







Object源码分析(二)
第五个方法
protected native Object clone() throws CloneNotSupportedException;
源码解释
/**
* Returns a string representation of the object. In general, the
* {@code toString} method returns a string that
* "textually represents" this object. The result should
* be a concise but informative representation that is easy for a
* person to read.
* It is recommended that all subclasses override this method.
* <p>
* The {@code toString} method for class {@code Object}
* returns a string consisting of the name of the class of which the
* object is an instance, the at-sign character `{@code @}', and
* the unsigned hexadecimal representation of the hash code of the
* object. In other words, this method returns a string equal to the
* value of:
* <blockquote>
* <pre>
* getClass().getName() + '@' + Integer.toHexString(hashCode())
* </pre></blockquote>
*
* @return a string representation of the object.
*/
clone方法首先会判对象是否实现了Cloneable接口,若无则抛出CloneNotSupportedException;
当某个类要复写clone方法时,要继承Cloneable接口。通常的克隆对象都是通过super.clone()方法来克隆对象。
一般的super.clone().getClass=x.getClass()。
clone有浅复制与深复制一说,浅复制与深复制的区别是对引用对象的处理区别:
(1)浅复制:
对于基本数据类型单纯复制值;
对于引用数据类型仅复制该栈值,如数组变量则复制地址,对于对象变量则复制对象的引用。
package com.lx.mode;
import java.io.Serializable;
import java.util.Arrays;
/**
* @author luxin
* @create 2019-07-25 17:05
*/
public class Cat implements Cloneable, Serializable {
private String name;
private String [] hobby;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String[] getHobby() {
return hobby;
}
public void setHobby(String[] hobby) {
this.hobby = hobby;
}
@Override
public String toString() {
return "Cat{" +
"name='" + name + '\'' +
", hobby=" + Arrays.toString(hobby) +
'}';
}
@Override
protected Object clone() throws CloneNotSupportedException {
//浅复制
return super.clone();
//深复制
// Cat clone =(Cat) super.clone();
// String newhobby[]=new String[clone.getHobby().length];
// for (int i = 0; i <clone.getHobby().length ; i++) {
// newhobby[i]=clone.getHobby()[i];
// }
// clone.setHobby(newhobby);
//
// return clone;
}
public static void main(String[] args) throws CloneNotSupportedException {
Cat cat=new Cat();
String []hobby={"吃饭","睡觉"};
cat.setName("name");
cat.setHobby(hobby);
Cat clone = (Cat) cat.clone();
System.out.println("实体--------"+cat);
System.out.println("克隆---------"+clone);
System.out.println(cat.hobby==clone.hobby);
//只修改克隆体的hobby
String []newhobby=clone.getHobby();
newhobby[0]="lanqiu";
newhobby[1]="paobu";
clone.setName("newName");
clone.setHobby(newhobby);
//修改后的结果
System.out.println("实体--------"+cat);
System.out.println("克隆---------"+clone);
System.out.println(cat.hobby==clone.hobby);
}
}
结果:
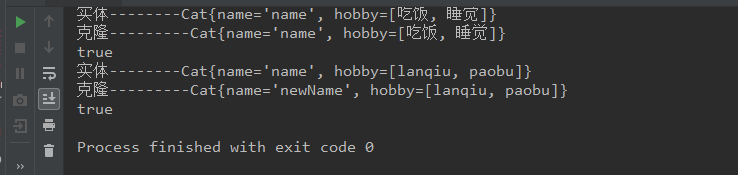

所以修改per2的hobby会影响per1,但是对于基本数据类型,age不会受影响。
(2)深复制,就是对于复合类型,重新new出来,给它赋值,然后set到克隆体。
代码同上,只需要将Person的浅复制代码注释,放开深复制代码;
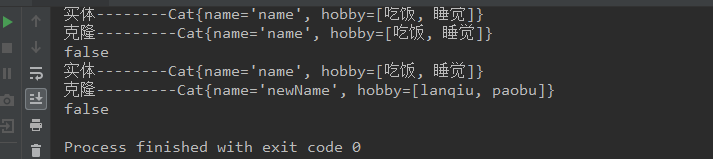

所以对于深复制,修改per2并不会影响per1。
第六个方法:返回对象的字符串表示。
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
第七个方法:
protected void finalize() throws Throwable { }
1.执行时机不可预知
当一个对象变得不可触及时,垃圾回收器某个时期会回收此对象。
当回收对象之前会调用finalize方法,这类似于人类临终之前必须做一件事情:写遗言。
因为GC是不确定性的(这跟JVM相关),所以finalize方法的执行具有不可预知性。
2.finalize忽略异常
即finalize代码中若出现异常,异常会被忽略
3.finalize使用
什么时候使用?当一个对象在回收前想要执行一些操作,就要覆写Object类中的finalize( )方法。一般来说,finalize被作为第二种安全网来使用,如FileInputStream类, 当对象回收时,有可能资源为释放,所以这里第二次来确认(那也总比不释放强吧,虽然具体释放时机未定)。
最后三个方法:
wait(), notify(), notifyAll(),这些属于基本的java多线程同步类的API,都是native实现:
该部分参考 参考
public final native void wait(long timeout) throws InterruptedException;
public final native void notify();
public final native void notifyAll();
1、wait()、notify/notifyAll() 方法是Object的本地final方法,无法被重写。
2、wait()使当前线程阻塞,前提是 必须先获得锁,一般配合synchronized 关键字使用,即,一般在synchronized 同步代码块里使用 wait()、notify/notifyAll() 方法。
3、 由于 wait()、notify/notifyAll() 在synchronized 代码块执行,说明当前线程一定是获取了锁的。
当线程执行wait()方法时候,会释放当前的锁,然后让出CPU,进入等待状态。
只有当 notify/notifyAll() 被执行时候,才会唤醒一个或多个正处于等待状态的线程,然后继续往下执行,直到执行完synchronized 代码块的代码或是中途遇到wait() ,再次释放锁。
也就是说,notify/notifyAll() 的执行只是唤醒沉睡的线程,而不会立即释放锁,锁的释放要看代码块的具体执行情况。所以在编程中,尽量在使用了notify/notifyAll() 后立即退出临界区,以唤醒其他线程 。
4、wait() 需要被try catch包围,中断也可以使wait等待的线程唤醒。
5、notify 和wait 的顺序不能错,如果A线程先执行notify方法,B线程在执行wait方法,那么B线程是无法被唤醒的。
6、notify 和 notifyAll的区别:
notify方法只唤醒一个等待(对象的)线程并使该线程开始执行。所以如果有多个线程等待一个对象,这个方法只会唤醒其中一个线程,选择哪个线程取决于操作系统对多线程管理的实现。notifyAll 会唤醒所有等待(对象的)线程,尽管哪一个线程将会第一个处理取决于操作系统的实现。如果当前情况下有多个线程需要被唤醒,推荐使用notifyAll 方法。比如在生产者-消费者里面的使用,每次都需要唤醒所有的消费者或是生产者,以判断程序是否可以继续往下执行。
7、在多线程中要测试某个条件的变化,使用if 还是while?
要注意,notify唤醒沉睡的线程后,线程会接着上次的执行继续往下执行。所以在进行条件判断时候,可以先把 wait 语句忽略不计来进行考虑,显然,要确保程序一定要执行,并且要保证程序直到满足一定的条件再执行,要使用while来执行,以确保条件满足和一定执行。如下代码:
public class K {
//状态锁
private Object lock;
//条件变量
private int now,need;
public void produce(int num){
//同步
synchronized (lock){
//当前有的不满足需要,进行等待
while(now < need){
try {
//等待阻塞
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("我被唤醒了!");
}
// 做其他的事情
}
}
}
显然,只有当前值满足需要值的时候,线程才可以往下执行,所以,必须使用while 循环阻塞。注意,wait() 当被唤醒时候,只是让while循环继续往下走.如果此处用if的话,意味着if继续往下走,会跳出if语句块。但是,notifyAll 只是负责唤醒线程,并不保证条件云云,所以需要手动来保证程序的逻辑。
实现生产者和消费者问题
什么是生产者-消费者问题

如上图,假设有一个公共的容量有限的池子,有两种人,一种是生产者,另一种是消费者。需要满足如下条件:
1、生产者产生资源往池子里添加,前提是池子没有满,如果池子满了,则生产者暂停生产,直到自己的生成能放下池子。
2、消费者消耗池子里的资源,前提是池子的资源不为空,否则消费者暂停消耗,进入等待直到池子里有资源数满足自己的需求。
-抽象仓库类
public interface AbstractStorage {
void consume(int num);
void produce(int num);
}
-仓库类
import java.util.LinkedList;
/**
* 生产者和消费者的问题
* wait、notify/notifyAll() 实现
*/
public class Storage1 implements AbstractStorage {
//仓库最大容量
private final int MAX_SIZE = 100;
//仓库存储的载体
private LinkedList list = new LinkedList();
//生产产品
public void produce(int num){
//同步
synchronized (list){
//仓库剩余的容量不足以存放即将要生产的数量,暂停生产
while(list.size()+num > MAX_SIZE){
System.out.println("【要生产的产品数量】:" + num + "\t【库存量】:"
+ list.size() + "\t暂时不能执行生产任务!");
try {
//条件不满足,生产阻塞
list.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
for(int i=0;i<num;i++){
list.add(new Object());
}
System.out.println("【已经生产产品数】:" + num + "\t【现仓储量为】:" + list.size());
list.notifyAll();
}
}
//消费产品
public void consume(int num){
synchronized (list){
//不满足消费条件
while(num > list.size()){
System.out.println("【要消费的产品数量】:" + num + "\t【库存量】:"
+ list.size() + "\t暂时不能执行生产任务!");
try {
list.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//消费条件满足,开始消费
for(int i=0;i<num;i++){
list.remove();
}
System.out.println("【已经消费产品数】:" + num + "\t【现仓储量为】:" + list.size());
list.notifyAll();
}
}
}
-生产者
public class Producer extends Thread{
//每次生产的数量
private int num ;
//所属的仓库
public AbstractStorage abstractStorage;
public Producer(AbstractStorage abstractStorage){
this.abstractStorage = abstractStorage;
}
public void setNum(int num){
this.num = num;
}
// 线程run函数
@Override
public void run()
{
produce(num);
}
// 调用仓库Storage的生产函数
public void produce(int num)
{
abstractStorage.produce(num);
}
}
-消费者
public class Consumer extends Thread{
// 每次消费的产品数量
private int num;
// 所在放置的仓库
private AbstractStorage abstractStorage1;
// 构造函数,设置仓库
public Consumer(AbstractStorage abstractStorage1)
{
this.abstractStorage1 = abstractStorage1;
}
// 线程run函数
public void run()
{
consume(num);
}
// 调用仓库Storage的生产函数
public void consume(int num)
{
abstractStorage1.consume(num);
}
public void setNum(int num){
this.num = num;
}
}
-测试
public class Test{
public static void main(String[] args) {
// 仓库对象
AbstractStorage abstractStorage = new Storage1();
// 生产者对象
Producer p1 = new Producer(abstractStorage);
Producer p2 = new Producer(abstractStorage);
Producer p3 = new Producer(abstractStorage);
Producer p4 = new Producer(abstractStorage);
Producer p5 = new Producer(abstractStorage);
Producer p6 = new Producer(abstractStorage);
Producer p7 = new Producer(abstractStorage);
// 消费者对象
Consumer c1 = new Consumer(abstractStorage);
Consumer c2 = new Consumer(abstractStorage);
Consumer c3 = new Consumer(abstractStorage);
// 设置生产者产品生产数量
p1.setNum(10);
p2.setNum(10);
p3.setNum(10);
p4.setNum(10);
p5.setNum(10);
p6.setNum(10);
p7.setNum(80);
// 设置消费者产品消费数量
c1.setNum(50);
c2.setNum(20);
c3.setNum(30);
// 线程开始执行
c1.start();
c2.start();
c3.start();
p1.start();
p2.start();
p3.start();
p4.start();
p5.start();
p6.start();
p7.start();
}
}
-结果
















 6586
6586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









