







 LMStudio是一个允许用户在本地离线运行大型语言模型的平台,提供脱机功能、应用内聊天界面、模型下载支持(如GGMLLama、MPT和StarCoder)以及隐私保护。它旨在降低对云服务的依赖,适合研究人员和开发者在本地环境工作。
LMStudio是一个允许用户在本地离线运行大型语言模型的平台,提供脱机功能、应用内聊天界面、模型下载支持(如GGMLLama、MPT和StarCoder)以及隐私保护。它旨在降低对云服务的依赖,适合研究人员和开发者在本地环境工作。
📌 简介
LM Studio是一个允许用户在本地离线运行大型语言模型(LLMs)的平台,它提供了一种便捷的方式来使用和测试这些先进的机器学习模型,而无需依赖于互联网连接。以下是LM Studio的一些关键特性:
-
脱机:用户可以在自己的笔记本电脑上运行LLMs,完全不需要在线连接。
-
用户界面:LM Studio提供了一个应用内聊天界面,用户可以通过这个界面与模型交互,或者使用一个与OpenAI兼容的本地服务器。
-
模型下载:用户可以从Hugging Face的🤗(即Hugging Face公司)仓库下载任何兼容的模型文件。
-
模型支持:LM Studio支持多种ggml Llama、MPT和StarCoder模型,这些模型都可以在Hugging Face上找到。
-
系统要求:为了运行LM Studio,用户需要M1/M2/M3 Mac,或者支持AVX2指令集的Windows PC。同时,它还提供了Linux系统的beta版本。
-
技术文档:LM Studio 提供了技术文档,以帮助用户更好地理解和使用这个平台。
-
项目支持:LM Studio的实现得益于llama.cpp项目。
-
隐私:当在本地运行模型时,没有信息被传输到云。尽管在使用GPT-4、Bard和claude 2等基于云的模型时,隐私问题可能被夸大了,但在本地运行模型可以避免任何问题。
-
实验:如果你看到了生成人工智能的价值,可以通过测试了解模型的细节并知道还有什么可用。
-
成本:开源模型是免费的,其中一些可以不受限制地用于商业。
LM Studio的目标是让大型语言模型更加易于访问和使用,同时减少对云服务的依赖,这对于希望在本地环境中进行模型训练和测试的研究人员和开发者来说非常有用。通过LM Studio,用户可以在自己的设备上探索和运行最新的语言模型,从而更好地控制数据隐私和安全性。
-
官网下载地址:https://lmstudio.ai/
-
Studio并不开源,只是免费使用。
📌 使用说明
📍 下载安装
-
官网下载地址:https://lmstudio.ai/
-
按需选择要下载的版本【mac、windos、linux】
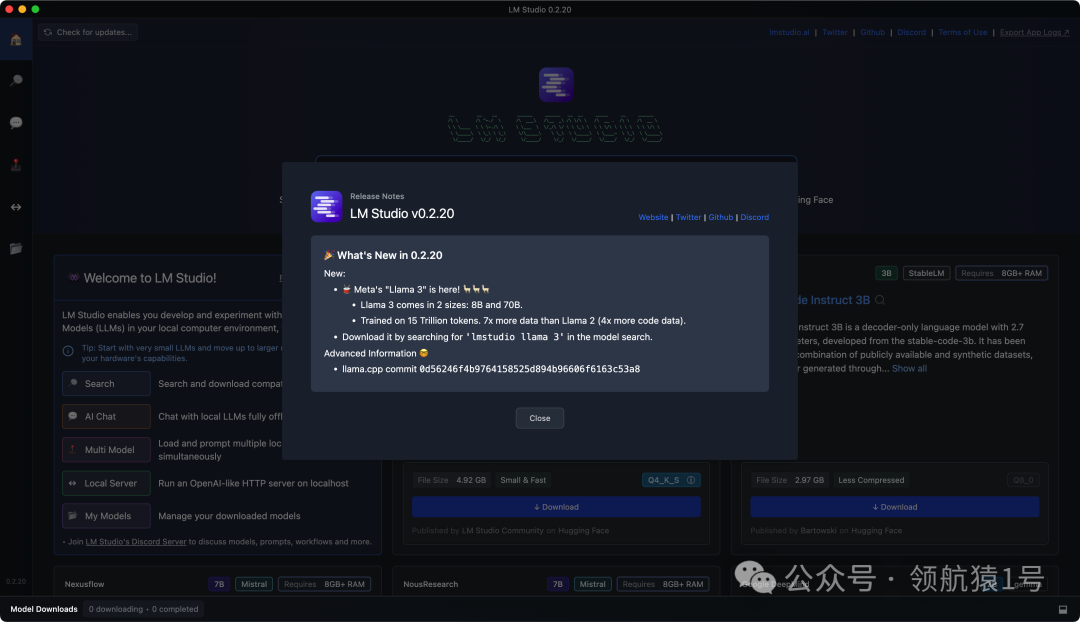
安装成功页面
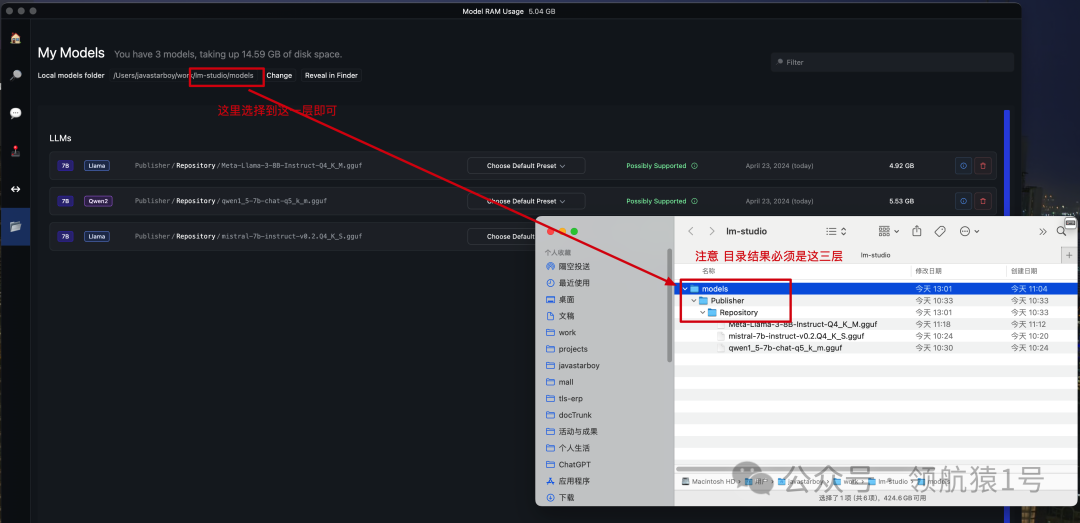
📍 调整模型存储路径
-
调整存储目录,方便管理,特别是 windos ,不要放默认的 C 盘
-
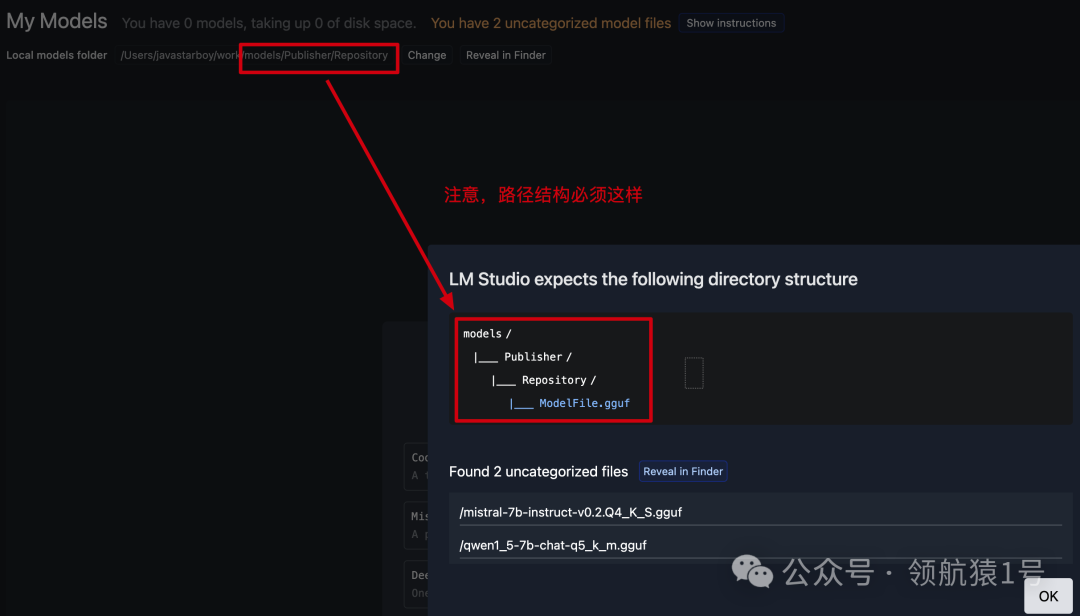
注意存放模型的目录结构:/models/Publisher/Repository/
-
自定义路径选择到 /models 层即可【我当时这里折腾了好久才加载出来模型】
注意存放模型的目录结构
📍 模型下载
安装之后打开, 搜索对应大模型, 下载, 举例: baichuan
点击左侧菜单栏文件夹图标进行管理

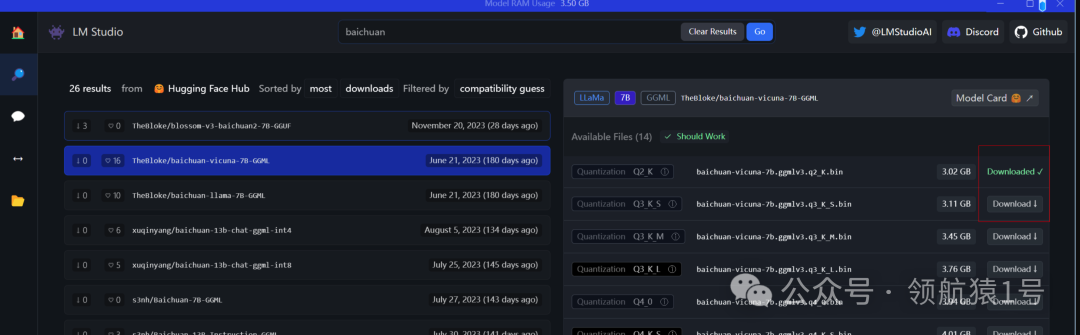
下载模型失败问题
如果出现下载模型失败问题,可以复制模型地址,然后用浏览器打开下载。关于网络问题:https://user.by.ltd/aff.php?aff=23165

📍 聊天
点击左侧菜单栏聊天图标, 新建聊天, 输入框输入内容
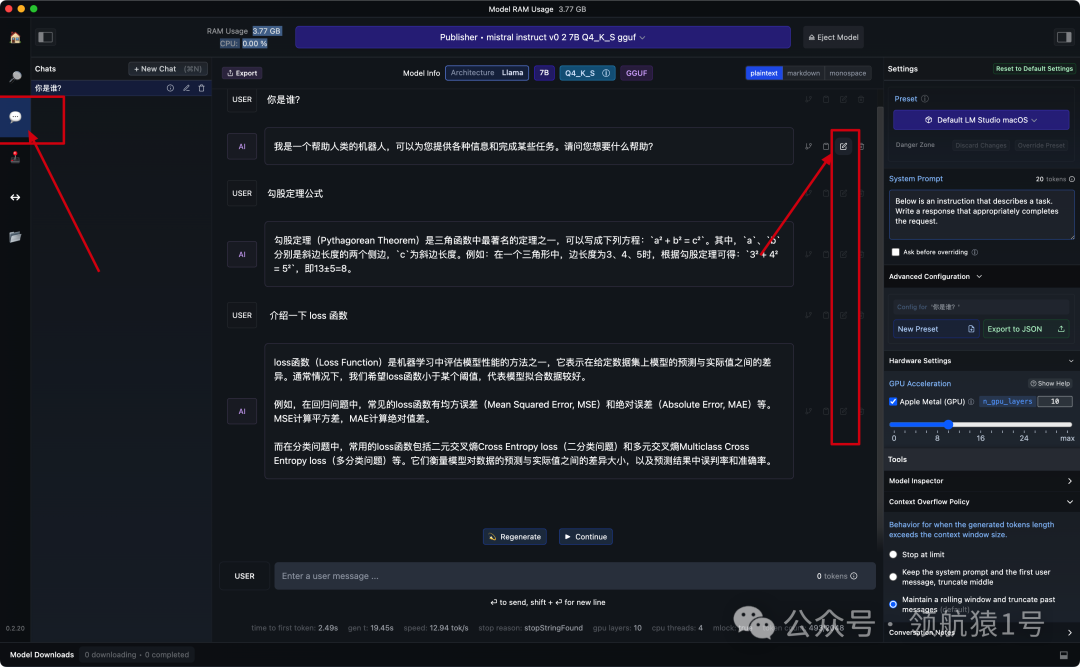
可能对回答的结果并不满意, 我们可以点击结果后面的编辑, 更正结果, 多次训练后, ai就回回复我们想要的答案
📍 API接口
点击菜单栏倒数第二个图标, 进入api页面; 随意设置一个端口号, 启动服务
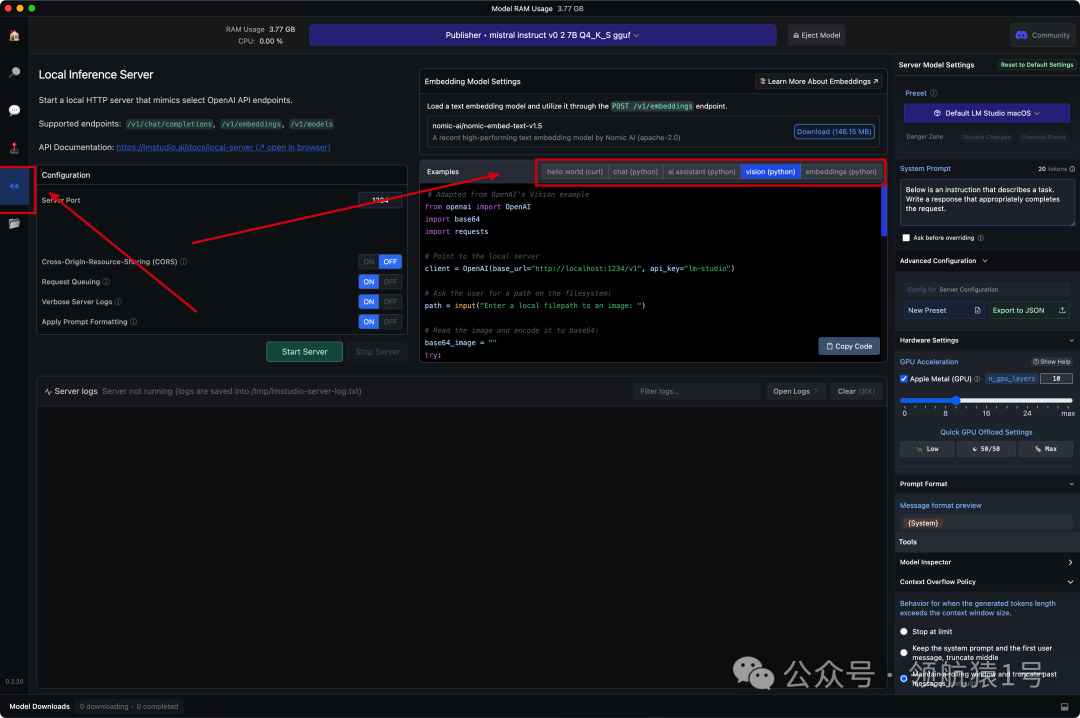
打开浏览器查看服务是否启动
AI 大模型全栈知识库👇
https://www.yuque.com/lhyyh/ai
我是一名资深 AI 全栈工程师,持续分享 AI 相关知识,感兴趣的小伙伴欢迎关注并一起学习、交流💪




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











