






 本文提出了一种新方法,在共享多智能体强化学习中引入多样性,旨在鼓励智能体表现出不同的行为,同时保持必要的协作。通过优化智能体身份与其轨迹之间的互信息,方法在保持参数共享的好处的同时,实现了智能体多样性与群体协调之间的平衡。实验结果表明,该方法在Google Research Football和星际争霸II微管理任务等多个基准测试中达到了最先进的性能。
本文提出了一种新方法,在共享多智能体强化学习中引入多样性,旨在鼓励智能体表现出不同的行为,同时保持必要的协作。通过优化智能体身份与其轨迹之间的互信息,方法在保持参数共享的好处的同时,实现了智能体多样性与群体协调之间的平衡。实验结果表明,该方法在Google Research Football和星际争霸II微管理任务等多个基准测试中达到了最先进的性能。
题目:Celebrating Diversity in Shared Multi-Agent Reinforcement Learning
出处:Neural Information Processing Systems 34(NeurIPS 2021),人工智能的顶级会议。
摘要:最近,深度多智能体强化学习(MARL)已显示出解决复杂合作任务的前景。它的成功部分是由于智能体之间的参数共享。然而,这种共享可能导致智能体行为类似,并限制其协调能力。在本文中,我们的目标是在共享多智能体强化学习的优化和表示中引入多样性。具体而言,我们提出了一种信息理论正则化,以最大化智能体身份及其轨迹之间的互信息,鼓励广泛探索和多样化的个性化行为。在表示中,我们在共享神经网络架构中加入了智能体特定模块,这些模块通过L1范数进行正则化,以促进agent之间的学习共享,同时保持必要的多样性。实证结果表明,我们的方法在Google Research Football和超硬星际争霸II微管理任务上实现了最先进的性能。
1,介绍
近年来,合作多智能体强化学习(MARL)引起了越来越多的兴趣,这为解决许多现实世界的挑战性问题提供了前景,如传感器网络[1]、交通管理[2]和机器人群的协调[3]。然而,学习这种复杂的多智能体系统的有效策略仍然具有挑战性。一个中心问题是,联合行动、观察空间随着智能体数量呈指数增长,这对学习算法的可伸缩性提出了高要求。
为了解决这一可扩展性挑战,广泛使用共享参数的策略分散(PDSP),其中智能体共享其神经网络权重。参数共享显著提高了学习效率,因为它显著减少了策略参数的总数,而一个智能体的经验和梯度可用于训练其他智能体。享受这些优势,许多先进的深层泥灰岩方法采用了PDSP范式,包括基于价值的方法[4-8]、政策梯度[9-13]和通信学习算法[14、15]。这些方法在星际争霸II微管理等任务上实现了最先进的性能[16]。
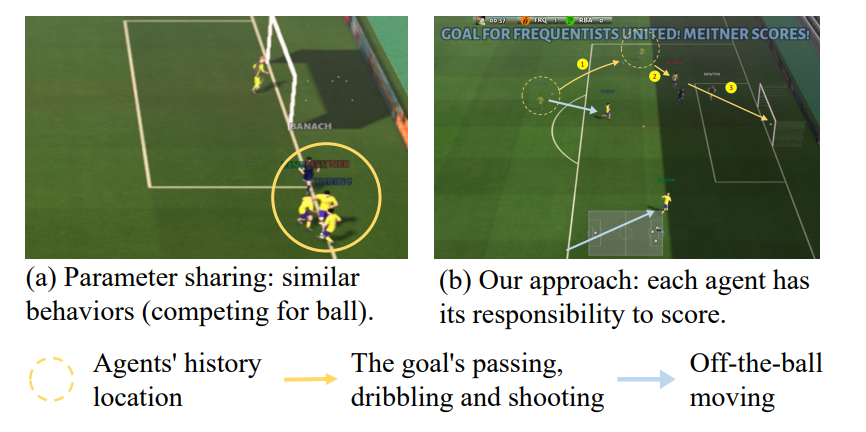
虽然已证明参数共享可加速训练[17],但其缺点在复杂任务中也很明显。这些任务通常需要大量的探索和智能体之间的多样化策略。当参数共享时,智能体倾向于获得同质行为,因为它们通常在相似的观察下采取相似的动作,从而阻止有效的探索和复杂的合作策略的出现。这种趋势对于许多具有挑战性的多智能体协调任务变成难以解决的问题,阻碍了MARL的广泛应用。例如,Google Research Football(图1和[18])上最先进的MARL算法的不令人满意的性能突出了对多样化行为的迫切需求。
图1:共享参数会诱发行为(左),在挑战性的谷歌足球研究任务中很难学习到成功的策略。我们的方法通过权衡多样性和共享来学习复杂的合作策略(右图)。
值得注意的是,为了分集而牺牲参数共享的优点也是不利的。与人一样,分享必要的经验或对任务的理解可以广泛加速合作学习。如果没有参数共享,智能体将在更大的参数空间中搜索,这可能是浪费,因为它们不需要一直表现不同。因此,问题是如何自适应地权衡多样性和共享。在本文中,我们通过提出几种结构和学习的新方法来解决这一难题。
为了鼓励多样性,我们提出了一个新的信息理论目标,以最大化智能体身份和轨迹之间的相互信息。这一目标使每个智能体能够将自己与其他智能体区分开来,因此涉及所有智能体的贡献。因此,我们通过学习作为个体Q-函数组合的总-Q函数,得出了激励多样性的内在奖励,并利用全局环境奖励对其进行优化。在结构上,我们进一步将单个Q-函数分解为共享和非共享局部Q函数之和,以共享经验,同时保持表示多样性。我们希望智能体能够尽可能使用和扩展共享知识。因此,我们在每个非共享Q函数上引入L1正则化,鼓励智能体在必要时在几个关键动作上共享和多样化。结合这些创新,实现了多样性和同质性之间的动态平衡,有效地促进了适应性和复杂的合作。
我们以谷歌研究足球(GRF)[18]和星际争霸II微管理任务(SMAC)[16]为基准测试我们的方法。我们的方法在具有挑战性的基准任务上的出色表现表明,我们的方法实现了比基线更高的协调能力,同时将多样性作为更稳健和人才政策的催化剂。据我们所知,我们的方法在SMAC超硬地图和具有挑战性的GRF多智能体任务(如academy_3_vs_1_with_keeper、academy _counterattack_hard和全场场景3_vs_1-with_ keeper(全场))上实现了最先进的性能。
2,背景
完全合作的多智能体任务可以表示为Dec POMDP[19],其定义为元组
,其中
是
个智能体的有限集合,
是环境的真实情况,
是动作集,
是折扣系数。在每个时间步骤中,每个智能体
接受他自己的观察
根据观察函数
,选择动作
这导致联合作用向量
。然后,环境基于转移函数
转移到新的状态
,并得到由所有智能体共享的全局奖励
。每个智能体都有自己的动作观察历史
。由于部分可观测性,每个智能体将其策略
限制在
上。联合策略
导出联合作用值函数
。
2.1,集中训练,分散执行
我们的方法采用了集中训练和分散执行(CTDE)[9、20、4、5、21、22、6、11]的框架。该框架通过分散控制策略,同时采用集中训练来学习合作,从而应对指数级增长的联合行动空间。智能体通过访问全局信息以集中方式学习,但根据其本地动作观察历史执行。实现CTDE框架的一种有希望的方法是值函数分解。IGM(个体全局最大值)原则[21]保证了局部和全局贪婪行为之间的一致性。当IGM满足时,智能体可以简单地选择使每个智能体的个体效果最佳函数
最大化的局部贪婪行为来实现全局行为。
3,方法
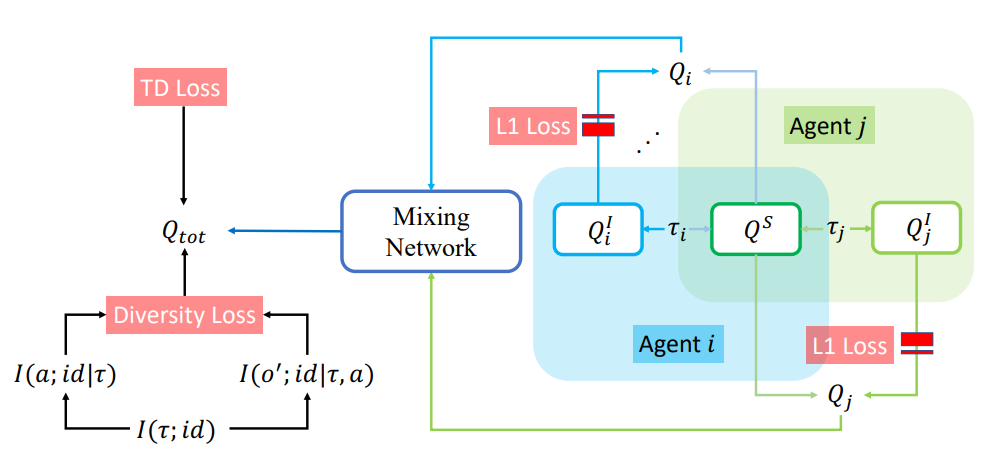
在本节中,我们提出了一种新的多样性驱动的MARL框架(图2),该框架平衡了每个主体的个体性和群体协调,这是一种可以与现有CDTE值分解方法相结合的通用方法。
图2:我们方法的示意图。
3.1,个体意识多样性
我们首先介绍如何通过设计内在动机来鼓励行为多样性。直观地说,为了鼓励个体轨迹的特殊性,智能体需要以不同的方式强调自己与他人,采取不同的行动,访问不同的地方观察。为了实现这一目标,我们使用信息理论目标,最大化个体轨迹和智能体身份之间的相互信息:
其中
和
分别是智能体的局部轨迹和身份的随机变量,
为了优化等式1,我们将
扩展为
,并且
扩展为
。 因此,互信息可以写成:
第一项由环境决定,我们可以在优化互信息时忽略它。第二项量化了当给定身份时关于智能体的动作选择的信息增益,它将行动意识多样性度量为:
。然而,
通常是
贪婪,其仅区分具有最高可能性的动作。因此,直接优化该项隐藏了关于局部Q函数的大部分信息。为了解决这个问题,我们使用局部Q值的Boltzmann softmax分布来代替
(3)
该不等式成立,因为KL散度
是非负的。我们最大化这个下界以优化第2项。受变分推理方法[24]的启发,我们通过引入由
参数化的变分后验估计器
,推导并优化了每个时间步长的项3的可处理下界:
(4)
与第2项类似,不等式成立,因为对于任何
是非负的。直观地说,优化等式4鼓励智能体具有不同的观察值,这些观察值可通过智能体的识别来区分,因此将观察感知多样性测量为
。为了收紧这个下界,我们使KL散度相对于参数
最小。更新
基于等式3和等式4所示的下限,我们引入了内在奖励,以优化信息理论目标(等式1),以鼓励不同行为:
我们引入了两个标度因子
,计算内在奖励。当
时,我们仅优化互信息目标(等式1)中的熵项
。
用于调整策略多样性相对于转移多样性的重要性。在附录A中,我们讨论并比较了估算
和
的两种不同方法。
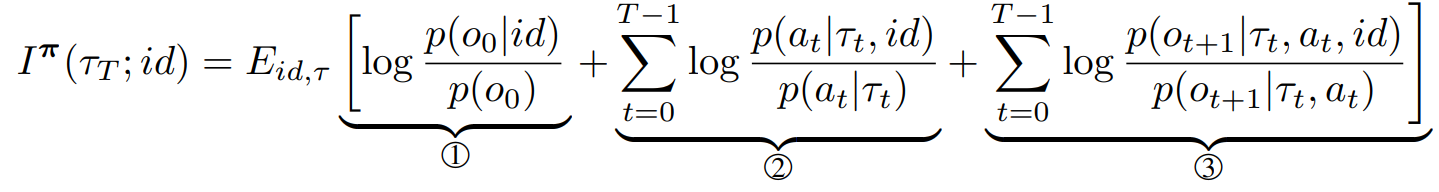
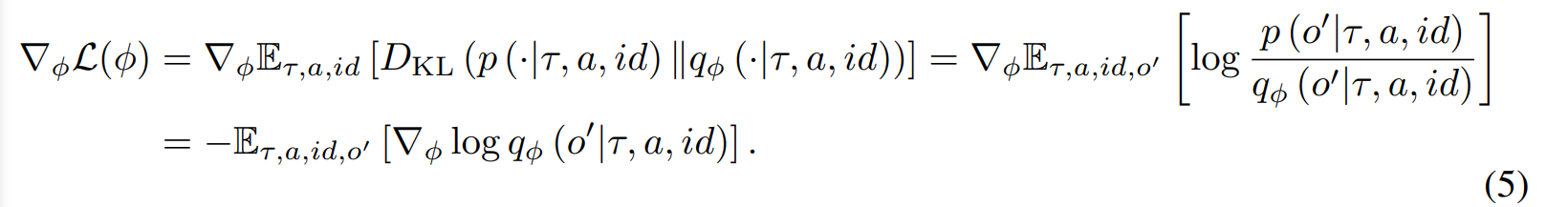
3.2,平衡多样性和共享的行动价值学习
在上一节中,我们介绍了一个信息理论目标,以鼓励每个智能体行为不同于一般轨迹。然而,共享的局部
函数没有足够的能力为每个智能体呈现不同的策略。为了解决这个问题,我们还为每个智能体
配备了一个单独的局部Q函数
。定义需要分享或专门学习的经验是低效的,通常不能一概而论。因此,我们让智能体自适应地决定是否通过将
其中
是智能体之间的共享
应用L1正则化,如图2所示。这种正则化还可以防止智能体过于多样化,忽略协作以完成任务。在我们的实验中,我们表明L1正则化对于实现多样性和协作之间的平衡至关重要。
3.3,总体学习目标
在本节中,我们将讨论如何使用多样性激励奖励来训练拟议的学习框架。由于内在奖励
不可避免地涉及所有智能体的影响,我们将
中,并使用以下TD损失:
其中
是整个框架中的参数,
是从
是调整与环境奖励相比的内在奖励权重的超参数。我们使用QPLEX将
分解为局部
其中
是
是独立
是比例因子。
4,案例研究:仅在必要时通过多样化超越
我们设计了图3所示的Pac-Men,以演示我们的方法如何工作。在该任务中,四个智能体在中心房间初始化,并且只能观察它们周围的5×5网格。在每个边缘房间中随机初始化三个点。为了使环境更具挑战性,通往不同房间的路径长度不同。为了使环境更具挑战性,通往不同房间的路径具有不同的长度,它们是:下:左:上:右=4:8:12:8。四条路径中有三条超出了智能体的观察范围,这带来了探索的困难。点将在所有房间空后随机刷新。智能体之间的无效竞争发生在他们聚集在一个房间时。总的环境奖励是一步吃掉的点的数量,如果没有人吃点,则为-0.1。此环境的时间限制设置为100步。
图3:为什么我们的方法有效?意识到身份的多样性和经验分享之间的平衡鼓励了复杂的战略。
图3-middle展示了我们方法的学习策略,热图显示了访问次数。在个体轨迹和身份之间相互信息的目标驱动下,智能体实现了多样性并分散在不同的房间中吃点。我们在图3中进一步分析了独立和共享
,其中
表示不同动作
我们注意到,与四个边缘房间相比,中心房间和四条路径的
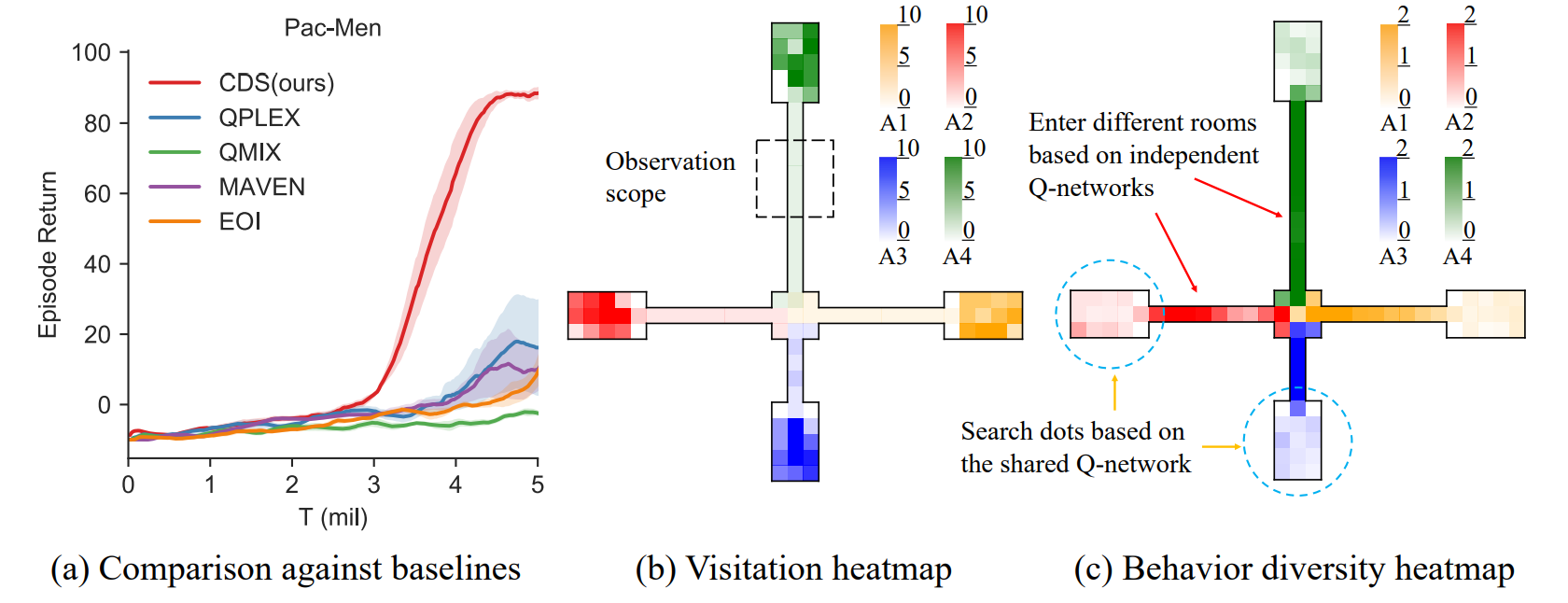
5,相关工作
近年来,深度多智能体强化学习算法取得了显著进展。COMA[20]、MADDPG[9]、PR2[27]和DOP[10]研究了基于策略的多智能体强化学习问题。他们使用(分解的)集中式批评家来计算分散参与者的梯度。基于价值的算法将联合价值函数分解为单个效用函数,以实现高效优化和分散执行。VDN[4]、QMIX[5]和QTRAN[21]逐步扩展了混合网络的表示能力。QPLEX[6]通过将IGM原理编码为双工双工网络架构来实现完整的IGM类[21]。加权QMIX[23]提出了加权投影来分解任何联合作用值函数。还有其他工作从协调图[28-30]、沟通[31、32、15]和基于角色的学习[17、33]的角度研究了MARL。
从IQL[34]到QPLEX的MARL知识共享,许多工作侧重于设计混合网络结构,并提供了有前景的经验和理论结果。对于这些工作,智能体之间的经验共享是一个重要组成部分。向他人学习是人类基因中的一项基本技能,它可以在社会中生存。基于人类社会中教师和学生之间的关系,一系列研究工作希望每个主体都能向他人学习或选择性地与他人分享其知识[35-37]。但在实践中指定的知识很有挑战性,更不用说决定分享或学习什么了。SEAC[38]通过共享仅用于非策略训练的轨迹,部分解决了这个问题。NCC[32]通过邻居之间的表示对齐来保持认知一致性。Roy等人[39]强制每个智能体预测其他人的本地政策,并为团队经验调整添加一名教练。Christianos等人[40]在预训练期间对智能体进行分组,并强制同一组中的智能体使用一个策略。在本文中,我们不试图让智能体选择是学习还是分享经验。图2所示的神经网络结构可以通过梯度反向传播来平衡组协调和多样性。
多样性在单智能体环境中,多样性用于探索或解决稀疏奖励问题。现有的方法,如好奇心驱动算法[41-44]或最大化相互信息[45-47],已显示出巨大的前景。在鼓励泥灰岩环境中的多样性时,必须考虑智能体的协调。最近的一些工作研究了这个问题,如MAVEN[25]、EITI&EDTI[48]和EOI[26]。MAVEN借助于探索的潜在空间学习各种单调近似集合。EITI和EDTI考虑成对相互影响,以鼓励智能体之间的相互依赖。EOI结合来自内在值函数(IVF)和总Q函数的梯度来训练每个智能体的局部Q函数。在本文中,我们通过优化agent身份和轨迹之间的互信息,鼓励agent探索独特的轨迹。此外,我们提出了一种新的网络结构,以实现经验共享或共识,它结合了所有智能体的罕见想法,同时仍然保持独立的行动价值函数,以便每个智能体在必要时表现不同。我们的方法考虑了知识共享和多样性之间的权衡关系,并学会在联合任务解决中建立平衡和利用它们的优势。
6,实验
在第4节中,我们使用一个玩具游戏来说明我们的方法如何自适应地平衡体验共享和身份感知多样性。在本节中,我们使用GRF和SMAC基准中的挑战性任务,进一步演示和说明我们方法的优越性。我们将我们的方法与基于多智能体价值的方法(QMIX[5]、QPLEX[6])、变分探索(MAVEN[25])和个体涌现(EOI[26])进行了比较。与基线不同,在计算局部Q函数时,我们不在输入中包含智能体的标识。我们展示了我们的方法、基线和使用五个随机种子测试的消融性能的平均值和方差。
6.1,谷歌研究足球(GRF)的表现
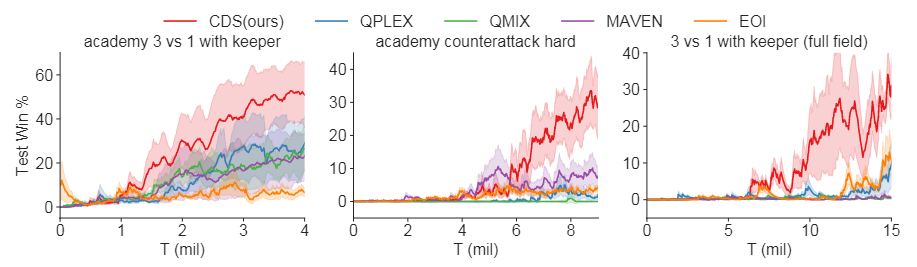
图4:我们的方法与Google Research Football上的基线算法的比较
我们首先在三个具有挑战性的谷歌研究足球(GRF)进攻sce上对我们的方法进行了基准测试-narios academy_3_vs_1_with_keeper、academy _counterattack_hard和我们自己设计的全场场景3_。每个场景的智能体初始位置如附录B.3所示。在GRF任务中,智能体需要协调组织进攻的时间和位置,以抓住稍纵即逝的机会,只有得分才能获得奖励。在我们的实验中,我们控制除了守门员之外的左侧球员(黄色)。右侧玩家是由游戏引擎控制的基于规则的机器人。智能体具有19的离散动作空间,包括八个方向的移动、滑动、射击和传球。观察包含自我主体、其他主体和球的位置和移动方向。还包括球的z坐标。
我们对半场进攻场景做了一个小而合理的改变:如果球员或球回到我们的半场,我们将输球。所有基线和消融都使用此修改进行测试。环境奖励只发生在游戏结束时。如果他们赢了,他们将得到+100,否则得到-1。
我们在图4中显示了与基线的性能比较。我们的方法优于所有场景。MAVEN需要更多的时间来探索复杂的策略,证明CDS激励更有效的探索。EOI允许每个智能体通过设置本地学习目标同时考虑个性和合作,但没有专用的Q网络,使得合作和个性难以持续协调。相比之下,利用部分共享的网络结构,CDS智能体学习不同但协调的策略。例如,如图1所示,三个智能体具有不同的行为,第一个智能体传球,第二个智能体得分,而第三个智能体跑动威胁。这些不同的行为密切协调,形成了一个完美的评分策略,并导致显著优于EOI。
6.2,星际争霸2的性能
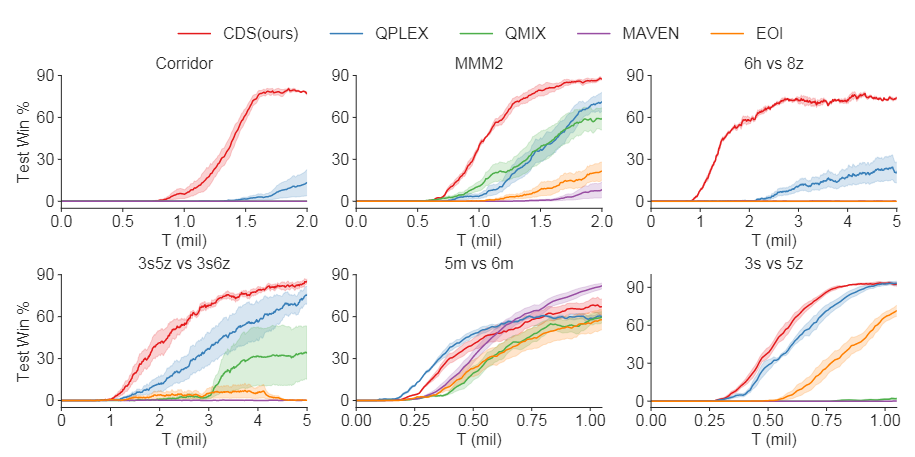
图5:我们的方法与四个超硬SMAC地图上的基线算法的比较:走廊、MMM2、6h_vs_8z和3s5z_vs_3s6z,以及两个硬SMAC图:5m_vs_6m和3s_vs_5z。
在本节中,我们将在星际争霸II微管理(SMAC)基准上测试我们的方法[16]。该基准由分类为易、硬和超硬的各种地图组成。在这里,我们在四个超硬地图上测试了我们的方法:走廊、MMM2、6h_vs_8z和3s5z_vs_3s6z,以及两个硬SMAC地图:5m_vs_6m和3s_vs_5z。对于四个超硬图,我们的方法优于所有基线,在随机种子之间具有可接受的方差,如图5所示。基线QPLEX和QMIX可以在一些具有挑战性的基准上实现令人满意的性能,如3s5z_vs_3s6z和MMM2。但在其他图上,它们需要提出的多样性庆祝方法来获得更好的性能。与MAVEN和EOI相比,我们的方法在学习复杂合作时保持了多样性和同质性之间的平衡。我们的方法在两个硬地图的基线上表现类似,表明我们的平衡过程可能无法提高在需要纯同质性的环境中的学习效率。但对于复杂策略难以探索的具有挑战性的环境,我们的方法可以有效地搜索具有稳定更新的有价值策略。
6.3,消融和可视化
为了理解拟议CDS框架中每个组件的贡献,我们进行了消融研究,以测试其三个主要组件的贡献:身份感知多样性(A)鼓励和部分共享(B)基于非共享Q函数的L1正则化神经网络结构(C)。为了测试成分A,我们将内在奖励分为四个不同级别。(1) CDS Raw通过将等式8中的
。(3) CDS无作用通过将等式6中的
设置为零,消融等式2中的项目2。(4) CDS-No-Obs通过消融
消融等式2中的项目3−等式6中的。为了测试组件B,我们设计了CDS,其与L1损失一起消融独立的动作值函数,并与基线一样,将智能体识别添加到输入中。为了测试分量C,我们设计了CDS-No-L1,通过将等式9中的λ设置为零,消除L1正则化项。
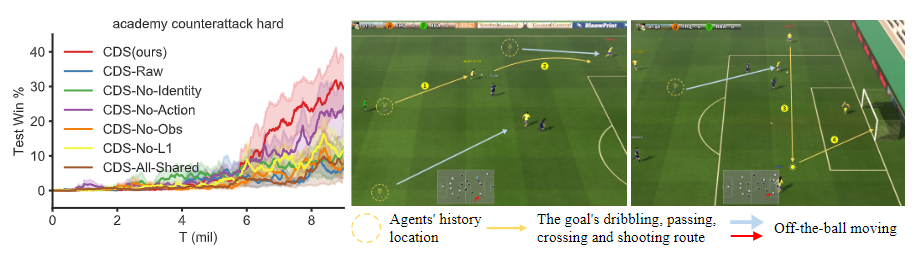
图6:左侧。academy_Countersack_hard的消融研究。正当经过培训的政策的可视化,通过令人印象深刻的非球移动策略实现复杂的合作。
我们首先对academy_counterattack_hard进行了消融研究,以分析我们的创新中的哪一部分导致了出色的性能,如图6左侧所示。消融我们内在奖励的每一部分将导致性能显著下降。其中,对性能影响最小的是行动感知多样性的消除。CDS-No-L1的性能类似于MAVEN,这表明无限多样性对合作有害。CDS All Shared的性能甚至比QPLEX更差,这表明如果没有我们专门设计的网络结构,身份感知多样性很难出现。
我们在图6的右侧进一步可视化了最终的训练策略,图6显示了智能体之间的复杂合作。我们的球员首先通过带球和传球从边路进攻。当球穿过禁区时,其中一个球引起了对方后卫和守门员的注意。另一名球员接住球,完成投篮。我们复杂策略中最令人印象深刻的部分是无球移动策略。所有没有球的球员都试图利用他们独特而有价值的动作创造更多的得分机会,这表明了完成进球的行为和位置多样性。
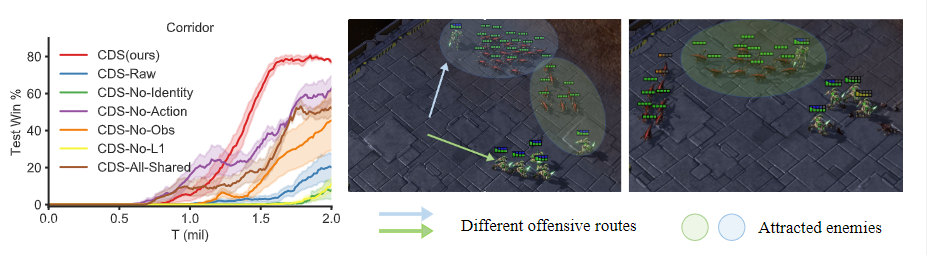
图7:左侧。超硬地图走廊中的消融研究。正当最终训练策略的可视化,实现了战士牺牲带来的来之不易的胜利。
我们还对超硬标测图走廊进行消融研究,如图7左侧所示。与academy_counterattack_hard的结果相同,行动感知多样性的消除导致最小的性能差距。在所有消融中,CDS-No-L1和CDS-No-Identity表现最差,其性能类似于QPLEX。这一现象表明,过度多样性不利于复杂合作的出现。CDS All Shared实现了可接受的性能,与GRF场景不同,反映了这两种基准的表示多样性的不同需求水平。
为了更好地解释为什么我们的方法表现良好。在走廊上,我们还将图7中的最终策略可视化。在这张超硬地图中,六个友方狂热者面对24个敌方小狗。数量上的差异意味着,如果我们的特工一起攻击,他们注定会失败。一名狂热者,其路线以蓝色突出显示,成为一名战士,离开队伍,吸引蓝椭圆形区域内大多数敌人的注意。虽然注定要牺牲,但他为球队带来了足够的时间,以消除绿色椭圆形中的一小部分敌人。之后,另一个狂热者站出来吸引一些敌人,使队友能够消灭他们。这些复杂的策略反映了多样性和同质性之间的杠杆作用,鼓励代理人只在必要时多样化。
7,结束语
观察到多智能体之间的行为多样性对于许多具有挑战性和复杂的多智能体任务至关重要,在本文中,我们在共享多智能体强化学习中引入了一种新的机制,即在必要时保持多样性。我们的CDS方法导致的个体多样性和群体协调之间的平衡,在保持参数共享利益的同时,推动了具有挑战性的基准任务的深层泥灰岩的最新发展。我们希望我们的方法能够为未来的工作提供启示,以激励agent与多样性合作,进一步探索复杂的多agent协调问题。

















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









