







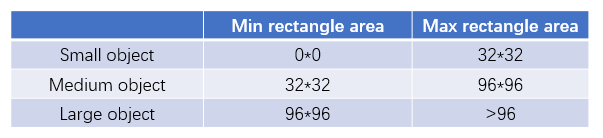
在2019年发布的论文《Augmentation for small object detection》中给出了小目标的定义:
忽略多尺度训练的因素及增加网络检测分支的情况
以ResNet-50为backbone为例,网络的输入为640×640×3,经过FPN结构,最终输出的特征图的shape有:10×10、20×20、40×40、80×80、160×160,其中最小的特征图负责检测大目标,最大的特征图负责检测小目标。
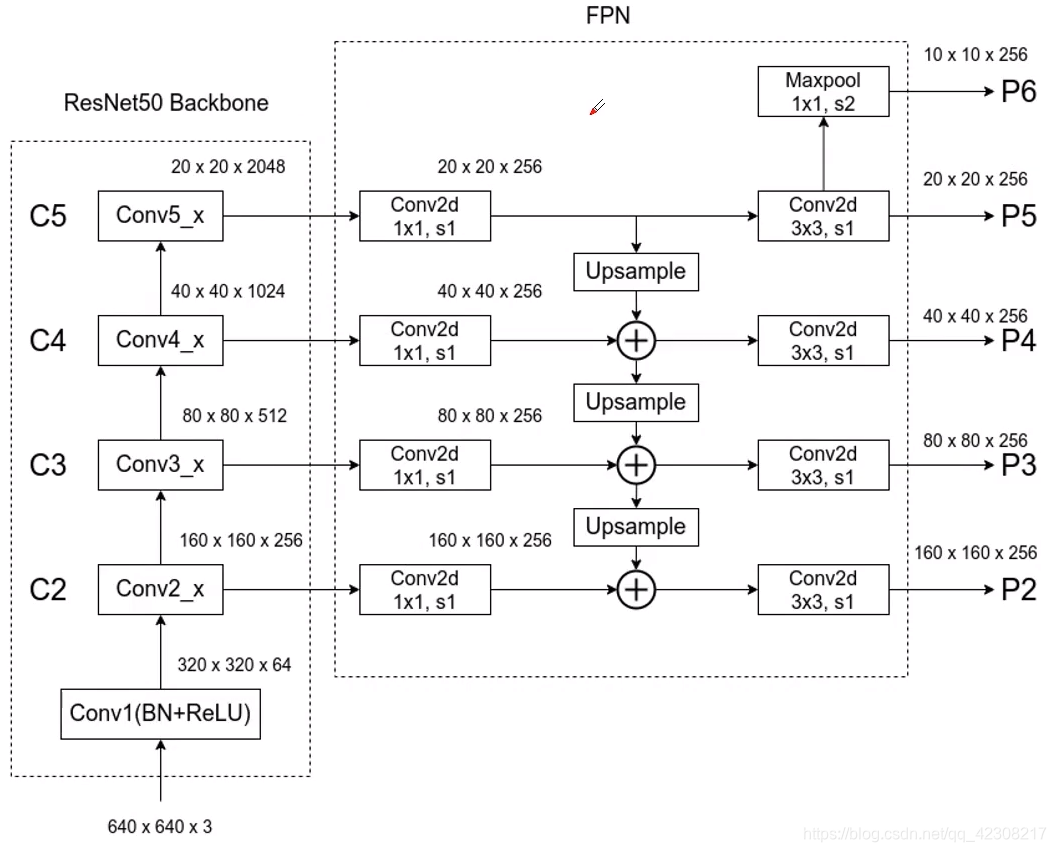
粗略的计算一下感受野 640÷160=4 ,因此每格特征图对应到原图的感受野是4×4大小,因此如果原始图像中目标的宽高小于4个像素,网络就很难学习到目标的特征信息。
但在现如今的小目标检测中,很多图像的尺寸的都是非常大的,比如射线探测图,遥感图等,在做特征提取的过程中如果下采样的倍数太大,就会丢失掉很多特征信息,也就很难让网络去学习,比如将上面的backbone应用到2000×2000的图像数据上,大致的感受野就是 2000÷640×4≈13,即目标的长宽小于13×13,则在训练的过程中就会出现问题。
换句话说,如果不去进行高倍数的降采样,网络向前传播时就需要大量的显存去保存特征图,会增加GPU的负担从而导致显存爆炸。
解决方案:
1.对大分辨率图像进行分割裁剪,变成一张张小的chip,为了避免chip之间一些目标正好被切断,根据目标大小的不同设置overlap重叠区域,最后经过NMS非极大值抑制去除重复检测框。
2.同时可以对一张张小的chip做腐蚀,然后再去做训练。
3.如果是多类的小目标检测,则可以训练多个模型,每个模型单独训练一类,最后将结果整合,这样可以很大程度是避免误检。
4.深度学习的效果在某种意义上是靠大量数据喂出来的,小目标往往存在特征单一的问题,因此小目标网络的性能同样也可以通过增加训练集中小目标样本的种类和数量来提升。



















评论 3

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包










