







 本文描述了一名Python初学者如何通过Pandas库解决部门考勤数据整理问题,包括表结构优化、使用groupby函数进行数据聚合,以及创建可执行文件自动化处理。作者强调了编程在提升工作效率中的作用。
本文描述了一名Python初学者如何通过Pandas库解决部门考勤数据整理问题,包括表结构优化、使用groupby函数进行数据聚合,以及创建可执行文件自动化处理。作者强调了编程在提升工作效率中的作用。
0. 前言
本python初学者最近对接了考勤工作,于是就拿了一个简单的需求练练手。在边学边写的过程中,我的评价是:chatgpt帮了大忙!写代码的过程中好多知识都是东拼西凑,缺乏系统性和完整性,后续会系统的将这部分内容再学习和梳理一遍。
1. 需求介绍
部门人员的加班日以及调休日都汇总在一张表里,由考勤员做记录(没错,很原始…再坚持一个月就不用这么麻烦了)。这张表拿到的时候很乱,just like this …

这样的记录方式更像是一个草稿,可以很直观地看到加班和调休如何抵消。之前考勤员是通过这张类似“记录”的表去统计本月的加班、调休累计。单统计一个人还比较轻松,但部门这么多人,再检查一遍,来来回回看下来老眼昏花。于是乎决定把表结构改的简单一些,利用pandas库来处理这些数据。
2. 实现过程
step1 表结构调整
我将这张表简单拆分成两张表:调休表和加班表。每张表只有姓名、日期、时长三个字段。
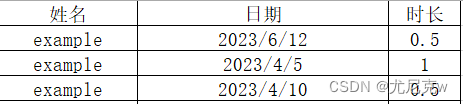
step2 代码实现统计
通过代码实现两点:
- 每月每个人加班及调休的累计时长
- 年度结余的调休时长
2.1
使用groupby函数对姓名作分组,再在月的维度上做聚合:
def aggregated_by_month(df):
return df.groupby(['姓名', pd.Grouper(key='日期', freq='M')])[ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 32
32

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









