o input.o calcu.o
gcc -o main main.o input.o calcu.o
# 定义如何生成 main.o
main.o: main.c
gcc -c main.c
# 定义如何生成 input.o
input.o: input.c
gcc -c input.c
# 定义如何生成 calcu.o
calcu.o: calcu.c
gcc -c calcu.c
# 清理规则,不是终极目标
clean:
rm -f *.o main4.1.2 Makefile 变量
Makefile 支持变量的使用,以简化复杂的构建过程并减少重复。
赋值符,
有基本赋值 =、 延迟展开变量,值是右值最后定义的值。
立即赋值 :=、 简单展开变量,值是左值最后定义的值。
条件赋值 ?=、 只在变量未定义时赋值。
追加赋值 +=。 追加。值是右值最后定义的值。
#基本赋值 = 注意基本赋值在使用时展开,如果
name = zzk #定义了一个名为name的变量,值为zzk
curname = $(name) #变量基本赋值 #引用点
name = zuozhongkai
print: #定义了一个名为 print的目标
@echo curname: $(curname) # 输出: curname: zuozhongkai //在命令中使用变量
#基本赋值 a=b,echo $(a),a=c #打印出来a是c,也就是最后定义的值
#但是基本赋值情况下,a=b,echo $(a),b=c,打印出来a=c,也就是延迟展开,值是右值最后定义的值#立即赋值,只使用定义时已知的值
name = zzk
curname := $(name)
name = zuozhongkai
print:
@echo curname: $(curname) # 输出: curname: zzk
#基本赋值 a=b,echo $(a),a=c #打印出来a是c,也就是最后定义的值
#但是基本赋值情况下,a=b,echo $(a),b=c,打印出来a=b,也就是立即展开,值是左值最后定义的值#条件赋值。只在变量未定义时赋值。
curname ?= zuozhongkai
curname = zzk #覆盖
print:
@echo curname: $(curname) # 输出: curname: zzk#追加赋值。向变量追加值,会自动在添加的内容前加上空格
objects = main.o input.o
objects += calcu.o
all:
@echo $(objects) # 输出: main.o input.o calcu.o4.1.3 Makefile 模式规则
在Makefile中使用模式规则可以极大地简化对多个源文件编译的描述。
模式规则允许使用通配符(如%)来匹配文件名,并基于这些匹配来定义编译规则。
在模式规则中,$<代表规则中的第一个依赖文件(在本例中是.c文件),而$@代表规则的目标文件(在本例中是.o文件)。
objects = main.o input.o calcu.o #变量 指出源文件 变量名可变
# .c 依赖于 .o
main: $(objects) #使用变量来给依赖
gcc -o main $(objects) #使用变量来给命令
#使用模式规则来将 .c文件编译为 .o文件,这里的自动化变量要找上面的 .c依赖于.o的makefile脚本
#然后自动将变量作为文件名的来源
%.o: %.c #%.o: %.c 是一个模式规则,它告诉make如何根据.c文件生成.o文件。
gcc -c $< -o $@
# $< 代表当前目标(.o文件)所依赖的第一个文件(.c文件),
# 而 $@ 代表当前规则的目标(即正在构建的.o文件)。
clean:
rm *.o
rm main4.1.4 Makefile 自动化变量
在Makefile中,自动化变量提供了一种便捷的方式来引用规则中的目标文件、依赖文件等,而不需要显式地写出它们的名称。
objects = main.o input.o calcu.o
# 定义目标
all: app
# 定义可执行文件app,依赖于所有.o文件
app: main.o foo.o bar.o
gcc -o app $^
# 使用模式规则来编译.c文件为.o文件
%.o: %.c
gcc -c $< -o $@
# 清理编译生成的文件
clean:
rm -f *.o app常用的 自动化变量 有
$^ 在规则中代表所有依赖的文件列表,用空号分隔,自动去重
$@ 在规则中代表所有依赖的 .o文件
$< 在规则中代表所有依赖的 .c文件
4.1.5 makefile伪目标
伪目标的概念
伪目标:Makefile中用于执行特定命令但不生成实际文件的目标。
目的:避免与文件名冲突,确保目标下的命令总是被执行。
clean就是一个常用的伪目标。
4.1.6 Makefile 条件判断
Makefile支持的条件判断语法主要有两种形式,并且包含四种条件关键字:
ifeq、 两个参数是否相等
ifneq、 两个参数是否不等
ifdef、 变量是否已定义且非空
ifndef。 变量是否未定义或为空
ifeq ($(VAR1),value)
# VAR1等于value时执行的语句
endif
ifneq ($(VAR2),another_value)
# VAR2不等于another_value时执行的语句
else
# VAR2等于another_value时执行的语句
endififdef VAR3
# VAR3已定义且非空时执行的语句
endif
ifndef VAR4
# VAR4未定义或为空时执行的语句
else
# VAR4已定义且非空时执行的语句
endif4.1.7 Makefile 函数使用
subst函数, 字符串替换
patsubst函数, 模式字符串替换
dir函数, 从文件名路径序列中提取目录部分
notdir函数, 从文件名路径序列中提取文件名,去除目录
foreach函数, 对列表中每个元素执行特定的表达式,返回字符串
wildcard, 让通配符在变量或函数中生效。
Makefile 支持使用预定义的函数来执行各种字符串操作、文件路径处理、循环等任务,但不允许用户自定义函数。
subst 函数:
字符串替换。将字符串中的特定子串替换为另一个子串。
$(subst zzk,ZZK,my name is zzk) # 结果为 "my name is ZZK"
patsubst 函数:
模式字符串替换。根据指定的模式匹配字符串中的单词,并用替换字符串替换它们。
$(patsubst %.c,%.o,a.c b.c c.c) # 结果为 "a.o b.o c.o"
dir 函数:
从文件名序列中提取目录部分。
$(dir /src/a.c) # 结果为 "/src"
notdir 函数:
从文件名序列中提取文件名部分,去除目录。
$(notdir /src/a.c) # 结果为 "a.c"
foreach 函数:
对列表中的每个元素执行给定的表达式,并返回由这些表达式的输出组成的字符串。
files = a.c b.c c.c $(foreach f,$(files),$(f).o) # 结果为 "a.c.o b.c.o c.c.o"
wildcard 函数:
用于生成匹配特定模式的文件列表。在变量定义和函数中使用时,通配符不会自动展开,wildcard 函数提供了这一功能。
SRCS = $(wildcard *.c) # 获取当前目录下所有.c文件
4.2 Makefile示例
比如常用的 sqlite3库,使用apt-get 安装后如果要用makefile来编译和链接,需要在链接阶段指明使用的外部库。
locate xxx.h //快速定位文件路径#指定sqlite3的头文件和库文件路径
#链接时要添加系统库的头文件
export CFLAGS="-I/path/to/sqlite/include"
libs = -lsqlite3
#汇编时要添加系统库的动态库.so的库文件
export LDFLAGS="-L/usr/lib/x86_64-linux-gnu/lib"
# Makefile 使用通配符的示例
# 编译器和选项
CC = g++
# 输出重要警告信息
CFLAGS = -Wall #-std=c++11
# 源文件通配符匹配所有的 .c 文件
SRCS = $(wildcard *.cpp)
# 对象文件,将源文件列表中的 .c 替换为 .o
OBJS = $(SRCS:.cpp=.o)
#指定sqlite3的头文件和库文件路径(假如需要使用,通常会去默认库找)
export CFLAGS="-I/path/to/sqlite/include"
export LDFLAGS="-L/usr/lib/x86_64-linux-gnu/lib"
#告诉编译器连接一个 名为 Xx的库,可以是静态库.a也可以是动态库.so
libs = -lsqlite3
# 目标可执行文件
TARGET = main
# 默认目标:编译所有源文件并链接成可执行文件
all: $(TARGET)
#链接 对引用的系统库 链接时 -I指定库头文件路径
# 编译目标可执行文件 $@表示.o文件 .$^用在链接阶段,被替换成没后缀的文件名
$(TARGET): $(OBJS)
$(CC) $(CFLAGS) -o $@ $^ $(libs)
#汇编 对引用的系统库 连接时 -L指定库源文件路径
# 编译对象文件的模式规则,使用 % 作为通配符匹配任意文件名
%.o: %.cpp
$(CC) $(CFLAGS) -c $< -o $@ $(LDFLAGS)
# 清除生成的文件
clean:
rm -f $(OBJS) $(TARGET)第五章 文件系统
在Linux系统中,系统镜像和固件是两个至关重要的概念。
系统镜像:是完整的操作系统安装包,含内核、文件系统、驱动等,保证系统完整性与可移植性,便于快速部署与版本控制。
固件:是嵌入硬件设备中的软件,控制硬件操作,管理初始化、配置,并可通过更新提升性能或修复问题。
引导加载程序(uboot)从存储介质加载系统镜像启动系统,固件则初始化硬件。
固件与驱动程序共同确保硬件正常工作。
通常为了让一个ARM裸机板子装上操作系统,会选择一个文件系统构建框架,或者完整的发行版本的linux,制作成镜像或者固件(都是.img),通过工具烧录进开发板。
一个完整的嵌入式 Linux 系统,包含 uboot,Linux 内核,根文件系统三个部分。
系统刚上电的时候,先执行 uboot,由 uboot 引导内核,内核启动成功之后挂载根文件系统。

5.1.1 什么是文件系统
现在linux用的都是 ext4文件系统,管理系统磁盘,像U盘常见的就是 fat32文件系统。
文件系统就是用文件形式对磁盘内容进行组织的工具。
5.1.2 文件系统目录介绍
Linux 文件系统结构一般由以下几个目录组成,每个目录承担不同的功能:

5.1.3 什么是根文件系统
Linux系统中的“根文件系统”位于整个文件系统的最顶端,类似于一棵大树的根部,所有其他的文件和目录都挂载(mount)在这个根目录(/)之下。Linux不使用盘符(如C:、D:等)来区分不同的存储设备或分区,而是采用这种树状结构来组织和管理文件。
简而言之,根文件系统是Linux系统启动时首先挂载的文件系统,它包含了系统启动和运行所必需的基本文件和目录。这个根目录(/)是访问所有其他文件和目录的起点,其他文件系统(如/home、/usr等)则作为子目录或独立文件系统挂载到根目录下。因此,根文件系统是Linux文件系统的核心和基础。

5.1.4 根文件系统制作工具
注意这里,ubuntu也属于文件系统构建工具。

Buildroot 简介
Buildroot 是一个用于构建嵌入式 Linux 系统的开源框架,通过 Makefile 脚本和 Kconfig 配置文件实现。它允许用户从源码构建完整的 Linux 系统,包括文件系统,支持高度定制和灵活的交叉编译环境。
优势:
- 源码构建:提供高度的灵活性和定制性。
- 交叉编译:支持快速构建针对特定硬件的系统。
- 配置便捷:通过 Kconfig 轻松配置系统组件。
Yocto 简介
Yocto Project 是另一套构建嵌入式系统的工具,与 Buildroot 不同,它采用模块化设计,每个模块(meta 包)负责不同的功能或硬件支持。
优势:
- 多架构支持:包括 ARM、MIPS、PPC 等。
- 设备仿真:通过 QEMU 支持各种设备仿真。
- 高度灵活:支持公司级定制,创建内部 Linux 发行版。
Ubuntu 简介
Ubuntu 是一个流行的开源 Linux 发行版,以友好的用户界面和强大的桌面系统著称。它也提供企业版 Ubuntu Enterprise Linux。
优点:
- 技术支持好:广泛的社区和官方支持。
- 用户界面友好:适合桌面和初学者。
- 硬件兼容性好:广泛的硬件支持。
Debian 简介
Debian 是一个由自由软件组成的 Linux 发行版,以其稳定性和对 Unix 传统的坚守而闻名。
优点:
- 稳定:经过严格测试,确保稳定性。
- 干净环境:提供干净的作业环境。
- 包管理:采用基于 Deb 的 APT 包管理系统。
缺点:
- 技术支持:不提供官方技术支持。
- 发行周期:稳定版本软件可能过时。
- 中文支持:中文支持相对较弱。
Busybox 工具简介
Busybox是一个开源的工具集合,专为嵌入式系统设计,提供了许多标准的Unix工具和命令。它通过将多个常用的Unix工具和命令整合到一个单独的可执行文件中,实现了轻量级的嵌入式系统。
Busybox包含了Shell、文件操作命令、文本处理工具、网络工具、系统管理命令等功能,适用于嵌入式Linux系统、路由器、嵌入式设备、手机等各种设备。其优势在于体积小、资源占用低,非常适合资源有限的嵌入式设备。
Buildroot与Busybox的区别
- 功能定位:
- Busybox:专注于提供一个轻量级的Unix工具集,是嵌入式系统中常用的工具集合。
- Buildroot:则是一个构建嵌入式Linux系统的自动构建框架,通过Makefile脚本和Kconfig配置文件,可以从源码构建完整的、可直接烧写到机器上运行的Linux系统。
- 构建范围:
- Busybox:主要用于提供工具集,并不直接参与整个系统的构建过程。
- Buildroot:不仅包含了Busybox作为其基本工具集的一部分,还负责构建整个系统的其它部分,如boot、kernel、rootfs以及rootfs中的各种库和应用程序。
- 使用方式:
- Busybox:通常作为嵌入式系统中的一个组件,由开发者根据需要集成到系统中。
- Buildroot:提供了一个完整的构建系统,开发者可以通过配置和编译Buildroot来生成一个完整的嵌入式Linux系统镜像。
- 灵活性与可定制性:
- Busybox:虽然可裁剪,但主要是针对其内部包含的命令和工具进行裁剪。
- Buildroot:提供了更高的灵活性和可定制性,不仅可以裁剪Busybox中的命令,还可以选择需要包含的软件包、库和工具,以及定制系统的其它方面。
第六章 GDB常用指令
| run | 启动程序执行,直到遇到断点或程序结束 |
| break(或b) | 在指定位置(如行号、函数名等)设置断点 |
| continue(或c) | 继续执行程序,直到遇到下一个断点或程序结束 |
| next(或n) | 执行下一行代码,不进入函数内部 |
| step(或s) | 执行下一行代码,进入函数内部 |
| print(或p) | 打印变量或表达式的值 |
| info locals | 显示当前作用域的所有局部变量及其值 |
| info breakpoints | 显示当前所有断点信息 |
| delete 断点号 | 删除指定编号的断点 |
| disable 断点号 | 禁用指定编号的断点 |
| enable 断点号 | 启用指定编号的断点 |
| list(或l) | 显示源代码,可指定行号或函数名 |
| finish | 继续执行程序,直到当前函数完成返回 |
| set args 参数 | 设置程序运行时的命令行参数 |
| info registers | 显示当前寄存器的值 |
| backtrace(或bt) | 显示当前调用堆栈 |
| frame 栈帧号 | 切换到指定的堆栈帧 |
| display 表达式 | 设置跟踪变量,每次程序暂停时自动显示其值 |
| undisplay 变量名编号 | 取消对先前设置的跟踪变量的跟踪 |
| watch 表达式 | 设置观察点,当表达式值改变时停止程序执行 |
| until 行号 | 运行程序直到指定行号处停止 |
| jump 行号 | 直接跳转到指定行号处执行 |
| quit(或q) | 退出GDB调试器 |



















 2070
2070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











