







布隆过滤器
起源:布隆过滤器 (Bloom Filter)是由 Burton Howard Bloom 于 1970 年提出,它是一种 space efficient 的概率型数据结构,用于判断一个元素是否在集合中
数据结构: 使用多个Hash函数和一个初始值都为0的bit大型数组构成
原理: 它先对key使用多个hash函数进行计算,得到多个不同的hash值,再拿数组长度进行对多个hash值取模得到多个位置,将这几个位置置为1,表示这个key存在
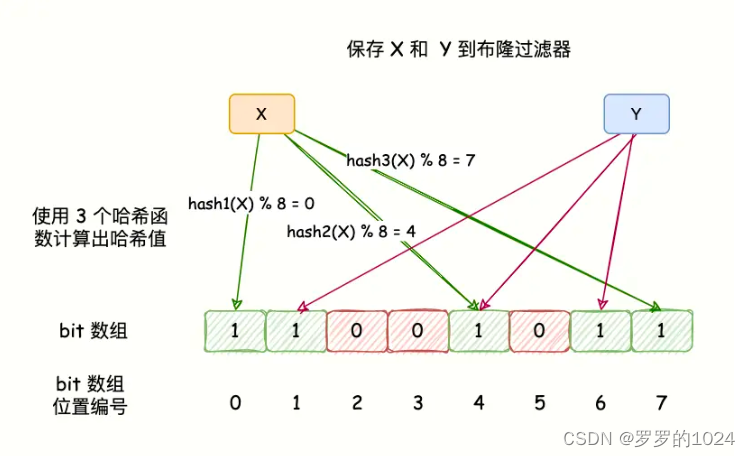
但是由于存在哈希冲突,所以存在一定的误判率,即实际没有的key经过hash计算,得出的结果却是存在。那么如何才能降低hash冲突呢?
- 扩大bit数组
- 增加hash函数
tips: 不管是扩大bit数组 还是 增加hash函数 都要根据业务实际情况判断,一味的扩大数组或者是增加hash函数,可能会浪费内存空间或者增加cpu计算。
还有一个问题,由于bit位可能存在多key共享的情况,所以对key进行删除时,bit位不能进行reset操作。那么如何解决呢?答案是解决不了。
我们常说redis的缓存穿透,即同一时间,大量请求请求一个不存在的key,导致请求全部打到了DB,给DB造成了巨大压力。而我们常说的解决方案
- 缓存这个不存在的key,并加上过期时间
- 使用布隆过滤器
那么是如何使用布隆过滤器的呢?用springboot示例
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.12.5</version>
</dependency>
@Component
public class BloomFilterFoctory<T> {
@Resource
private RedissonClient redissonClient;
/**
* @param filterName 过滤器名称
* @param expectedInsertions 元素数量
* @param falseProbability 容错率
* @return
*/
public RBloomFilter<T> createBloomFiltert(String filterName, long expectedInsertions, double falseProbability){
RBloomFilter<T> bloomFilter = redissonClient.getBloomFilter(filterName);
bloomFilter.tryInit(expectedInsertions,falseProbability);
return bloomFilter;
}
}
@Slf4j
@Service
public class GoodsService implements InitializingBean {
/** 过滤器名 */
private static final String filterName = "goods-phone-filter";
/** 期待插入的数量 */
private static final long expectedInsertions = 10000;
/** 失败的可能性 */
private static final double falseProbability = 0.001;
@Resource
private BloomFilterFoctory<String> bloomFilterFoctory;
@Resource
private StringRedisTemplate stringRedisTemplate;
private RBloomFilter<String> bloomFilter;
@Override
public void afterPropertiesSet() throws Exception {
List<Phone> phoneList = new ArrayList<>(64);
this.bloomFilter = bloomFilterFoctory.createBloomFiltert(filterName, expectedInsertions, falseProbability);
for (Phone phone : phoneList) {
bloomFilter.add(phone.getId());
}
}
public Phone findPhoneById(String id) {
if (bloomFilter.contains(id)){
log.warn("布隆过滤器中存在,由于hash冲突,不一定真实存在");
String phoneString = stringRedisTemplate.opsForValue().get(id);
return StringUtils.hasLength(phoneString) ? JSON.parseObject(phoneString, Phone.class) : null;
}else {
log.warn("布隆过滤器中没有,这是一个非法访问");
}
return null;
}
public int detelePhoneById(String id) {
log.warn("直接删DB,布隆过滤器里面不能删除");
return detelePhoneInDB(id);
}
public void updatePhoneById(Phone phone) {
if (bloomFilter.contains(phone.getId())){
String key = stringRedisTemplate.opsForValue().get(phone.getId());
if (StringUtils.hasLength(key)){
log.warn("这个key真实存在,更新DB");
updatePhoneInDB(phone);
}
log.warn("不管这个key是否真实存在,都设置一下");
stringRedisTemplate.opsForValue().set(phone.getId(), JSON.toJSONString(phone),30, TimeUnit.MINUTES);
}
}
public void insertPhone(Phone phone) {
insertPhoneInDB(phone);
bloomFilter.add(phone.getId());
}
}
让我们总结一下布隆过滤器:
优点:高效地插入和查询,占用空间较少
缺点:不能删除元素,存在误判,所以看项目能不能接受


















 167万+
167万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











