







目录
1、DOM4j包的下载地址及导入(导入Myecilpse中)
本课目标:
(1)理解XML概念及优势
(2)会编写格式良好的XML文档
(3)了解XML中特殊字符的处理方式
(4)了解解析器的概念
(5)了解DOM树节点构造
(6)会使用DOM操作XML数据(添加/保存)
01、XML
1、XML简介
2、XML文档结构
3、XML优势
4、XML中的命名空间
02、XML文档验证(略)
03、使用DOM解析XML
1、使用DOM解析XML文档的步骤如下:
①创建解析器工厂对象,即DocumentBuilderFactory对象
②由解析器工厂对象创建解析器对象,即DocumentBuilder对象
③由解析器对象对指定的XML文件进行解析,构建相应的DOM树,创建Document对象
④以Document对象为起点对DOM树的节点进行增加、删除、修改、查询等操作。
2、使用DOM解析XML时主要使用到以下对象
(1)Document对象
Document对象代表整个XML文档,所有其他的节点(Node)都以一定的顺序包含在Document对象之内,排列成一个树状结构,可以通过遍历这棵“树”来得到XML文档的所有内容。它也是对XML文档进行操作的起点,人们总是先通过解析XML源文件得到一个Document对象,然后再来执行后续的操作。
Document主要方法:
- ①getElementsByTagName(String name):返回一个NodeList对象,它包含了所有指定便签名称的标签。
- ②getDocumentElement():返回一个代表这个DOM树的根节点的Element对象,也就是代表XML文档根元素的对象。
(2)NodeList对象
顾名思义,NodeList对象是指包含了一个或者多个节点的列表。可以简单的把它看成一个Node数组,也可以通过方法来获得列表中的元素。
NodeList对象常用方法:
- ①getLength():返回列表的长度
- ②item(int index):返回指定位置的Node对象。
(3)Node对象
Node对象是DOM结构中最基本的对象,代表了文档树中的一个抽象节点。在实际使用时,很少真正用到Node对象,一般会用Element、Test等Node对象的子对象来操作文档。
Node对象的主要方法:
- ①getChildNodes():此节点包含的所有子节点的NodeList。
- ②getFirstChild():如果节点存在子节点,则返回第一个子节点。
- ③getLastChild():如果节点存在子节点,则返回最后一个子节点。
- ④getNextSibling():返回DOM树中这个节点的下一个兄弟节点
- ⑤getPreviousSibling():返回DOM树中这个节点的上一个兄弟节点
- ⑥getNodeName():返回节点的名称
- ⑦getNodeValue():返回节点的值
- ⑧getNodeType():返回节点的类型
(4)Element对象
Element对象代表XML文档中的标签元素,继承自Node,也是Node最主要的子对象。在标签中可以包含属性,因而Element对象中也有存取其属性的方法。
- ①getAttribute(String attributename):返回标签中指定属性名称的属性的值
- ②getElementByTagName(String name):返回具有指定标记名称的所有后代Element的NodeList。
1、XML解析
目前常见的XML解析技术有4种:
(1)DOM
①基于XML文档树结构的解析
②适用于多次访问的XML文档
③特点:比较消耗资源
(2)SAX
①基于事件的解析
②适用于大数据量的XML文档
③特点:占用资源少,内存消耗小
(3)JDOM
(4)DOM4J
①非常优秀的Java XML API
②性能优异、功能强大
③开放源代码
2、DOM
(1)DOM概念
①文档对象模型(Document Object Model)
②DOM把XML文件映射成一棵倒挂的"树",以根元素为根节点,每个节点都以对象的形式存在,通过存取这些对象就能够存取XML文档的内容。
(2)JAXP包含3个包
①org.w3c.dom:W3C推荐的用于使用DOM解析XML文档的接口
②org.xml.sax:用于使用SAX解析文档的接口
③javax.xml.parsers:解析器工厂工具,程序员获得并配置特殊的分析器。
(3)使用DOM(增、删、改、查)手机收藏信息
使用DOM解析XML文档的步骤如下:
①创建解析器工厂对象,即DocumentBuilderFactory对象
②由解析器工厂对象创建解析器对象,即DocumentBuilder对象
③由解析器对象对指定的XML文件进行解析,构建相应的DOM树,创建Document对象
④以Document对象为起点对DOM树的节点进行查询(查)、添加(增)、修改(改)、删除(删)等操作。
3、查询手机收藏信息
示例01:查询手机收藏信息
(1)XML文档代码如下:
<?xml version="1.0" encoding="UTF-8"?> <PhoneInfo> <Brand name="华为"> <Type name="U8650"/> <Type name="HW123"/> <Type name="HW321"/> </Brand> <Brand name="苹果"> <Type name="iPhone4"/> </Brand> </PhoneInfo>(2)关键代码:
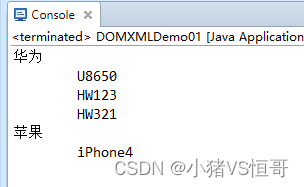
package cn.bdqn.demo02; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; /* * 查询操作 * * */ public class Demo01 { /* * 类DocumentBuilderFactory:定义工厂 API,使应用程序能够从 XML 文档获取生成 DOM 对象树的解析器。 * newInstance():获取 DocumentBuilderFactory 的新实例。 * newDocumentBuilder():使用当前配置的参数创建一个新的 DocumentBuilder 实例 * * 类DocumentBuilder:使其从XML文档获取DOM文档实例。使用此类,应用程序员可以从 XML 获取一个 Document。 * parse(File f):将给定文件的内容解析为一个 XML 文档,并且返回一个新的 DOM Document 对象 * * 接口Document:Document 接口表示整个 HTML 或 XML 文档。从概念上讲,它是文档树的根,并提供对文档数据的基本访问。 * getElementsByTagName():按文档顺序返回包含在文档中且具有给定标记名称的所有 Element 的 NodeList。 * * 接口NodeList:NodeList 接口提供对节点的有序集合的抽象,没有定义或约束如何实现此集合。 * getLength():列表中的节点数。 * item(int index):返回集合中的第 index 个项。 * * 接口Node:该文档树中的单个节点 getChildNodes():包含此节点的所有子节点的 NodeList。 * getNodeType():表示基础对象的类型的节点,如上所述。 ELEMENT_NODE字段: 该节点为 Document。 * * 接口Element:表示XML 文档中的一个元素 getAttribute(String name):通过名称获得属性值。 */ public static void main(String[] args) { /* * 要想将XML文件转换成Document对象,需要使用到解析器对象 * 要想使用解析器对象将xml文件转换成Document对象,首先需要是用解析器工厂对象 * * 使用DOM解析XML文档的步骤如下: * (1)创建解析器工厂对象,即DocumentBuilderFactory对象 * (2)由解析器工厂对象创建解析器对象,即DocumentBuilder对象 * (3)由解析器对象对指定的XML文件进行解析,构建相应的DOM树,创建Document对象 * (4)以Document对象为起点对DOM树的节点进行增加、删除、修改、查询等操作。 */ // (1)创建解析器工厂对象,即DocumentBuilderFactory对象 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); try { // (2)由解析器工厂对象创建解析器对象,即DocumentBuilder对象 DocumentBuilder db = dbf.newDocumentBuilder(); // (3)由解析器对象对指定的XML文件进行解析,构建相应的DOM树,创建Document对象 Document document = db.parse("收藏信息.xml"); /* * 获取收藏信息.xml文件中所有的Document元素,可能会获取多个,所以将获取的元素存放在NodeList集合中, * 即:得到所有Brand节点列表信息 * */ NodeList nl = document.getElementsByTagName("Brand"); // 第一个for循环里面拿出Brand的属性值 for (int i = 0; i < nl.getLength(); i++) { // 将节点集合中的元素取出来 Node node = nl.item(i); //获取第i个Brand元素的name属性的值 Element brand = (Element) node; // Element是Node的子节点:父变子,需要进行强制类型转换 String nameVlue = brand.getAttribute("name"); //即获得XML文件中name的属性值 System.out.println(nameVlue); //获取第i个Brand元素的所有子元素(Type)的name属性值 NodeList typeNodes = brand.getChildNodes(); for (int j = 0; j < typeNodes.getLength(); j++) { Node typeNode = typeNodes.item(j); /*类型判断,如果tybeNode能够转换成Element,才进行转换和输出 (假如此处不是一个标签就转换不了,需要进行类型判断,如果是Element则允许下述操作)*/ if (typeNode.getNodeType() == Node.ELEMENT_NODE) { Element type = (Element) typeNode; //Type节点 String typeValue = type.getAttribute("name"); //获得手机型号 System.out.println("\t" + typeValue); } } } } catch (ParserConfigurationException e) { e.printStackTrace(); } catch (SAXException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } }(3)输出结果

4、添加手机收藏信息
示例02:添加手机收藏信息
在示例01的XML文档中添加品牌为“MOTO”,型号为“A1680”的手机收藏信息
(1)XML文档代码如下:
<?xml version="1.0" encoding="UTF-8" standalone="no"?><PhoneInfo> <Brand name="华为"> <Type name="U8650"/> <Type name="HW123"/> <Type name="HW321"/> </Brand> <Brand name="苹果"> <Type name="iPhone4"/> </Brand> </PhoneInfo>(2)关键代码
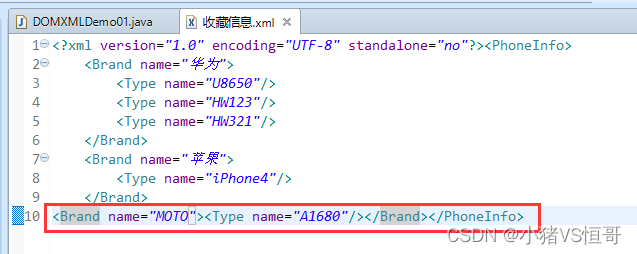
package cn.bdqn.demo03; import java.io.FileOutputStream; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import javax.xml.transform.OutputKeys; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerConfigurationException; import javax.xml.transform.TransformerException; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.xml.sax.SAXException; /** * 示例05:在XML文档中添加品牌为“MOTO”,型号为“A1680”的手机收藏信息 * * 分析如下: * 首先,根据收藏信息在内存中构建出它的DOM树,要在PhoneInfo的节点上添加品牌节点,需要先找到PhoneInfo节点。 * 然后再此DOM树上创建一个新的Brand品牌节点,设置它的属性name为“MOTO”。 * 然后根据它在DOM树的位置,把他添加为PhoneInfo的子节点。这样,此DOM树就有了新的结构。 * 最后把这个DOM树结构保存到XML文件就可以了。 * * */ public class ParseXMLDemo { /* * 在XML文档中添加品牌为“MOTO”,型号为“A1680”的手机收藏信息 * * 实现步骤如下: * (1)为XML文档构造DOM树 * (2)创建新节点,并设置name属性 * (3)把节点加到其所属父节点上 * (4)保存XML文档 */ public static void main(String[] args) { //得到DOM解析器的工厂示例 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); try { //从DOM工厂获得DOM解析器 DocumentBuilder db = dbf.newDocumentBuilder(); //解析XML文档,得到一个Document对象,即DOM树 //parse():将给定文件的内容解析为一个 XML 文档,并且返回一个新的 DOM Document 对象。 Document doc = db.parse("收藏信息2.xml"); //创建Brand节点 //createElement(String tagName):创建指定类型的元素 //setAttribute(name, value):添加一个新属性。 Element brandElement = doc.createElement("Brand"); brandElement.setAttribute("name", "MOTO"); //创建Type节点 Element typeElement = doc.createElement("Type"); typeElement.setAttribute("name", "A1680"); //添加父子关系 //appendChild(newChild):将节点 newChild 添加到此节点的子节点列表的末尾。 //getElementsByTagName():返回一个NodeList对象,它包含了所有指定便签名称的标签。 //item(int index):返回集合中的第 index 个项。 brandElement.appendChild(typeElement); Element phoneElement = (Element)doc.getElementsByTagName("PhoneInfo").item(0);//Element是NodeList的子节点,父变子,需要进行强制类型转换 phoneElement.appendChild(brandElement); //保存XML文件 //类TransformerFactory: //newInstance():获取 TransformerFactory 的新实例。 //newTransformer():创建执行从 Source 到 Result 的复制的新 Transformer。 //类Transformer: //类DOMSource TransformerFactory transformerFactory = TransformerFactory.newInstance(); Transformer transformer = transformerFactory.newTransformer(); DOMSource domSource = new DOMSource(doc); //设置编码类型 //setOutputProperty(String name,String value): //类OutputKeys:提供可用于设置 Transformer 的输出属性或从 Transformer 或 Templates 对象检索输出属性的字符串常量。 //ENCODING:类OutputKeys的字段,表示:指定了首选的字符编码,Transformer 应使用此编码将字符序列编码作为字节序列进行编码。 //类StreamResult:充当转换结果的持有者,可以为 XML、纯文本、HTML 或某些其他格式的标记。 //StreamResult(OutputStream outputStream) transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8"); StreamResult result = new StreamResult(new FileOutputStream("收藏信息2.xml")); //把DOM树转换为XML文件 //transform(Source xmlSource, Result outputTarget) :将 XML Source 转换为 Result。 transformer.transform(domSource, result); System.out.println("数据添加成功"); } catch (ParserConfigurationException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (SAXException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (TransformerConfigurationException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (TransformerException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }(3)添加手机收藏后的XML文档结果

5、修改手机收藏信息
示例03:修改手机收藏信息
将保存手机收藏信息的XML文档中的手机品牌信息MOTO修改为“摩托罗拉”。
(1)XML文档代码如下:
<?xml version="1.0" encoding="UTF-8"?> <PhoneInfo> <Brand name="华为"> <Type name="U8650"/> <Type name="HW123"/> <Type name="HW321"/> </Brand> <Brand name="苹果"> <Type name="iPhone4"/> </Brand> <Brand name="MOTO"> <Type name="A1680"/> </Brand> </PhoneInfo>(2)关键代码
package cn.bdqn.demo04; import java.io.FileOutputStream; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import javax.xml.transform.OutputKeys; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerConfigurationException; import javax.xml.transform.TransformerException; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; /** * 示例06:将保存手机收藏信息的XML文档中的手机品牌信息MOTO修改为“摩托罗拉”。 * * 分析如下: * 手机收藏信息的修改仍然要先构建DOM树,要把品牌信息MOTO修改为“摩托罗拉”, * 先要找到属性为MOTO的Brand节点,然后把name属性设置为“摩托罗拉”, * 最后将DOM树的修改保存到XML文件中 * */ public class ParseXMLDemo { /* * 示例06:将保存手机收藏信息的XML文档中的手机品牌信息MOTO修改为“摩托罗拉”。 * * 实现步骤如下: * (1)为XML文档构造DOM树 * (2)找到符合修改条件的节点 * (3)设置该节点的属性为修改值 * (4)保存XML文档 */ public static void main(String[] args) { //得到DOM解析器的工实例 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); try { //从DOM工厂获得DOM解析器 DocumentBuilder db = dbf.newDocumentBuilder(); //解析XML文档,得到一个Document对象,即DOM树 Document doc = db.parse("收藏信息3.xml"); //找到修改的节点 //getAttribute(String attributename):返回标签中指定属性名称的属性的值 //setAttribute(name, value):添加一个新属性。 NodeList list = doc.getElementsByTagName("Brand"); for(int i = 0;i<list.getLength();i++){ Element brandElement = (Element)list.item(i); String brandName = brandElement.getAttribute("name"); if(brandName.equals("MOTO")){ brandElement.setAttribute("name", "摩托罗拉"); } } //保存XML文件 //类TransformerFactory: //newInstance():获取 TransformerFactory 的新实例。 //newTransformer():创建执行从 Source 到 Result 的复制的新 Transformer。 //类Transformer: //类DOMSource TransformerFactory transformerFactory = TransformerFactory.newInstance(); Transformer transformer = transformerFactory.newTransformer(); DOMSource domSource = new DOMSource(doc); //设置编码类型 //setOutputProperty(String name,String value): //类OutputKeys:提供可用于设置 Transformer 的输出属性或从 Transformer 或 Templates 对象检索输出属性的字符串常量。 //ENCODING:类OutputKeys的字段,表示:指定了首选的字符编码,Transformer 应使用此编码将字符序列编码作为字节序列进行编码。 //类StreamResult:充当转换结果的持有者,可以为 XML、纯文本、HTML 或某些其他格式的标记。 //StreamResult(OutputStream outputStream) transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8"); StreamResult result = new StreamResult(new FileOutputStream("收藏信息3.xml")); //把DOM树转换为XML文件 //transform(Source xmlSource, Result outputTarget) :将 XML Source 转换为 Result。 transformer.transform(domSource, result); System.out.println("数据修改成功"); } catch (ParserConfigurationException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (SAXException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (TransformerConfigurationException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (TransformerException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }(3)修改手机收藏后的XML文档结果

6、删除手机收藏信息
示例04:删除手机收藏信息
从保存手机收藏信息的XML文档中,删除手机品牌信息“摩托罗拉”。
(1)XML文档代码如下:
<?xml version="1.0" encoding="UTF-8"?> <PhoneInfo> <Brand name="华为"> <Type name="U8650"/> <Type name="HW123"/> <Type name="HW321"/> </Brand> <Brand name="苹果"> <Type name="iPhone4"/> </Brand> <Brand name="摩托罗拉"> <Type name="A1680"/> </Brand> </PhoneInfo>(2)关键代码
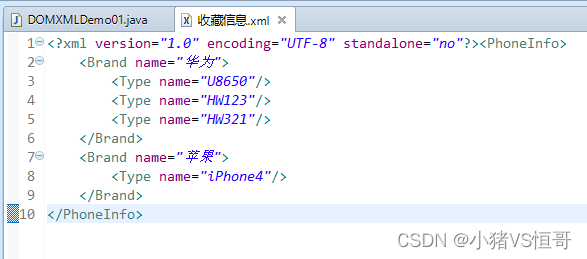
package cn.bdqn.demo05; import java.io.FileOutputStream; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import javax.xml.transform.OutputKeys; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerConfigurationException; import javax.xml.transform.TransformerException; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; /** * 示例07:从保存手机收藏信息的XML文档中,删除手机品牌信息“摩托罗拉”。 * * 分析如下: * 手机收藏信息的删除操作也要先构建DOM树,在DOM树种找到name属性为“摩托罗拉”的品牌节点,然后删除, * 这时需要先找到删除节点的父节点,通过Brand节点的父节点PhoneInfo去实现最终的删除功能。 * * @author 小厨Java * */ public class ParseXMLDemo { /* * 示例07:从保存手机收藏信息的XML文档中,删除手机品牌信息“摩托罗拉”。 * * 实现步骤如下: * (1)为XML文档构造DOM树 * (2)找到符合删除条件的节点 * (3)找到该节点的父节点实现其子节点的删除功能 * (4)保存XML文档 */ public static void main(String[] args) { //得到DOM解析器的工厂实例 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); try { //从DOM工厂获得DOM解析器 DocumentBuilder db = dbf.newDocumentBuilder(); //解析XML文档,得到一个Document对象,即DOM树 Document doc = db.parse("收藏信息4.xml"); //找到删除的节点 NodeList list = doc.getElementsByTagName("Brand"); for (int i = 0; i < list.getLength(); i++) { Element brandElement = (Element)list.item(i); String brandName = brandElement.getAttribute("name"); if (brandName.equals("摩托罗拉")) { brandElement.getParentNode().removeChild(brandElement); } } //保存XML文件 TransformerFactory transformerFactory = TransformerFactory.newInstance(); Transformer transformer = transformerFactory.newTransformer(); DOMSource domSource = new DOMSource(doc); //设置编码类型 transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8"); StreamResult result = new StreamResult(new FileOutputStream("收藏信息4.xml")); //把DOM转换为XML文件 transformer.transform(domSource, result); System.out.println("删除元素完毕"); } catch (ParserConfigurationException e) { e.printStackTrace(); } catch (SAXException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } catch (TransformerConfigurationException e) { e.printStackTrace(); } catch (TransformerException e) { e.printStackTrace(); } } }(3)删除手机收藏后的XML文档结果

7、 将上述示例01~示例04通过方法封装在一起
示例05:将增、删、改、查变为方法,调用方法操作完成
(1)XML文档起始代码如下:
<?xml version="1.0" encoding="UTF-8"?> <PhoneInfo> <Brand name="华为"> <Type name="U8650"/> <Type name="HW123"/> <Type name="HW321"/> </Brand> <Brand name="苹果"> <Type name="iPhone4"/> </Brand> </PhoneInfo>(2)关键代码
package cn.bdqn.demo01; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import javax.xml.transform.OutputKeys; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerConfigurationException; import javax.xml.transform.TransformerException; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class DOMXMLDemo01 { Document document;// 全局变量 public static void main(String[] args) { DOMXMLDemo01 domd = new DOMXMLDemo01(); File file = new File("收藏信息.xml"); // 获取Document对象 domd.getDocument(file); // 输出XML文件中的所有信息 // domd.printInfo(); // 添加XML信息 // domd.addXml(); // 修改XML信息 //domd.updateXml(); //删除XML信息 domd.deleteXml(); } // 声明方法获得Document对象 public void getDocument(File file) { // 获取解析器工厂对象 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); try { // 从DOM工厂获得DOM解析器 DocumentBuilder db = dbf.newDocumentBuilder(); // 解析XML文档,得到一个Document对象,即DOM树 document = db.parse(file); } catch (ParserConfigurationException e) { e.printStackTrace(); } catch (SAXException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } // 声明保存XML的方法 public void saveXml(String url) { // 保存XML文件 TransformerFactory transformerFactory = TransformerFactory .newInstance(); try { Transformer transformer = transformerFactory.newTransformer(); DOMSource domSourse = new DOMSource(document); // 设置编码类型 transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8"); StreamResult result = new StreamResult(new FileOutputStream(url)); // 把DOM转换为XML文件 transformer.transform(domSourse, result); } catch (TransformerConfigurationException e) { e.printStackTrace(); } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (TransformerException e) { // TODO Auto-generated catch block e.printStackTrace(); } } // 查询输出XML文件中的信息 public void printInfo() { // 获取收藏信息.xml文件中所有的Brand元素,可能会获取多个,所以将获取的元素存放在NodeList集合中 NodeList nl = document.getElementsByTagName("Brand"); for (int i = 0; i < nl.getLength(); i++) { // 将节点集合中的元素取出来 Node node = nl.item(i); Element brand = (Element) node; String nameVlue = brand.getAttribute("name"); System.out.println(nameVlue); NodeList typeNodes = brand.getChildNodes(); for (int j = 0; j < typeNodes.getLength(); j++) { Node typeNode = typeNodes.item(j); // 类型判断,如果typeNode能够转换成Element,才进行转换和输出 if (typeNode.getNodeType() == Node.ELEMENT_NODE) { Element type = (Element) typeNode; String typeValue = type.getAttribute("name"); System.out.println("\t" + typeValue); } } } } // 向XML文件中添加数据 public void addXml() { // 创建Brand节点 // createElement(String tagName):创建指定类型的元素 // setAttribute(name, value):添加一个新属性。 Element brandElement = document.createElement("Brand"); brandElement.setAttribute("name", "MOTO"); // 创建Type节点 Element typeElement = document.createElement("Type"); typeElement.setAttribute("name", "A1680"); // 添加父子关系 // appendChild(newChild):将节点 newChild 添加到此节点的子节点列表的末尾。 // getElementsByTagName():返回一个NodeList对象,它包含了所有指定便签名称的标签。 // item(int index):返回集合中的第 index 个项。 brandElement.appendChild(typeElement); Element phoneElement = (Element) document.getElementsByTagName( "PhoneInfo").item(0);// Element是NodeList的子节点,父变子,需要进行强制类型转换 phoneElement.appendChild(brandElement); // 添加完毕之后要保存文件 saveXml("收藏信息.xml"); } // 修改XML里面的数据 public void updateXml() { // 找到修改的节点 // getAttribute(String attributename):返回标签中指定属性名称的属性的值 // setAttribute(name, value):添加一个新属性。 NodeList list = document.getElementsByTagName("Brand"); for (int i = 0; i < list.getLength(); i++) { Element brandElement = (Element) list.item(i); String brandName = brandElement.getAttribute("name"); if (brandName.equals("MOTO")) { brandElement.setAttribute("name", "摩托罗拉"); // 修改属性值 } } // 修改完毕之后要保存文件 saveXml("收藏信息.xml"); } // 删除XML信息 public void deleteXml() { // 找到删除的节点 NodeList list = document.getElementsByTagName("Brand"); for (int i = 0; i < list.getLength(); i++) { Element brandElement = (Element) list.item(i); String brandName = brandElement.getAttribute("name"); if (brandName.equals("摩托罗拉")) { // getParentNode():此节点的父节点。(Node接口中的方法) // removeChild(Node oldChild):从子节点列表中移除 oldChild 所指示的子节点,并将其返回。 brandElement.getParentNode().removeChild(brandElement);// 删除属性值 } } //删除完毕之后要保存文件 saveXml("收藏信息.xml"); } }(3)操作结果(通过XML文档查看结果):
① 输出XML文件中的所有信息
② 添加XML信息
③修改XML信息
④删除XML信息

04、使用 DOM4J解析XML
1、DOM4j包的下载地址及导入(导入Myecilpse中)
详细步骤请查看:向MyEclipse中导入DOM4J包的方法(截图)_小猪VS恒哥的博客-CSDN博客
2、DOM4J解析
3、读取、添加、修改、删除操作
示例06:使用DOM4j进行 查询、添加、修改、删除操作
(1)XML文档代码如下:
<?xml version="1.0" encoding="GBK"?> <PhoneInfo> <Brand name="华为"> <Type name="U8650"/> <Type name="HW123"/> <Type name="HW321"/> </Brand> <Brand name="苹果"> <Type name="iPhone4"/> </Brand> </PhoneInfo>(2)关键代码
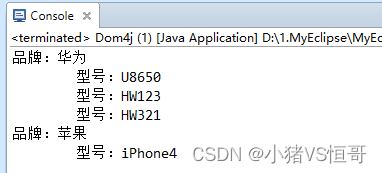
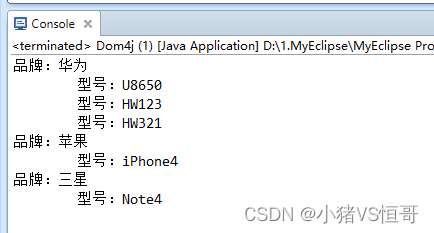
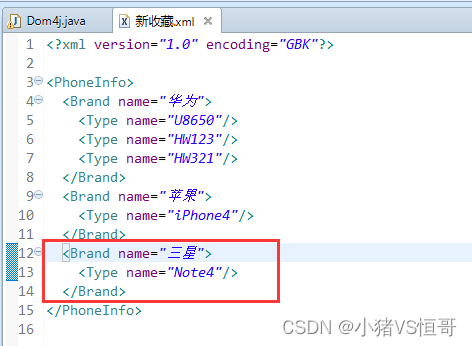
package cn.bdqn.demo02; import java.io.File; import java.io.FileWriter; import java.io.IOException; import java.util.Iterator; import org.dom4j.Document; import org.dom4j.Element; import org.dom4j.io.OutputFormat; import org.dom4j.io.SAXReader; import org.dom4j.io.XMLWriter; public class Dom4j { public static Document doc; public static void main(String[] args) { // 获取Document对象 loadDocument(); // 输出xml文件中所有信息 // showPhoneInfo(); // 添加xml信息 // addNewPhoneInfo(); // 修改xml信息 // updatePhoneInfo(); // saveXML("新收藏.xml"); // 删除xml信息 // deleteItem(); // showPhoneInfo(); } // 声明方法获得Document对象 public static void loadDocument() { try { SAXReader saxReader = new SAXReader(); doc = saxReader.read(new File("新收藏.xml")); } catch (Exception e) { e.printStackTrace(); } } // 修改XML里面的数据 public static void updatePhoneInfo() { // 获取XML的根节点 Element root = doc.getRootElement(); int id = 0; for (Iterator itBrand = root.elementIterator(); itBrand.hasNext();) { Element brand = (Element) itBrand.next(); id++; brand.addAttribute("id", id + ""); } saveXML("新收藏.xml"); } // 删除xml文件里面的数据 public static void deleteItem() { // 获取XML的根节点 Element root = doc.getRootElement(); int id = 0; for (Iterator itBrand = root.elementIterator(); itBrand.hasNext();) { Element brand = (Element) itBrand.next(); if (brand.attributeValue("name").equals("华为")) { brand.getParent().remove(brand); } } saveXML("新收藏.xml"); } // 查询输出XML文件中的信息 public static void showPhoneInfo() { // 获取XML的根节点 Element root = doc.getRootElement(); // 遍历所有的Brand标签 for (Iterator itBrand = root.elementIterator(); itBrand.hasNext();) { Element brand = (Element) itBrand.next(); // 输出标签的name属性 System.out.println("品牌:" + brand.attributeValue("name")); // 遍历Type标签 for (Iterator itType = brand.elementIterator(); itType.hasNext();) { Element type = (Element) itType.next(); // 输出标签的name属性 System.out.println("\t型号:" + type.attributeValue("name")); } } } // 声明保存XML的方法 public static void saveXML(String path) { try { OutputFormat format = OutputFormat.createPrettyPrint(); format.setEncoding("GBK"); // 指定XML编码 XMLWriter writer; writer = new XMLWriter(new FileWriter(path), format); writer.write(doc); writer.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } // 声明向XML文件中添加数据的方法 public static void addNewPhoneInfo() { // 获取XML的根节点 Element root = doc.getRootElement(); // 创建Brand标签 Element el = root.addElement("Brand"); // 给Brand标签设置属性 el.addAttribute("name", "三星"); // 创建Type标签 Element typeEl = el.addElement("Type"); // 给Type标签设置属性 typeEl.addAttribute("name", "Note4"); saveXML("新收藏.xml"); } }(3)操作结果
① 输出XML文件中的所有信息
② 添加XML信息
③修改XML信息
④删除XML信息




















 2581
2581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











