







1. 概述
随机森林(Random Forests,RF),是由多棵决策树构成的集成算法,用来做分类预测,属于有监督学习,其输出的类别是由每个树输出类别的众数而定。当今在业内有着极为广泛的应用场景,从市场营销到医疗保健保险,再到用户画像和广告推荐算法,性能强大且应用广泛。
2. 信息论和决策树
2.1 信息论原理
什么是信息?信息就是用来消除不确定性的度量。信息论是为解决信息传递问题而建立的理论,是数据挖掘的基础理论之一。一个信息传递系统是由发送端(信源)和接收端(信宿)以及通信通道(信道)三者组成,信息传递过程中所消除的不确定性越大,那么所传递的信息量就越大。
在信息开始传递之前,接收端(信宿)对于信源的状态有着不确定性,这种不确定性叫做先验不确定性。在通信之后,这种不确定性会被减少或消除,一般情况下,干扰(噪音)会对传递的信息造成破坏,因此先验不确定性不能被完全消除,只能部分消除,也就是说,通信完成后信宿还任然具有一定程度的不确定性,这就是后验不确定性。显然,后验不确定性总要小于先验不确定性,如果两者相等,说明信宿根本没有接受到任何信息。
将其应用在数据挖掘中,对于一个分类问题而言,每一个属性的值都会为它的分类结果提供一定的信息,在没有得知任何属性的数据之前,我们对于分类结果是完全不确定的,然后每得到一个属性的值都会消除一定的不确定性,直到得知所有属性取值之后,我们对于分类结果便基本上可以确定了。
2.2 信息熵
信息熵是自信息的平均值,它反映信源
U
(
u
1
,
u
2
,
⋯
u
r
)
U\left(u_{1}, u_{2}, \cdots u_{r}\right)
U(u1,u2,⋯ur)中所有信息在发出前的平均不确定性。公式为:
H
(
U
)
=
∑
i
P
(
u
i
)
log
1
P
(
u
i
)
=
−
∑
i
P
(
u
i
)
log
P
(
u
i
)
H(U)=\sum_{i} P\left(u_{i}\right) \log \frac{1}{P\left(u_{i}\right)}=-\sum_{i} P\left(u_{i}\right) \log P\left(u_{i}\right)
H(U)=i∑P(ui)logP(ui)1=−i∑P(ui)logP(ui)
2.3 条件熵
条件熵表示在接收端收到信息
V
(
v
1
,
v
2
,
⋯
v
r
)
V\left(v_{1}, v_{2}, \cdots v_{r}\right)
V(v1,v2,⋯vr)后,对于信源
U
(
u
1
,
u
2
,
⋯
u
r
)
U\left(u_{1}, u_{2}, \cdots u_{r}\right)
U(u1,u2,⋯ur)尚存在的不确定性,这种不确定性是由于干扰(噪音)造成的。条件熵公式为:
H
(
U
∣
V
)
=
∑
j
P
(
v
j
)
∑
i
P
(
u
i
∣
v
j
)
log
1
P
(
u
i
∣
v
j
)
{H(U \mid V)}=\sum_{j} P\left(v_{j}\right) \sum_{i} P\left(u_{i} \mid v_{j}\right) \log \frac{1}{P\left(u_{i} \mid v_{j}\right)}
H(U∣V)=j∑P(vj)i∑P(ui∣vj)logP(ui∣vj)1
信息论原理是数据挖掘的基础理论之一,一般用于解决数据的分类问题。具体而言,就是在已知各样本类别的数据中,找出确定类别的关键条件属性。求关键属性的方法,是先计算各个条件属性的信息量,再从中选出信息量最大的属性,信息量的计算是利用信息论原理中的公式。
2.4 互信息与信息增益
互信息
I
(
U
∣
V
)
{I(U \mid V)}
I(U∣V)又叫信息增益,是信息熵与条件熵的差值,它代表最后接受到信息
V
V
V后所获得的信源
U
U
U的信息量,也就是最终不确定性的消除量。公式为:
I
(
U
,
V
)
=
H
(
U
)
−
H
(
U
∣
V
)
I(U, V)=H(U)-H(U \mid V)
I(U,V)=H(U)−H(U∣V)
2.5 决策树
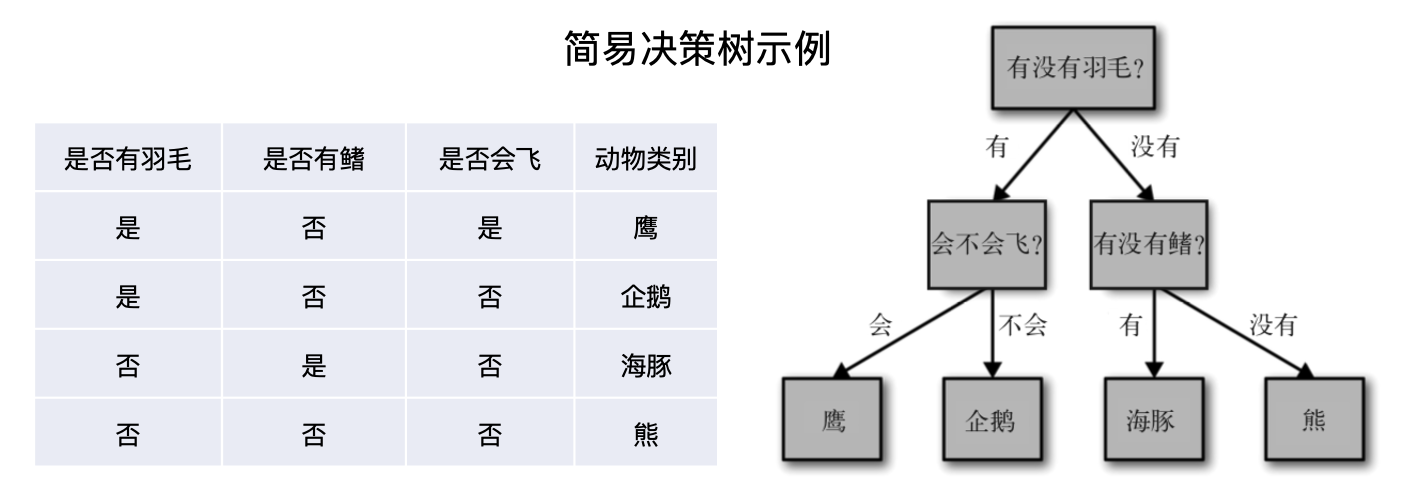
决策树(Decision Tree)是数据挖掘中的一种预测模型,由每个样本的属性分析归纳而产生。它是以样本的属性作为结点,以属性的取值作为分支的树结构,越靠近根结点的属性是全体样本中信息量越大的属性,信息量大小的计算方法通常是信息增益或基尼系数。
决策树是对全体样本数据的高度概括,不但能够准确识别现有样本的类别,也能对新样本的类别作出有效的预测。决策树的算法实现有多种类型,如ID3、C4.5、IBLE、CART等。
3. 集成学习
”团结就是力量“,这句话很好地表达了机器学习领域中强大的集成学习的基本思想。集成学习方法都是建立在一个假设上:将多个模型组合在一起通常可以产生更强大的模型。
在集成学习中,我们会训练多个模型(通常称为”弱学习器“)解决相同的问题,并将它们结合起来以获得更好的结果。最重要的假设是:当弱模型被正确组合时,我们可以得到更精确或更鲁棒的模型。
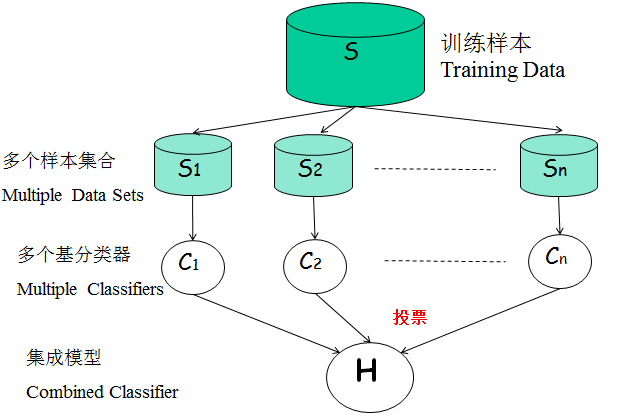
集成学习的方法有很多种,最常用的是Bgging(袋装法)和Boosting(提升法),随机森林所使用的是bagging方法。
Bagging
Bagging可以认为是一种平均法,简单来说,就是所有算法进行相互独立训练得到各自的模型,然后再进行投票选择最好的模型。步骤如下:
-
对于给定的训练样本S,每轮从训练样本S中采用有放回抽样(Booststraping)的方式抽取M个训练样本,共进行n轮,得到了n个样本集合,需要注意的是这里的n个训练集之间是相互独立的。
-
在获取了样本集合之后,每次使用一个样本集合得到一个预测模型,对于n个样本集合来说,我们总共可以得到n个预测模型。
-
如果我们需要解决的是分类问题,那么我们可以对前面得到的n个模型采用投票的方式得到分类的结果,对于回归问题来说,我们可以采用计算模型均值的方法来作为最终预测的结果。
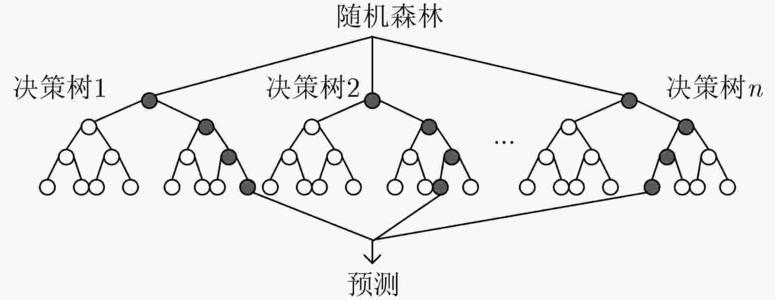
4. 随机森林
简而言之,随机森林就是用随机的方式建立一个森林,里面有很多的决策树,每一棵决策树之间是没有关联的。当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行预测,得到该样本的类别预测结果,最终,森林中所有树的预测结果是哪一类的最多,就作为最终预测结果。随机森林既可以处理离散型变量,也可以处理连续型变量。
算法步骤
- 假设训练集大小为N,对于每棵决策树而言,随机且有放回地从训练集中的抽取N个训练样本,作为该决策树的训练集进行训练
- 假设每个样本有M个属性,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
- 每棵树都尽最大程度的生长,并且没有剪枝过程
直观理解
随机森林算法得到的森林中的每一棵都是很弱的,但是大家组合起来就很厉害。可以这样比喻随机森林算法:每一棵决策树就是一个精通于某一个窄领域的专家(因为我们从M个feature中选择m让每一棵决策树进行学习),这样在随机森林中就有了很多个精通不同领域的专家,对一个新的问题(新的输入数据),可以用不同的角度去看待它,最终由各个专家,投票得到结果。而这正是群体智慧的力量,同时,由于每个专家相互独立(每棵树的训练数据是有放回抽样),所以不容易产生overfitting。
算法优点
- 两个随机性的引入,使得随机森林不容易陷入过拟合
- 两个随机性加上集成学习的方法使得随机森林有很好的抗噪能力,在缺失值比较多或者噪音比较大的数据集任然能有良好表现
- 能够处理高维度(feature很多)的数据,并且不用做特征选择,对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需标准化
- 训练速度比较快,容易做成并行方法
- 对于不平衡的数据集来说,它可以平衡误差。

















 1821
1821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











