一、集成学习
- 在机器学习的有监督学习算法中,我们的目标是通过训练学习出一个稳定的且在各个方面表现都较好的模型,但实际情况往往不这么理想,有时我们只能得到多个偏向于某方面比较好的模型,如果我们能够将这些有各自特点的模型结合起来,肯定会比单个模型的效果好很多。
- 而集成学习就是组合这里的多个弱监督模型以得到一个更好更全面的强监督模型,集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。
- 举个例子:小明、小黑和小白严重偏科,他们分别在学科数学、语文和英语中学习很好,其它学科都很差,但如果将三个人的特征集合于一身,那么这个人学习肯定就非常好了。
- 集成学习的目的:让机器学习效果更好!聚集多个学习器的预测来提高分类准确率。实现方式即从原数据抽取n个子数据集训练n个分类器,将n个分类器进行结合得到最终的分类器。
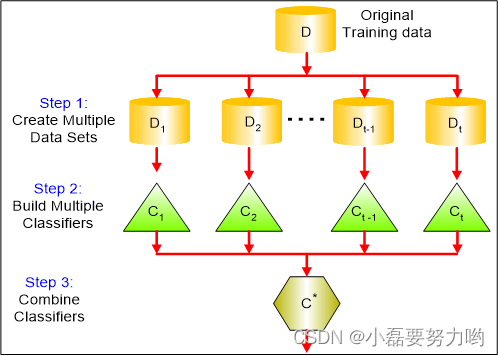
- 集成学习的种类
- Bagging装袋:又称自主聚集(bootstrap aggregating),是一种根据均匀概率分布从数据集中重复抽样(有放回)的技术。每个新数据集和原始数据集大小相等。代表算法:随机森林。
- Boosting提升:是一个迭代的过程,用来自适应地改变训练样本的分布,使得弱学习器聚焦到那些很难分类的样本上。它的做法是给每一个训练样本赋予一个权重,在每一轮训练结束时自动地调整权重。代表算法:Adaboost、GBDT、XGBoost。
- 组合策略 预测结果
- 平均法:对于数值类的回归预测问题,通常使用平均法,即对于若干个弱学习器的输出进行算术平均或加权平均得到最终的预测输出。
- 投票法:对于分类问题的预测,通常使用投票法。
- 少数服从多数,即n个弱学习器的对样本x的预测结果中,数量最多的类别为最终的分类类别。
- 输出各类别数量要过半数。
- 加权投票法:每个弱学习器的分类票数要乘以一个权重,最终将各个类别的加权票数求和,最大的值对应的类别为最终类别。
二、随机森林
- 随机森林是用随机的方式建立一片森林,森林由决策树组成,每一棵决策树之间是没有关联的。
在得到森林之后,当有一个新的输入样本需要分类,就让森林中的每一棵决策树分别进行判断,看看这个样本应该属于哪一类,然后看看哪一类被选择最多,就预测这个样本为那一类。 - 随机:子数据集有放回的随机采样,训练特征随机的选取
- 森林:很多棵决策树并行训练
之所以要进行随机,是要保证泛化能力,如果树都一样,那就没意义了!
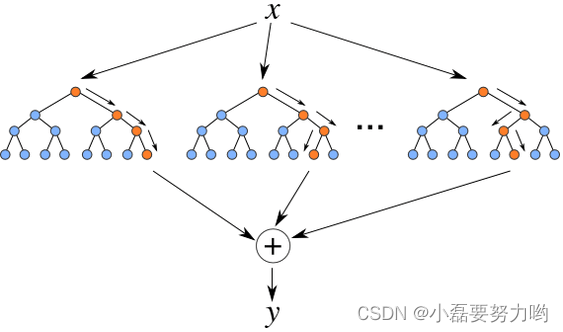
- 随机森林步骤:
- 1、从N个样本集中用Bootstrap有放回的随机选择N个样本(每次随机选择一个样本,然后返回继续选择)。用选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。(子数据集与原数据集的大小相同,但数据不同,因为是有放回的随机抽取数据。)
- 2、从样本的M个特征中随机选取出m个特征,满足条件m << M,然后从这m个特征中采用某种策略(信息增益(率)、Gini指标等)来选择1个特征作为该节点的分裂特征。
- 3、 决策树形成过程中每个节点都要按照步骤2来分裂。一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
- 4、按照步骤1~2建立大量决策树,构成随机森林。
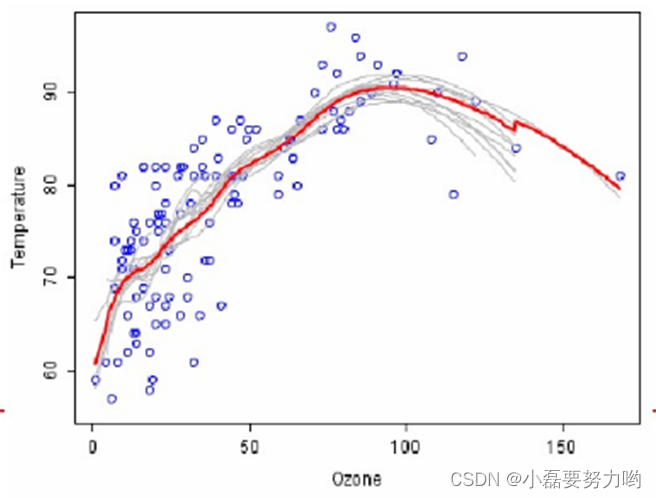
- 随机森林不仅可以使用决策树作为基分类器,也可以利用SVM、逻辑回归等分类模型作为基分类器。同时随机森林还可以处理回归问题,例如下图: 做100次Bootstrap,每次使用局部回归拟合一条曲线,如图中的灰色曲线;将这些曲线取平均,即得到红色的最终拟合曲线;显然红色曲线更加稳定,且过拟合明显减弱。
- 影响随机森林性能的主要因素:
- 森林中单棵树的强度(strength):每棵树的强度越大,则随机森林的性能越好。
- 森林中树之间的相关度(correlation):树之间的相关度越大,则随机森林的性能越差。
- 随机森林的特点:
- 两个随机性的引入,使得随机森林不容易陷入过拟合,且具有良好的抗噪声能力。
- 对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据无需规范化。
- 可以得到特征重要性排序,以此进行其它模型的特征选择也可以。(两种:基于OOB误分率的增加量和基于分裂时的Gini指标下降量)。
- OOB:对于子数据集没采集到的数据,称之为袋外数据(Out Of Bag,简称OOB)。这些数据没有参与该训练集模型的拟合,因此可以用来检测模型的泛化能力。)
- 它能够处理很高维度(特征较多)的数据,并且不用做特征选择。(随机选取出m个特征进行训练)
- 缺点:
- 随机森林已经被证明在某些噪音较大的分类或回归问题上也会过拟合。
- 对于有不同取值的特征的数据,取值划分较多的特征会对随机森林产生更大的影响,所以随机森林在这种数据上产出的特征权值是不可信的。
三、python实战
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] =['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
iris = datasets.load_iris()
X = iris.data
Y = iris.target
x_train,x_test,y_train,y_test = train_test_split(X,Y,test_size=0.3,random_state=0)
x_train.shape,x_test.shape,y_train.shape,y_test.shape
RFC = RandomForestClassifier(n_estimators=10,bootstrap='true',max_depth=4)
rf = RFC.fit(x_train,y_train)
y_train_pred = RFC.predict(x_train)
y_test_pred = RFC.predict(x_test)
accuracy1 = metrics.accuracy_score(y_train,y_train_pred)
accuracy2 = metrics.accuracy_score(y_test,y_test_pred)
print('训练集精确度:%.3f,测试集精确度:%.3f'% (accuracy1,accuracy2))
rf.estimators_

plt.figure(figsize=[5,4])
sns.heatmap(metrics.confusion_matrix(y_test,y_test_pred),annot=True,cmap='Reds')
plt.xlabel('真实值',size=14)
plt.ylabel('预测值',size=14)
plt.show()

from IPython.display import Image
from sklearn import tree
import pydotplus
import graphviz
i=0
for per_rf in rf.estimators_:
dot_data = tree.export_graphviz(per_rf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
i = i+1
graph.write_pdf(str(i)+"Ttree.pdf")
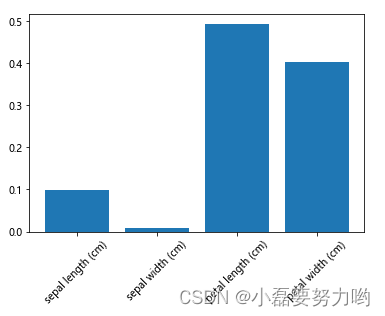
y_importances = rf.feature_importances_
x_importances = iris.feature_names
y_importances,x_importances
plt.bar(x_importances,y_importances)
plt.xticks(rotation=45)
参考:
随机森林原理介绍与适用情况(综述篇)
OOB错误率























 7860
7860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









