







mysql笔记
基础-注意的点
- 显示表结构
describe/desc table
- 比较运算符 =
之类的 如果是数值和字符串,则会将字符串转为0比较,两边都是字符串的比较acsll码
- 安全等于 <=>
为null而生,1=null=0(false)如果不是安全等与于 1=null=>null
-
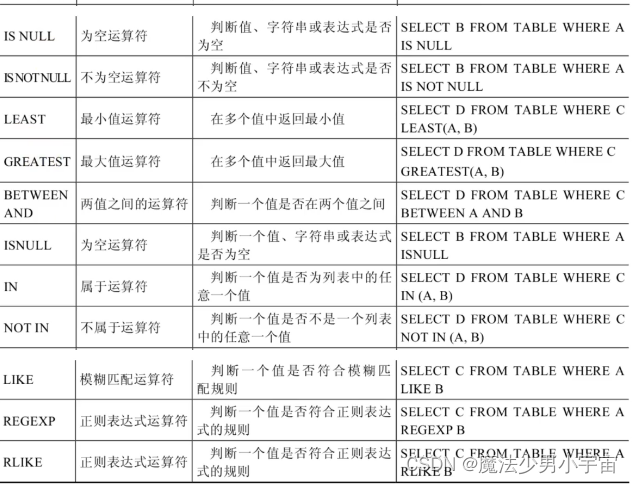
常用运算函数
-
_代表一个不确定性字符

-
mysql 8.0 limit 的新写法

-
给表取了别名,则select和where中使用了别名就必须用别名
-
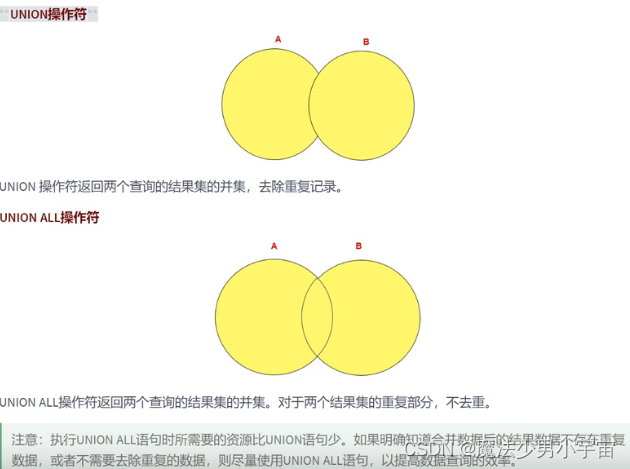
union & unionall
-
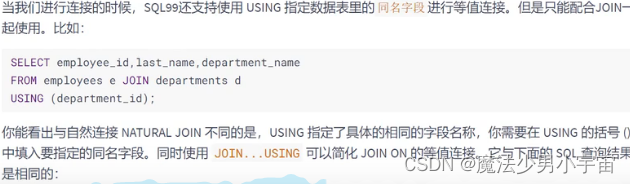
sql99 新语法 自然连接 nature join,using

-
数值函数基本函数

-
三角函数

-
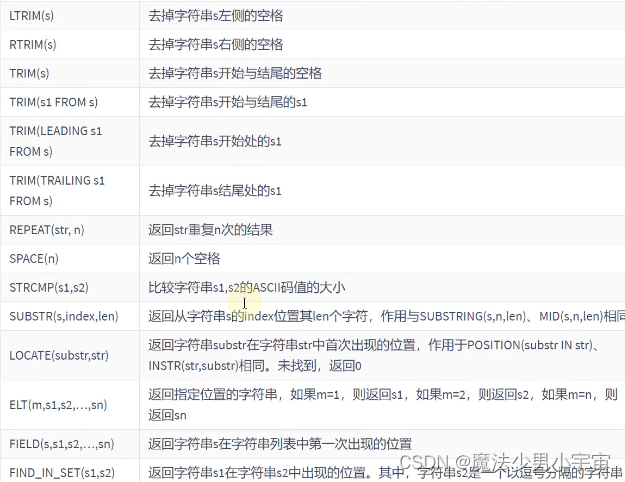
字符串函数

-
流程控制函数
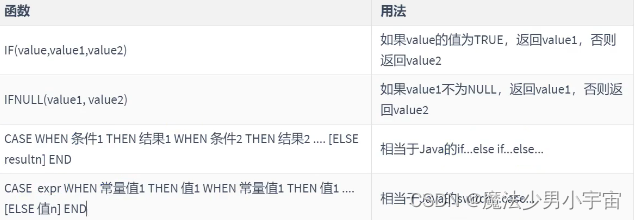
if /case when
-
加密函数 MD5(Str) ,0SHA(str),8.0弃用PASSWORD encode decode函数
-
benchmark 函数, 可以测试mysql表达式执行的耗时时间
-
benchmark
*
-
计算总数
count(常量/字段/*) 建议使用常量,使用字段当字段值为null时,不参与计算,导致数据误差

-
group by
grou by函数使用后,select的字段必须出现在group by 中,或者使用聚合函数查询未出现的字段
-
having vs where
1.使用在group by 之后,一般使用前提是sql中使用了group by
2.过滤条件又聚合函数,使用having
3.过滤条件无聚合函数都可以用 建议用where,效率更高

-
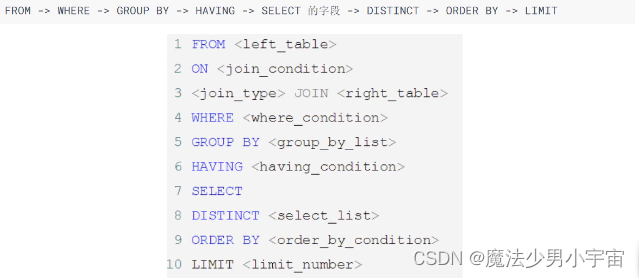
sql的书写顺序 & 执行顺序

-
多行比较符 in any all some


-
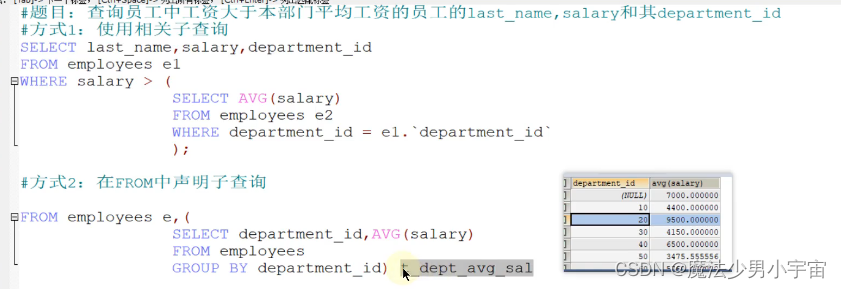
相关子查询
-
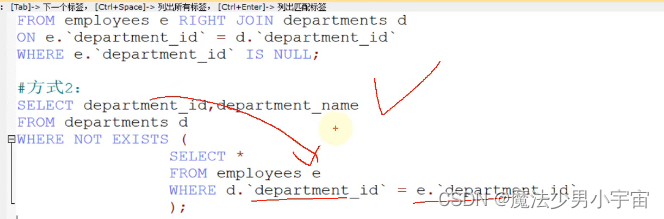
exists/ not existss 相关子查询
-
创建table特别的方式,包括数据都会复制,如果select结果为空就不会复制数据
create table as select a ,b from c…
-
清空表
TRUNCATE TABLE 清空数据,保留结构,不支持回滚
delete -
DCL中的commit和rollback
提交数据,一旦提交,不能回滚
rollback 可以执行回滚到最近的一次commit -
列级约束 & 表级约束 & 唯一性约束

1.可以向声明为唯一建的列添加 null,并且可以多次添加

-
视图的创建
1.create view view_name [(字段)] as select xxx
2.create view view_name as select a 别名 b ...也可以from另外一个视图 -
视图的修改

create or replace ..还有其他的方式 -
存储过程的理解


-
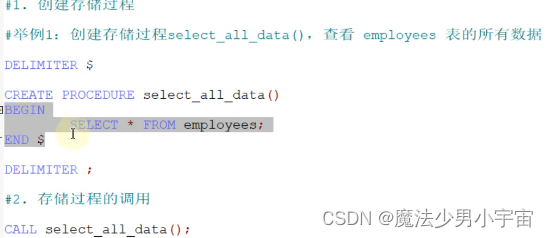
存储过程的创建
阿里禁止使用存储过程

-

-
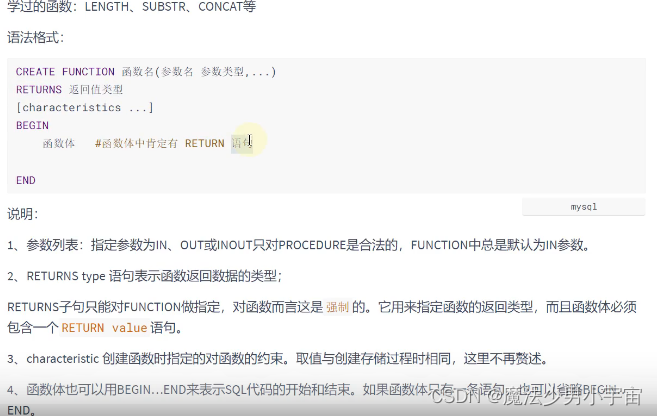
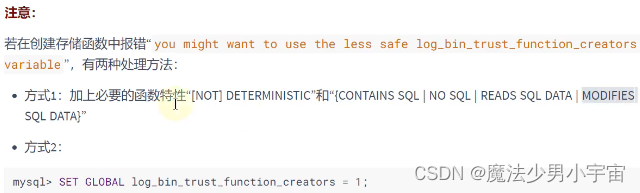
存储函数
-
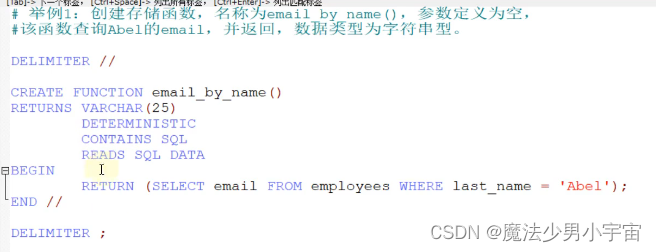
示例
-
存储过程和存储函数的对比
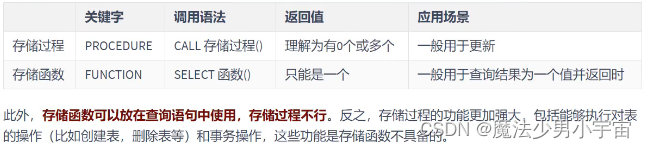
-
查看存储过程 & 函数
1.
show create PROCEDURE/FUNCTON 具体某一个的名字
2.show PROCEDURE/FUNCTON like (%具体某一个的名字%) -
触发器

-
创建触发器
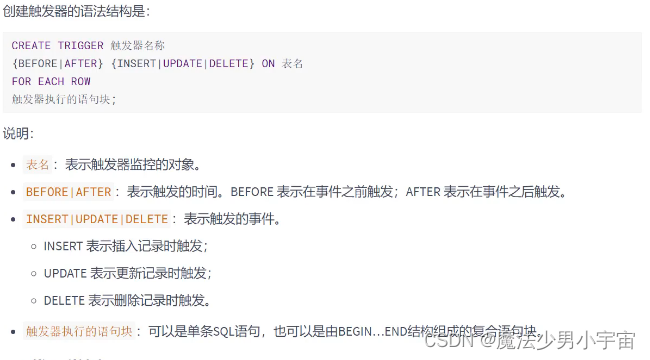
-
mysql的大小写敏感

-
Mysql 文件结构

-
mysql 服务端逻辑架构
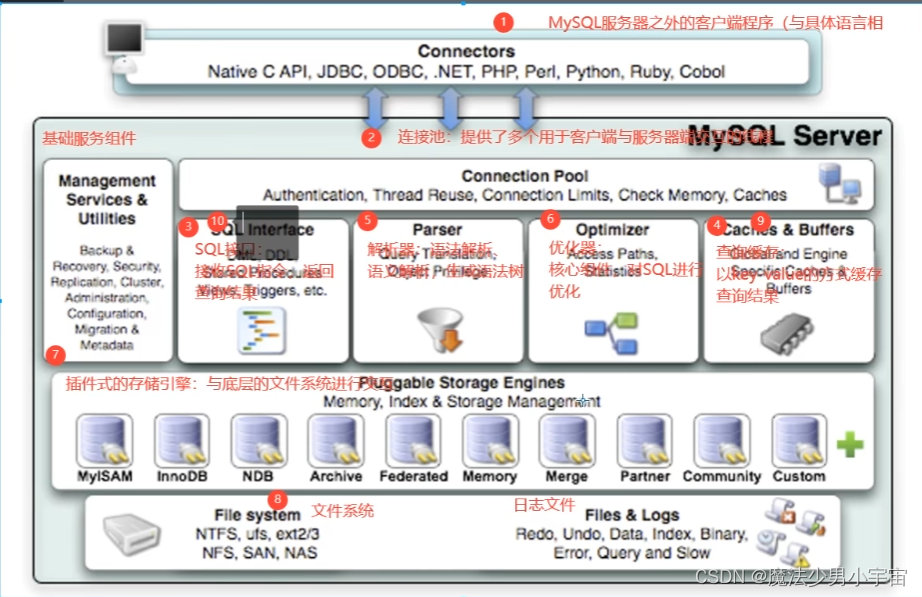
-
连接层(TCP连接池和线程池)
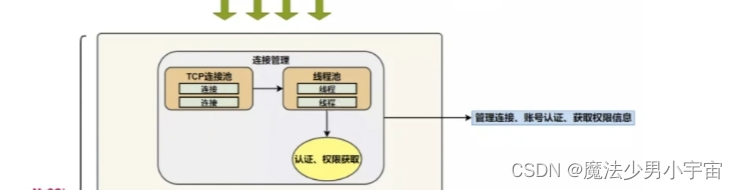
-
mysql 5.70开始不推荐查询缓存,8.0开始移除查询缓存
-
sql执行流程

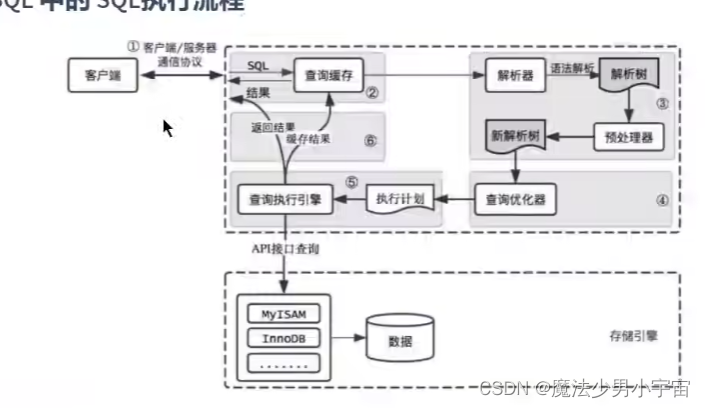
- 查询sql执行流程
- set @@profiling=1
- 执行sql
- show profiles
- show profile for query {id}

- mysql引擎介绍

- innodb 支持事务,行锁(高并发),外键,崩溃重启断点回复且无额外操作,处理效率稍差,缓存索引和数据,对内存要求较高->索引即数据
- myisam 不支持行锁支持表锁,不支持事务,外键,崩溃后无安全恢复,比较节省资源
- archive 仅支持插入和查询,支持索引,不可修改,拥有良好的压缩机制,主要用于日志和数据归档,
- 页的内部空间

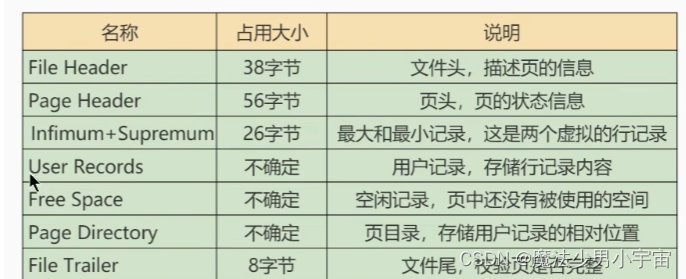

- 文件头校验和

- 联合索引删除字段对索引的影响

- 隐藏索引

适合创建索引的场景
-
字段唯一

-
频繁作为where条件的字段
-
经常group by & order by的字段
注意: 当查询既有group by you又有oder by的时候,如果想这两个都生效索引,需要建立联合索引,且 group by 的字段要出现在前面
-
update 和delete的where条件
-
distinct 的字段需要添加索引
-
多表连表的时候创建索引
注意:
1.连表的数量尽量不超过三张
2. 对where 条件字段创建索引
3. 对用于连接的字段创建索引 ,且字段的类型要一致,类型不一致就会使用函数转换,导致索引失效 -
使用字符串前缀创建索引
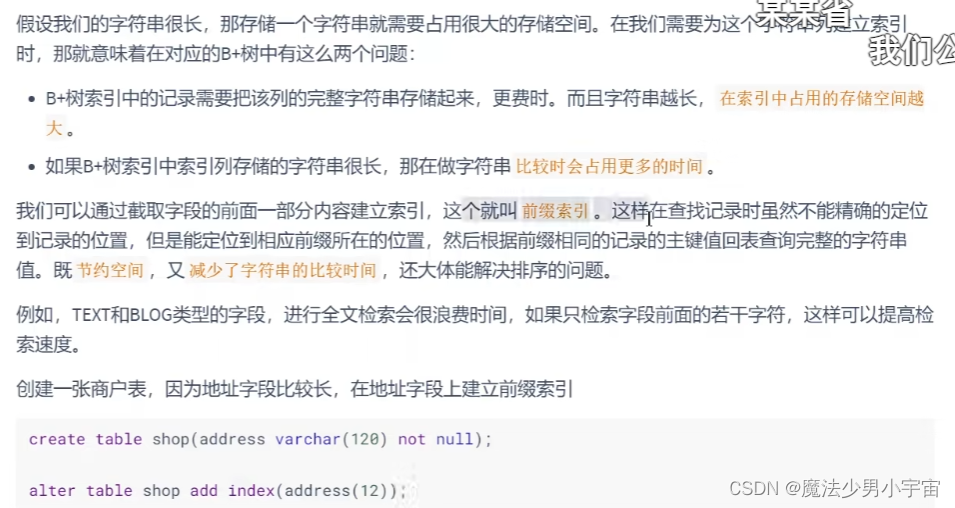
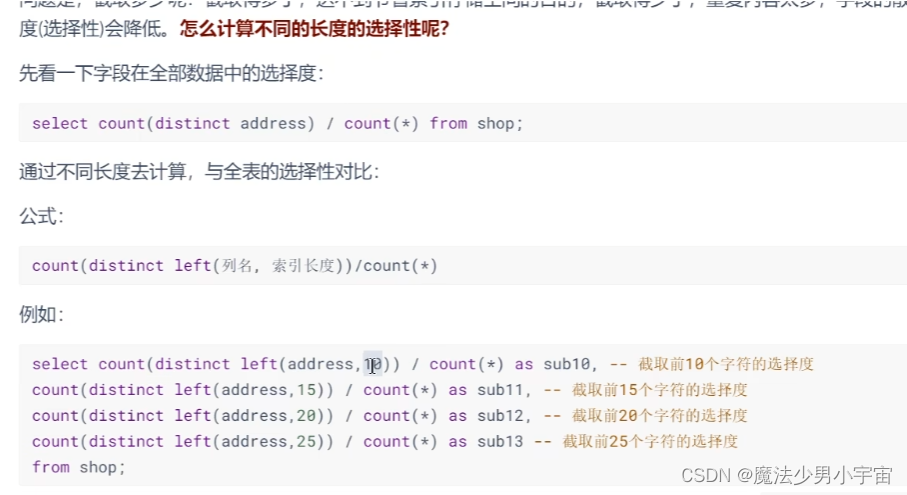
注意:

-
散列程度高的列适合做索引字段

-
使用最频繁的列放在联合索引的最左侧
-
在多个字段都要使用索引的情况下,联合索引优于单值索引
-
限制索引的数目
- 建议单张表的索引数量不超过6个
- 每个索引都要占用磁盘空间
- 索引会影响insert delete update的性能
- 优化器在选择如何优化查询时,会对每一个可以用到的索引评估,以产生一个新的执行计划,如果同时有多个索引可以用于查询,会增加mysql优化器生成执行计划时间,降低查询的性能
不建议使用索引的地方
- 在where 中用不到的字段
- 数据量小的列
- 有大量重复的列上不建立索引 (数据重复度超过10%不建议对该字段使用索引)
- 避免对经常更新的表创建过多的索引
- 不建议用无序的值作为索引(在索引比较时要转化为ASCLL)
- 不定义冗余和重复的索引
mysql服务器调优思路
慢查询定位
- 开启mysql服务器记录慢查询日志
1. show variables like '%slow_query_log%' 2. set slow_query_log = 'on' - 设置慢查询阈值
1. show variables like '%long_query_time%'
2. set long_query_time=xx秒 - 查看慢查询数据
show gloabl status like '%Slow_queries%'注意:

- 使用工具 命令行下使用 mysqldumpslow
- 关闭慢查询日志(影响性能)
- 定位到慢查询sql之后 使用 show profile 或explain
- set profiling=‘on’
- show profile
- show profile cpu… for query {query id}
10.explain
explain的使用
-
版本说明

-
语法
explain /describe sql -
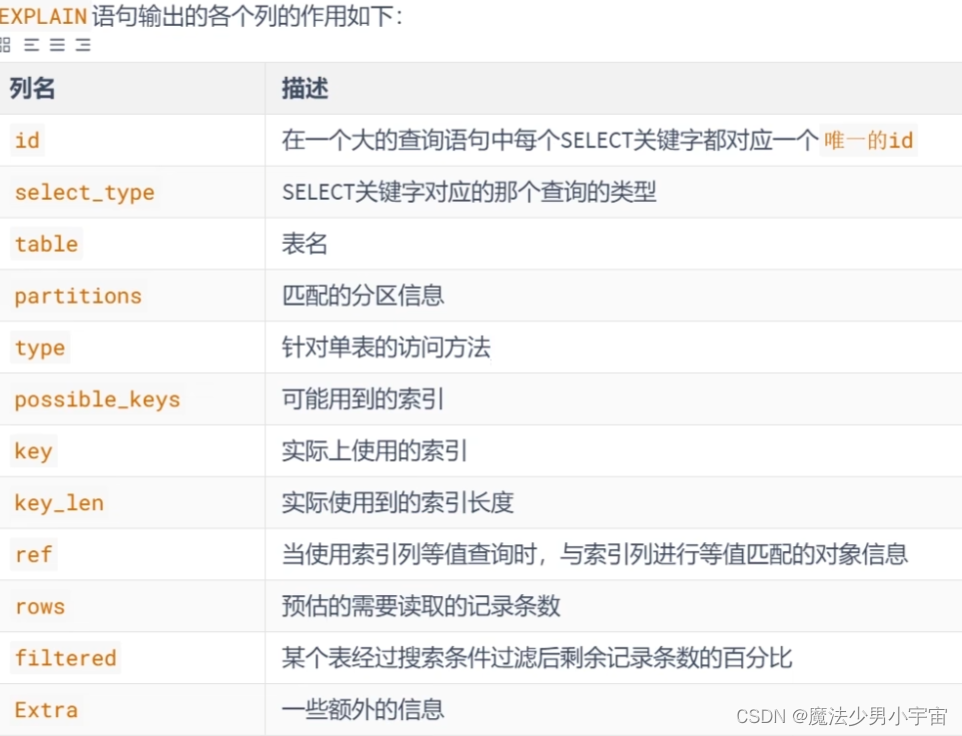
explain结果列说明
-
各列说明
-
table 表名
查询的每一行记录都对应一个单表,有几个表就会有几行记录 -
id, 一个大的sql查询语句每个select关键字对应一个id
查询优化器可能对设计子查询的查询语句进行重写

union会去重


注意:
1. id如果相同,可以认为是一组,从上往下顺序执行
2. 在所有组中,id值越大,优先级越高,越先执行
3. 关注点,id号每个号码,表示一趟独立的查询,一个sql的查询躺输越少越好
-
-
select_type







-
partition 分区
-
type, 执行查询是的访问类型

-
key 和possible_key

-
key_len 实际使用到的索引长度,值越大越好,主要针对联合索引有意订购参考意义
-
ref,与索引列对比的类型
-
rows 预估要读取的记录数 越小越好
-
filtered:查询条件过滤后剩余数据 越大越好 ,在连接查询时有意义
-
extra
- explain四种格式

慢sql分析之trace

索引失效的场景
失效场景
- select *
- 最左原则使用部分字段

- 插入的主键不是自增,忽大忽小,建议AUTO_INCREMENT
- 计算,函数,类型转换(自动(隐式)/手动)导致索引失效
- 范围条件右侧的列失效(可以将范围条件放在最后,并且调整索引字段顺序,范围的字段在最后)
- 不等于会使索引失效
- is null 可以使用索引,is not null 不能使用索引
- like以通配符开头(‘%xx’)会使索引失效
- or 前后存在非索引的列
- 数据库和表统一使用utf8mb4,不同字符集会存在 转换
- 示例:

- 建议

关联查询的优化
- 左外连接
连接的字段最后驱动表(小表)添加索引,最后都加索引 - 内连接
对于内连接来说,查询优化器可以决定谁作为驱动和被驱动表,如果连接条件中只能有一个字段有索引,则有索引的字段所在表会被作为驱动表,当两个表的连接条件都存在索引时,会用数据小的表作为驱动表 - join原理(增加join buffer大小)

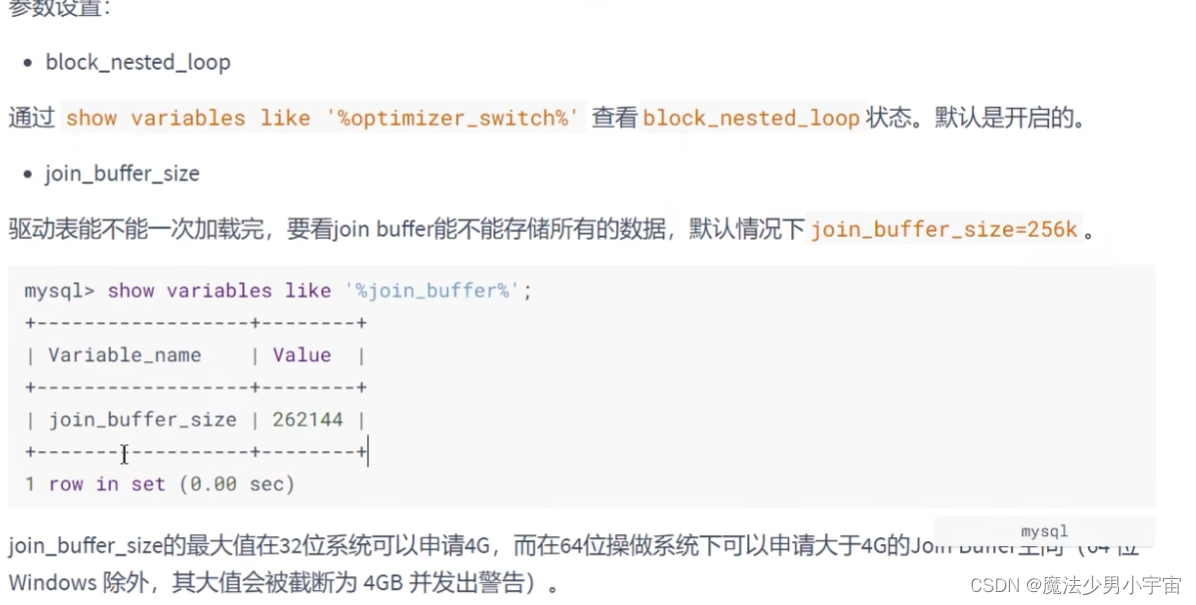
小结:

- hashjoin

子查询优化
尽量用join代替子查询


排序优化

注意:
- order by 顺序错了,不同字段desc asc顺序不一致不会使用索引
- 小结:

- filesort及两种算法


- filesort 优化

group by 优化

优化分页查询
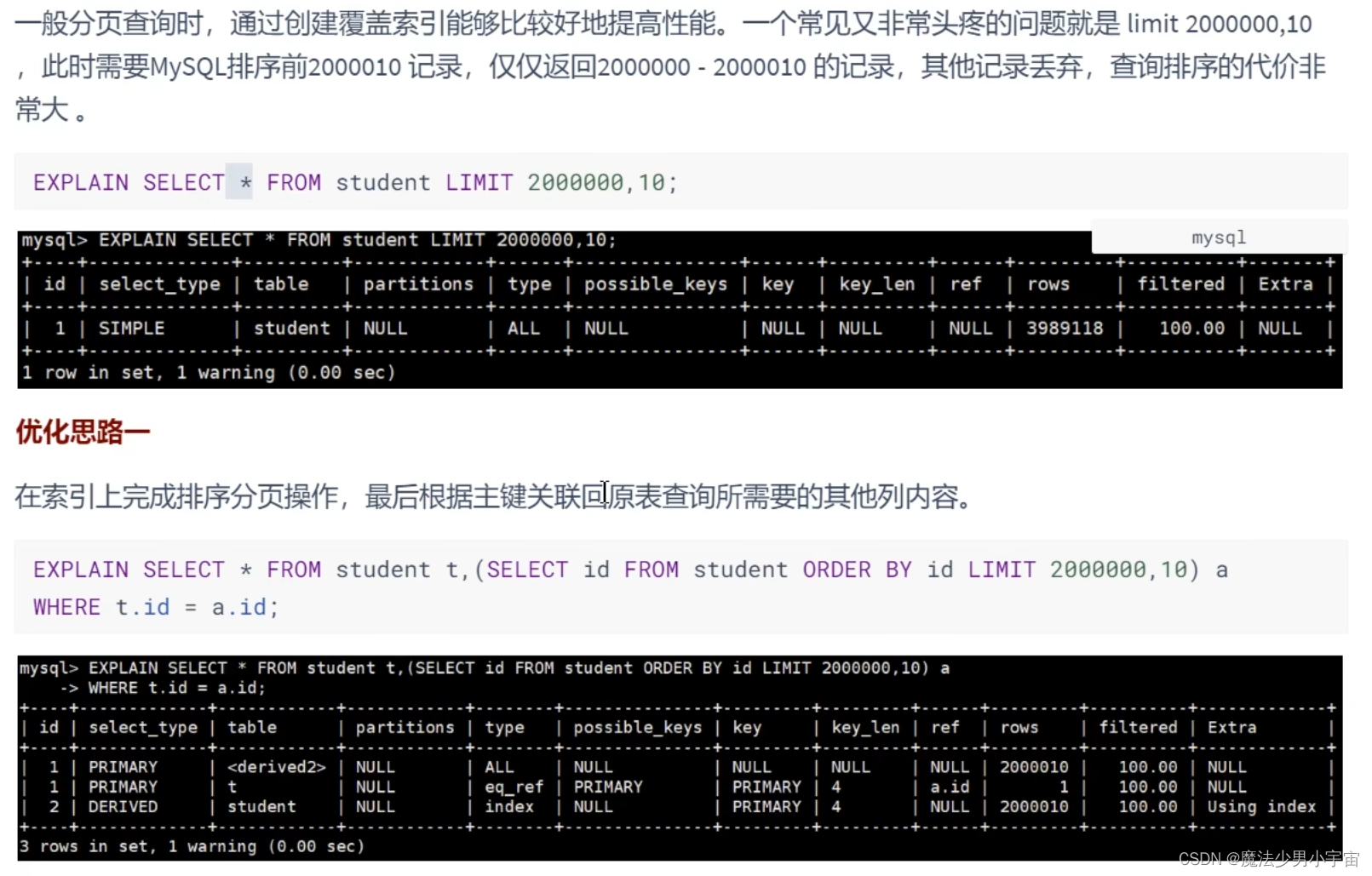
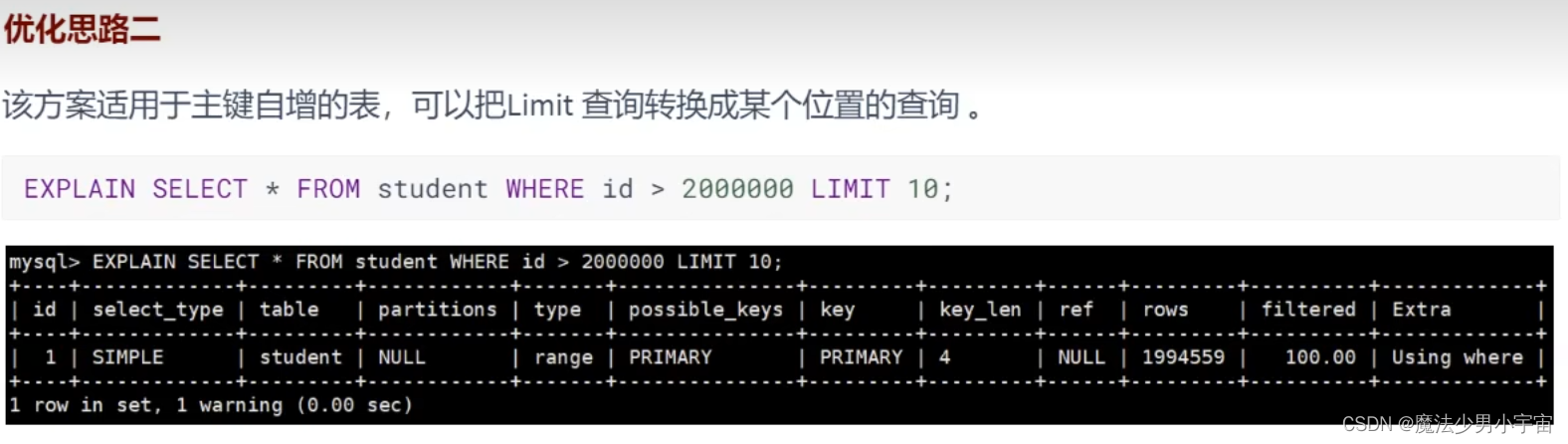
覆盖索引
如果一个索引包含(或覆盖)所有需要查询的字段的值,称为‘覆盖索引’。即只需扫描索引而无须回表。
覆盖索引可能让<>(!=)使用索引
使用不等于不一定不使用索引,下面的使用了覆盖索引,编译器发现不用回表,还能使用索引,就会用到索引


同理也可能让前置模糊查询使用索引
覆盖索引的利弊
- 好处
- 避免Innodb表查询回表
- 可以把随机io变成顺序IO加快查询效率

- 坏处
- 索引字段的维护需要代价,可能需要建立冗余索引来支持覆盖索引
索引下推(ICP)
开启和关闭
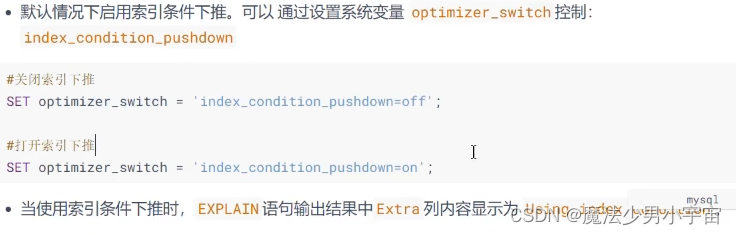
概念说明
在条件字段出现索引字段比如有个索引是 a,b两个子段的联合索引,where a=xx and b like '%xx',理论上这里b的索引会失效,索引下推的意思就是针对b这种有索引但是索引失效的字段,会先执行过滤,然后再将数据回表,可以减少(回表)io的次数,提升效率
Extra一列里 Using index condition,这就是用到了索引下推。只适用于二级索引,通常针对联合索引
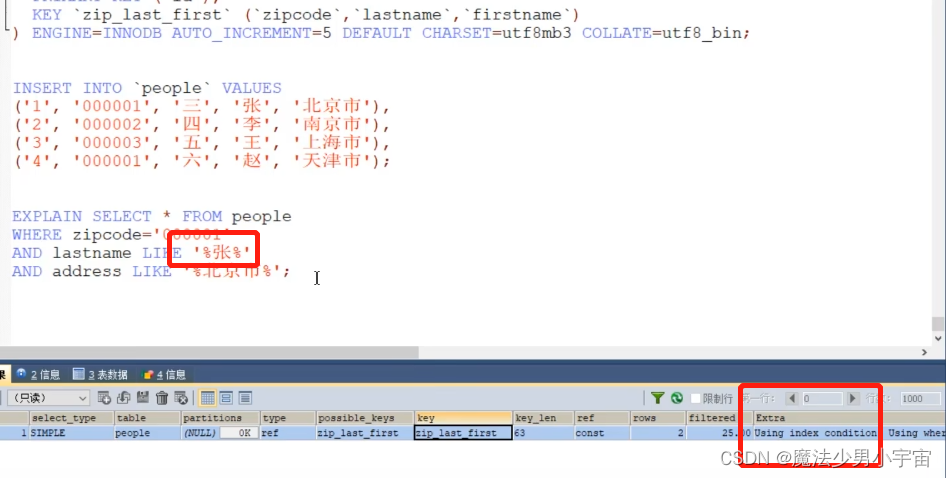
使用條件

EXISTS 和 IN 的区分

为什么要小表驱动大表
count(*) 和count(1) 和count(字段)

count(*) 和count(1) 都是统计行数,而count(字段) 是统计字段列非null的行数
自增id的设计
自增id的问题
-
可靠性不高:存在自增id回溯的问题,直到8.0才修复
-
自增id回溯:假设我们设置id自增为1,插入三条数据,然后这时删除一条记录,这时候用SHOW CREATE TABLE命令查看该表的AUTO_INCREMENT的值是4,然后重启数据库,再次查看会发现AUTO_INCREMENT变成了3
原因就是AUTO_INCREMENT的值是保存在内存中的,数据库重启后会计算当前表的记录数然后重新设置导致回溯出错
-
安全性不高:对外暴露的接口容易暴露信息,如/usr/1,很容易被爬虫进行数据爬取
-
性能差:需要在mysql服务端进行生成
-
交互多:业务需要根据执行一次lase_insert_id获取刚才插入的自增值,多一次sql对于海量并发系统就多很多性能消耗
-
局部唯一性:自增的id只在当前数据库唯一,无法用于分布式系统
建议
非核心业务:对应表的主键自增id,如告警、监控、日志信息等数据量较小的表
核心业务:主键设计至少是全局唯一而且自增的,全局唯一是为了保证分布式之间的唯一性,自增则是保证插入数据的性能,防止忽大忽小的主键导致页分裂影响性能如mysql8.0支持的自增uuid **在MySQL 8.0版本,将自增值的变更记录在了redo log中,重启的时候依靠redo log恢复重启之前的值。**
范式


一范式
原子性,字段值不可拆分

二范式
主键的完全依赖

三范式
非主属性之间要相互独立

事务
mysql中只有Innodb引擎支持事务
事务的特性(ACID)
- Atomacity 原子性
- Consistency一致性

- Isolation 隔离性
一个事务不能被其他事务干扰
- Duration 持久性
一旦事务提交,改变是永久的,除非下一次再修改
事务的状态
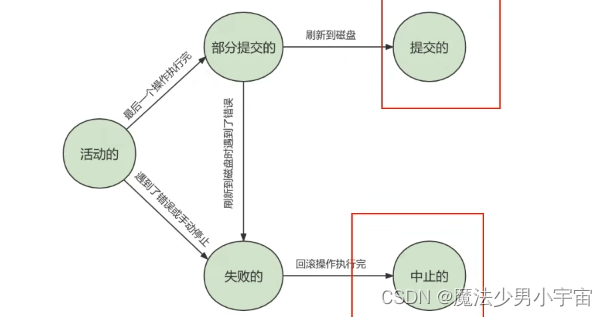
- 活动的
- 部分提交的
- 失败的
- 中止的
- 提交的
事物的完整过程
- 开启事务
- 业务操作
- 提交或中止
显示事务
1.开启 start transaction 或 begin
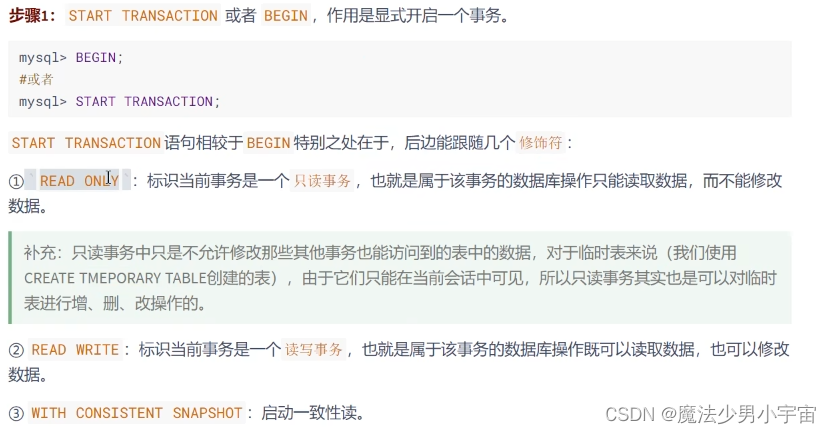
隐式事务

mysql的completion_type对事务的影响

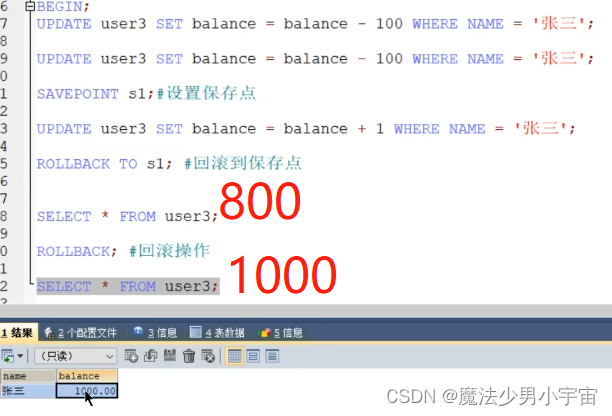
savepoint
事务隔离级别
数据并发问题
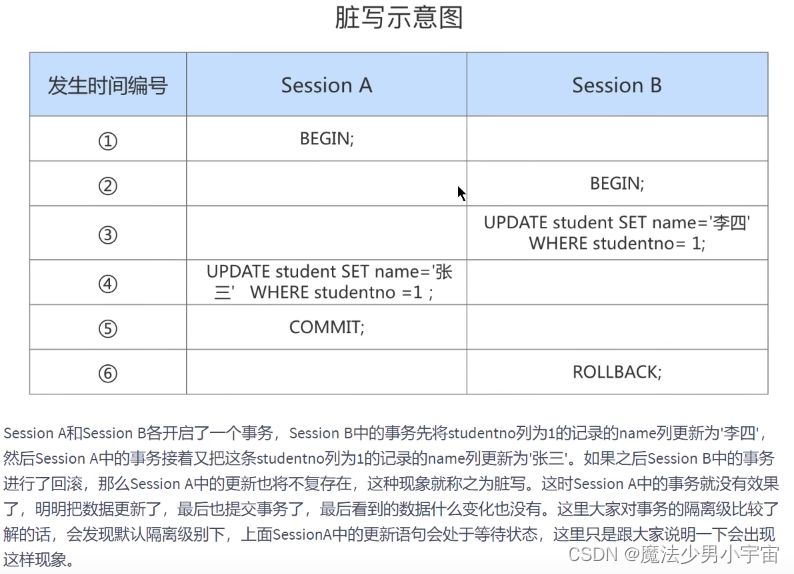
脏写
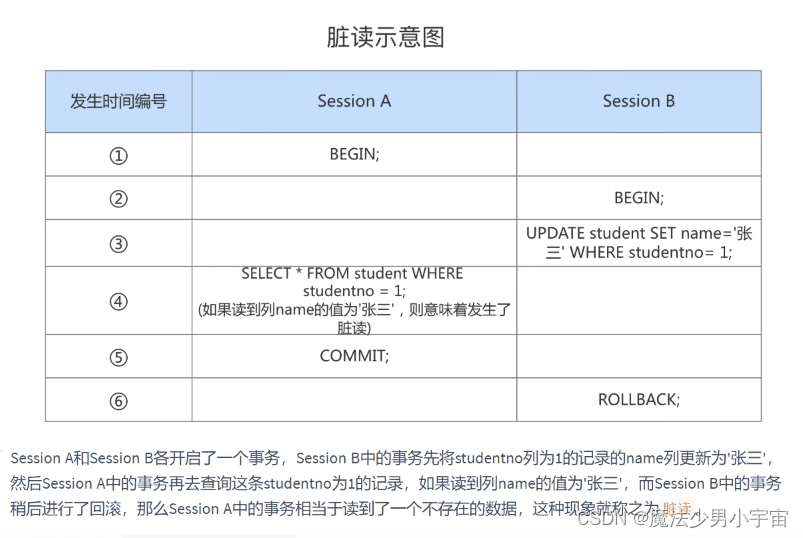
脏读
不可重复读

幻读

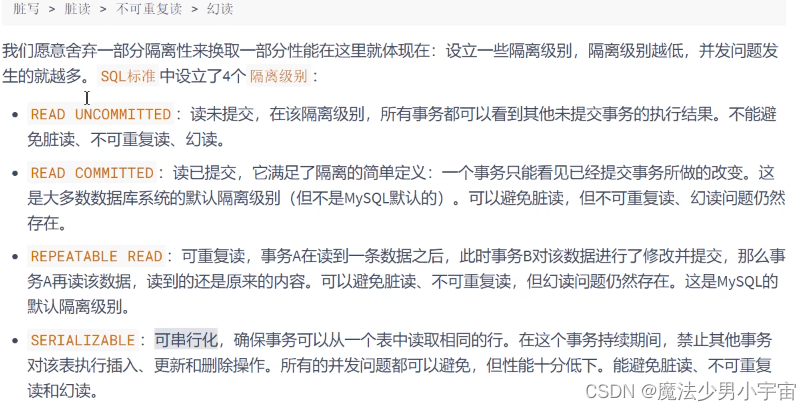
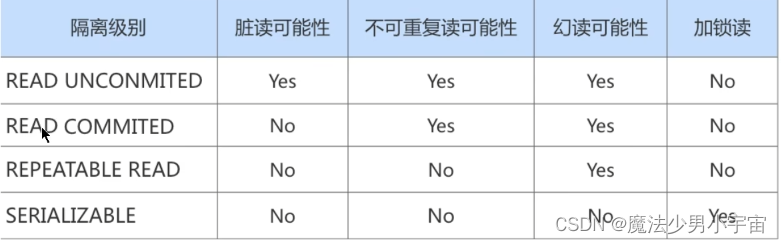
SQL中的四种隔离级别(mysql默认可重复读)
mysql事务日志
- 事务的隔离性由锁解决
- redo log 保证持久性
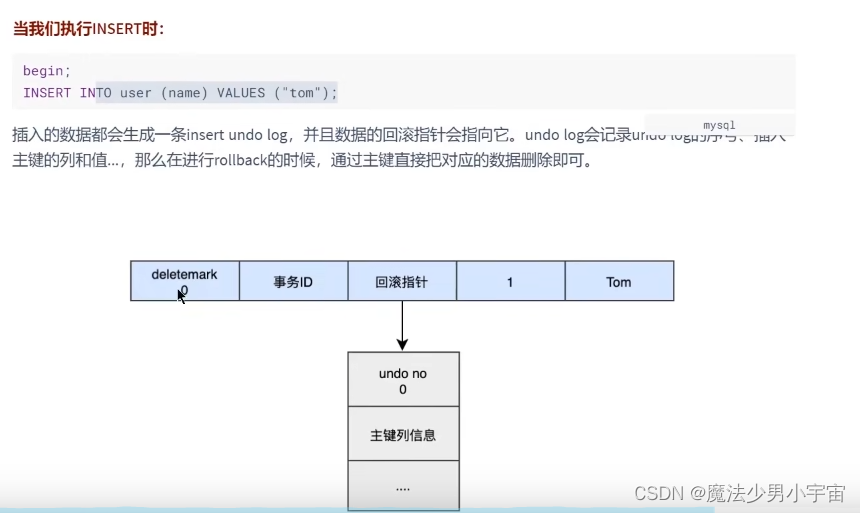
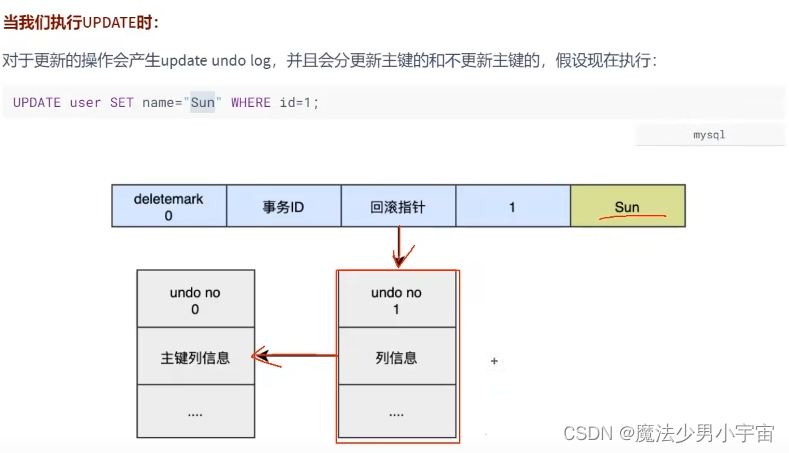
- undo log 保证原子性 一致性

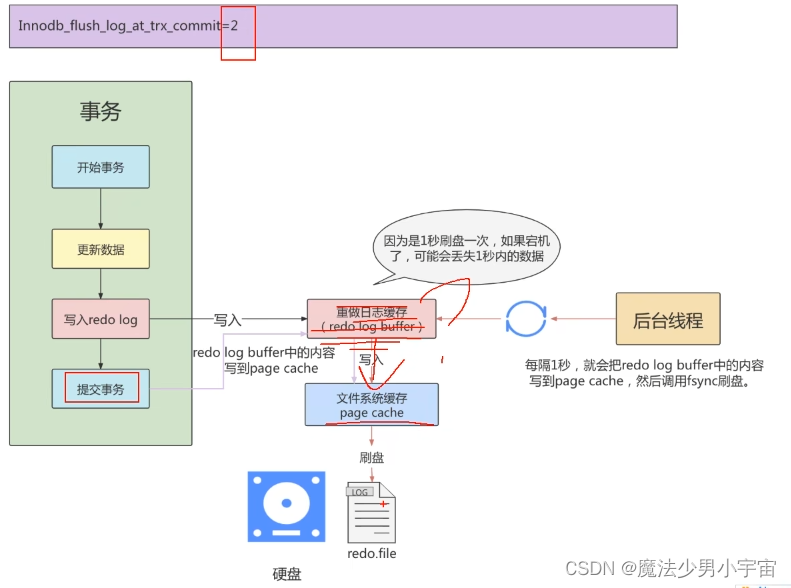
redo 日志




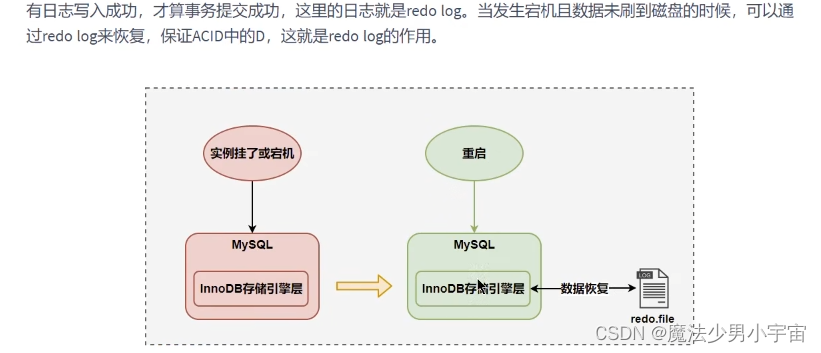
Innodb_flush_log_at_trx(默认为1,刷盘的频率会影响插入的性能)



undo日志
记录的是更新之前的数据,更新包括insert delete update,undo log本身也会产生redo log

作用
- 回滚数据

- mvcc
详细生产过程


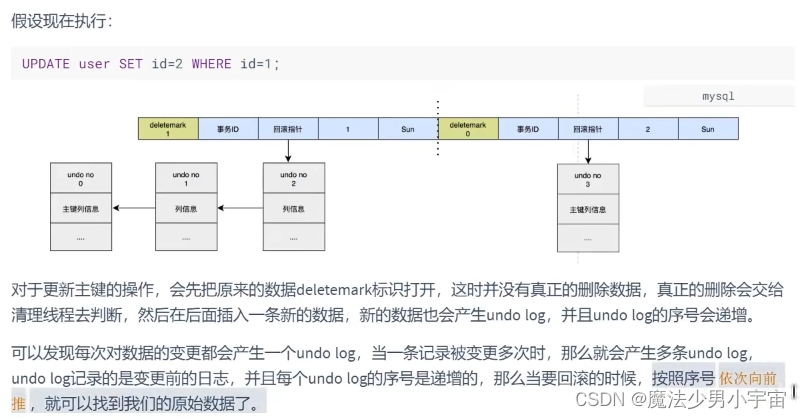

小结 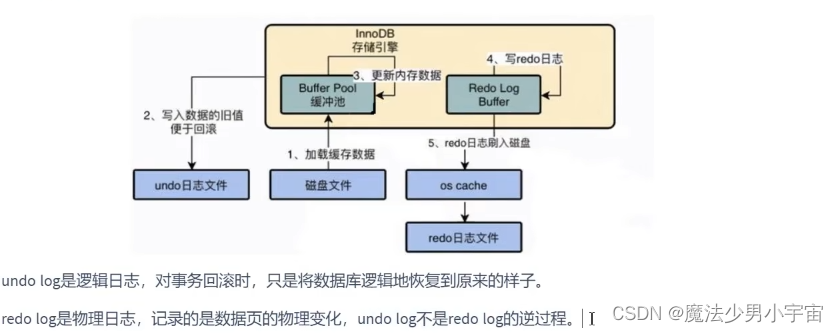
锁

表锁

意向锁


行锁

行间隙锁
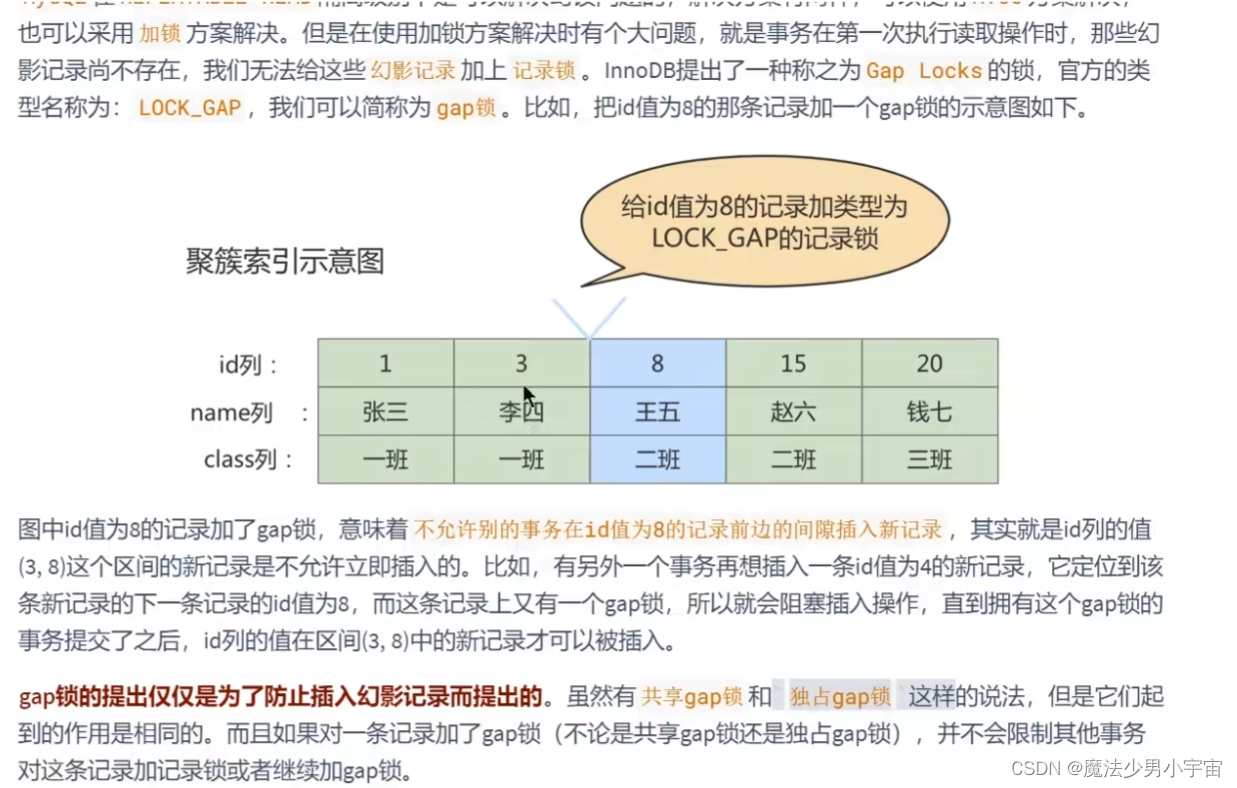
临键锁=间隙锁+记录锁
x/s锁 = 独占和共享锁 悲观锁和乐观锁
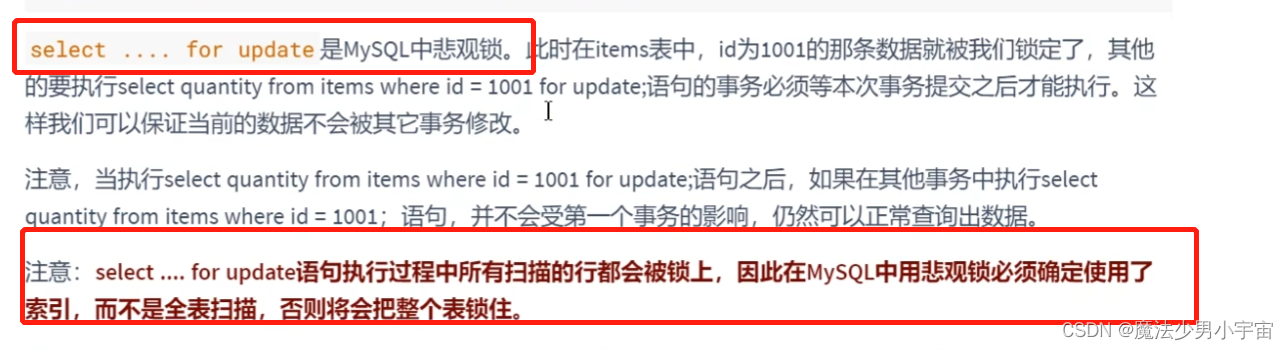

注意: 读写分离时乐观锁可能出现问题,此时要强制读取master表数据,保证数据一致

死锁
- mysql timeout 控制
- mysql的死锁检测

解决

MVCC

介绍
mvcc 依赖隐藏字段,undolog,readview 实现
应用
READ_COMMITEED /REPEATABLE_READ
快照
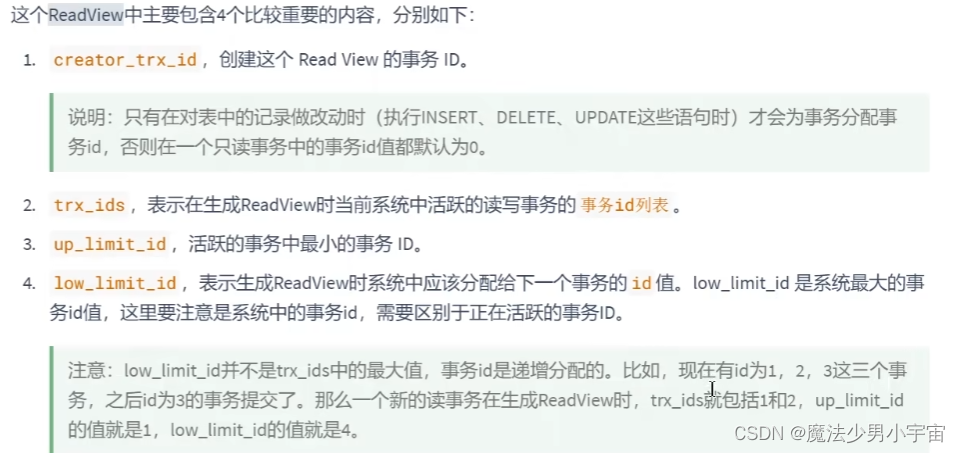
快照的规则
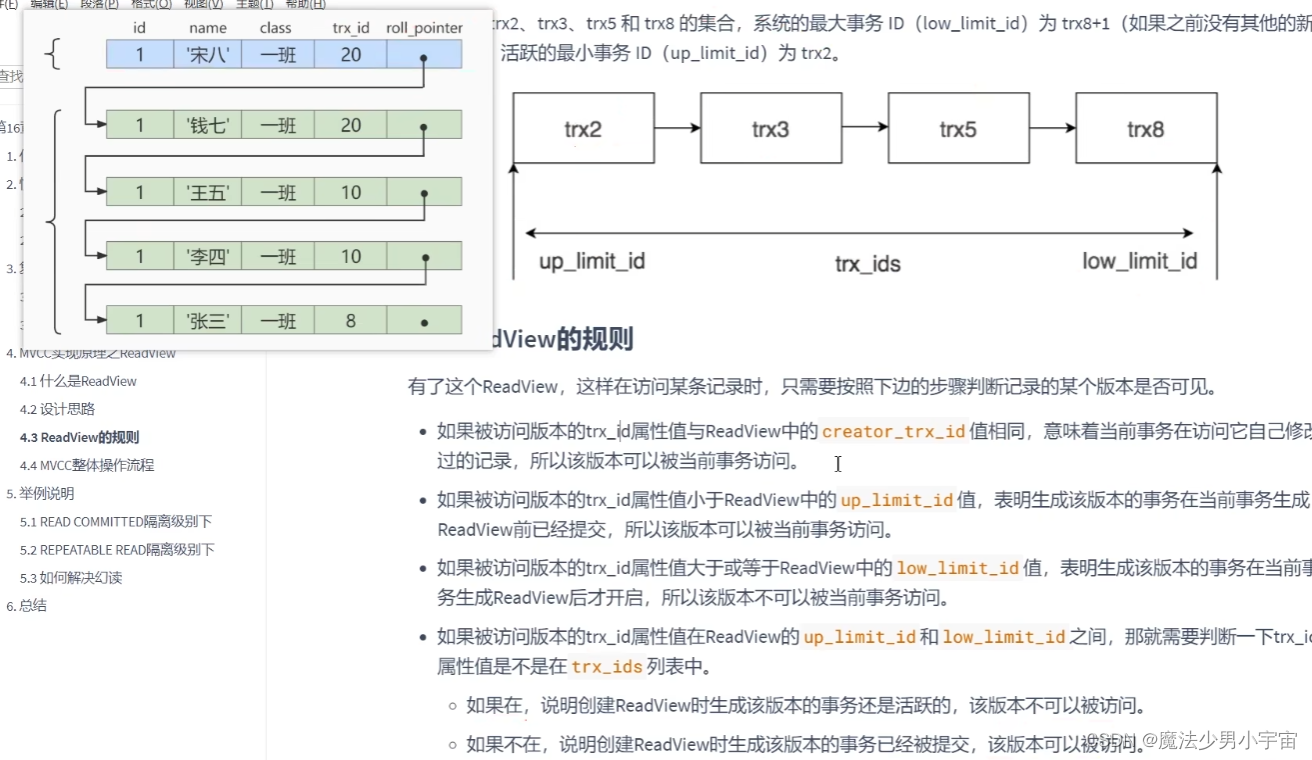
可重复读时,只获取一次快照

读已提交,每次都获取快照

MVCC在可重复读下解决幻读
因为只生成一次快照,所以其他事务后续添加的数据,都不会满足当前快照的展示
其他数据库日志

二进制日志文件
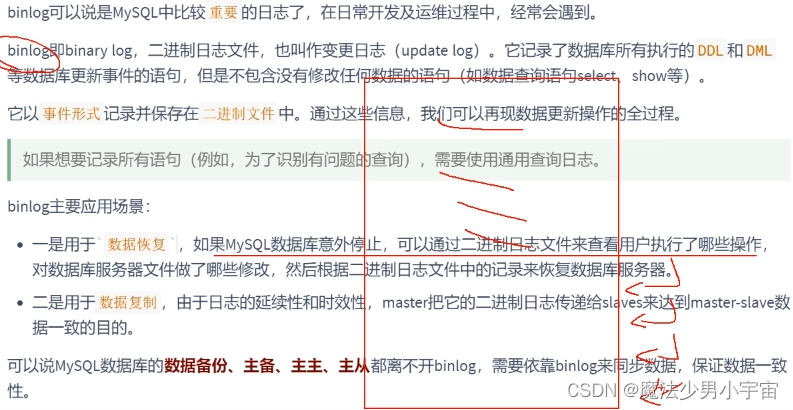
查看二进制文件
-
mysqlbinlog -v 文件
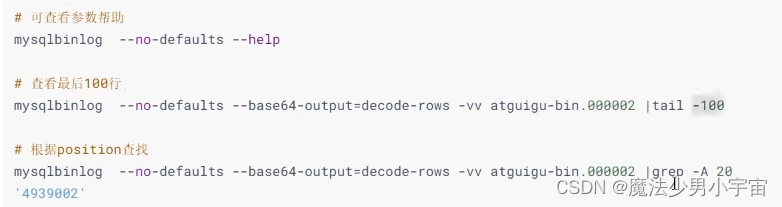
-
show binlog events …
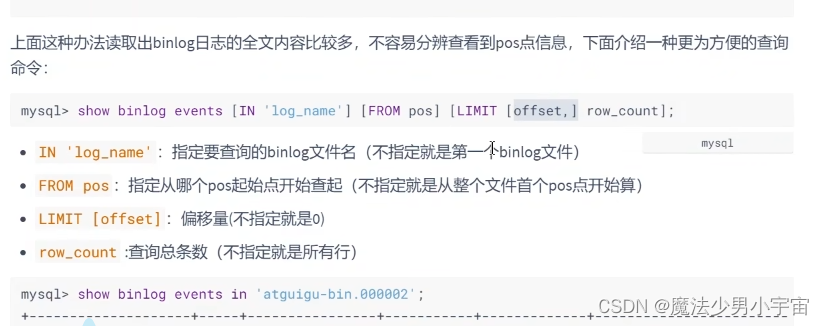

使用binlog恢复数据
- flush logs
- show binary logs
- show binlog events in (binlog文件名)

- 或者使用mysqlbinlog
二进制日志的写入机制
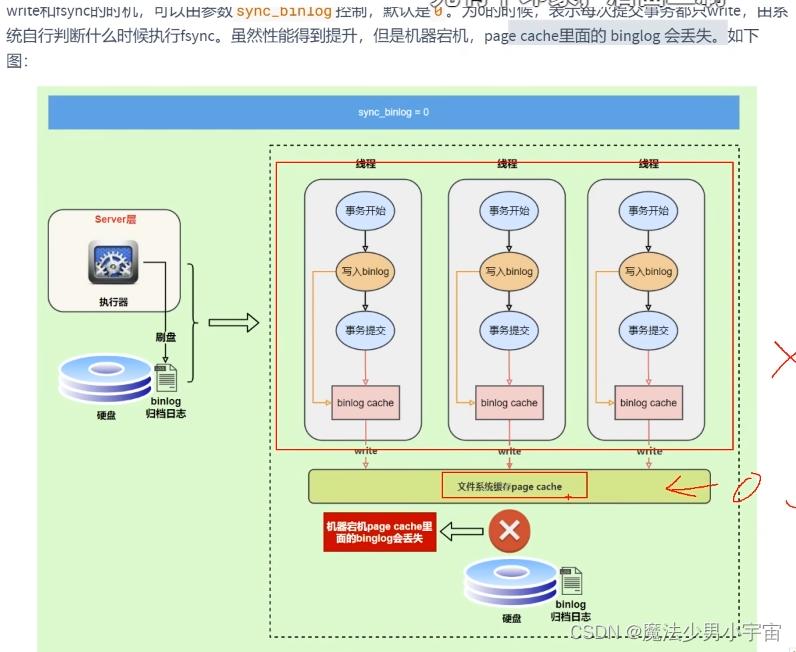

两阶段提交
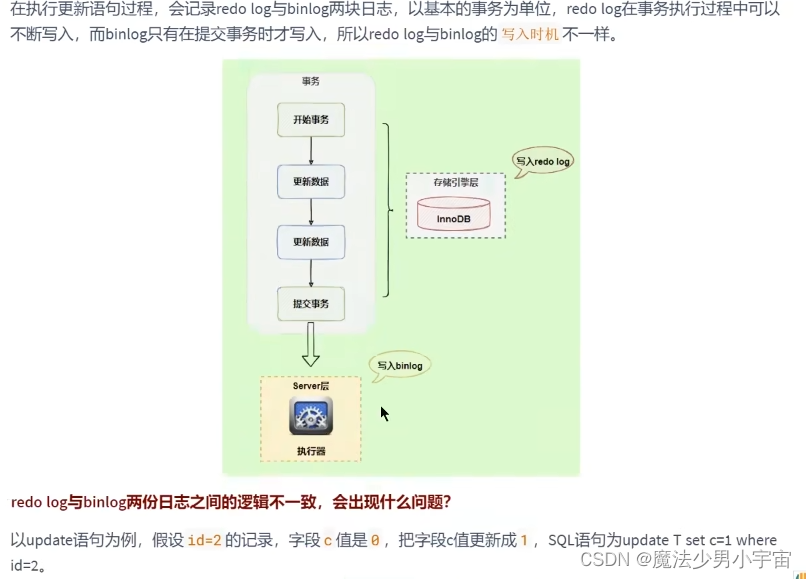
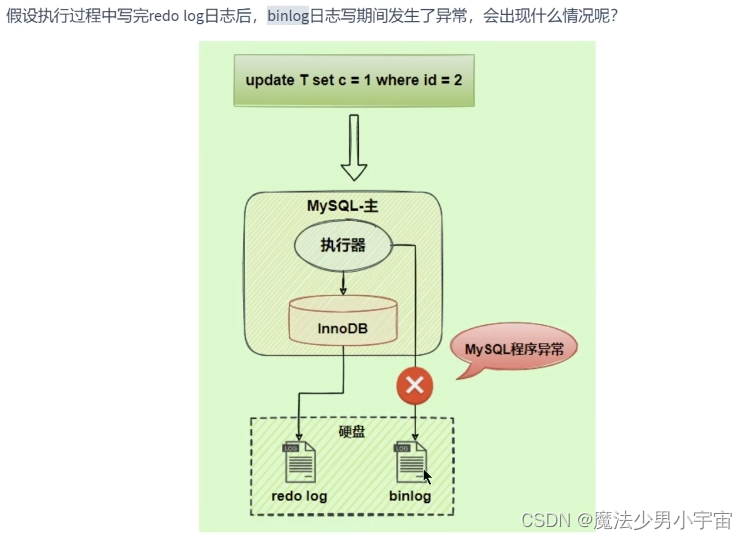
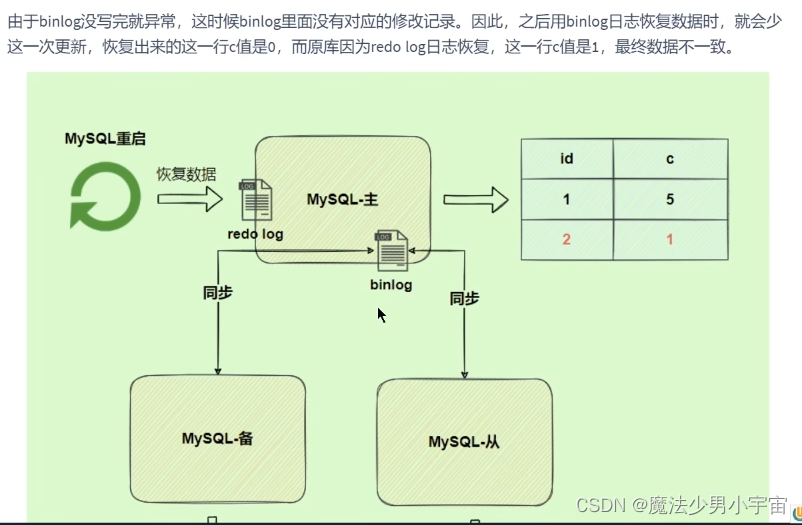
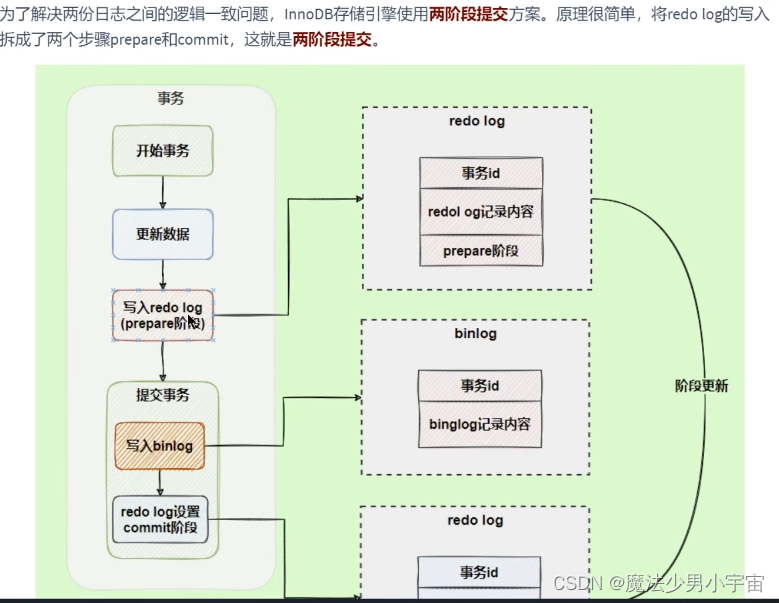
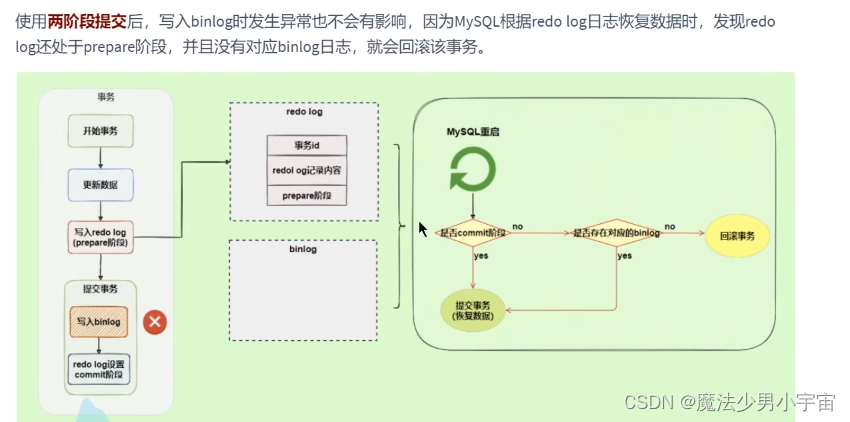
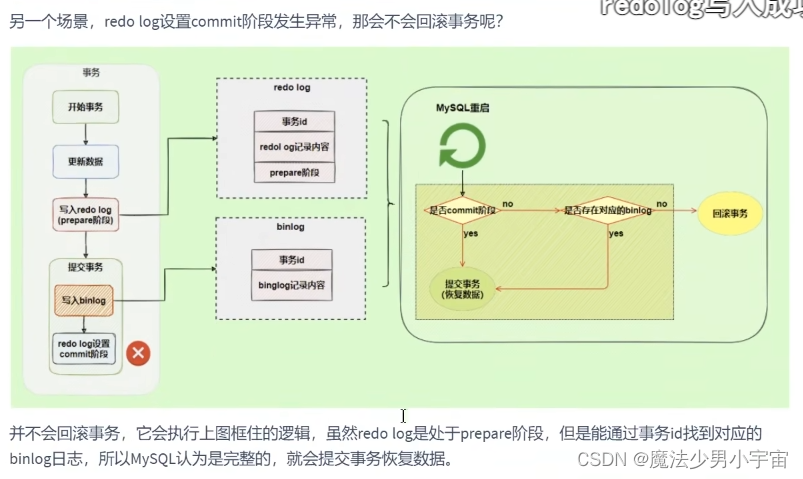
中继日志 relay log
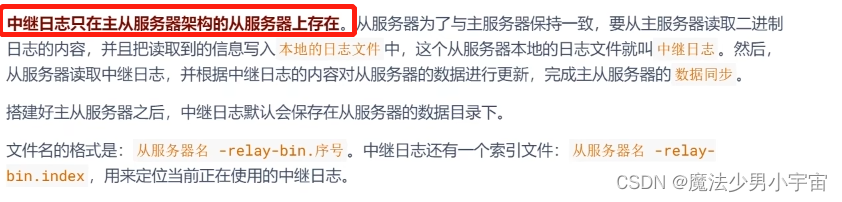
注意: 从服务器使用relay log恢复时,可能由于从服务器更改了名字,导致数据同步失败
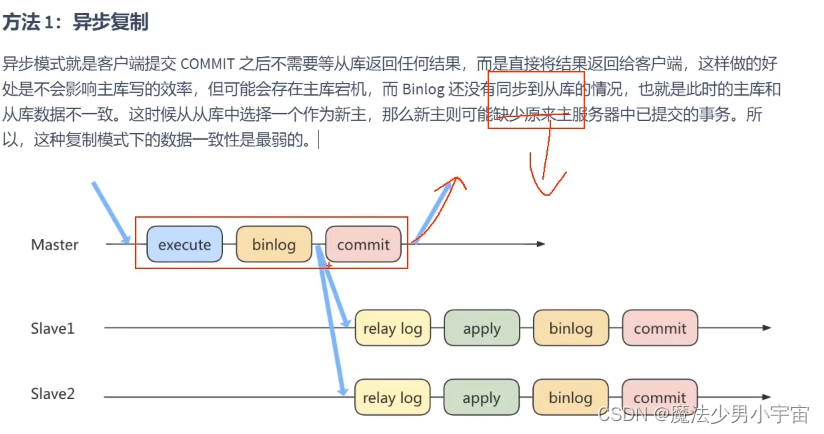
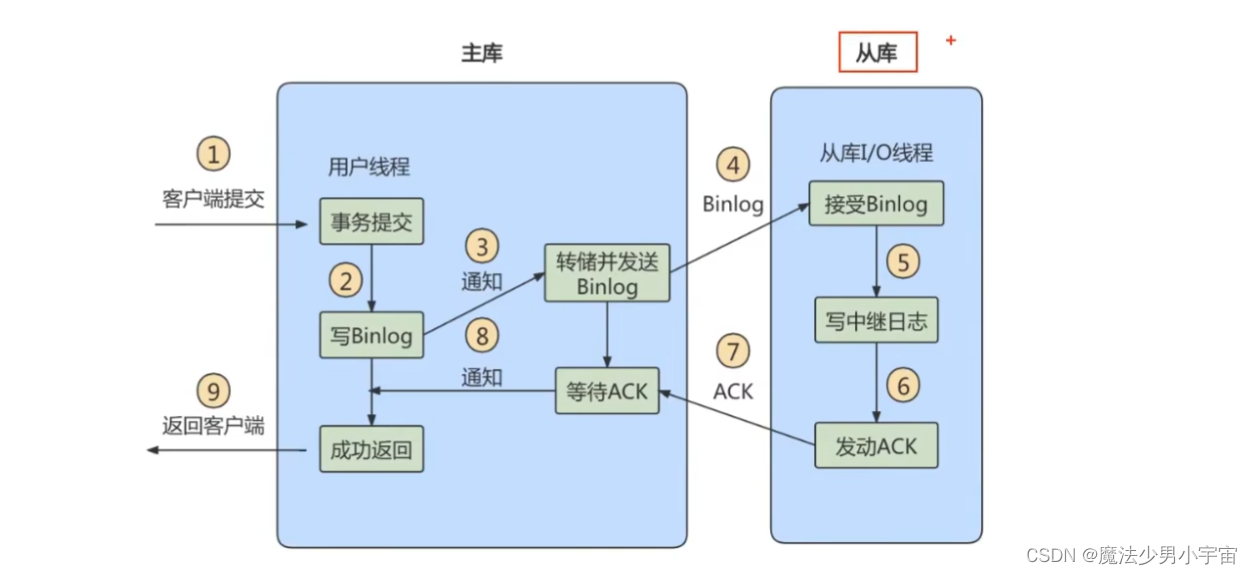
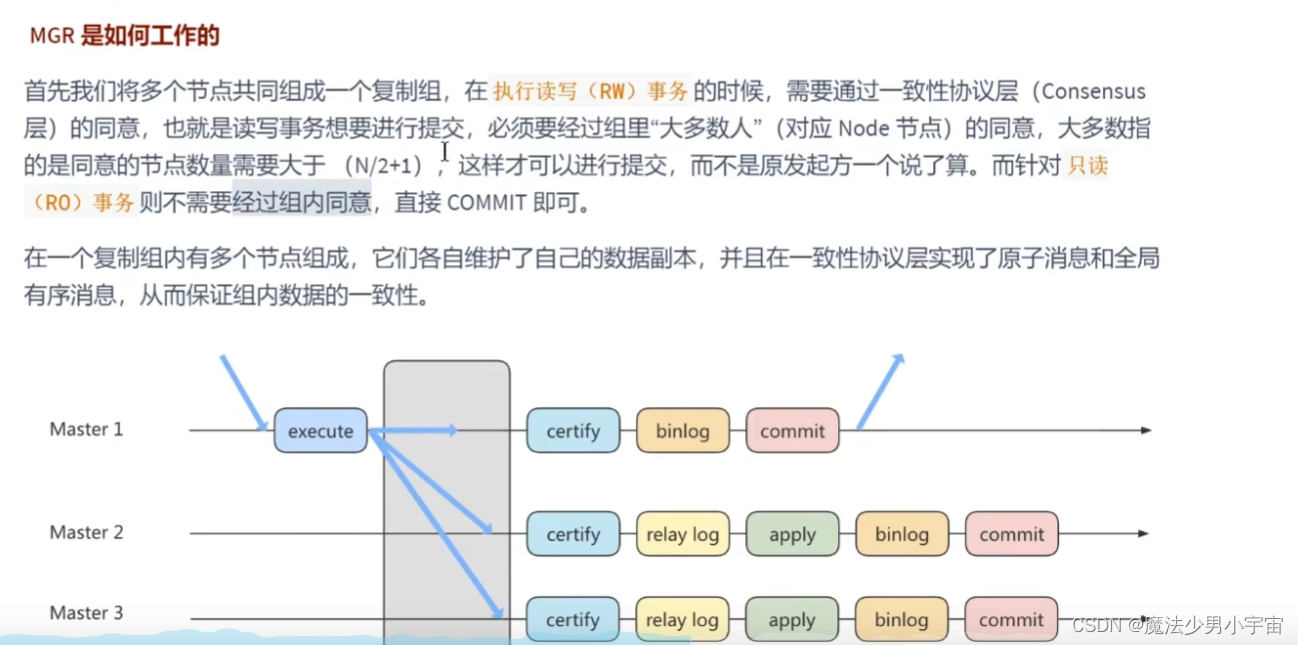
主从复制
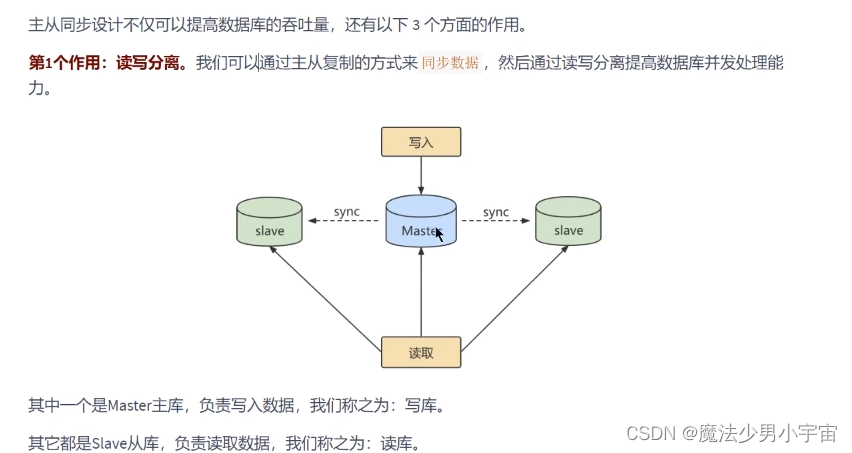


原理
三个线程
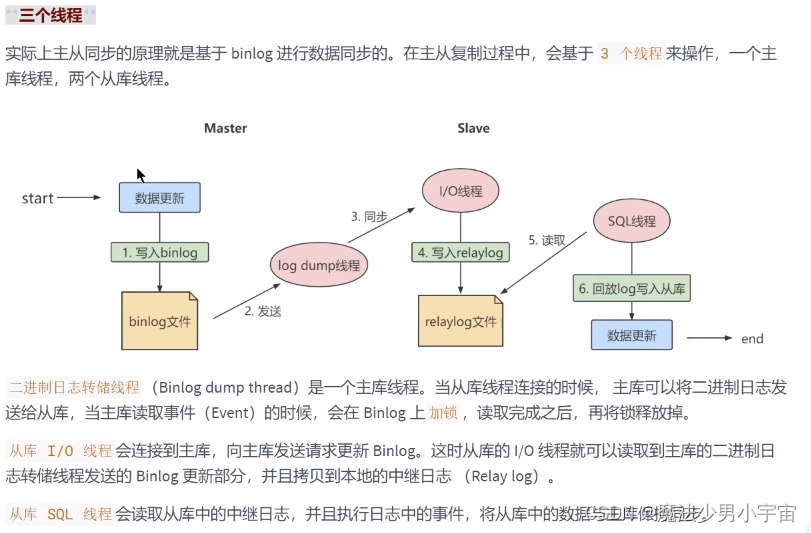
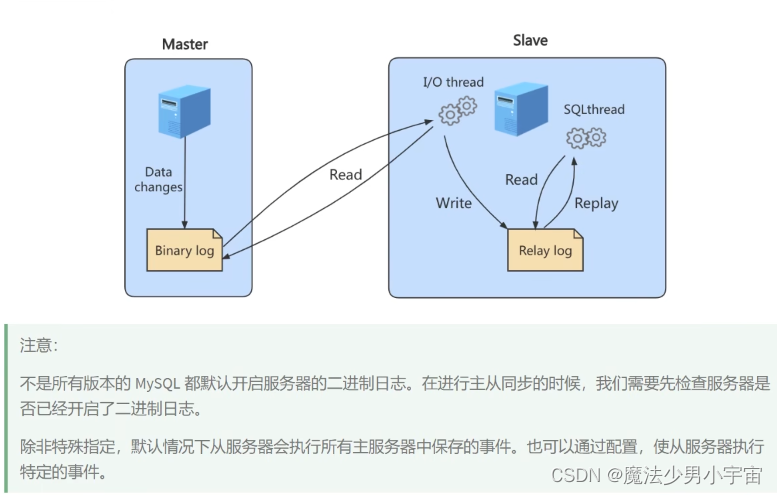
复制的基本原则

主从一致性问题


百万级数据怎么删除
删除数据的速度和创建的索引数量是成正比的。先删索引,再删无用数据,再创建索引















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









