







一、前言
设计模式(Design pattern)代表了最佳的实践,通常被有经验的面向对象的软件开发人员所采用。设计模式是软件开发人员在软件开发过程中面临的一般问题的解决方案。这些解决方案是众多软件开发人员经过相当长的一段时间的试验和错误总结出来的。
咱之前研究命令模式的时候,探讨了怎么把请求打包成对象,这样就能实现解耦,还能把请求排队、记录日志啥的。现在呢,咱把目光转向另一个行为型设计模式 —— 解释器模式。
这个模式在规则解析这块,就像个 “语言建筑师”,能搭建特定领域语言(DSL)的语法规则,还能建立对应的解释执行体系,给复杂的规则解析问题提供了一套有条理的解决办法。下面,咱就从原型设计、实际应用场景这些方面,好好研究一下解释器模式是怎么工作的,有啥实用价值。
二、解释器模式原型设计及说明
解释器模式(Interpreter Pattern)提供了评估语言的语法或表达式的方式,它属于行为型模式。
解释器模式给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。解释器模式有着一套严谨且精妙的核心架构,其具体结构我们通过 UML 类图得以清晰展现:
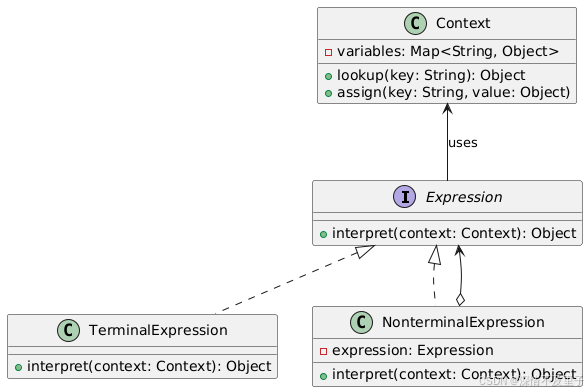
在该类图中,Expression接口定义了所有表达式类都必须实现的interpret方法,此方法构成了解释器模式的基础契约。作为抽象表达式角色,Expression接口为终结符表达式和非终结符表达式提供了统一的interpret接口规范,确保不同类型的表达式在解释执行时具有统一的方法调用形式,进而为构建复杂的语法解释体系奠定基础。
TerminalExpression类实现了Expression接口,负责处理基础语法单元的解释工作,是语法解析的最基本元素。在简单数学表达式解释器中,单个数字或变量属于终结符表达式。其interpret方法根据上下文环境直接返回解释结果,是语法解释的最底层单元。
NonterminalExpression也实现了Expression接口,持有一个或多个Expression类型的成员变量,通过组合不同的表达式构建复杂规则。在数学表达式(a + b) * c中,(a + b)属于非终结符表达式,由终结符表达式a、b以及运算符+组成。其interpret方法递归调用所包含子表达式的interpret方法,按照既定语法规则组合子表达式的解释结果,以得到最终复杂规则的解释。
Context类用于存储解释器工作过程中的全局状态信息,为表达式的解释提供必要的上下文环境。它包含一个用于存储变量及其对应值的Map结构,通过lookup方法可根据变量名获取对应值,通过assign方法可为变量赋值。在表达式解释过程中,Context类为各个表达式提供必要的环境信息,使表达式能够根据实际变量值准确解释。各个类之间通过继承和关联关系紧密协作,共同完成从语法定义到解释执行的全过程。
因此在解释器模式的应用中,其最核心的角色也就不难而知了:
-
抽象表达式(Abstract Expression):定义了解释器的抽象接口,声明了解释操作的方法,通常是一个抽象类或接口。
-
终结符表达式(Terminal Expression):实现了抽象表达式接口的终结符表达式类,用于表示语言中的终结符(如变量、常量等),并实现了对应的解释操作。
-
非终结符表达式(Non-terminal Expression):实现了抽象表达式接口的非终结符表达式类,用于表示语言中的非终结符(如句子、表达式等),并实现了对应的解释操作。
-
上下文(Context):包含解释器之外的一些全局信息,在解释过程中提供给解释器使用,通常用于存储变量的值、保存解释器的状态等。
-
客户端(Client):创建并配置具体的解释器对象,并将需要解释的表达式传递给解释器进行解释。
三、解释器模式的适用场景与框架应用
3.1 典型应用场景
在深入理解了模式原型后,我们来探讨一下解释器模式的适用场景。
✅需要解释执行 DSL 的场景:当系统需要处理特定领域语言时,解释器模式就派上用场了。例如,在规则引擎系统中,业务人员可能通过自定义的规则语言来描述业务规则,像 “如果用户等级大于 3 且订单金额大于 500 元,则享受八折优惠”。解释器模式能够将这种规则语言解析并执行,实现业务规则的灵活配置和动态调整。
✅存在频繁变更的业务规则解析需求:对于业务规则经常变动的系统,使用解释器模式可以将规则的定义与代码实现分离。通过修改规则文件或者配置界面中的规则描述,而无需大量修改代码,就能适应业务规则的变化。这大大提高了系统的可维护性和扩展性。
✅数学公式 / 正则表达式等结构化语法解析:在处理数学公式计算或者正则表达式匹配等场景时,解释器模式能够将复杂的语法结构进行拆解和解释。以数学公式解析为例,将数学表达式按照运算符和操作数拆分成不同的表达式单元,通过解释器模式实现逐步计算,最终得到正确的结果。
3.2 开源框架实践
和其他设计模式相似,解释器模式在众多开源框架中均有广泛应用,接下来我们一起来了解一下:
✅Spring Expression Language:Spring Expression Language(SpEL)是 Spring 框架提供的一种强大的表达式语言,它支持在运行时查询和操作对象图,以及解析逻辑、算术表达式等。SpEL 通过组合模式实现表达式解析,将复杂的表达式分解为多个简单的子表达式进行处理。例如,在 Spring 的配置文件中,可以使用 SpEL 来动态地设置 Bean 的属性值。假设我们有一个 User 类,其中包含 name 和 age 属性,在 Spring 的配置文件中可以这样使用 SpEL:
<bean id="user" class="com.example.User">
<property name="name" value="#{'John Doe'}"/>
<property name="age" value="#{25 + 5}"/>
</bean>在这段配置中,#{25 + 5} 就是一个 SpEL 表达式,SpEL 会将其解析为一个算术表达式进行计算,然后将结果赋值给 age 属性。在 Java 代码中,也可以使用 SpEL 来解析表达式。首先创建一个SpelExpressionParser对象,然后使用该对象解析表达式并获取值:
import org.springframework.expression.Expression;
import org.springframework.expression.ExpressionParser;
import org.springframework.expression.spel.standard.SpelExpressionParser;
public class SpelExample {
public static void main(String[] args) {
ExpressionParser parser = new SpelExpressionParser();
Expression exp = parser.parseExpression("'Hello World'.concat('!')");
String message = (String) exp.getValue();
System.out.println(message);
}
}上述代码中,'Hello World'.concat('!') 是一个 SpEL 表达式,它调用了字符串的concat方法,SpEL 解析该表达式并返回结果Hello World!。
✅ANTLR:ANTLR(ANother Tool for Language Recognition)是一个强大的语法解析器生成工具,它可以根据给定的语法规则生成相应的解析器。ANTLR 通过解释器模式实现语法分析,将输入的文本按照语法规则解析为抽象语法树(AST),然后可以对抽象语法树进行遍历和处理。例如,我们可以使用 ANTLR 来解析一个简单的数学表达式语言。首先定义数学表达式的语法规则,如下所示:
grammar MathExpression;
expression
: expression ('+' | '-') expression
| expression ('*' | '/') expression
| '(' expression ')'
| INT
;
INT : [0-9]+ ;
WS : [ \t\r\n]+ -> skip ;上述语法规则定义了数学表达式的基本结构,包括加法、减法、乘法、除法、括号和整数。然后使用 ANTLR 工具根据这个语法规则生成相应的解析器代码。在 Java 代码中,可以使用生成的解析器来解析数学表达式:
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTree;
public class MathExpressionParserExample {
public static void main(String[] args) {
String expression = "3 + 5 * 2";
MathExpressionLexer lexer = new MathExpressionLexer(CharStreams.fromString(expression));
CommonTokenStream tokens = new CommonTokenStream(lexer);
MathExpressionParser parser = new MathExpressionParser(tokens);
ParseTree tree = parser.expression();
// 可以进一步遍历树进行计算等操作
}
}这里我们首先创建了一个MathExpressionLexer词法分析器,将输入的表达式转换为词法单元流,然后创建MathExpressionParser语法分析器,将词法单元流解析为抽象语法树。
✅MyBatis:MyBatis 是一个流行的持久层框架,它支持使用 OGNL(Object - Graph Navigation Language)表达式来动态生成 SQL 语句。OGNL 表达式可以在运行时根据对象的属性值动态地构建 SQL 语句,实现数据的灵活查询和操作。例如,在 MyBatis 的映射文件中,可以使用 OGNL 表达式来实现动态 SQL:
<select id="findUsers" resultType="User">
SELECT * FROM users
<where>
<if test="name != null">
AND name LIKE '%${name}%'
</if>
<if test="age != null">
AND age > ${age}
</if>
</where>
</select>这里<if>标签中的test属性就是一个 OGNL 表达式,它根据传入的参数值来判断是否需要添加相应的 SQL 条件。如果name参数不为空,就会添加AND name LIKE '%${name}%'条件;如果age参数不为空,就会添加AND age > ${age}条件。通过这种方式,MyBatis 可以根据不同的业务需求动态地生成 SQL 语句,提高了 SQL 语句的灵活性和可维护性。
3.3 实际开发中的应用建议
✅优先考虑成熟表达式引擎(如 SpEL)而非自研:在企业开发中,当面临需要处理表达式解析的场景时,优先选择成熟的表达式引擎是一个明智的决策。像 Spring Expression Language(SpEL),它经过了大量项目的实践检验,具有丰富的功能和强大的表达式解析能力。它不仅支持基本的算术、逻辑运算,还能方便地访问对象的属性和方法,在 Spring 生态系统中更是无缝集成,使用起来非常便捷。
与自研表达式引擎相比,成熟的表达式引擎在稳定性、性能优化、安全性等方面都有着显著的优势。自研引擎不仅需要投入大量的时间和人力进行开发和测试,而且在面对复杂的表达式场景和性能压力时,很难保证其稳定性和可靠性。
✅在规则复杂度达到语法树层级时采用:当业务规则变得复杂,需要通过层次化、结构化的方式来表示和处理时,解释器模式就展现出了它的价值。
如果规则简单,只是一些基本的条件判断,使用传统的if - else语句或者简单的逻辑判断即可,这样代码简洁明了,易于维护。但当规则发展到需要构建语法树才能清晰表达和处理时,比如在一个复杂的工作流系统中,任务的执行规则可能涉及到多个条件的组合、嵌套,以及不同条件下的不同执行路径,此时使用解释器模式,将规则构建成语法树,通过解释器对语法树进行解析和执行,能够更好地应对规则的复杂性,提高系统的可扩展性和可维护性。
⚠️避免过度设计简单条件判断场景:在简单条件判断场景中,过度使用解释器模式会导致代码复杂度增加,可读性变差,反而降低了开发效率和系统性能。
例如,在一个简单的用户权限验证场景中,只需要判断用户的角色是否为管理员即可决定是否允许访问某个功能,使用简单的if (user.getRole() == "ADMIN")这样的代码就足够简单高效。如果强行使用解释器模式,将这个简单的判断逻辑构建成复杂的表达式和解释器体系,不仅会增加代码量和维护成本,还会引入不必要的性能开销,使得系统变得臃肿和难以理解。
所以,在实际开发中,要根据具体的业务场景和需求,合理选择是否使用解释器模式,避免过度设计。
四、解释器模式的简单实践:订单折扣规则引擎
4.1 业务场景描述
在电商业务中,订单折扣规则的设定对于吸引用户、促进销售起着至关重要的作用。我们要实现的是一个高度可配置化的订单折扣规则系统,它需要支持灵活多变的组合条件表达式,以满足不同的促销活动和业务策略。
以一个具体的组合条件表达式(memberLevel > 3 && totalAmount >= 500) || couponType == 'FESTIVAL'为例,这个表达式表示当会员等级大于 3 且订单总金额大于等于 500,或者使用的优惠券类型为FESTIVAL时,订单可以享受相应的折扣优惠。
在实际业务中,会员等级可能对应着不同的用户忠诚度和消费能力,较高等级的会员通常期望获得更多的优惠,以增加他们的满意度和忠诚度;订单总金额的设定则是为了鼓励用户增加购买量,达到一定金额后给予折扣,从而提高客单价;而优惠券类型的判断则是针对特定的节日或促销活动,通过发放特定类型的优惠券来吸引用户购买商品。
这样的组合条件表达式能够灵活地应对各种复杂的业务场景,为电商平台提供了丰富的促销手段。
4.2 代码实现具体过程
首先是表达式接口的定义,它是整个规则引擎的基础,所有具体的规则表达式都需要实现这个接口:
// 表达式接口
public interface RuleExpression {
boolean interpret(OrderContext context);
}RuleExpression接口中定义了一个interpret方法,该方法接收一个OrderContext类型的上下文对象作为参数,返回一个布尔值,表示当前表达式在给定的上下文中是否成立。这个接口就像是一个统一的契约,规定了所有具体规则表达式的行为。
接下来是终结符表达式实现类VariableExpression,它用于处理单个变量和条件的判断:
import java.util.function.BiPredicate;
// 终结符表达式实现
public class VariableExpression implements RuleExpression {
private final String key;
private final BiPredicate<Object, Object> operator;
private final Object value;
public VariableExpression(String key, BiPredicate<Object, Object> operator, Object value) {
this.key = key;
this.operator = operator;
this.value = value;
}
public boolean interpret(OrderContext ctx) {
return operator.test(ctx.get(key), value);
}
}在VariableExpression类中,通过构造函数接收三个参数:key表示要判断的变量名,operator是一个二元谓词,用于定义变量和值之间的比较操作,value则是要比较的值。在interpret方法中,通过从OrderContext上下文对象中获取变量的值,然后使用operator进行比较,返回比较结果。
例如,如果要判断订单金额是否大于 500,可以创建一个VariableExpression实例,其中key为订单金额的变量名,operator为大于比较操作的谓词,value为 500。
然后是组合表达式实现类CompositeExpression,它可以将多个RuleExpression组合起来,形成更复杂的规则:
import java.util.List;
import java.util.function.Function;
import java.util.stream.Collectors;
// 组合表达式实现
public class CompositeExpression implements RuleExpression {
private final List<RuleExpression> expressions;
private final BooleanOperator operator;
public CompositeExpression(List<RuleExpression> expressions, BooleanOperator operator) {
this.expressions = expressions;
this.operator = operator;
}
public boolean interpret(OrderContext ctx) {
return operator.apply(expressions.stream()
.map(e -> e.interpret(ctx))
.collect(Collectors.toList()));
}
}CompositeExpression类通过构造函数接收两个参数:expressions是一个包含多个RuleExpression的列表,代表要组合的子表达式;
operator是一个BooleanOperator类型的运算符,用于定义子表达式之间的逻辑关系,如AND、OR等。在interpret方法中,通过遍历expressions列表,对每个子表达式调用interpret方法获取其结果,然后使用operator对这些结果进行逻辑运算,返回最终的结果。
例如,对于(memberLevel > 3 && totalAmount >= 500)这样的组合条件,可以创建一个CompositeExpression实例,其中expressions列表包含两个VariableExpression实例,分别用于判断会员等级和订单总金额,operator为AND运算符。
最后是 Spring 配置类RuleEngineConfig,用于配置和管理规则引擎的相关组件:
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
// Spring配置类
@Configuration
public class RuleEngineConfig {
@Bean
public ExpressionParser ruleParser() {
return new RuleExpressionParser();
}
}在RuleEngineConfig类中,通过@Bean注解定义了一个ruleParser方法,返回一个ExpressionParser实例。
这里的RuleExpressionParser是一个自定义的表达式解析器,用于将字符串形式的规则表达式解析为具体的RuleExpression对象。通过将ruleParser配置为 Spring 的 Bean,我们可以方便地在其他组件中通过依赖注入获取并使用它,实现对规则表达式的解析和处理。
例如,在服务层或控制器层中,可以通过@Autowired注解注入ruleParser,然后使用它来解析用户输入的规则表达式,从而实现订单折扣规则的动态配置和应用。
4.3 核心设计说明
✅组合模式构建语法树:在我们的订单折扣规则引擎中,组合模式被巧妙地应用于构建语法树结构。以复杂的组合条件表达式(memberLevel > 3 && totalAmount >= 500) || couponType == 'FESTIVAL'为例,我们可以将其看作是一个由多个节点组成的语法树。
其中,CompositeExpression类扮演了非终结符节点的角色,它可以包含多个子表达式,通过逻辑运算符(如AND、OR)将这些子表达式组合在一起,形成更复杂的逻辑结构。而VariableExpression类则作为终结符节点,代表了最基本的条件判断,如memberLevel > 3、totalAmount >= 500、couponType == 'FESTIVAL'。
通过递归地组合这些节点,我们可以构建出一棵完整的语法树,准确地表达复杂的订单折扣规则。在解析和计算规则时,从语法树的根节点开始,递归地调用每个节点的interpret方法,逐步计算出整个表达式的结果,从而判断订单是否满足折扣条件。
✅策略模式封装运算符逻辑:策略模式在本项目中用于封装不同的运算符逻辑,极大地提高了代码的可维护性和扩展性。
我们定义了BooleanOperator接口,它包含一个apply方法,用于对一组布尔值进行逻辑运算。不同的运算符(如AND、OR)通过实现这个接口来提供具体的运算逻辑。
例如,AndOperator类实现了BooleanOperator接口,在apply方法中,它会遍历传入的布尔值列表,只有当所有布尔值都为true时,才返回true,否则返回false,这正是逻辑AND运算符的行为。而OrOperator类则实现了逻辑OR运算符的逻辑,只要列表中有一个布尔值为true,就返回true。通过这种方式,当需要添加新的运算符时,只需要创建一个新的实现类并实现BooleanOperator接口,而不需要修改现有的代码,使得代码的扩展性得到了极大的提升。
同时,这种封装也使得代码的结构更加清晰,每个运算符的逻辑都被独立地封装在一个类中,易于理解和维护。
✅上下文对象封装订单状态信息:OrderContext上下文对象在规则引擎中起着至关重要的作用,它封装了订单的各种状态信息,为规则的解释和执行提供了必要的环境。
OrderContext类内部使用一个Map来存储订单的各种属性,如会员等级、订单总金额、优惠券类型等。通过get方法可以根据属性名获取相应的值,在VariableExpression类的interpret方法中,就是通过ctx.get(key)来获取订单的某个属性值,然后与预设的值进行比较,判断条件是否成立。
同时,OrderContext类也可以提供一些方法来更新订单的状态信息,在规则执行过程中,可能会根据某些条件对订单的属性进行修改,比如在满足特定折扣条件后,更新订单的实际支付金额等。
这样,上下文对象就像一个信息仓库,将订单的所有相关信息集中管理,使得规则引擎在解释和执行规则时能够方便地获取和使用这些信息,保证了规则引擎的正常运行。
✅Spring 集成实现解释器实例管理:Spring 框架的集成使得解释器实例的管理变得更加便捷和高效。在RuleEngineConfig配置类中,通过@Bean注解将ruleParser定义为一个 Spring Bean,这样 Spring 容器就会负责创建、初始化和管理这个实例。
在其他组件中,只需要通过@Autowired注解就可以轻松地获取到ruleParser实例,无需手动创建和管理。在服务层的某个类中,通过@Autowired private ExpressionParser ruleParser;就可以注入ruleParser,然后使用它来解析规则表达式。
这种方式不仅简化了代码的编写,还提高了代码的可测试性和可维护性。同时,Spring 的依赖注入机制还可以方便地对ruleParser进行替换和扩展,比如在测试环境中,可以注入一个模拟的ruleParser来进行单元测试,而在生产环境中则使用实际的ruleParser。此外,Spring 的生命周期管理功能还可以确保ruleParser在合适的时机被创建和销毁,保证了系统的稳定性和性能。
五、总结
解释器模式作为一种强大的行为型设计模式,通过构建语法树实现了领域特定语言的解析执行,为解决复杂的规则解析问题提供了有效的方案。其核心价值在于将易变的业务规则转化为可维护的语法结构,使得系统能够灵活应对各种变化。
在实际应用中,我们需要明确解释器模式与组合模式、策略模式的协同关系。
组合模式用于构建复杂的语法树结构,将简单的表达式组合成复杂的规则;策略模式则封装了运算符逻辑,使得不同的运算策略可以灵活替换,提高了代码的可维护性和扩展性。
同时,上下文对象在解释器模式中扮演着重要角色,它封装了系统的状态信息,为表达式的解释提供了必要的环境。
然而,解释器模式也并非完美无缺。在性能考量方面,由于解释器模式通常涉及递归调用和频繁的对象创建,可能会带来一定的性能损耗。特别是在处理大型代码或复杂语法时,性能问题可能会更加突出。
因此,在实际应用中,我们需要根据具体场景,合理评估性能需求,采取相应的优化措施,如缓存计算结果、使用编译器技术、优化抽象语法树等,以提高解释器的执行效率。
此外,语法规则的动态加载机制也是解释器模式在实际应用中需要关注的要点。随着业务的发展和变化,语法规则可能需要不断更新和扩展。
通过实现语法规则的动态加载,我们可以使解释器模式更加灵活,能够适应不同的业务需求。例如,可以将语法规则存储在外部配置文件中,在运行时动态加载和解析,这样可以避免在代码中硬编码规则,提高系统的可维护性和可扩展性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











