







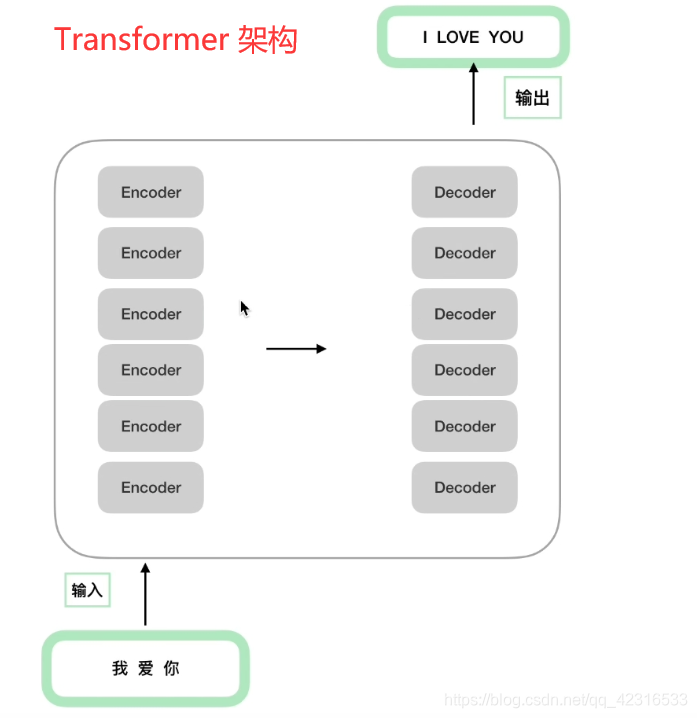
BERT的基础架构是Transformer的encoder部分:

为什么说基础架构是Transformer的encoder部分,原因:BERT是12个encoder的叠加:

而Transformer的架构是这样的:
Transformer中的输入是input embedding和positional encoding,而BERT的输入是:input=token embedding + segment embedding + position embedding
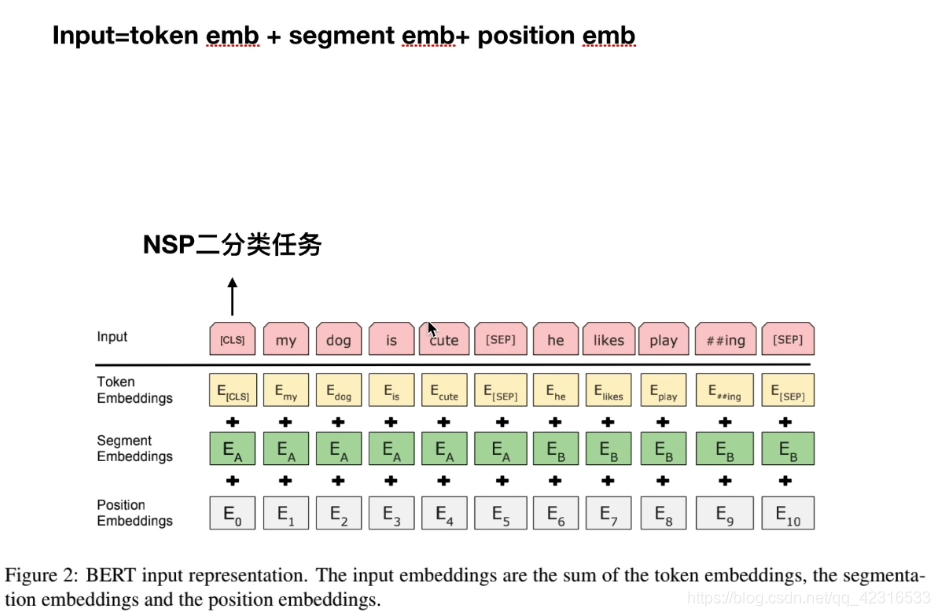
解释一下上面的3个部分的输入:
Token embedding:一行句子中的每个单词(包括特殊符号CLS和SEP)作为一个token,对这些token做embedding。
Segment embedding:对于一些特殊的任务比如NSP(Next Sentence Prediction),这个任务是预测两个句子之间的关系,是否属于顺序上下文关系(二分类),这个任务的输入需要句子对,那么就需要特殊符号来区别这两个句子。一行句子中第一个SEP符号之前的单词,属于第一个句子,那么它们的Segment embedding全为0,第一个SEP符号之后的单词,属于第二个句子,它们的Segment embedding全为1。而CLS呢,它是一个向量,当我们的BERT模型训练完成之后,就将CLS输入到最后一层prediction层,去完成NSP二分类任务。(需要注意的一点是,CLS不能代表整个句子的语义信息,如果直接拿CLS向量去做文本相似度的任务效果非常不好,不过有些论文已经在这上面做出了改进,现在是有一些方法可以用BERT做文本相似度)。
Position embedding:对一行句子中每个单词(包括特殊符号)的索引做一个embedding,BERT规定句子的Max_len=512。
接下来看BERT的两个任务:MLM(Mask Language Model掩码语言模型)和NSP(Next Sentence Prediction)
MLM
在介绍MLM之前,先来了解两个概念,AR和AE:

举个例子:

对于同样的一句话:我爱吃饭,AR模型在预测这句话出现的概率时是单侧的,先预测“我”出现的概率,再预测在“我”出现的条件下“爱”出现的概率,以此类推,可以看出这是依照句子顺序来预测的。而AE模型会mask句子中的单字(是单字,不是单词),比如mask吃之后,那么公式左边在“我爱mask饭”的条件下“我爱吃饭”出现的概率就变成了,在“我爱饭”条件下“吃”出现的概率。AE模型mask文本之后,能够利用上下文信息使得文本重建。BERT中就是用到了AE模型。
但AE模型有个问题,当mask的单词存在依赖关系时,它不能够利用这两个单字之间的关系,只能将它们认为是相互独立的,如下图所示。

BERT中的做法是,对于所有的文本,只mask 15%的文本,并且在mask的15%中,80%的是用[mask]符号代替,10%是保持原来的字,另10%是从词列表中选择任意一个词替代。BERT中代码是这样写的:

NSP
BERT中训练NSP任务时使用的样本如下:

这样会混淆两个概念(主题预测和连贯性预测),同一训练语料库中抽取到的两个连续的段落大概率是属于同一个主题的,而从不同文档中随机创建的一对段落大概率是不同主题的,这样做出来的效果是非常好,但是已经混淆了概念。(因为主题预测比连贯性预测要容易得多)。但目前已经有论文提出了新的样本(同一文档中的连续段落为正样本,颠倒顺序之后为负样本做训练)。














 2958
2958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









