







 本文探讨了最优控制中的关键概念,如汉-雅-贝方程、充分性和必要条件,以及庞特里亚金最大原理的应用。讲解了如何通过这些方法解决优化问题,涉及开环与闭环策略的区别,以及在无限时间horizon下的考虑。
本文探讨了最优控制中的关键概念,如汉-雅-贝方程、充分性和必要条件,以及庞特里亚金最大原理的应用。讲解了如何通过这些方法解决优化问题,涉及开环与闭环策略的区别,以及在无限时间horizon下的考虑。
Control theoretic methods
3.1 A simple optimal control problem

3.2 The Hamilton-Jacobi-Bellman equation
最优性充分条件(sufficient optimality conditions):满足某些条件,推导出其为最优点。
HJB方程:
We now present an intuitive argument for the fact that the optimal value function V satisfies the partial differential equation
, which is called the Hamilton-Jacobi-Bellman equation.
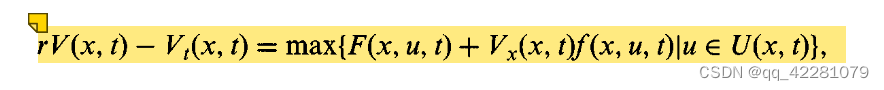

3.3 Pontryagin’s maximum principle
必要优化条件(necessary optimality condition):在函数g的局部最大值处,函数的梯度向量为0。
It is a first order condition for smooth problems, comparable to the
condition that the gradient vector of a function g : Rn—>R must vanish
at a local maximum of g.
但在局部极小值和其他临界点出,函数的梯度向量也为0
因此只有我们对g的整体曲率性质有额外的信息(如g的凹性),我们才能从g’(x)=0的条件中推断出x确实是一个最大值。
Only if we have some additional information on the global curvature
properties of g (like concavity of g) can we infer from the condition
g(x) = 0 that x is indeed a maximum.
###########################################################################################################
充分优化条件:增广最大值原则(augmented maximum principle)
哈密顿函数、协态变量/伴随变量、最大哈密顿函数:

最大值条件:

伴随方程:(两个都是,后面的用起来更方便)

横截条件:

充分性定理:

上述定义中λ=Vx,即λ等于值函数V对x的一阶导。因此 (啥玩意,没看懂)
λ measures the marginal utility of the state at time t along the optimal trajectory. In other words, λ (t) is the highest hypothetical price which a rational decision maker would be willing to pay for an additional, infinitesimally small unit of the state variable at time t. Because of this, the adjoint variable is often called the shadow price of x.
根据状态变量X初始变量X(0)的不同,横截条件λ(0)会有所变化
目标函数若包含依赖X(0)的额外项,横截条件也会有所变化

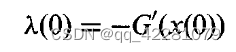
3.2定理的另外一种写法:

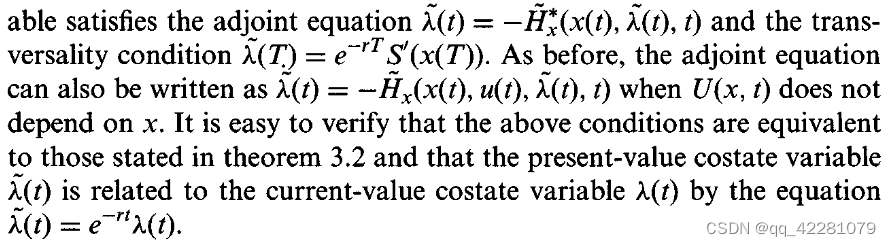
3.4 How to solve an optomal control problem
有3种方法可以解任何优化问题:
第一种 重构问题使最优解明确 (只适用于非常简单的问题,需要对解的形式有很好的直觉)
第二种 利用必要最优性条件(necessary optimality conditions)(必须与最优解存在性定理结合适用)
第三种 利用充分最优性条件(sufficient optimality conditions)
(第四种 先用第二种再用第三种)
0.0 讲了一个例子 云里雾里
3.5 Information, commitment, and strategies
- 只需提供时间 u(t)=φ(t),open-loop stategy
- 提供时间和当前状态 u(t)=φ(x(t),t), Markovian strategy, a closed-loop strategy, or a feedback strategy.
二者需要知道的信息量不同
开环决策可以看成是马尔科夫决策的一种退化,即φ与x无关。
不是开环决策的马尔科夫决策称为非退化马尔科夫决策。
3.6 Infinite time horizon
无界时域最优化问题目标函数积分应该收敛,但这是一个很强的假设。
当积分不收敛时,无界时域问题最优性的几个定义:


(强度越来越弱)
充分性定理
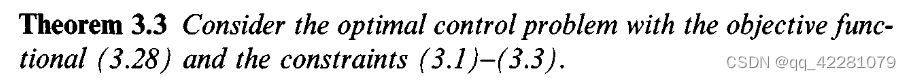





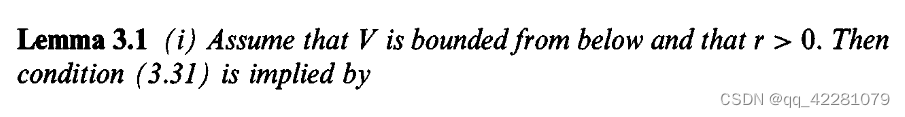

















 354
354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









