







前言
这是一次浪费了我一周时间(做了62次实验)的深坑记录,说多了都是心酸。在开源代码的基础上,为了简化封装,重构了其代码,模型结构等等保持不变,但training loss始终不下降,极其稳定。
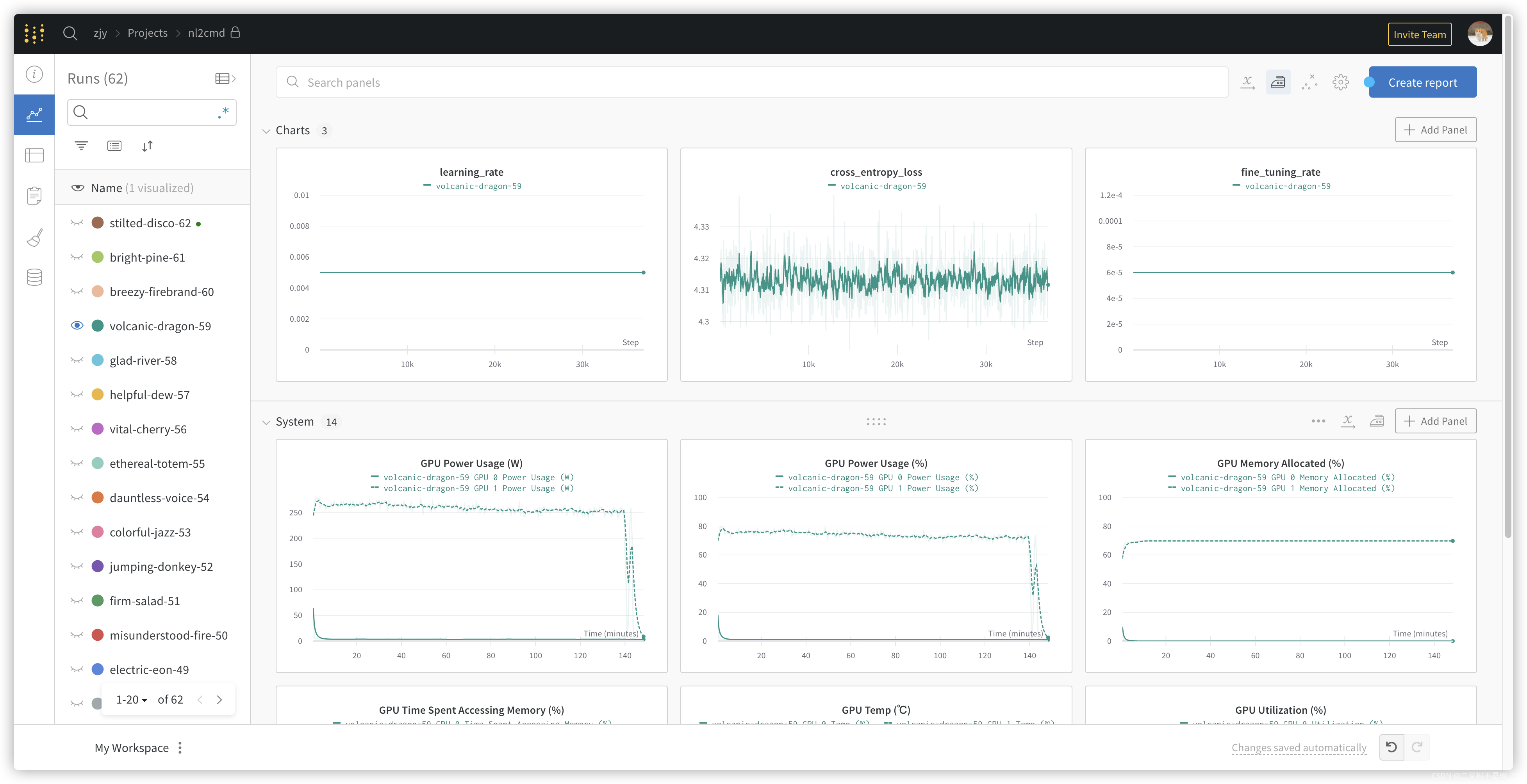
找bug的过程
- 检查了模型结构和参数维度
- 检查注明🌟的地方:
for epoch in range(sp.num_epochs): # Update model parameters sp.train() # 🌟 for step, mini_batch in enumerate(tqdm(train_loader, total=len(train_loader))): wandb.log({'learning_rate': sp.optim.param_groups[0]['lr']}) wandb.log({'fine_tuning_rate': sp.optim.param_groups[1]['lr']}) formatted_batch = sp.format_batch(mini_batch) loss = sp.loss(formatted_batch) loss.backward() # 🌟 epoch_losses.append(float(loss)) # Update parameters sp.optim.step() # 🌟 sp.optim.zero_grad() # 🌟
最终原因
发现先定义了优化器,才定义的model,导致优化器中的params待更新的参数为空,更新了个寂寞!
# Optimizer
self.optim = optim.Adam(
[
{'params': [p for n, p in self.named_parameters() if not 'trans_parameters' in n and p.requires_grad]},
{'params': [p for n, p in self.named_parameters() if 'trans_parameters' in n and p.requires_grad],
'lr': self.bert_finetune_rate}
], lr=self.learning_rate)
# Construct NN model
self.mdl = Seq2Seq_PG(args, self.in_vocab, self.out_vocab)
修正
调换顺序,先定义模型,最后定义优化器
# Construct NN model
self.mdl = Seq2Seq_PG(args, self.in_vocab, self.out_vocab)
# Optimizer
self.optim = optim.Adam(
[
{'params': [p for n, p in self.named_parameters() if not 'trans_parameters' in n and p.requires_grad]},
{'params': [p for n, p in self.named_parameters() if 'trans_parameters' in n and p.requires_grad],
'lr': self.bert_finetune_rate}
], lr=self.learning_rate)














 1986
1986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









